最强MOE开源:Mixtral 8x22B 发布!
最强MOE开源:Mixtral 8x22B 发布!

权重地址:https://huggingface.co/mistral-community/Mixtral-8x22B-v0.1
根据上传时间发现是一周之前,在Llama3正式放出来之前抢一个热度。
根据网站开放的信息,我们有如下信息:
Mixtral 8x22B 是我们Mixtral 的开放模型。它为人工智能社区设定了性能和效率的新标准。这是一个稀疏的专家混合(SMoE)模型,仅使用141B中的39B活动参数,为其规模提供了无与伦比的成本效率。Mixtral 8x22B 具有以下优势:
- 它能够流利地使用英语、法语、意大利语、德语和西班牙语。
- 它具有强大的数学和编程能力。
- 它具有本地函数调用能力;结合在 La Plateforme 实施的受限输出模式,这使得可以大规模进行应用开发和技术栈现代化。
- 它的64K令牌上下文窗口允许从大型文档中精确地回忆信息。
- 真正开放 我们相信开放和广泛分发的力量,以促进人工智能领域的创新和合作。因此,我们根据 Apache 2.0 许可,这是最宽松的开源许可,发布 Mixtral 8x22B,允许任何人在任何地方无限制地使用该模型。
效率之最我们构建的模型为各自的规模提供了无与伦比的成本效率,提供了社区提供的模型中最佳的性能-成本比。
Mixtral 8x22B 是我们开放模型家族的自然延续。其稀疏激活模式使其比任何密集的70B模型更快,同时比任何其他开放权重模型(在宽松或限制性许可下分发)更有能力。基础模型的可用性使其成为微调用例的优秀基础。
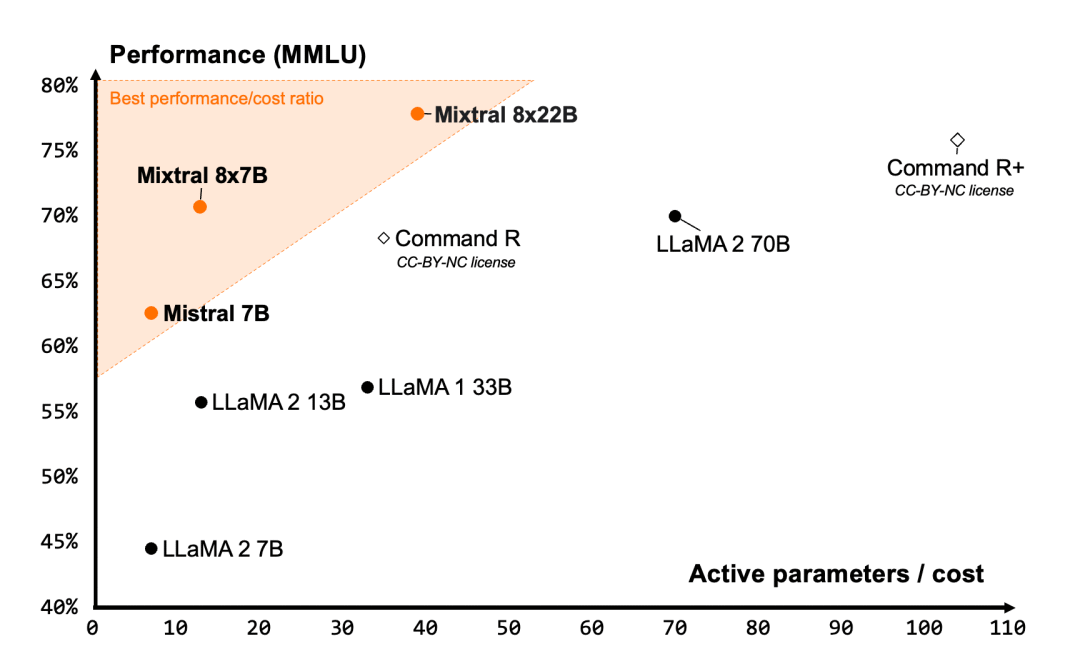
图1:性能(MMLU)与推理预算权衡(活动参数数量)的度量。Mistral 7B、Mixtral 8x7B 和 Mixtral 8x22B 都属于与其它开放模型相比高度高效的模型家族。
无与伦比的开放性能以下是在标准行业基准上的开放模型比较。
推理和知识Mixtral 8x22B 针对推理进行了优化。
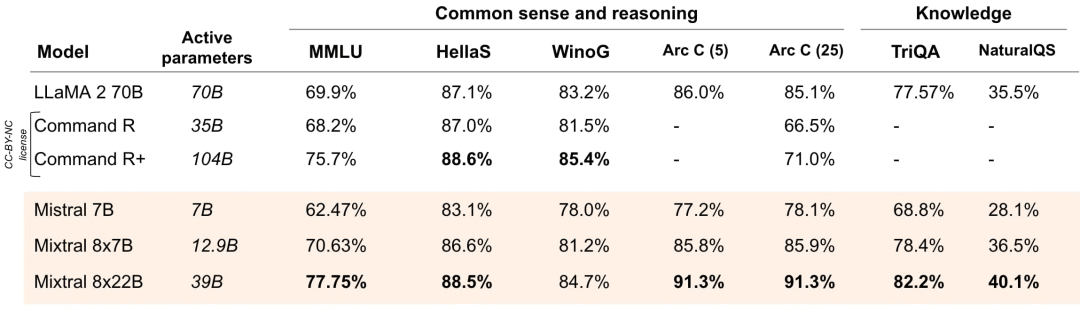
图2:在广泛常识、推理和知识基准上的性能,顶级领先的大型语言模型(LLM)开放模型:MMLU(测量大规模多任务语言理解)、HellaSwag(10次射击)、Wino Grande(5次射击)、Arc Challenge(5次射击)、Arc Challenge(25次射击)、TriviaQA(5次射击)和 NaturalQS(5次射击)。
多语言能力Mixtral 8x22B 具有原生的多语言能力。在法语、德语、西班牙语和意大利语的 HellaSwag、Arc Challenge 和 MMLU 基准测试中,它的表现大大超过了 LLaMA 2 70B。

图3:Mistral 开源模型与 LLaMA 2 70B 在法语、德语、西班牙语和意大利语的 HellaSwag、Arc Challenge 和 MMLU 的比较。
数学 & 编程与其他开放模型相比,Mixtral 8x22B 在编程和数学任务中表现最佳。

图4:在领先的开放模型上的流行编程和数学基准测试性能:HumanEval pass@1、MBPP pass@1、GSM8K maj@1(5次射击)、GSM8K maj@8(8次射击)和 Math maj@4。
今天发布的 Mixtral 8x22B 的指导版本展示了更好的数学性能,在 GSM8K maj@8 上得分为90.8%,在 Math maj@4 上得分为44.6%。
使用方法
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistral-community/Mixtral-8x22B-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
text = "Hello my name is"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
半精度加载
+ import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistral-community/Mixtral-8x22B-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
+ model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.float16).to(0)
text = "Hello my name is"
+ inputs = tokenizer(text, return_tensors="pt").to(0)
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))flashattention2支持
+ import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistral-community/Mixtral-8x22B-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
+ model = AutoModelForCausalLM.from_pretrained(model_id, use_flash_attention_2=True)
text = "Hello my name is"
+ inputs = tokenizer(text, return_tensors="pt").to(0)
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))