【关于Java的数据类型】


1、八种基本的数据类型
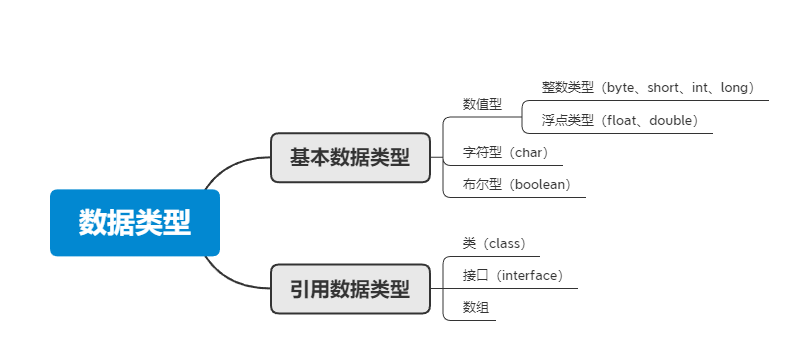
Java支持数据类型分为两类: 基本数据类型和引用数据类型。
基本数据类型共有8种,可以分为三类:
- 数值型:整数类型(byte、short、int、long)和浮点类型(float、double)
- 字符型:char
- 布尔型:boolean
img
8种基本数据类型的默认值、位数、取值范围,如下表所示:
数据类型 | 占用大小(字节) | 位数 | 取值范围 | 默认值 | 描述 |
|---|---|---|---|---|---|
byte | 1 | 8 | -128(-2^7) 到 127(2^7 - 1) | 0 | 是最小的整数类型,适合用于节省内存,例如在处理文件或网络流时存储小范围整数数据。 |
short | 2 | 16 | -32768(-2^15) 到 32767(2^15 - 1) | 0 | 较少使用,通常用于在需要节省内存且数值范围在该区间的场景。 |
int | 4 | 32 | -2147483648(-2^31) 到 2147483647(2^31 - 1) | 0 | 最常用的整数类型,可满足大多数日常编程中整数计算的需求。 |
long | 8 | 64 | -9223372036854775808(-2^63) 到 9223372036854775807(2^63 - 1) | 0L | 用于表示非常大的整数,当 int 类型无法满足需求时使用,定义时数值后需加 L 或 l。 |
float | 4 | 32 | 1.4E - 45 到 3.4028235E38 | 0.0f | 单精度浮点数,用于表示小数,精度相对较低,定义时数值后需加 F 或 f。 |
double | 8 | 64 | 4.9E - 324 到 1.7976931348623157E308 | 0.0d | 双精度浮点数,精度比 float 高,是 Java 中表示小数的默认类型。 |
char | 2 | 16 | '\u0000'(0) 到 '\uffff'(65535) | '\u0000' | 用于表示单个字符,采用 Unicode 编码,可表示各种语言的字符。 |
boolean | 无明确字节大小(理论上 1 位) | 无明确位数 | true 或 false | false | 用于逻辑判断,只有两个取值,常用于条件判断和循环控制等逻辑场景。 |
Float和Double的最小值和最大值都是以科学记数法的形式输出的,结尾的“E+数字”表示E之前的数字要乘以10的多少倍。比如3.14E3就是3.14×1000=3140,3.14E-3就是3.14/1000=0.00314。
注意一下几点:
- Java八种基本数据类型的字节数:1字节(byte、boolean)、 2字节(short、char)、4字节(int、float)、8字节(long、double)
- 浮点数的默认类型为double(如果需要声明一个常量为float型,则必须要在末尾加上f或F)
- 整数的默认类型为int(声明Long型在末尾加上l或者L)
- 八种基本数据类型的包装类:除了char的是Character、int类型的是Integer,其他都是首字母大写
- char类型是无符号的,不能为负,所以是0开始的
2、int和long是多少位,多少字节的?
int类型是 32 位(bit),占 4 个字节(byte),int 是有符号整数类型,其取值范围是从 -2^31 到 2^31-1 。例如,在一个简单的计数器程序中,如果使用int类型来存储计数值,它可以表示的最大正数是 2,147,483,647。如果计数值超过这个范围,就会发生溢出,导致结果不符合预期。long类型是 64 位,占 8 个字节,long类型也是有符号整数类型,它的取值范围是从 -2^63 到 2^63 -1 ,在处理较大的整数数值时,果int类型的取值范围不够,就需要使用long类型。例如,在一个文件传输程序中,文件的大小可能会很大,使用int类型可能无法准确表示,而long类型就可以很好地处理这种情况。
3、long和int可以互转吗 ?
可以的,Java中的long和int可以相互转换。由于long类型的范围比int类型大,因此将int转换为long是安全的,而将long转换为int可能会导致数据丢失或溢出。
将int转换为long可以通过直接赋值或强制类型转换来实现。例如:
int intValue = 10;
long longValue = intValue; // 自动转换,安全的将long转换为int需要使用强制类型转换,但需要注意潜在的数据丢失或溢出问题。
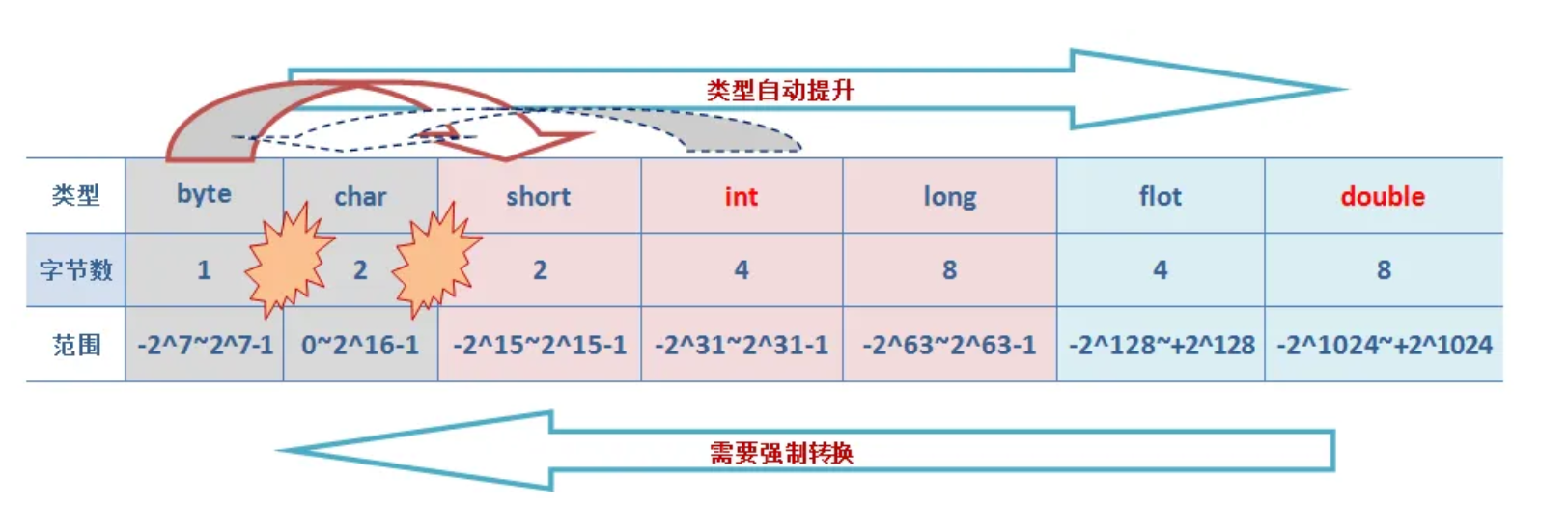
image-20240726003850183
例如:
long longValue = 100L;
int intValue = (int) longValue; // 强制类型转换,可能会有数据丢失或溢出在将long转换为int时,如果longValue的值超出了int类型的范围,转换结果将是截断后的低位部分。因此,在进行转换之前,建议先检查longValue的值是否在int类型的范围内,以避免数据丢失或溢出的问题。
4、数据类型转换方式你知道哪些?
- 自动类型转换(隐式转换):当目标类型的范围大于源类型时,Java会自动将源类型转换为目标类型,不需要显式的类型转换。例如,将
int转换为long、将float转换为double等。 - 强制类型转换(显式转换):当目标类型的范围小于源类型时,需要使用强制类型转换将源类型转换为目标类型。这可能导致数据丢失或溢出。例如,将
long转换为int、将double转换为int等。语法为:目标类型 变量名 = (目标类型) 源类型。 - 字符串转换:Java提供了将字符串表示的数据转换为其他类型数据的方法。例如,将字符串转换为整型
int,可以使用Integer.parseInt()方法;将字符串转换为浮点型double,可以使用Double.parseDouble()方法等。 - 数值之间的转换:Java提供了一些数值类型之间的转换方法,如将整型转换为字符型、将字符型转换为整型等。这些转换方式可以通过类型的包装类来实现,例如
Character类、Integer类等提供了相应的转换方法。
5、类型互转会出现什么问题吗?
基本数据类型转换的问题
当把小范围数据类型赋值给大范围数据类型时,Java 会自动进行类型转换,这种转换一般是安全的。
int num = 100;
long bigNum = num; // 自动将int转换为long但是大范围数据类型赋值给小范围数据类型时,会发生数据数据溢出或者精度损失的问题。
- 数据溢出:如果大范围数据类型赋值给小范围数据类型时,当目标类型无法容纳原数据时,就会发生数据溢出。比如下面,byte 类型的取值范围是 - 128 到 127。300 的二进制表示为
00000001 00101100,强制转换为 byte 类型时,会丢弃高位字节,只保留低位的 8 位00101100,其十进制值为 44。
int largeNum = 300;
byte b = (byte) largeNum; // b的值为44- 精度损失:在进行浮点数类型的转换时,可能会发生精度损失。由于浮点数的表示方式不同,将一个单精度浮点数(
float)转换为双精度浮点数(double)时,精度可能会损失,如果 double 转换为 int 也会发生精度损失的问题,如下:
double d = 3.14;
int i = (int) d; // i的值为3,小数部分0.14被舍弃对象引用转换的问题
向上转型是自动进行的,而且是安全的,如下:
class Animal {}
class Dog extends Animal {}
Dog dog = new Dog();
Animal animal = dog; // 自动向上转型但是向下转型需要手动进行,并且存在风险。如果父类对象实际上并不是目标子类的实例,在转型时就会抛出异常:
Animal animal = new Animal();
Dog dog = (Dog) animal; // 运行时抛出ClassCastException原因是Java 的对象在运行时会记录其真实类型,当进行向下转型时,Java 会检查对象的实际类型是否与目标类型兼容。如果不兼容,就会抛出ClassCastException。
解决方式是需要使用 instanceof 检查:
if (animal instanceof Dog) {
Dog dog = (Dog) animal; // 只有确认animal是Dog的实例时才进行转型
}6、为什么用bigDecimal 不用double ?
double会出现精度丢失的问题,double执行的是二进制浮点运算,二进制有些情况下不能准确的表示一个小数,就像十进制不能准确的表示1/3(1/3=0.3333...),也就是说二进制表示小数的时候只能够表示能够用1/(2^n)的和的任意组合,但是0.1不能够精确表示,因为它不能够表示成为1/(2^n)的和的形式。
比如:
System.out.println(0.05 + 0.01);
System.out.println(1.0 - 0.42);
System.out.println(4.015 * 100);
System.out.println(123.3 / 100);
输出:
0.060000000000000005
0.5800000000000001
401.49999999999994
1.2329999999999999可以看到在Java中进行浮点数运算的时候,会出现丢失精度的问题。那么我们如果在进行商品价格计算的时候,就会出现问题。很有可能造成我们手中有0.06元,却无法购买一个0.05元和一个0.01元的商品。因为如上所示,他们两个的总和为0.060000000000000005。这无疑是一个很严重的问题,尤其是当电商网站的并发量上去的时候,出现的问题将是巨大的。可能会导致无法下单,或者对账出现问题。
而 Decimal 是精确计算 , 所以一般牵扯到金钱的计算 , 都使用 Decimal。
import java.math.BigDecimal;
public class BigDecimalExample {
public static void main(String[] args) {
BigDecimal num1 = new BigDecimal("0.1");
BigDecimal num2 = new BigDecimal("0.2");
BigDecimal sum = num1.add(num2);
BigDecimal product = num1.multiply(num2);
System.out.println("Sum: " + sum);
System.out.println("Product: " + product);
}
}
//输出
Sum: 0.3
Product: 0.02在上述代码中,我们创建了两个BigDecimal对象num1和num2,分别表示0.1和0.2这两个十进制数。然后,我们使用add()方法计算它们的和,并使用multiply()方法计算它们的乘积。最后,我们通过System.out.println()打印结果。
这样的使用BigDecimal可以确保精确的十进制数值计算,避免了使用double可能出现的舍入误差。需要注意的是,在创建BigDecimal对象时,应该使用字符串作为参数,而不是直接使用浮点数值,以避免浮点数精度丢失。
7、装箱和拆箱是什么?
装箱(Boxing)和拆箱(Unboxing)是将基本数据类型和对应的包装类之间进行转换的过程。
Integer i = 10; //装箱
int n = i; //拆箱自动装箱主要发生在两种情况,一种是赋值时,另一种是在方法调用的时候。
赋值时
这是最常见的一种情况,在Java 1.5以前我们需要手动地进行转换才行,而现在所有的转换都是由编译器来完成。
//before autoboxing
Integer iObject = Integer.valueOf(3);
Int iPrimitive = iObject.intValue()
//after java5
Integer iObject = 3; //autobxing - primitive to wrapper conversion
int iPrimitive = iObject; //unboxing - object to primitive conversion方法调用时
当我们在方法调用时,我们可以传入原始数据值或者对象,同样编译器会帮我们进行转换。
public static Integer show(Integer iParam){
System.out.println("autoboxing example - method invocation i: " + iParam);
return iParam;
}
//autoboxing and unboxing in method invocation
show(3); //autoboxing
int result = show(3); //unboxing because return type of method is Integershow方法接受Integer对象作为参数,当调用show(3)时,会将int值转换成对应的Integer对象,这就是所谓的自动装箱,show方法返回Integer对象,而int result = show(3);中result为int类型,所以这时候发生自动拆箱操作,将show方法的返回的Integer对象转换成int值。
自动装箱的弊端
自动装箱有一个问题,那就是在一个循环中进行自动装箱操作的情况,如下面的例子就会创建多余的对象,影响程序的性能。
Integer sum = 0; for(int i=1000; i<5000; i++){ sum+=i; } 上面的代码sum+=i可以看成sum = sum + i,但是+这个操作符不适用于Integer对象,首先sum进行自动拆箱操作,进行数值相加操作,最后发生自动装箱操作转换成Integer对象。其内部变化如下
int result = sum.intValue() + i; Integer sum = new Integer(result); 由于我们这里声明的sum为Integer类型,在上面的循环中会创建将近4000个无用的Integer对象,在这样庞大的循环中,会降低程序的性能并且加重了垃圾回收的工作量。因此在我们编程时,需要注意到这一点,正确地声明变量类型,避免因为自动装箱引起的性能问题。
8、Java为什么要有Integer?
Integer对应是int类型的包装类,就是把int类型包装成Object对象,对象封装有很多好处,可以把属性也就是数据跟处理这些数据的方法结合在一起,比如Integer就有parseInt()等方法来专门处理int型相关的数据。
另一个非常重要的原因就是在Java中绝大部分方法或类都是用来处理类类型对象的,如ArrayList集合类就只能以类作为他的存储对象,而这时如果想把一个int型的数据存入list是不可能的,必须把它包装成类,也就是Integer才能被List所接受。所以Integer的存在是很必要的。
泛型中的应用
在Java中,泛型只能使用引用类型,而不能使用基本类型。因此,如果要在泛型中使用int类型,必须使用Integer包装类。例如,假设我们有一个列表,我们想要将其元素排序,并将排序结果存储在一个新的列表中。如果我们使用基本数据类型int,无法直接使用Collections.sort()方法。但是,如果我们使用Integer包装类,我们就可以轻松地使用Collections.sort()方法。
List<Integer> list = new ArrayList<>();
list.add(3);
list.add(1);
list.add(2);
Collections.sort(list);
System.out.println(list);转换中的应用
在Java中,基本类型和引用类型不能直接进行转换,必须使用包装类来实现。例如,将一个int类型的值转换为String类型,必须首先将其转换为Integer类型,然后再转换为String类型。
int i = 10;
Integer integer = new Integer(i);
String str = integer.toString();
System.out.println(str);集合中的应用
Java集合中只能存储对象,而不能存储基本数据类型。因此,如果要将int类型的数据存储在集合中,必须使用Integer包装类。例如,假设我们有一个列表,我们想要计算列表中所有元素的和。如果我们使用基本数据类型int,我们需要使用一个循环来遍历列表,并将每个元素相加。但是,如果我们使用Integer包装类,我们可以直接使用stream()方法来计算所有元素的和。
List<Integer> list = new ArrayList<>();
list.add(3);
list.add(1);
list.add(2);
int sum = list.stream().mapToInt(Integer::intValue).sum();
System.out.println(sum);9、Integer相比int有什么优点?
int是Java中的原始数据类型,而Integer是int的包装类。
Integer和 int 的区别:
- 基本类型和引用类型:首先,int是一种基本数据类型,而Integer是一种引用类型。基本数据类型是Java中最基本的数据类型,它们是预定义的,不需要实例化就可以使用。而引用类型则需要通过实例化对象来使用。这意味着,使用int来存储一个整数时,不需要任何额外的内存分配,而使用Integer时,必须为对象分配内存。在性能方面,基本数据类型的操作通常比相应的引用类型快。
- 自动装箱和拆箱:其次,Integer作为int的包装类,它可以实现自动装箱和拆箱。自动装箱是指将基本类型转化为相应的包装类类型,而自动拆箱则是将包装类类型转化为相应的基本类型。这使得Java程序员更加方便地进行数据类型转换。例如,当我们需要将int类型的值赋给Integer变量时,Java可以自动地将int类型转换为Integer类型。同样地,当我们需要将Integer类型的值赋给int变量时,Java可以自动地将Integer类型转换为int类型。
- 空指针异常:另外,int变量可以直接赋值为0,而Integer变量必须通过实例化对象来赋值。如果对一个未经初始化的Integer变量进行操作,就会出现空指针异常。这是因为它被赋予了null值,而null值是无法进行自动拆箱的。
10、那为什么还要保留int类型?
包装类是引用类型,对象的引用和对象本身是分开存储的,而对于基本类型数据,变量对应的内存块直接存储数据本身。
因此,基本类型数据在读写效率方面,要比包装类高效。除此之外,在64位JVM上,在开启引用压缩的情况下,一个Integer对象占用16个字节的内存空间,而一个int类型数据只占用4字节的内存空间,前者对空间的占用是后者的4倍。
也就是说,不管是读写效率,还是存储效率,基本类型都比包装类高效。
11、说一下 integer的缓存
Java的Integer类内部实现了一个静态缓存池,用于存储特定范围内的整数值对应的Integer对象。
默认情况下,这个范围是-128至127。当通过Integer.valueOf(int)方法创建一个在这个范围内的整数对象时,并不会每次都生成新的对象实例,而是复用缓存中的现有对象,会直接从内存中取出,不需要新建一个对象。
原作者:小林coding
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-08-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号