端到端自动驾驶:数据、方法与展望

作者:Qijie Zhao
转载自:气节说
编辑:郑欣欣@一点人工一点智能
原文地址:端到端自动驾驶:数据、方法与展望
00 前言
“端到端”,可以说是神经网络战胜传统算法的最重要法宝。一个训练好的神经网络,只需要部署在一个接受输入数据的模块里面,就可以直接输出该任务的最终结果,曾经让目标检测、语义分割、关键点检测等计算机视觉(现在已经不限于视觉了)无论是精度、速度还是模块本身的部署都有了划时代的进展。
自动驾驶领域的研究者也一直在推进端到端的进展,但是因为自动驾驶的复杂性和对安全的高度要求,落地是非常困难的,所以几乎所有自动驾驶公司都不会在研发中考虑端到端的方式,而是分成了导航、定位、感知、预测、规划、控制等多个模块,然后按上下游的顺序来处理。
但无需悲观,如果遵从马斯克的第一性原理,我们是否可以重新来讨论这个问题呢?这篇文章主要讨论端到端自动驾驶,围绕其对数据的要求、所涉及到的方法和对未来的展望来讲解。
01 端到端
“图像目标检测”,是计算机视觉领域里最受关注的任务之一。现在(至2023年)已非常多精度与速度并重的前沿方法,让我们回顾一下,其爆发式浪潮起源于RCNN[1] -> Fast RCNN[2] -> Faster RCNN[3]三部曲的进展。在更早之前,目标检测任务包含:通过聚类、组合等传统算法获取候选区域(比如Selective Search[4]),提取正负样本并算出其区域特征,然后用SVM等分类器来进行分类,最后使用非极大抑制方法保留最终的结果,其训练过程如下图所示。
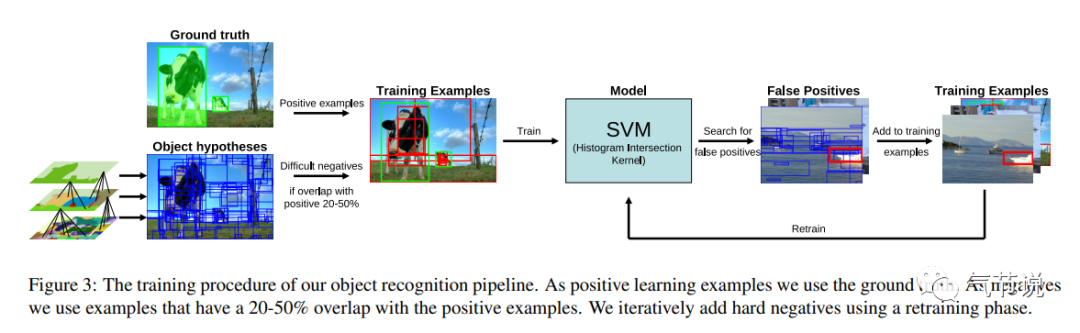
后来神经网络发展让图像识别(即图像分类)突飞猛进,RCNN替代了上述步骤里的特征提取过程、Fast RCNN进一步替代了分类器,Faster RCNN则又是进一步替代了获取候选区域的算法,至此为止,目标检测任务可以只通过一个神经网络结合少量的后处理代码(非极大抑制等)来完成。后来又有了SSD[5]、YOLO[6]等方法,使得神经网络可以比Faster RCNN更简洁、更端到端。再后来CenterNet[7]在神经网络的最后一层通过最大池化层,让目标检测告别了基于规则的非极大抑制,可以完成整个任务完整的端到端输出。
通过图像目标检测,我们发现,复杂任务的端到端进展并不是一蹴而就的,而是研究者们一步步走出来的路,攻克了一个个问题,最终发展的成果。然而,对于自动驾驶任务的端到端,并不能轻易的复制图像目标检测的发展路径。原因在于以下五点:
1. 自动驾驶的输入数据非常多,而且是多模态的。自动驾驶已经发展数十年,众多顶级企业和天才学者以及工程师们已经总结下来,自动驾驶所需传感器数据包括:激光雷达、毫米波雷达、超声波雷达、高清摄像头、IMU、GPS以及V2X等。这些数据来自不同的坐标系,带有不同的触发时间戳。以及要考虑到硬件损坏等问题时,如此多的输入数据,对于自动驾驶而言,放在一个端到端的网络里是极其困难的一件事。
2. 自动驾驶是一项安全性要求非常高的任务,所以我们对其输出精度和速度都有着非常严苛的要求。通常情况下,自动驾驶要求的最低处理频率是10Hz,也就是说整个网络在运行一次所需要的时间不能超过100ms,这对于目前尚能支持车端量产的计算芯片而言,算力要求非常之高。这一点也说明,自动驾驶的端到端落地,也需要硬件的发展来支持。
3. 自动驾驶的软件系统输出是给车轮的控制信号,这个信息并不是一个确定的真值,绝大多数时候,它应该是一个概率分布,或者说是一个多标签的概率分布。举个例子:面对会车(两车道变一车道)的情况、本车是选择让旁边车道的车先走,还是抢在其之前走,司机本身也是有两个选择的。而当前情况下的概率分布真值又很难获得,这又非常依赖大规模数据的积累和数据真值的清洗,总之,要获取端到端自动驾驶任务的标签,是非常困难的。
4. 自动驾驶需要导航。自动驾驶的路径规划大体可以分为导航和局部规划两部分,而导航是否应该包含进端到端的神经网络,该神经网络的输出是否应该包含规划的路线。如果从最终的形态来思考,那肯定要包含在一起的。这里的难点在于:a.使用神经网络来做路径规划尚未成熟;b.预测路径规划肯定需要地图和定位作为输入,尤其是地图数据作为神经网络的输入,无疑又进一步增加了其网络参数的复杂度。
5. 端到端任务的模型更新容易出现衰退。众所周知,神经网络的更新升级伴有非常大的不确定性因素,旧模型表现好的数据,极其可能在新的模型上出现衰退,虽然大多数数据会表现更好。这个问题,在实验中可以被暂时忽略,我们可以暂时只关注总体趋势。但是在自动驾驶任务里,这是不能承受的,工程师们可能会频繁的拆东墙补西墙,同时这也会影响产品化的进展。

端到端自动驾驶面临诸多挑战,确实让企业望而却步,几乎没有企业会投入过多精力做这件事,基本只有学术界和一些研究机构在追踪。记得2017年的时候,有幸和当时的明星自动驾驶创业公司的技术负责人聊起过端到端自动驾驶,大牛给我的回复是说,端到端自动驾驶是不可靠的,不会在真实场景中被采用。
六年过去了,这个结论现在依然可以这么讲。如果对未来抱有足够的信心,我们不妨激进地去展望这项技术的发展,就像曾经打败塞班系统的安卓系统横空出世,就像L2L3技术已然大面积落地,就像最近的英伟达抢占曾经的龙头mobileye的车端芯片市场,更别提最近大火的ChatGPT。
从技术上来讲,最近两年,随着特斯拉的视觉大模型带来的热潮、大规模语言模型在自然语言理解领域的强势进展(ChatGPT中的LLM技术[8])以及强化学习的发展(ChatGPT中的RLHF技术),端到端自动驾驶又吸引了一些关注点。我本人也注册了CVPR2023,希望去参与其中一个端到端自动驾驶的workshop和领域里最前沿的学者们进行讨论。
02 数据
熟悉神经网络的同学们都知道,数据是神经网络的源泉,在工业落地中,数据的重要性比神经网络方法本身更大。任何神经网络的开发工程,都离不开数据的采集工作。很多研究者在一些常用Benchmark(比如nuscenes[9]等数据集)上有了很多关于神经网络方法的探索,但是因为神经网络在领域适应性上的问题,其落地实测时的领域偏差要求我们必须要采集大量的实测数据集。这个篇章讨论对于端到端自动驾驶所需训练数据的话题。
端到端自动驾驶首先要面临的第一个问题,就是定位。自动驾驶的定位一般是采用融合定位的方法,即GNSS+RTK+传感器数据(有时结合感知)匹配地图的多源融合定位,一般用卡尔曼滤波即可,不需要神经网络就可以达到不错的精度。定位模块一般是独立出来的,强行同其他模块(比如感知、规划和控制等)合进一个神经网络是很困难的,也是没有必要的。那么事情是否陷入了一个困局而无解呢?
依据马斯克的第一性原理,我们深入思考定位模块的作用:定位对于自动驾驶是否是全链路必须(即没有定位是否完全无法做自动驾驶了)的?其实包括工业界和学术界都在近几年提过类似的话题,即重感知,轻地图。
这个思路也是自动驾驶发展到中后期,大家不得不讨论的一个问题,因为扩展自动驾驶的测试路段后会面临地图数据出现变化、甚至要覆盖无地图的场景等。也因此,端到端自动驾驶的可行性也可以去讨论。也就是说,端到端自动驾驶是在“重感知,轻地图”这样一个设定下,去思考的,而如果采用对地图和定位的强依赖的技术路线,现阶段是不可能研发出端到端自动驾驶的。
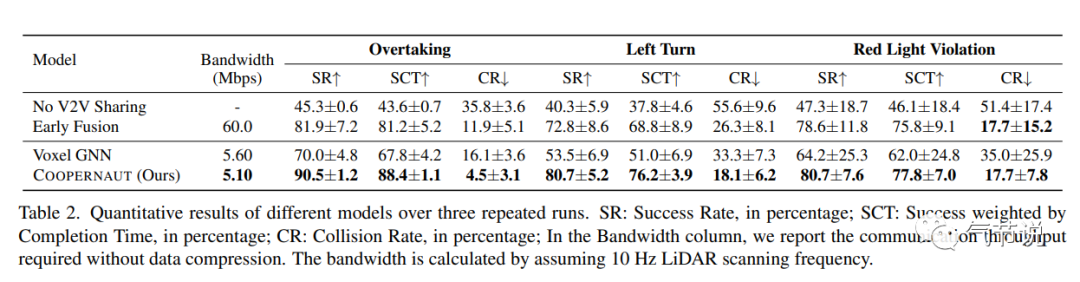
最近的一些端到端自动驾驶的方法,比如Transfuser[10],就是直接利用每帧数据里的摄像头数据和激光雷达数据来输出目标点位置(再通过控制模块转成轮毂数据发出),比如Coopernaut[11],只利用激光雷达一个传感器来隐式地学习出周边其他车辆的交互信息,并最终输出轮胎转速和刹车等信号给到轮毂电机模块。从这些论文里看到的测度表现结果,不用说是肯定远不如最前沿自动驾驶企业的实测表现的,这也说明还有很长的路要走,下图是Coopernaut里的metric截图。
回到“数据”这个话题来。虽然如前文所述,端到端自动驾驶是不应该依赖显式的定位的,但是我们需要准备的数据里还是需要包含定位信息的。定位数据存在的好处:
1. 做数据分析的时候,可以结合定位信息去进一步分析路况特征。
2. 定位数据可以给模型提供额外的监督信息,以帮助多元化地搭建神经网络,比如连续帧数据下的位移真值。
3. 定位信息结合地图,可以提供车道线等数据的真值,而这些信息同样可以作为神经网络的额外监督信息。
这是我想强调的一点,也是非常重要的一点,虽然是研究端到端自动驾驶,但还是应该基于搭建全链路的自动驾驶架构之后,能够获取完整的地图、定位、传感器数据以及感知结果等,才可以更好的去开发端到端自动驾驶模型。否则,仅仅是基于传感器数据,比如激光雷达和图像(大多数学术论文都是如此),我觉得是巧妇难为无米之炊。这个观点的下一个结论就是,只有成熟的自动驾驶公司,在余有精力的情况下,适合研究端到端自动驾驶,因为他们有更丰富和更全面的数据,而一般的学术单位只能在极少量开源数据集里面去做有限的事情。
这里不得不提到一个开源数据集,即nuscenes。这个数据集在近几年催生出了很多前沿的算法,比如纯视觉BEV的一系列论文,激光雷达和摄像头前后融合等方法的探索等。
想要开发端到端自动驾驶,最起码的是要准备一份类似于nuscenes这样的数据集,当然数据规模需要再大几个数量级。其包含地图信息、精准的定位信息、做好了时序对齐和坐标系对齐了的各个传感器数据,而这样数据的准备工作,最前期是离线研发的过程,而且每个模块都包含着一定的工作量。因为中间阶段要生成各类信息,比如一些中间的感知结果(车道线、行人和车辆等),也有了专门做离线感知的任务。Nuscenes提供了丰富的api,可以查看详细的数据细节,这同样是非常重要的步骤,因为可视化、数据检查也是我们作为研发人员大量需要做的工作。
03 方法
端到端自动驾驶,一定是基于3D感知的,激光雷达天然是3D位置的数据,而摄像头的数据需要通过坐标系投影的方式,转到3D空间中,这也是最近一两年受人关注的Camera BEV讨论的问题。一个能给出足够精准结果的端到端自动驾驶神经网络,一定是具备以下部分的:
1. 输入的传感器数据足够丰富。包括摄像头、激光雷达、毫米波雷达等。这三个传感器需要选定一个作为参考坐标系,一般会选择激光雷达,毫米波雷达的数据可以直接利用其相对激光雷达的pose进行矩阵乘法转至激光雷达坐标系,而摄像头的数据,则是通过一些神经网络层之后,显式(通过内外参)或隐式(通过transformer)地转到激光雷达的坐标系。有时我们也会使用超声波雷达,但是超声雷达一般是1维信号,结合其部署的位置,可以拓展成带位置的1维信号,可以在神经网络比较深层的位置去和其他传感器数据进行后融合。
2. 传感器的特征融合。从后往前看,这个神经网络最终的输出信息一般是转速和角速度,而这两个数据来自于更前面的特征,也就是前文所提到的3D空间的特征,那么这个特征需要融合足够多的传感器数据,才可以更完备地表达车辆周围的环境信息。
3. 时序模型。当前时间戳下,网络的输出,一定不仅取决于当前帧的传感器数据,而且也要结合上一帧的特征、上一帧的决策信息(控制信号)。因为自动驾驶面对的不只是场景复杂,而且需要考虑前几秒,甚至前半分钟的“所见所闻”。
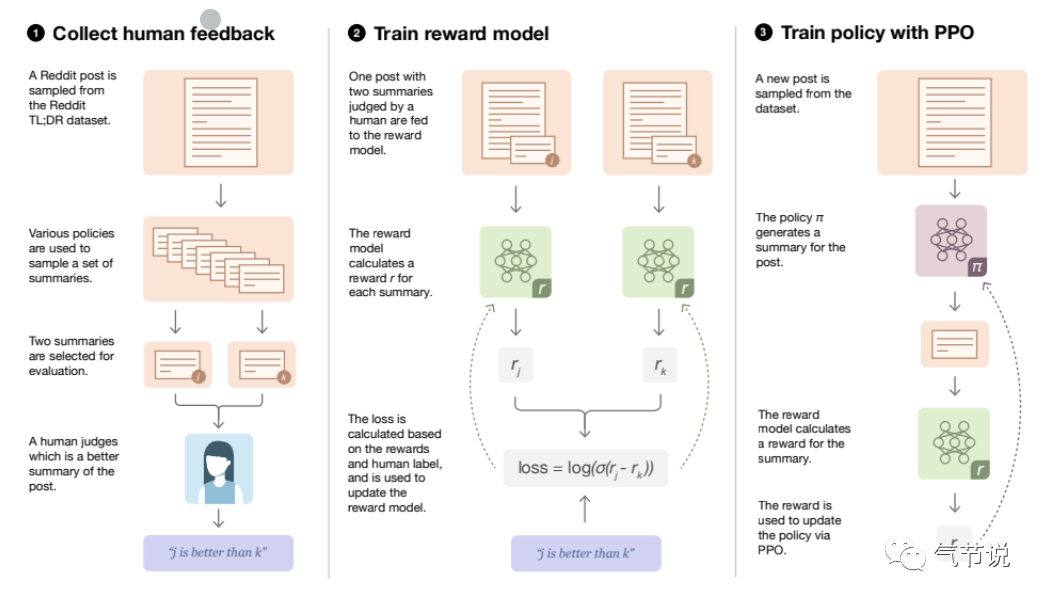
4. 强化学习。为什么说强化学习是必须的?这里指的是对于网络显式或隐式地处理规划问题所需要的解决方法。规划的解决方法可以分为三类,包括建模成优化问题、建模成卷积神经网络和建模成强化学习的架构。虽然绝大多数自动驾驶公司都采用的优化问题求解,但是不得不面对的是需要对不同的场景建立不同的优化方程,这种做法本身就决定了几乎不能被设计成端到端的神经网络。建模成卷积神经网络来解决规划问题,比如VectorNet这类网络,虽然可以实现端到端,但是卷积神经网络的特征编码特性(逐渐推理成一个概率分布)会破坏自动驾驶场景中的交互性,这就使得我们必须要收集无限多的数据,并且让神经网络全部学习,才能做得足够好。从其他领域来参考,RLHF(基于人类反馈信号的强化学习,如下图所示)已经在chatgpt上取得了巨大的成功,这让我们很自然的想到,RLHF这个idea能成功解决交互性问题(包含逻辑处理的决策性问题)是否可以来帮助解决自动驾驶问题。
这将是一个非常大的模型,包含多模态的输入和多任务的输出,包含多个特征编码结构(比如对于图像和点云数据的骨干网络),多个transformer结构进行特征融合,以及比如LSTM这样的时序编码结构。在网络的训练阶段,除去网络的输出层需要给监督信号以外,也需要对中间层的输出进行监督或弱监督。在部署的时候,因为模型过大,还需要做模型蒸馏、量化等操作进行加速。
04 实践
端到端自动驾驶的实际落地,一定不会是突然就实现了。如前文引用图像目标检测领域里的FasterRCNN的发展,这件事情一定是会渐进式地发展。从最近的一篇论文UniAD[12]借用一幅图来展示自动驾驶几个主要模块的上下游关系,以及如何整合进一个模型,如下图所示:
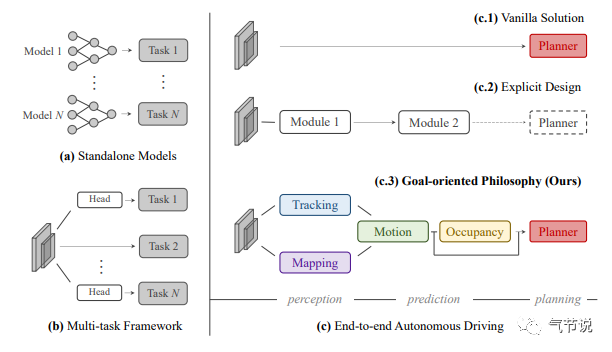
我们看图c.3,输入的传感器数据经过感知、预测和规划模块后进行输出,这个方法显然是实现了这三个模块的端到端。网络最终输出一系列ST(space-time)点给到下游独立的控制模块,控制模块再计算出自车速度和角速度等信息,给到小车底盘。这其实以及迈出了一大步了,对比早期我们需要单独研发2D目标检测、3D目标检测、目标识别、目标追踪等神经网络模型。这篇论文就是基于“重感知,轻地图”的理念而设计,所以没有把地图作为输入,甚至为了轻便(和硬件成本)连激光雷达都没有用上。从方法的验证测度(metric)也可以看出一些有意思的事情,主要是用离目标规划路径的平均距离(L2)和碰撞率(collision rate)来作为参考,这些还离L4真实的反馈指标(乘坐体验舒适度、路径规划是否合理等)有较远的距离,不过这肯定还不是现阶段端到端自动驾驶需要考虑的问题。特斯拉把感知和预测做到了一个模型上,这引发了大家推进端到端自动驾驶,UniAD则是更进一步把规划也做进了同一个神经网络模型。
在此框架下(感知、预测、规划同在一个模型里面),应该还有能预见的调优工作,并且一些企业内部可能会发展的更靠前,这样的神经网络模型一旦调到差不多的水平之后,可以通过不断收集数据来提升其精度,直至超越现有的多链路框架(即感知、预测、规划分开为3个步骤),当然我觉得这不是一件容易的事情,不过却是理论上可行的。
再近一步,可以把传感器的数据预处理也包含进神经网络,比如摄像头的ISP和undistortion、激光雷达点云栅格化和去重等。特斯拉2021年的AI day里Andrej Karpathy就展示过特斯拉的做法,可以让神经网络端到端地学习。
再近一步,可以把控制模块也做进神经网络,最近两年也有一些工作,比如机械臂的控制,用时序神经网络(比如LSTM)来代替PID的工作。所以这件事情也是理论可行的,如果是基于UniAD来做这件事,则可以很快实现一个二阶段的端到端神经网络。
再近一步,就是把地图数据作为神经网络的输入,每帧都会输出当前帧的规划路径,这件事的难点在于地图数据的编码(encoder),以及地图数据非常大之后的计算量问题。通常情况下,多链路的自动驾驶系统里面,导航路线的计算并不会每帧都执行,而是在一开始执行一次,所以可以容忍一次较大的计算量,但是对于神经网络而言,是否有必要因为是一个大一统的模型而被迫每帧都计算一次导航呢?这里的网络设计是需要灵活地处理的,我个人觉得是没有必要的,可以保持传统思路,全局导航只在一开始做一次,相关的神经网络部分也只推理一次,之后的每帧只需要动态的去抓取局部的地图数据做维神经网络的输入,以帮助神经网络推理出更好的局部路线,以及可以做“一定范围内的重新规划路线”。
也许到了这里,可以说得上是基本实现了端到端的自动驾驶了。从组成模块上来看,这是一个非常大的工程,需要从数据、架构、算法、测试等多个部分合作完成,不断调优,不断精进。OpenAI一百多位天才研究员实现了ChatGPT,不知道自动驾驶的端到端会被一个什么样的团队完成首次突破呢?
05 展望
前些天Sam写了他对通用人工智能(AGI)的畅想和未来计划,在7年前AlphaGo刚出来时,即便是作为从业者,我也觉得这离通用人工智能还相差十万八千里,而如今ChatGPT却让我们真的看到了实现的可能。那么再近一步,ChatGPT离AGI还有多少距离?在我看来,其实就是配以传感器数据为输入的感知和预测等技术些技术结合ChatGPT,机器就可以实现自动获取、理解、思考、生成、输出等工作,成为一个个活生生的人。当下看来,这也是极其可能会实现的。
端到端自动驾驶,只是实现自动驾驶的最理想的技术方案,带有研究者的理想主义情感。那么,未来自动驾驶真正实现的那一天,他能解决各种长尾问题、难例问题甚至伦理问题的时候,内部是怎样实现的呢?这是一个非常有意思的问题。
本文系转载,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文系转载,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。