【AIGC】检索增强技术深度剖析(RAG)
原创
toc
想象一下,您的公司可以使用强大的 AI 工具,该工具可以处理大量数据并提取重要结论、识别关键信息并有效地总结它。这些功能可以显着提高员工的工作效率,使他们能够专注于工作中最有价值的方面,而不是耗时的数据处理。在这种情况下,检索增强生成 (RAG) 开辟了新的视角。RAG 允许将 AI 模型与公司的特定内部数据集成,不仅可以进行处理,还可以对这些知识进行智能解释和利用。在本文中,我们将探讨如何实现这一点。
一、检索增强定义
RAG 是一种技术,它允许通过从大型文档数据库中实时检索信息来扩展预训练语言模型的知识。
用于查询机器学习模型的基本提示架构如下所示:
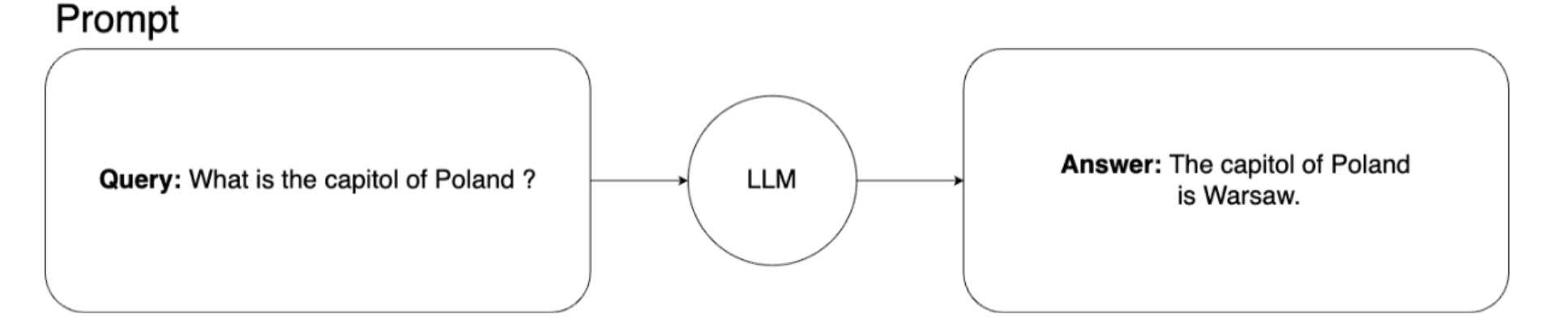
在这种情况下,我们向机器学习模型询问波兰首都的情况。这是常识,我们的模型对答案没有问题。
二、深度使用检索增强
想更深入地了解这个简单的例子吗?比方说,我们想要一个机器学习模型,可以回答有关我们从未出版过的 300 页原始书《我的故事》情节的问题,该书的唯一来源是我们私人笔记本电脑上的.pdf文件。因此,模型不可能在训练期间接触到这本书,也不可能在其他地方找到有关它的任何信息。
如果我们向学习模型询问这个故事,模型无法回答。这是它的样子:
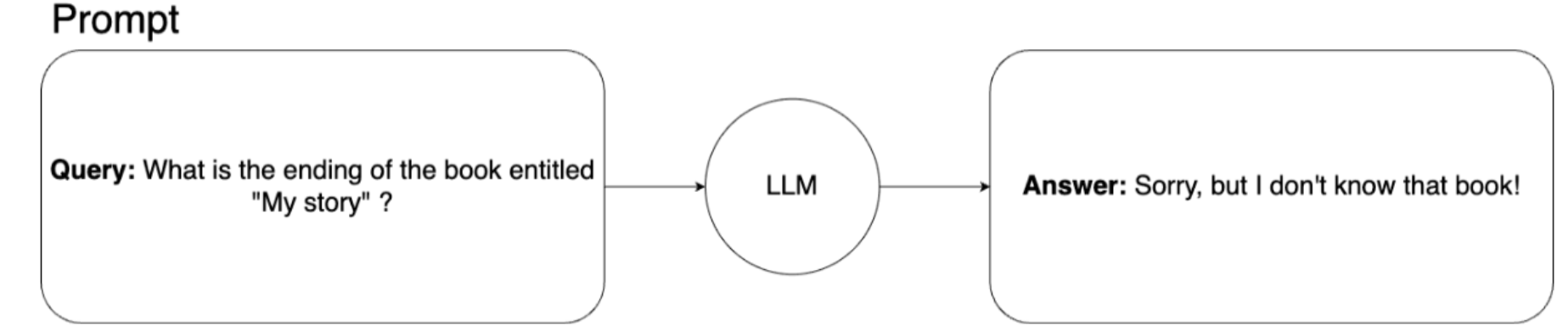
在这种情况下,检索增强生成 (RAG) 就派上用场了。我们可以通过向提示添加上下文信息来简单地扩展机器学习模型的知识。
从理论上讲,它如下所示:
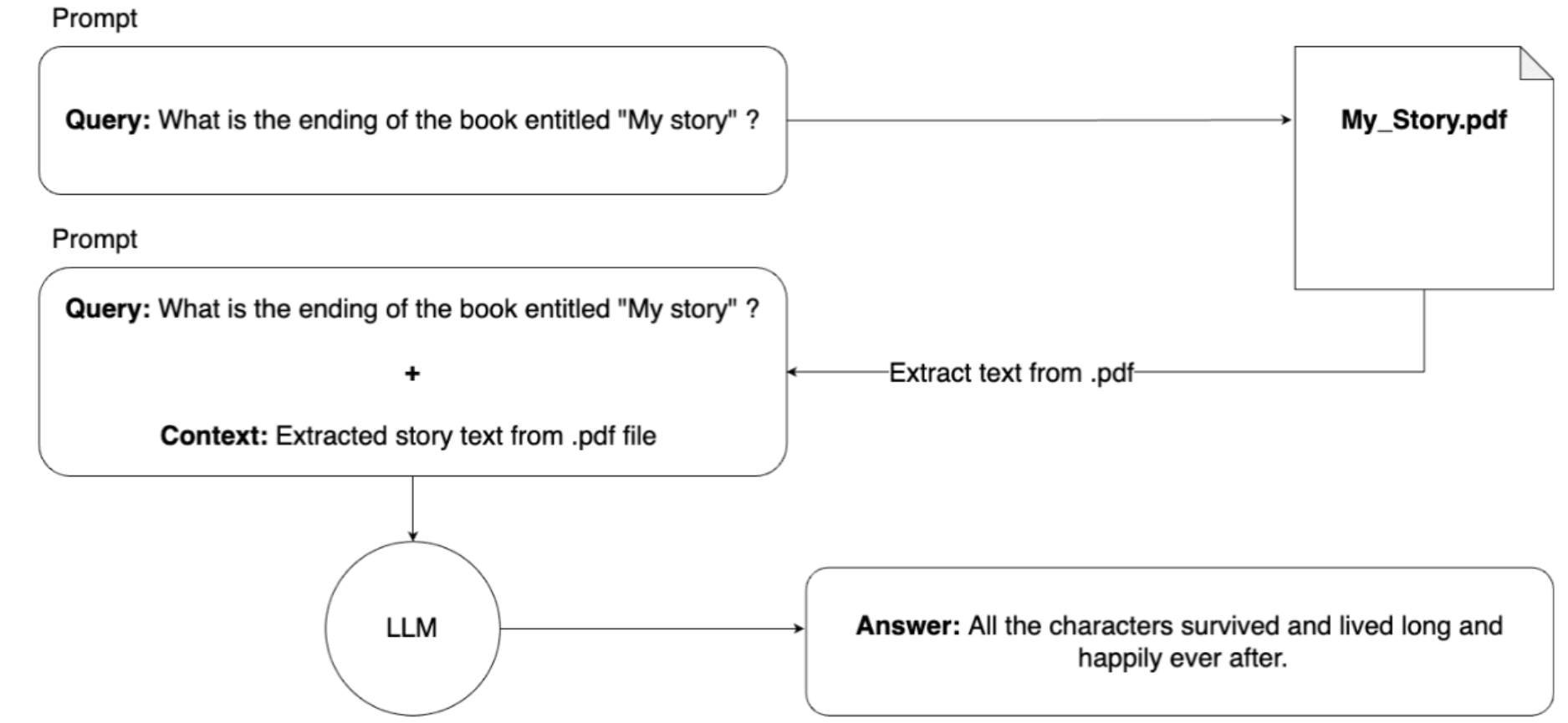
从理论上讲,它会起作用。该模型会收到我们的查询以及整本书,因此它现在知道了故事并可以回答我们的查询。但是,此解决方案存在实际问题。
我们可以在一个提示下使用的令牌数量是有限的。例如,对于 ChatGPT-4,此限制为 8192 个代币;即使是 GPT-4 Turbo,限制也是 128,000 个代币。
假设我们书中的一页平均有 500 个单词。300 页乘以 500 字等于整本书的 150,000 字。我们应该记住,使用的令牌数量由提示查询、提示上下文和机器学习模型的答案组成。

仅上下文就相当于 150,000 个令牌。通过添加提示查询和机器学习模型的答案,总数将更高。即使可以发送这样的提示,也只是浪费资源和金钱。我们不需要本书的整个上下文来回答我们的问题。
很明显,我们需要将我们的书分成几块,对于提示的上下文,只附加那些与我们的问题相关的块。将文本分成块是一项简单的任务,但是我们如何确定哪些部分是获得查询答案所必需的呢?
在这里,将文本表示为数字向量(称为嵌入)的技术派上了用场。在另一篇博文中,您可以了解有关嵌入工作原理的更多详细信息。
现在,只要理解嵌入是一种将文本转换为数字向量的技术就足够了,这些数字向量保留了转换后句子的含义。根据句子的含义,这些向量位于向量空间中的特定位置。所以,现在我们知道,在运行我们的提示之前,我们必须首先准备数据(在我们的例子中是书),方法是将其分成块,使用嵌入技术将它们转换为数字向量,并将它们保存在向量数据库中。
此过程如下所示:
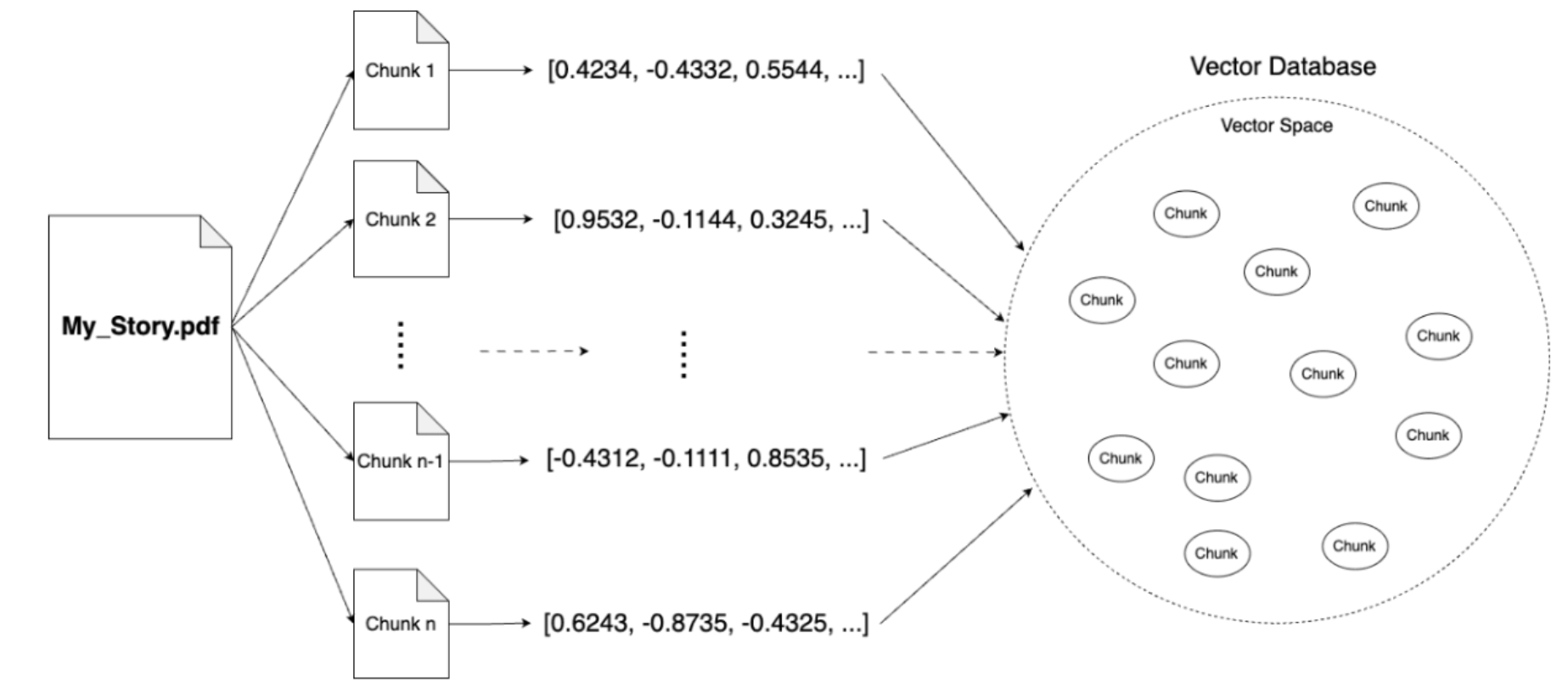
我们已经准备好了我们的数据,以便我们可以很容易地准确地找到书中对我们的查询有用的部分。
有了这些知识和准备好的数据,让我们再次开始从机器学习模型中获取答案的过程。下图描述了在此过程中执行的所有步骤。
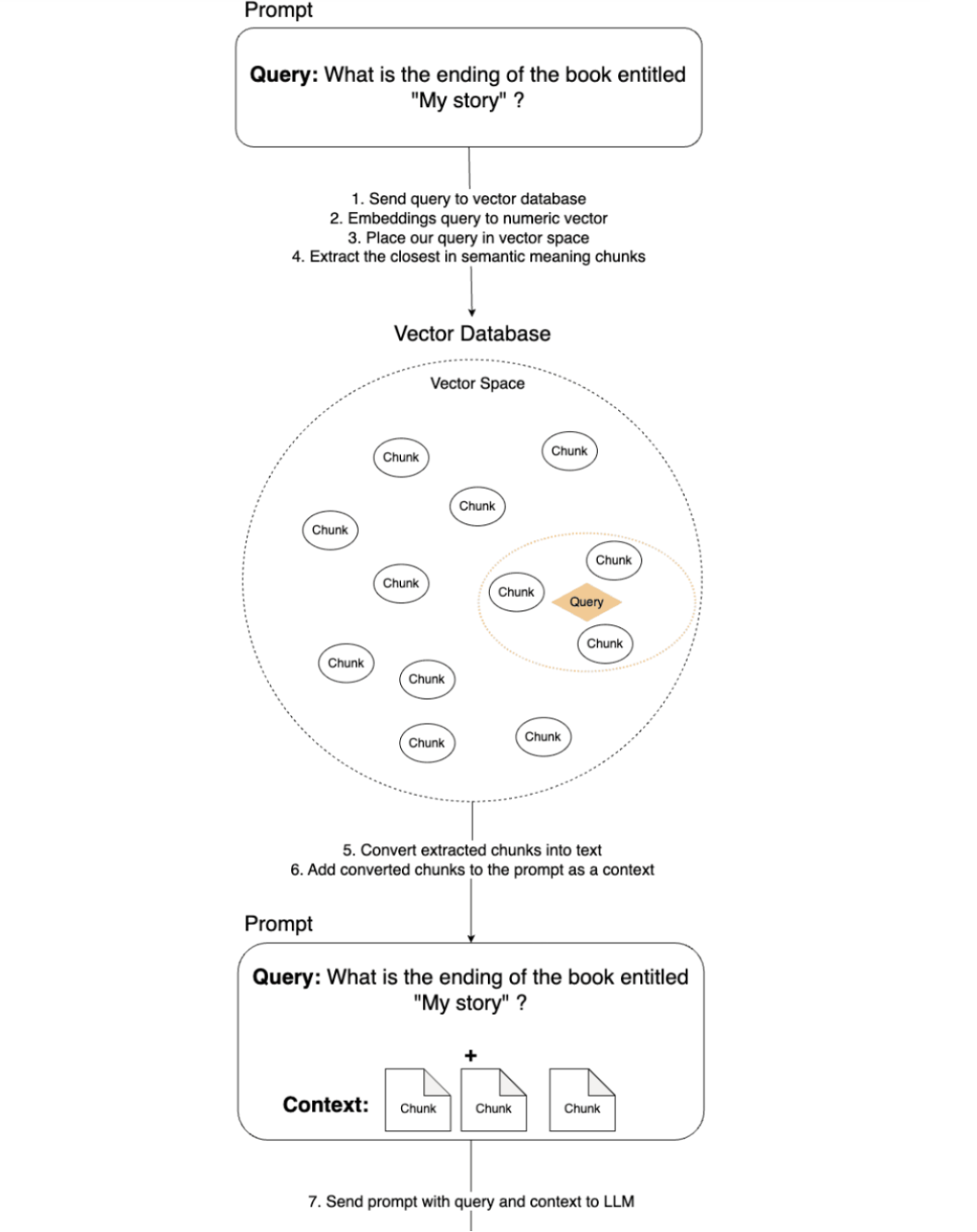
小节
本节我们学习了检索增强,我们知道了什么是检索增强,我们为什么需要检索增强以及检索增强构建思路,后面章节我们会专门整理出来检索增强服务的构建过程,大家敬请期待吧。
小编是一名热爱人工智能的专栏作者,致力于分享人工智能领域的最新知识、技术和趋势。这里,你将能够了解到人工智能的最新应用和创新,探讨人工智能对未来社会的影响,以及探索人工智能背后的科学原理和技术实现。欢迎大家点赞,评论,收藏,让我们一起探索人工智能的奥秘,共同见证科技的进步!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。