基于国产chatGLM微调nlp信息抽取任务
基于国产chatGLM微调nlp信息抽取任务

一、传统nlp做信息抽取
- 文本预处理:包括去除HTML标签、分段、分句、分词、词性标注、命名实体识别等。
- 句法分析:对句子进行结构分析,确定语法成分和关系。可以采用依存句法或者短语结构句法进行分析。
- 语义分析:使用自然语言理解技术进行语义解析,提取句子的含义。包括词义消歧、指代消解、情感分析等。
- 实体识别:对文本中的实体进行识别,包括人名、地名、组织机构名等。可以采用规则匹配、统计学方法、机器学习等方法进行实现。
- 关系抽取:基于实体识别和语义分析结果,提取实体之间的关系。可以采用规则匹配、模式匹配、统计学方法、机器学习等方法进行实现。
- 结果过滤:根据需要,对抽取的信息进行筛选和过滤。可以采用阈值过滤、逻辑判断、规则匹配等方法进行实现。
在这个流程中,有几个困难点需要注意:
- 数据质量问题:数据质量会影响到整个流程的效果,因此需要对数据进行清洗、去重等操作。需要大量人工标注数据,进行训练才能达到想要的效果
- 解析复杂度问题:句法分析和语义分析都是NLP中比较复杂的任务,需要耗费大量的计算资源和时间。
- 实体识别难点:实体识别需要考虑上下文环境、实体类型、同名实体等问题,这些都会影响到实体识别的准确性。
- 关系抽取挑战:关系抽取需要考虑多个实体之间的关系,同时还需要解决一些歧义问题。
在整个流程中,实体识别和关系抽取是比较关键的工作,它们的准确性直接影响到信息抽取的结果。
二、什么是零样本和少样本
1. 零样本和少样本的概念:
零样本和少样本是机器学习领域中常见的两个概念,特别是在图像识别、自然语言处理等领域中应用较为广泛。所谓的零样本学习是指模型在没有任何样本数据的情况下进行预测;而少样本学习则是指模型只有很少的样本数据时进行预测。
2. 零样本和少样本的应用场景:
在实际应用中,零样本和少样本学习都有广泛的应用场景。比如,在自然语言处理中,我们希望算法能够自动理解新出现的单词,即使它们从未在训练集中出现过,这就是一种零样本学习。另外,当我们需要训练一个模型来分类大量不同物体的图像时,如果每个类别的训练数据都很少,那么就需要利用少样本学习的方法来训练模型。
3. 零样本和少样本在大模型时代的优势和意义:
在当前的大模型时代,零样本和少样本学习变得更加重要。对于大规模的复杂任务,模型需要更多的数据来训练,但是获取足够的数据却非常困难。在这种情况下,通过零样本学习和少样本学习,我们可以利用已有的数据来加速模型的训练,并且提高模型的泛化能力。同时,这种方法还可以减少人工标注数据的工作量,大大降低了人力和时间成本。
4. 相比传统NLP,零样本和少样本学习具有以下优势:
更高的泛化能力:在传统NLP中,模型通常需要大量训练数据才能达到较好的性能。但是在实际应用中,我们经常遇到新的、未知的情况,此时传统NLP的表现会受到限制。而利用零样本和少样本学习的方法,则可以通过先前学习到的知识来更好地适应新的环境和任务,从而提高模型的泛化能力。
更低的数据标注成本:传统NLP通常需要大量的人工标注数据来进行模型的训练。但是这种方法需要耗费大量人力和时间,并且难以适应不断变化的场景。而利用零样本和少样本学习的方法,我们可以减少数据标注的成本,并且更快地适应新的任务和环境。
更广泛的应用场景:传统NLP通常需要大量的数据来支持模型的训练,因此很难在一些场景下应用,比如医疗、法律、金融等领域,这些领域的数据往往非常敏感、难以获取。而利用零样本和少样本学习的方法,则可以通过少量数据来支持模型的训练,并且在这些敏感领域具有更广泛的应用场景。
三、大模型时代信息抽取
console函数
在Rich库中,console和print函数都用于向控制台输出文本。它们的用途略有不同,print函数会将其参数打印成字符串,然后输出到控制台;而console对象则提供了许多其他的输出功能,如输出进度条、表格、警告信息等。
例如,你可以使用console.log()方法向控制台输出调试信息或状态更新,console.print()方法可以将数据按照指定格式输出为表格或树形结构,console.warn()方法可以显示警告信息等。这些功能可以帮助开发者更快地发现问题并解决它们。
console.status()方法用于向控制台输出状态信息。它通常用于在长时间运行的操作中显示进度。
例如,如果你有一个需要进行一段时间的耗时操作(比如下载大型文件),你可以使用console.status()方法在控制台上显示进度条或百分比,以便用户知道操作的进展情况。
console.status()方法接受三个参数:text、done和total。
text参数是要显示的文本,
done参数是已完成的数量,
total参数是总数量。
使用这些参数,console.status()方法会自动计算出当前进度,并将其以进度条的形式显示在控制台上。
例如,下面的代码演示了如何使用console.status()方法显示下载进度:
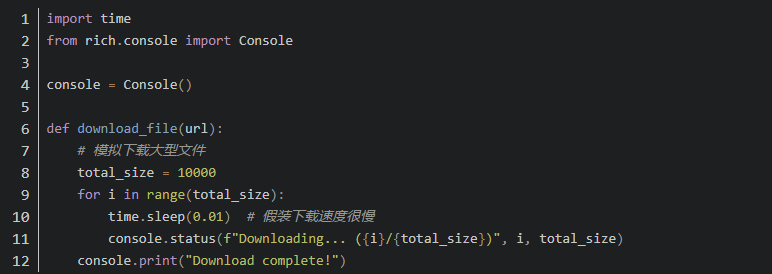
当你运行这段代码时,会在控制台上显示一个进度条,告诉你下载的进度。
1. 提示词设计
该任务的 prompt ,我们主要考虑 是什么,输出什么:
也就是:
- 告诉模型你要干什么:信息抽取任务
- 告诉模型输出格式
2. 微调逻辑
基于chatGLM微调nlp信息抽取任务的大致逻辑是这样的:
先进行对预料做一个分类,即该语料属于哪个概念(也就是属于哪个模式层,例如:猫,狗等概念层)。然后对这个概念进行属性的抽取:例如,猫有年纪,品种,产地等属性信息。
3. 数据样本
ok有了这个逻辑就知道,需要两个语料:
分类语料一:告诉模型 属于哪个模式层

微调语料二:告诉模型,一些示例,让它输出什么样的数据

在定义一下你想要的属性
根据需要添加即可:

4. 微调代码
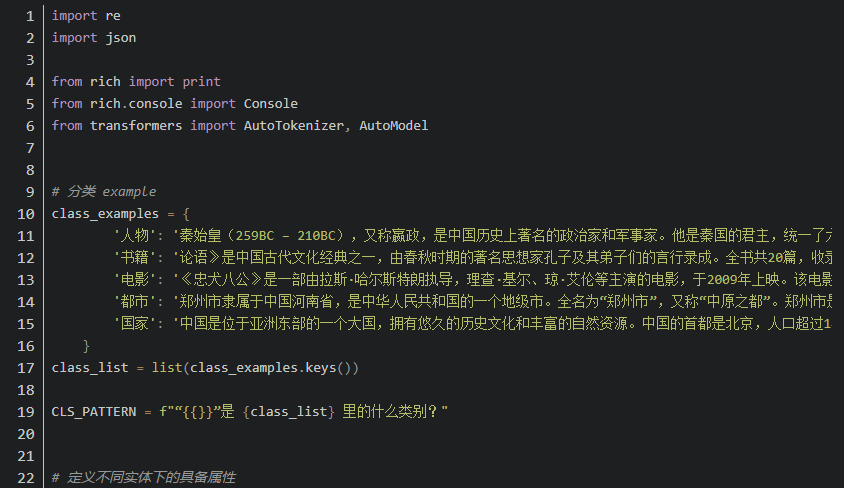
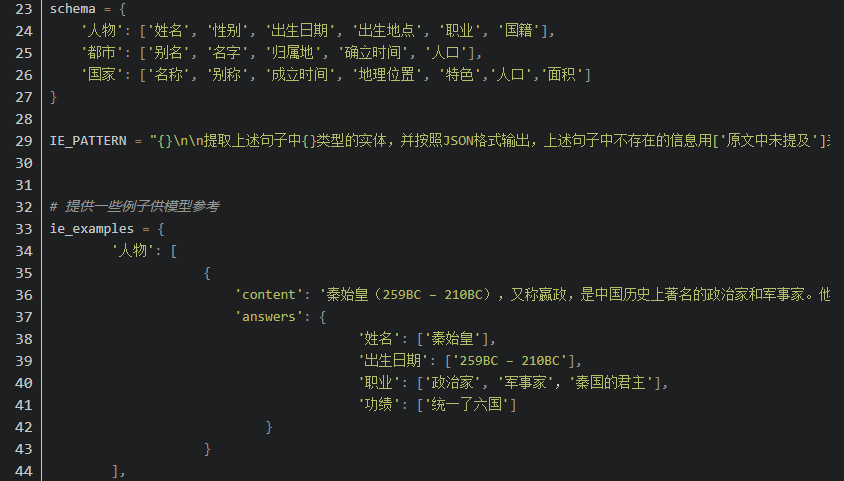
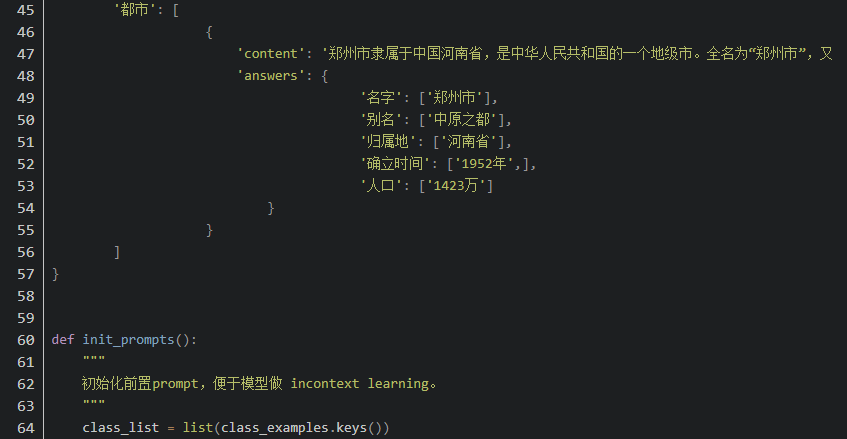

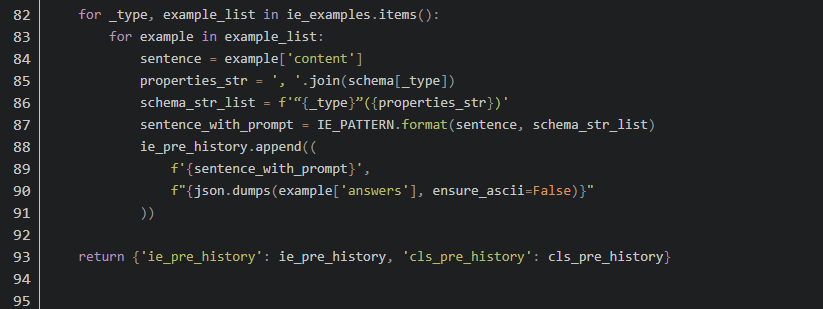
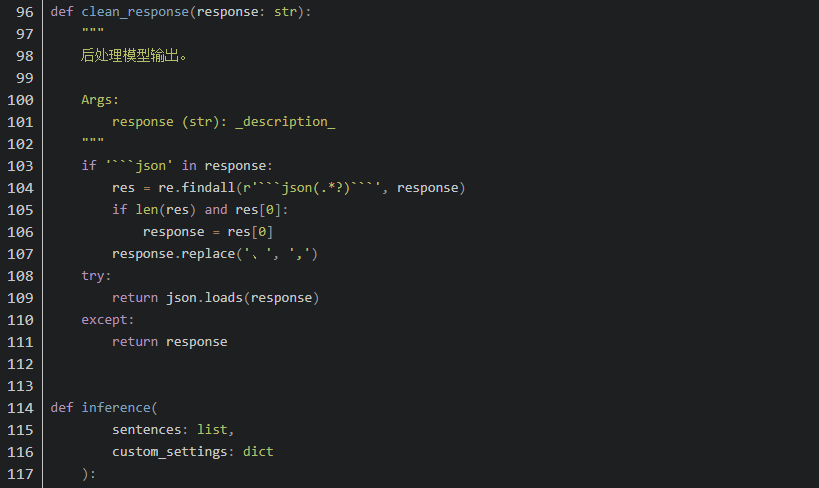
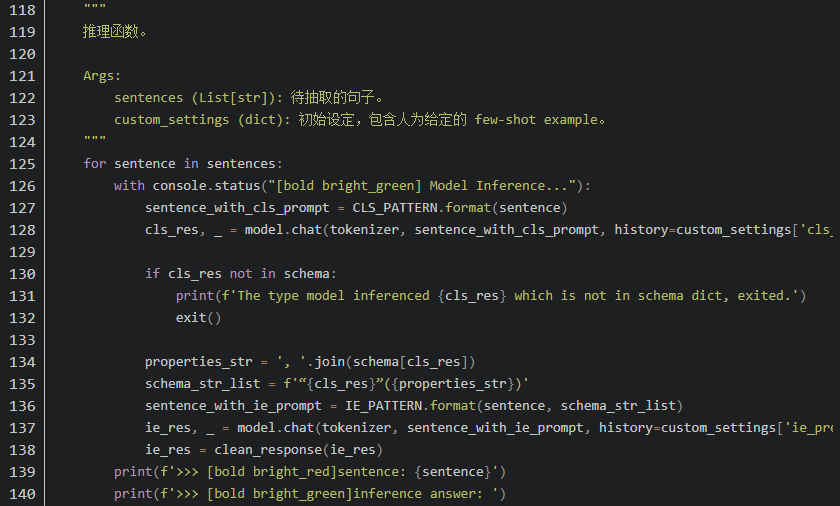
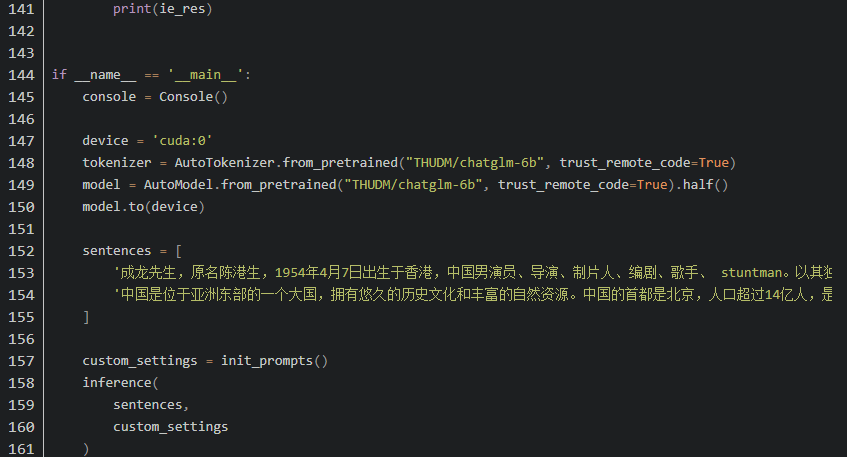
5. 优势
可以看到,我们可以不在进行繁琐的数据标注工作,另外可以用少量的数据即可带来不错的表现。
参考文献
[1]. https://mp.weixin.qq.com/s/XlY2VUR9eXeiC8lJI5Q7Nw
[2]. https://github.com/HarderThenHarder/transformers_tasks
[3]. https://huggingface.co/THUDM/chatglm-6b