Es、kibana安装教程-ES(二)


上篇文章介绍了ES负责数据存储,计算和搜索,他与传统数据库不同,是基于倒排索引来解决问题的。Kibana是es可视化工具。
一、ElasticSearch安装
官网下载地址:https://www.elastic.co/cn/downloads/past-releases#
(注意jdk1.8版本和最新es的版本可能不适配,博主重新下载的ES7.6.1 版本才正常启动成功)
用cmd进入解压好的es目录下的bin目录,执行elasticseach,
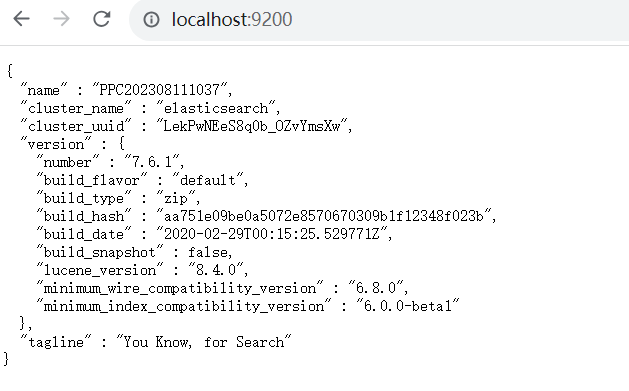
执行localhost:9200看到当前页面代表运行成功。
二、kibana安装教程
Node.js官网下载地址:https://nodejs.org/en
官网下载地址:https://www.elastic.co/cn/downloads/kibana
1、进入kibana目录的config\kibana.yml文件里更改Elasticsearch的启动url。
# The URLs of the Elasticsearch instances to use for all your queries.
#elasticsearch.hosts: ["http://localhost:9200"]
(默认就是9200端口,不需要修改)
2、进入bin目录下执行kibana.bat启动kibana。
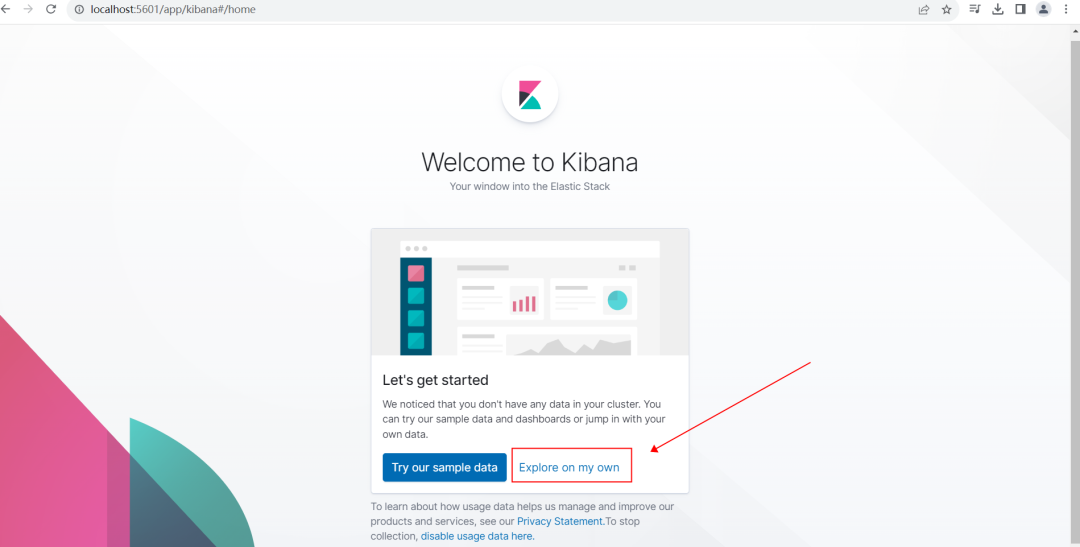
3、当我们进入浏览器输入localhost:5601看到这个页面就代表启动成功。
进入页面之后点击右边的Explore on my own
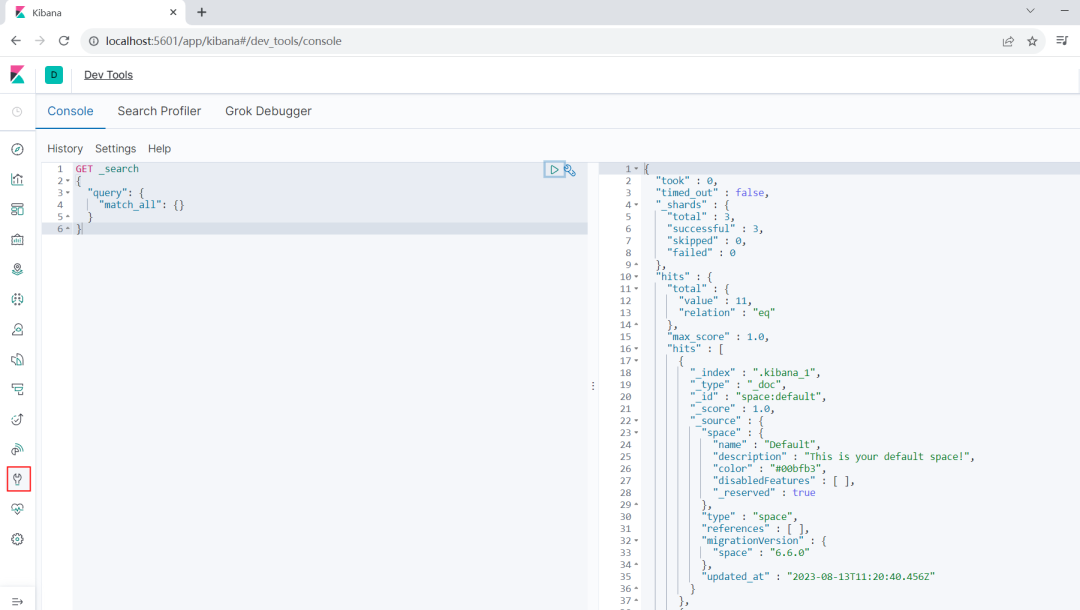
4、点左边图标dev Tools,可以看到我们的DSL语句。这个语句的含义是查询query,match_all所有的数据。
三、分词器
Es默认的分词器对中文处理并不友好,我们发送一个post请求,analyze表示分析。
Dsl语句有两个字段,analyzer表示分词器,standard是默认分词器,text则是需要分词的文本。

当我们分词器不管选择默认的,还是english还是chinese,分词结果都如右边,每个中文都是单独分词,这样肯定达不到我们想要的结果,查询的时候并不合适。
所以我们需要在github上下载分词器:
https://github.com/medcl/elasticsearch-analysis-ik
进入页面点击releases,找到我们对应elasticsearch对应的版本,一定要版本一致。
下载好解压在es的目录plugins新建ik目录,将解压后的文件放进去。
D:\download\es7\elasticsearch-7.6.1\plugins\ik
重新关闭启动es。
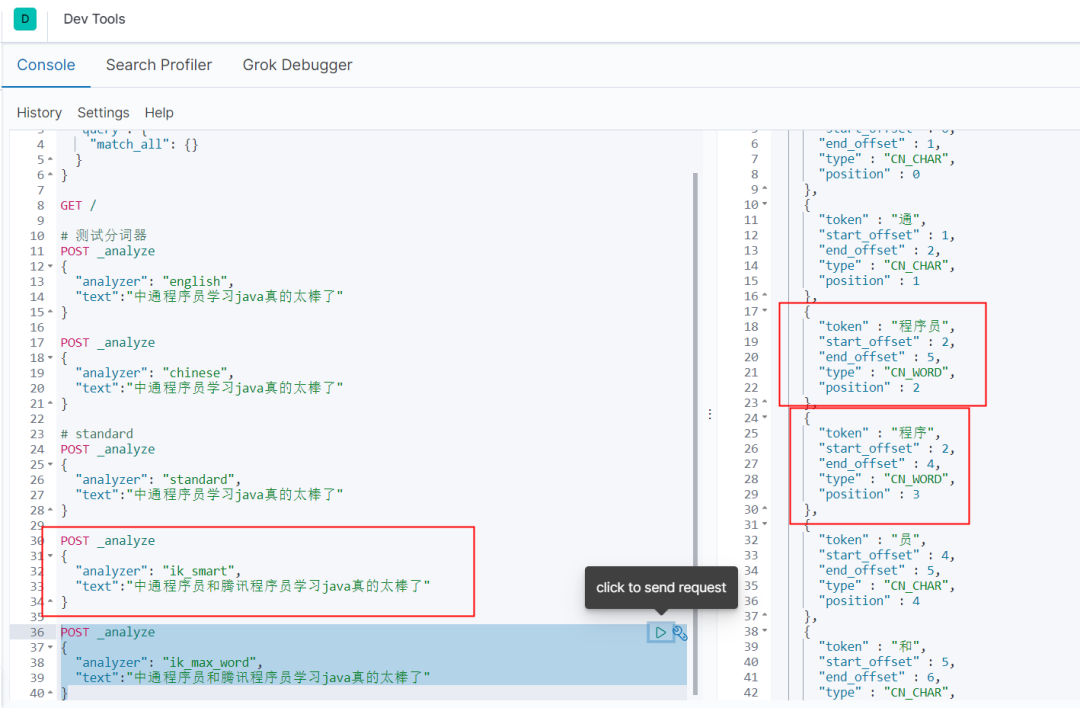
这时候es就会加载ik,他有两个分词器策略,ik_smart和ik_max_word,
Ik_max_word分词会更多更细致,ik_smart则少一点。
意味着ik_max_word搜索的更多但是内存也就占得越多,因此查询效率和概率之间做个选择。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-08-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号