统计机器学习方法 for NLP:基于CRF的词性标注
统计机器学习方法 for NLP:基于CRF的词性标注

知乎: nghuyong 链接: https://zhuanlan.zhihu.com/p/523164712
前言
最近在重刷李航老师的《统计机器学习方法》尝试将其与NLP结合,通过具体的NLP应用场景,强化对书中公式的理解,最终形成「统计机器学习方法 for NLP」的系列。这篇将介绍条件随机场CRF(绝对给你一次讲明白)并基于CRF完成一个词性标注的任务。
CRF是什么
条件随机场(Conditional random field, CRF)是一个NLP领域广泛使用的模型,即使在深度学习时代也是如此。尤其在序列标注任务上,DNN+CRF依然是目前最主流的范式。 CRF是一个判别式模型,通过训练数据直接学习输入序列X和对应的标签序列Y的条件概率P(Y|X)。相比于逻辑回归(Logistic Regression)的分类,CRF能学习到标签之间的序列关系来辅助分类。例如在词性标注任务中,如果之前上一个词的词性是「动词」,那么当前词的词性就很小的概率依然是「动词」,因为「动词」后面继续跟「动词」是小概率事件。
马尔可夫随机场
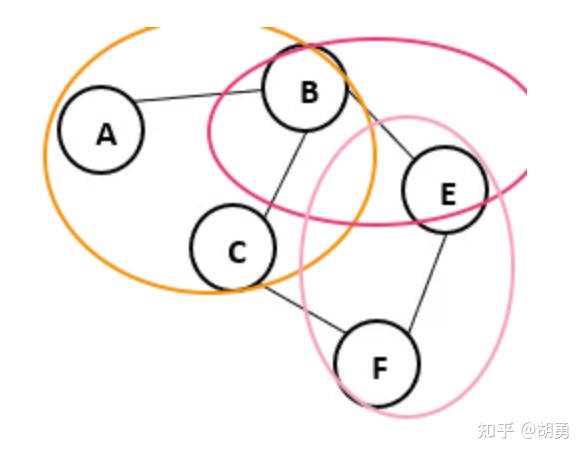
条件随机场CRF中的随机场指的是马尔可夫随机场。马尔可夫随机场满足马尔可夫随机性,即节点v上的随机变量Y_v只与跟节点v直接相连的节点有关。所以我们就可以把一个无向图上随机变量进行因式分解,写成「最大团」乘积的形式。这里「最大团」指的是一个子图C中的任何两个节点都有边相连(这就是「团」),并且在这个子图C上不能再添加一个新的节点使其构成一个更大的团。例如下图中的{A,B,C}就是一个最大团。

线性链条件随机场
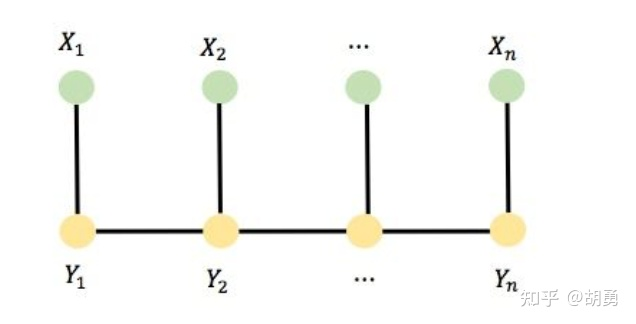

再进一步,我们可以将这两类最大团合并进行形式上的简化, 所以可以写成下面的形式:
这就是线性CRF最终推出的公式了!!!
额外补充
「特征函数」:可以看到特征函数与4个变量有关: (1) 整体的观测变量 X
(2) 当前位置 i
(3) 当前的隐变量 y_i
(4) 前一个隐变量 y_{i-1} 。所以在词性标注的例子中, 整体的观测变量就是输入的句子 s, 当前位置就是当前的单词w , 当前的隐变量就是当前的位置的词性标签 \operatorname{tag}_i , 前一个隐变量就是前一个单词的词性标签 tag_{i-1} 。这时候我们就可以定义特征函数,例如:如果句子的结尾是问号, 当前的单词为第一个单词, 且当前单词的词性为动词, 那么函数输出为 1 , 否则为 0 。如果这个特征函数的权重越大, 说明这种范式越正确, 即问句的第一个词的词性是动词的概率较大, 比如: "吃饭了吗?"
「与HMM的关系」: HMM在之前的文章中专门介绍过, 具体参见: 统计机器学习方法 for NLP: 基于HMM的词性标注。先说结论, HMM是一种特殊的CRF。下面进行推倒, 首先对于 HMM:
写成log相加的形式:
接着我们通过定义两类特征函数就能转变成CRF的形式:

所以我们可以看到HMM是一种特殊的CRF,同时具有两方面的局限性: (1) HMM是局部特征而非全局特征,也就是没有利用X整体的特征,而CRF可以利用整个句子的全局特征; (2) HMM中的写成CRF特征函数的形式后,权重就是概率值,所以有加和为1的限制,而CRF没有系数和的限制。
模型训练与预测
在定义了特征函数之后,CRF模型本质是一个线性的模型,模型的参数就是特征函数的权重,这里可以采用「梯度下降」的方法学习模型参数。模型训练之后,预测阶段可通过viterbi算法进行解码,来获得最优的隐变量序列。
基于CRF的词性标注
词性标注任务是指给定一句话,给这种话中的每个词都标记上词性,例如动词/形容词等。例如给定句子:“I love China”, 需要输出: (I: 代词, love: 动词, China: 名词),具体可以参见HMM章节中对词性标注任务的介绍:统计机器学习方法 for NLP:基于HMM的词性标注。
下面将分为:数据处理,模型训练,模型预测 三个部分来介绍如何利用CRF实现词性标注,具体参考的是这篇工作:「NLP Guide: Identifying Part of Speech Tags using Conditional Random Fields」 。
数据处理
这里采用的数据集是:NLTK Treebank 。获取数据并切分数据集为训练集和测试集。
tagged_sentence = nltk.corpus.treebank.tagged_sents(tagset='universal')
print("Number of Tagged Sentences ",len(tagged_sentence))
tagged_words=[tup for sent in tagged_sentence for tup in sent]
print("Total Number of Tagged words", len(tagged_words))
vocab=set([word for word,tag in tagged_words])
print("Vocabulary of the Corpus",len(vocab))
tags=set([tag for word,tag in tagged_words])
print("Number of Tags in the Corpus ",len(tags))
“”“
Number of Tagged Sentences 3914
Total Number of Tagged words 100676
Vocabulary of the Corpus 12408
Number of Tags in the Corpus 12
”“”
train_set, test_set = train_test_split(tagged_sentence,test_size=0.2,random_state=1234)
print("Number of Sentences in Training Data ",len(train_set))
print("Number of Sentences in Testing Data ",len(test_set))
“”“
Number of Sentences in Training Data 3131
Number of Sentences in Testing Data 783
”“”
模型训练
首先我们手工定义一组特征函数(状态特征函数),例如「第一个字母是不是大写」,「是不是第一个单词」,「是不是最后一个单词」,「前一个单词」,「后一个单词」等,并从数据集中进行特征的抽取:
# 特征定义
def features(sentence,index):
### sentence is of the form [w1,w2,w3,..], index is the position of the word in the sentence
return {
'is_first_capital':int(sentence[index][0].isupper()),
'is_first_word': int(index==0),
'is_last_word':int(index==len(sentence)-1),
'is_complete_capital': int(sentence[index].upper()==sentence[index]),
'prev_word':'' if index==0 else sentence[index-1],
'next_word':'' if index==len(sentence)-1 else sentence[index+1],
'is_numeric':int(sentence[index].isdigit()),
'is_alphanumeric': int(bool((re.match('^(?=.*[0-9]$)(?=.*[a-zA-Z])',sentence[index])))),
'prefix_1':sentence[index][0],
'prefix_2': sentence[index][:2],
'prefix_3':sentence[index][:3],
'prefix_4':sentence[index][:4],
'suffix_1':sentence[index][-1],
'suffix_2':sentence[index][-2:],
'suffix_3':sentence[index][-3:],
'suffix_4':sentence[index][-4:],
'word_has_hyphen': 1 if '-' in sentence[index] else 0
}
def untag(sentence):
return [word for word,tag in sentence]
def prepareData(tagged_sentences):
X,y=[],[]
for sentences in tagged_sentences:
X.append([features(untag(sentences), index) for index in range(len(sentences))])
y.append([tag for word,tag in sentences])
return X,y
# 特征抽取
X_train,y_train=prepareData(train_set)
X_test,y_test=prepareData(test_set)
下面简单看一下抽取出来的特征:
[{'is_alphanumeric': 0,
'is_complete_capital': 0,
'is_first_capital': 1,
'is_first_word': 1,
'is_last_word': 0,
'is_numeric': 0,
'next_word': 'Wall',
'prefix_1': 'O',
'prefix_2': 'On',
'prefix_3': 'On',
'prefix_4': 'On',
'prev_word': '',
'suffix_1': 'n',
'suffix_2': 'On',
'suffix_3': 'On',
'suffix_4': 'On',
'word_has_hyphen': 0},
{'is_alphanumeric': 0,
'is_complete_capital': 0,
'is_first_capital': 1,
'is_first_word': 0,
'is_last_word': 0,
'is_numeric': 0,
'next_word': 'Street',
'prefix_1': 'W',
'prefix_2': 'Wa',
'prefix_3': 'Wal',
'prefix_4': 'Wall',
'prev_word': 'On',
'suffix_1': 'l',
'suffix_2': 'll',
'suffix_3': 'all',
'suffix_4': 'Wall',
'word_has_hyphen': 0},
...
]
以及对应的标签:
['ADP',
'NOUN',
'NOUN',
...
]
接着使用sklearn-crfsuite - sklearn-crfsuite 0.3 documentation 进行模型训练:
from sklearn_crfsuite import CRF
crf = CRF(
algorithm='lbfgs',
c1=0.01,
c2=0.1,
max_iterations=100,
all_possible_transitions=True
)
crf.fit(X_train, y_train)
模预预测
对测试集进行预测,并计算F1指标
y_pred=crf.predict(X_test)
metrics.flat_f1_score(y_test, y_pred,average='weighted',labels=crf.classes_)
“”“
0.9738471726864286
”“”
可以看到最终评估指标高达97.3% 表明抽取的特征很有效,CRF也是一个很强的模型。
下面看一下头部的转移特征和状态特征:
# 头部的转移特征
[(('ADJ', 'NOUN'), 4.114996),
(('NOUN', 'NOUN'), 2.935448),
(('NOUN', 'VERB'), 2.891987),
(('VERB', 'PRT'), 2.519179),
(('X', 'VERB'), 2.271558),
(('ADP', 'NOUN'), 2.265833),
(('NOUN', 'PRT'), 2.172849),
(('PRON', 'VERB'), 2.117186),
(('NUM', 'NOUN'), 2.059221),
(('DET', 'NOUN'), 2.053832),
(('ADV', 'VERB'), 1.994419),
(('ADV', 'ADJ'), 1.957063),
(('NOUN', 'ADP'), 1.838684),
(('VERB', 'NOUN'), 1.763319),
(('ADJ', 'ADJ'), 1.660578),
(('NOUN', 'CONJ'), 1.591359),
(('PRT', 'NOUN'), 1.398473),
(('NOUN', '.'), 1.381863),
(('NOUN', 'ADV'), 1.380086),
(('ADV', 'ADV'), 1.301282)]
# 头部的状态特征
[(('prev_word:will', 'VERB'), 6.751359),
(('prev_word:would', 'VERB'), 5.940819),
(('prefix_1:*', 'X'), 5.830558),
(('suffix_4:rest', 'NOUN'), 5.644523),
(('suffix_2:ly', 'ADV'), 5.260228),
(('is_first_capital', 'NOUN'), 5.043121),
(('prev_word:could', 'VERB'), 5.018842),
(('suffix_3:ous', 'ADJ'), 4.870949),
(('prev_word:to', 'VERB'), 4.849822),
(('suffix_4:will', 'VERB'), 4.677684),
(('next_word:appeal', 'ADJ'), 4.386434),
(('prev_word:how', 'PRT'), 4.35094),
(('suffix_4:pany', 'NOUN'), 4.329975),
(('prefix_4:many', 'ADJ'), 4.205028),
(('prev_word:lock', 'PRT'), 4.153643),
(('word_has_hyphen', 'ADJ'), 4.151036),
(('prev_word:tune', 'PRT'), 4.147576),
(('next_word:Express', 'NOUN'), 4.137127),
(('suffix_4:food', 'NOUN'), 4.116688),
(('suffix_2:ed', 'VERB'), 4.070659)]
根据转移特征('ADJ', 'NOUN')可以看到「形容词」后面接「名词」的概率非常高;根据状态特征('prev_word:will', 'VERB')可以看到如果上一个单词是will,那么当前词的词性为「动词」的概率非常高。
本篇的CRF还处于统计学习阶段,所以构建的特征也都是手工构建的特征,还是存在一定的局限性。所以后来在深度学习时代,一般会先用LSTM或者BERT这种深度神经网络先进行特征的抽取,再送到CRF进行标签的预测,能有更加显著的效果提升。
参考
- Introduction to Conditional Random Fields: https://blog.echen.me/2012/01/03/introduction-to-conditional-random-fields/
- NLP Guide: Identifying Part of Speech Tags using Conditional Random Fields: https://medium.com/analytics-vidhya/pos-tagging-using-conditional-random-fields-92077e5eaa31
- https://github.com/AiswaryaSrinivas/DataScienceWithPython/blob/master/CRF%20POS%20Tagging.ipynb