四种基本筛法(朴素法、埃氏筛、欧拉筛(线性筛)、区间筛法)

四种基本筛法(朴素法、埃氏筛、欧拉筛(线性筛)、区间筛法)

十二.
发布于 2025-10-22 14:47:43
发布于 2025-10-22 14:47:43
基本介绍
求素数的魅力就在于,他为编程与数学思想的组合。
在竞赛里,素数筛大有用处。快速筛选质数能高效解决数论相关题目,节省时间。在算法设计题中,可降低复杂度、优化性能。像密码学模拟题,用其找质数构建模型,助选手得分。
首先,明确素数的定义:
质数(素数)是指在大于 1 的**自然数**中,除了 1 和它本身以外不再有其他因数的自然数。—“质数(素数)百度百科”
以上可知,自然数为质数的基础,故先理清何为自然数(非负的所有整数)。
由此对自然数可做出以下分类:
1、按奇数和偶数分
2、偶数:能被2整除的数。
2、按因数个数分
1、质数:只有1和它本身这两个因数的自然数叫做质数,也叫素数。
2、合数:除了1和它本身还有其它因数的自然数叫做合数。
3、1:1既不是质数也不是合数。
4、0:0既不是质数也不是合数。
根据素数这一定义,可以提炼出几点内容:
- 质数是自然数,因此是整数
- 质数是大于1的自然数,因此小于等于1的数字都不是素数(包括负数,0和小数)
- 质数只有两个因数,1和自身
- 结合1,2,3点,可以推断出,在自然数范围内,最小的素数是2
同时根据这一定义,发展出许多计算素数的方法,以下让我一一介绍。
练习题目:X质数(蓝桥国赛)
算法
1、朴素算法
(简称试除法)也是(BF-暴力算法)
朴素算法即最为直观的算法,这里只是根据素数的定义而设计的算法,没有涉及其他方面的知识。
根据质数的定义:质数只有两个因子,1和自身。
因此如果有其他因子的数字,都不是质数,这类数字称之为合数,概念上和质数相对。
从因子这一点入手,根据因子个数的多少,判断一个数字是否为质数。
#include "iostream"
using namespace std;
bool IsPrime(int n){
if(n<=1 || n%2==0) return false; // 0、1不是质数,n如果能被2取余,代表有因子
for(int i=2; i<n; ++i){ // 经过简化,可以写成。for(int i=2; i*i<=n; ++i),经测试,到达√n即可。
// 切记,为 <= 这样
// 但不推荐for(int i=2; i<=(int)sqrt(double(n)); ++i) 这样使用,此会造成精度损失
if(n%i==0) return false;
}
return true;
}
int main(){
int n = 10;
if(IsPrime(n)) cout<<"为质数(素数)"<<endl;
else cout<<"为合数"<<endl;
}2、素数筛 - 埃氏筛
又称为(埃拉托斯特尼筛法)。
埃氏筛(简洁、背诵版):
#include <cstring>
#include <iostream>
using namespace std;
bool num[10005];
int arr_prime[10005];
int sieve(int n){
int num_prime = 0;
for(int i=2; i<n; ++i){
if(!num[i]){ // 素数就不用判断了,因为没必要
arr_prime[num_prime++] = i;
for(int j = 2*i; j<n; j+=i){ // 一般可从 int j=i 写起,枝剪操作
num[j] = true; // 为合数
}
}
}
return num_prime;
}
int main(){
int n;
cout<<"请输入,您想要的取值范围内的素数个数:"<<endl;
cin>>n;
memset(num, false,10005); // 为其分配空间,统一设为质数
// 本题也能这样写 memset(num,false,sizeof(num)); 为所有数据全分配
int i = sieve(n);
cout<<i<<endl;
return 0;
}
请输入,您想要查找的素数范围(<10000)
10000
1229埃氏筛(详细解释版):
// 引入cstring头文件,该头文件提供了一些处理字符串的函数,这里主要用于使用memset函数
#include <cstring>
// 引入iostream头文件,用于输入输出流操作,如cin和cout
#include <iostream>
// 使用标准命名空间,这样就可以直接使用标准库中的函数和对象,而无需加std::前缀
using namespace std;
// 预处理打表,技巧
// 定义一个布尔类型的数组num,大小为10005,用于标记每个数是否为合数
// num[i]为false表示i是质数,为true表示i是合数
bool num[10005];
// 定义一个整型数组arr_prime,大小为10005,用于存储筛选出来的质数
int arr_prime[10005];
// 定义一个名为sieve的函数,该函数接受一个整数n作为参数
// 函数的作用是使用埃拉托斯特尼筛法筛选出小于n的所有质数,并返回质数的个数
int sieve(int n){
// 初始化一个整型变量num_prime,用于记录筛选出的质数的个数,初始值为0
int num_prime = 0;
// 使用for循环从2开始遍历到n-1,因为0和1不是质数,所以从2开始
for(int i=2; i<n; ++i){
// 如果num[i]为false,说明i是质数
if(!num[i]){
// 将质数i存入arr_prime数组中,并将质数的个数num_prime加1
arr_prime[num_prime++] = i;
// 对于找到的质数i,将其所有的倍数标记为合数
// 从i的2倍开始,直到i*j小于n为止
for(int j = 2*i; j<n; j+=i){ // 一般可从 int j=i 写起,枝剪操作
// 将j标记为合数,即将num[j]设为true。
num[j] = true; // 为合数
}
}
}
// 返回筛选出的质数的个数
return num_prime;
}
// 主函数,程序的入口点
int main(){
// 定义一个整型变量n,用于存储用户输入的取值范围
int n;
// 输出提示信息,提示用户输入想要的取值范围内的素数个数
cout<<"请输入,您想要的取值范围内的素数个数:"<<endl;
// 从标准输入读取用户输入的整数,并将其赋值给变量n
cin>>n;
// 使用memset函数将数组num的所有元素初始化为false
// 表示初始时假设所有数都是质数
// 第一个参数是要初始化的数组的首地址,第二个参数是要设置的值(这里是false,即0),第三个参数是要初始化的字节数
memset(num, false,10005 * sizeof(bool));
// 调用sieve函数,传入用户输入的n,将返回的质数个数赋值给变量i
int i = sieve(n);
// 输出筛选出的质数的个数
cout<<i<<endl;
// 主函数正常结束,返回0表示程序成功执行
return 0;
}3、线性筛法 - 欧拉筛:
相比于埃氏筛,欧拉筛更倾向于,空间换时间
为啥会出现欧拉筛呢,因为埃氏筛存在大量被重复标记的数字,导致浪费了时间与空间。
经过数学观察:
发现每个合数都有唯一的最小质因数。例如:
- 12 的最小质因数是 2(12 = 2 × 6),
- 15 的最小质因数是 3(15 = 3 × 5),
- 28 的最小质因数是 2(28 = 2 × 14)。
若能保证每个合数仅被其最小质因数筛除,即可彻底消除重复标记。
于是便能在O(n)的时间内,成功筛出质数。
解读:i%arr_prime[j]==0为啥此时就要结束呢,因为要确保是最小的质数,一旦能被取余为0,后方的乘积,都不在是最小的质数了。
欧拉筛(简洁、背诵版)
#include "iostream"
#include "cstring"
using namespace std;
// 预处理打表
bool arr_num[10005]; // 1~10004内的数
int arr_prime[10005]; // 为质数的存储开辟空间
int sieve(int n){
int num_prime = 0;
for(int i=2; i<n; ++i){
if(arr_num[i]) arr_prime[num_prime++]=i; // 将质数存入
for(int j=0; j<num_prime; ++j){
if(i*arr_prime[j]>=n) break;
arr_num[i*arr_prime[j]] = false;
if(i%arr_prime[j]==0) break;
}
}
return num_prime;
}
int main(){
int n;
cout<<"请输入,您想要查找的素数范围(<10000)"<<endl;
cin>>n;
memset(arr_num, true, sizeof arr_num); // 初始化,全部设为素数
int num = sieve(n);
cout<<num<<endl;
return 0;
}欧拉筛(详细解释版)
// 引入标准输入输出流头文件,用于使用cin和cout进行输入输出操作
#include "iostream"
// 引入cstring头文件,该头文件提供了一些用于处理字符串的函数,这里主要使用memset函数
#include "cstring"
// 使用标准命名空间,这样可以直接使用标准库中的函数和对象,而无需加std::前缀
using namespace std;
// 预处理打表
// 定义一个布尔类型的数组arr_num,大小为10005,用于标记1到10004内的每个数是否为质数
// arr_num[i]为true表示i是质数,为false表示i是合数
bool arr_num[10005];
// 定义一个整型数组arr_prime,大小为10005,用于存储筛选出来的质数
int arr_prime[10005];
// 定义一个名为sieve的函数,它接收一个整数n作为参数
// 该函数的作用是使用欧拉筛法(线性筛法)筛选出小于n的所有质数,并返回质数的个数
int sieve(int n){
// 初始化一个整型变量num_prime,用于记录筛选出的质数的个数,初始值为0
int num_prime = 0;
// 从2开始遍历到n - 1,因为0和1不是质数,所以从2开始
for(int i=2; i<n; ++i){
// 如果arr_num[i]为true,说明i是质数,将其存入arr_prime数组中,并将质数个数加1
if(arr_num[i]) arr_prime[num_prime++]=i;
// 遍历已经找到的质数
for(int j=0; j<num_prime; ++j){
// 如果i乘以当前质数大于等于n,超出了筛选范围,退出内层循环
if(i*arr_prime[j]>=n) break;
// 将i乘以当前质数得到的数标记为合数,即设为false
arr_num[i*arr_prime[j]] = false;
// 如果i能被当前质数整除,退出内层循环
// 这一步保证每个合数只会被它的最小质因数筛去,避免重复筛选,实现线性时间复杂度
if(i%arr_prime[j]==0) break;
}
}
// 返回筛选出的质数的个数
return num_prime;
}
// 主函数,程序的入口点
int main(){
// 定义一个整型变量n,用于存储用户输入的查找素数的范围
int n;
// 输出提示信息,提示用户输入想要查找的素数范围,要求范围小于10000
cout<<"请输入,您想要查找的素数范围(<10000)"<<endl;
// 从标准输入读取用户输入的整数,并将其赋值给变量n
cin>>n;
// 使用memset函数将数组arr_num的所有元素初始化为true
// 表示初始时假设所有数都是质数
// 第一个参数是要初始化的数组的首地址,第二个参数是要设置的值(这里是true,即1),第三个参数是要初始化的字节数
memset(arr_num, true, sizeof arr_num);
// 调用sieve函数,传入用户输入的n,将返回的质数个数赋值给变量num
int num = sieve(n);
// 输出筛选出的质数的个数
cout<<num<<endl;
// 主函数正常结束,返回0表示程序成功执行
return 0;
}4、区间筛法:
起源:
区间筛法是一种用于在大范围内高效筛选素数的算法,特别适用于那些范围较大但区间长度相对较小的情况。例如,当我们需要找出一个大区间 [a, b] 中的所有素数时,直接使用埃拉托斯特尼筛法(Eratosthenes Sieve)可能不切实际,因为这会占用大量的内存。而区间筛法则通过仅处理 [a, b] 区间内的数字来减少内存消耗。
写法:
区间筛:类似于埃式筛法。
b以内的合数的最小质因数一定不超过sqrt(b)。如果有sqrt(b)以内的素数表的话,就可以把埃式筛法运用在[a,b)上了。也就是说,先分别做好[2,sqrt(b))的表和[a,b)的表,然后从[2,sqrt(b))的表中筛得素数的同时,也将其倍数从[a,b)的表中划去,最后剩下的就是区间[a,b)内的素数了。
区间筛(简洁、背诵版)
#include <cmath>
#include "iostream"
#include "algorithm"
#define ll long long
using namespace std;
// 区间筛
void sieve(ll a, ll b){
vector<bool> is_prime_small((ll)sqrt(b)+1,true);// 求此区间内的素数
vector<bool> is_prime(b-a, true);
// 埃氏筛求法
ll z = (ll)sqrt(b)+1;
for(ll i=2; i<z; ++i){ // 这是什么鬼
for(ll j=2; i*j<z; ++j){
is_prime_small[i*j] = false; // 将所有质数标志,也就是筛出来
}
}
// 筛出来
for(ll i=2; i*i<=b; ++i){ // 先找到小质数
if(is_prime_small[i]){ // 如果是质数
ll start = (a+i-1)/i*i; // 求出start 开始时的质数
if(start<i*i) start = i*i; // i*i是为了去重,就像 5*3 被 3*5排除过一样
for(ll j = start; j<b; j += i){
is_prime[j-a]= false;
}
}
}
for(ll i = a; i<b; ++i){
// 是什么筛法
if(is_prime[i-a]){
cout<<i<<" ";
}
cout<<endl;
}
}
int main(){
ll a,b;
while (cin>>a>>b){
sieve(a,b);
}
return 0;
}区间筛(详细解释版)
#include <cmath> // 包含数学函数,如 sqrt
#include "iostream" // 包含输入输出流操作
#include "algorithm" // 包含算法库(尽管在此例中未直接使用)
#define ll long long // 定义长整型为 ll,便于书写
using namespace std; // 使用标准命名空间,避免每次调用时都需要 std:: 前缀
// 区间筛法函数,用于找出区间 [a, b) 内的所有素数
void sieve(ll a, ll b){
// 创建一个布尔向量 is_prime_small 来存储小于等于 sqrt(b) 的所有数字是否为质数
vector<bool> is_prime_small((ll)sqrt(b)+1,true);
// 创建一个布尔向量 is_prime 来表示区间 [a, b) 中的每个数字是否为质数
vector<bool> is_prime(b-a, true);
// 计算 z 作为 sqrt(b) + 1,用于后续循环
ll z = (ll)sqrt(b)+1;
// 第一步:使用埃拉托斯特尼筛法标记小于等于 sqrt(b) 的所有非质数
for(ll i=2; i<z; ++i){
// 对于每个 i,如果它是一个质数,则标记它的所有倍数为非质数
for(ll j=2; i*j<z; ++j){
// 标记 i*j 为非质数
is_prime_small[i*j] = false;
}
}
// 第二步:使用已找到的小质数来标记区间 [a, b) 内的合数
for(ll i=2; i*i<=b; ++i){ // 遍历可能的质数因子
if(is_prime_small[i]){ // 如果 i 是一个小质数
// 计算在区间 [a, b) 内第一个大于等于 a 的 i 的倍数
ll start = (a+i-1)/i*i;
// 如果计算出的起点小于 i*i,调整起点到 i*i 以避免重复筛选
if(start<i*i) start = i*i;
// 标记从 start 开始的 i 的所有倍数为非质数
for(ll j = start; j<b; j += i){
is_prime[j-a]= false; // 注意索引调整,因为 is_prime 是基于 [a, b) 的相对位置 练习题目:
问题描述 对于一个含有 MM 个数位的正整数 NN ,任意选中其中 KK 个不同的数位(0≤K<M0≤K<M),将这些选中的数位删除之后,余下的数位按照原来的顺序组成了一个新的数字 PP 。如果至少存在一个 PP 是质数,我们就称 NN 是一个 X 质数。例如,对于整数 78697869 ,我们可以删去 77 和 66 ,得到一个新的数字 8989 ,由于 8989 是一个质数,因此 78697869 是一个 X 质数。又如,对于整数 7777 ,可以删去一个 77 后变为质数 77 ,因此 7777 也是一个 X 质数。 请问 11 (含)至 10000001000000 (含)中一共有多少个不同的 X 质数。 答案提交 这是一道结果填空的题,你只需要算出结果后提交即可。本题的结果为一个整数,在提交答案时只填写这个整数,填写多余的内容将无法得分。
#include "iostream" // 导入输入输出流库,用于标准输入输出操作
#include "cstring" // 导入C风格字符串处理库,主要用于memset函数
const int c = 1000005; // 定义一个常量c,表示数组的最大大小(考虑到1000000需要的空间)
using namespace std; // 使用std命名空间,避免每次调用std::前缀
bool is_prime[c]; // 定义一个布尔数组is_prime,用于存储从0到c-1这些数是否为质数
bool flag = false; // 定义一个标志位flag,用于判断当前数字是否为X质数
int cd = 0; // 定义一个整型变量cd,用于存储当前处理的数字转换成字符串后的长度
string s_num; // 定义一个字符串s_num,用于存储当前正在处理的数字转换成字符串的形式
// 获得整个数组的质数
void sieve(){ // 埃氏筛法
is_prime[0]=is_prime[1]= false; // 初始化0和1不是质数
for(int i=2; i<c; ++i){ // 遍历从2到c的所有数
if(is_prime[i]){ // 如果当前数是质数
for(int j=2; j*i<c; ++j){// 对于该质数的所有倍数
is_prime[i*j]= false;// 将其标记为非质数
}
}
}
}
// 求排列
void dfs(int inNum, int num){ // 深度优先搜索,inNum是当前考虑的字符位置,num是从开始到当前位置组成的数字
if(inNum==cd){ // 如果已经遍历到了字符串的末尾
if(num<c && is_prime[num]){// 如果组成的数字小于c并且是质数
flag = true; // 设置flag为true,表示找到了至少一个质数子序列
return; // 返回,结束搜索
}
return; // 结束当前搜索路径
}
dfs(inNum+1,num); // 不选择当前字符,继续搜索下一个字符
if(num*10+s_num[inNum]-'0'<c) // 如果选择当前字符后组成的数字仍小于c
dfs(inNum+1,num*10+s_num[inNum]-'0'); // 选择当前字符,继续搜索下一个字符
}
// 输入质数
bool is_X_prime(int num){ // 判断一个数字是否为X质数
s_num = to_string(num); // 将数字转换为字符串形式
flag = false; // 初始化flag为false
cd = s_num.size(); // 获取字符串的长度
dfs(0,0); // 从第0个字符开始,初始数字为0,进行深度优先搜索
return flag; // 返回flag值,表示是否找到至少一个质数子序列
}
int main(){
memset(is_prime,true,sizeof(is_prime)); // 初始化is_prime数组为true,假设所有数都是质数
sieve(); // 调用sieve函数,筛选出所有质数
int cnt = 0; // 定义计数器cnt,用于统计X质数的数量
for(int i=1; i<1000001; ++i){ // 遍历从1到1000000的所有整数
if(is_X_prime(i)) cnt++; // 如果当前数字是X质数,则计数器加1
}
cout<<cnt<<endl; dfs的解题思路
有相当一部分人对dfs(深搜)有相当大的疑惑,这里我就画图解释一下:
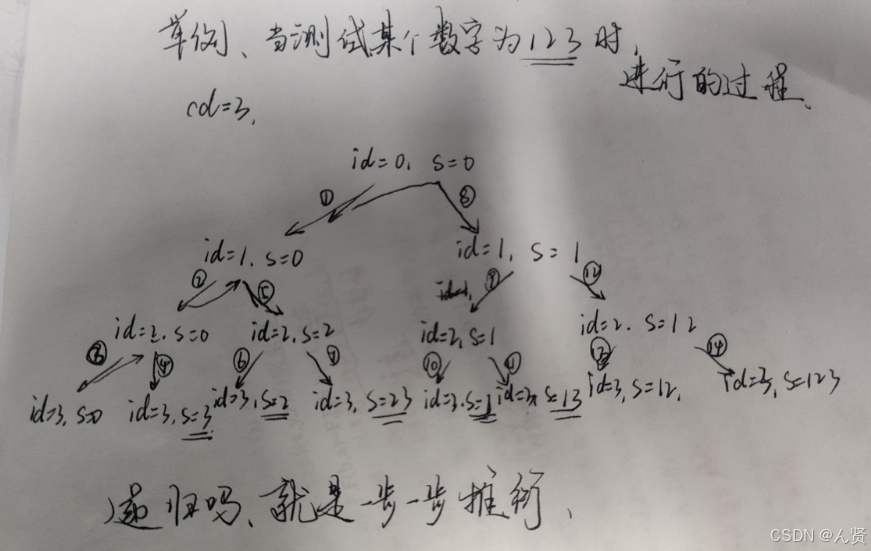
拓展知识:
1、memset的用法
C/C++ 首先需导入头文件 #include <cstring>。
memset 是一个非常有用的函数,用于将一块内存区域的所有字节设置为特定的值。然而,由于它按字节操作,因此在使用 memset 初始化不同数据类型的变量或数组时需要注意一些细节和限制。以下是关于 memset 初始化的一些关键点和常见用法:
void *memset(void *str, int c, size_t n);适用场景:
1、字符串初始化:
char str[50];
memset(str, 0, sizeof(str)); // 设为空字符串2、整型字符串初始化为0、-1:
int arr[10];
memset(arr, 0, sizeof(arr));
memset(arr, -1, sizeof(arr));不适用场景:
1、非0、非-1的整数初始化
int arr[10];
memset(arr, 10, sizeof(arr)); // 错误的做法
------------------------
168430090
168430090
168430090
168430090
168430090
168430090
168430090
168430090
168430090
1684300902、浮点数初始化
不能使用 memset 直接初始化浮点数数组到非零值,因为浮点数的内部表示与整数不同。
注意也不支持long long。
- 朴素算法:时间复杂度为
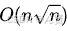
,对于较大的 n,效率较低。
- 埃氏筛:时间复杂度为
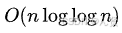
,效率较高,但对于某些极端情况,仍有一定的优化空间。
- 欧拉筛法:时间复杂度为
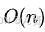
,是目前已知的筛素数最快的方法之一。
- 区间筛法:时间复杂度接近
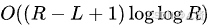
当需要处理较大区间内的素数问题时使用。
借鉴文章、视频:
4、欧拉筛除法# 少儿编程 # 逻辑...
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-03-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号