VFIO简介-Linux内核源码分析-模块加载-IOCTL接口-DPDK使用VFIO
原创VFIO简介-Linux内核源码分析-模块加载-IOCTL接口-DPDK使用VFIO
原创
术语
VFIO(Versatile Framework for userspace I/O) : 用户空间 I/O 的多功能框架
LPC: Linux Plumbers Conference(Linux"管道工"大会) 是开源社区的技术会议,重点关注解决Linux开发问题和推动代码前进。会议汇集了致力于 Linux“管道”(内核子系统、核心库、窗口系统)的顶级开发人员 等等 - 并给他们三天的时间来面对面地共同解决子系统内和跨子系统的核心设计问题。 还包括有关 Linux 社区感兴趣的新的创新项目的演讲。 参与者包括受邀参加者、通过公开、竞争性评审过程选出的演讲者以及学生, 大会参考: https://lpc.events/blog/current/index.php/2023/08/21/vfio-iommu-pci-mc-cfp/
VFIO简介
许多现代系统现在提供 DMA 和中断重新映射工具,以帮助确保 I/O 设备在分配的边界内运行。 这包括采用 AMD-Vi 和 Intel VT-d 的 x86 硬件、采用可分区端点 (PE) 的 POWER 系统以及嵌入式 PowerPC 系统(例如 Freescale PAMU)。 VFIO 驱动程序是一个与 IOMMU/设备无关的框架,用于在受 IOMMU 保护的安全环境中公开对用户空间的直接设备访问。 换句话说,这允许安全 、非特权、用户空间驱动程序,为什么我们想要这样? 当配置为获得尽可能高的 I/O 性能时,虚拟机通常会使用直接设备访问(“设备分配”)。 从设备和主机的角度来看,这只是将虚拟机变成了用户空间驱动程序,具有显着减少延迟、更高带宽以及直接使用裸机设备驱动程序的好处。一些应用程序,特别是在高性能计算领域, 还受益于从用户空间进行的低开销、直接设备访问。 示例包括网络适配器(通常不基于 TCP/IP)和计算加速器。 在 VFIO 之前,这些驱动程序必须经历完整的开发周期才能成为适当的上游驱动程序,在树外进行维护,或者使用 UIO 框架,该框架没有 IOMMU 保护的概念、有限的中断支持,并且需要 root 访问 PCI 配置空间等内容的权限。 VFIO 驱动程序框架旨在统一这些,取代 KVM PCI 特定设备分配代码,并提供比 UIO 更安全、功能更丰富的用户空间驱动程序环境
来宾虚拟IOMMU(guest vIOMMU in QEMU)
Intel VT-d 支持仿真, guest vIOMMU 是 QEMU 中的通用设备。 目前仅 Q35 平台支持 guest vIOMMU。 以下是使用 Intel e1000 卡和来宾 vIOMMU 启动 Q35 机器的最简单示例
qemu-system-x86_64 -machine q35,accel=kvm,kernel-irqchip=split -m 2G \
-device intel-iommu,intremap=on \
-netdev user,id=net0 \
-device e1000,netdev=net0 \
$IMAGE_PATH这里 intremap=[on|off] 显示 guest vIOMMU 是否支持中断重新映射。 为了完全启用 vIOMMU 功能,我们需要在此处提供 intremap=on。 目前,中断重映射不支持全内核irqchip,仅支持“split”和“off”。
大多数全模拟设备(如上面提到的 e1000)现在应该能够与 Intel vIOMMU 无缝协作。 然而,有一些特殊设备需要格外小心。 这些设备是:
- 分配的设备(Assigned, 例如 vfio-pci)
- Virtio 设备(例如 virtio-net-pci)
当使用 vIOMMU 设备启用时,设备分配具有特殊依赖性。 下面做一些介绍。
我们可以使用以下命令来启动具有 VT-d 单元和分配设备的虚拟机:
qemu-system-x86_64 -M q35,accel=kvm,kernel-irqchip=split -m 2G \
-device intel-iommu,intremap=on,caching-mode=on \
-device vfio-pci,host=02:00.0 \
$IMAGE_PATH当我们使用 intel-iommu 设备分配设备时,这里需要 caching-mode=on 。 上面的示例将主机 PCI 设备 02:00.0 分配给来宾。
同时,必须将 intel-iommu 设备指定为参数列表中的第一个设备(在所有其余设备之前)
Qemu中常规的设备分配架构图
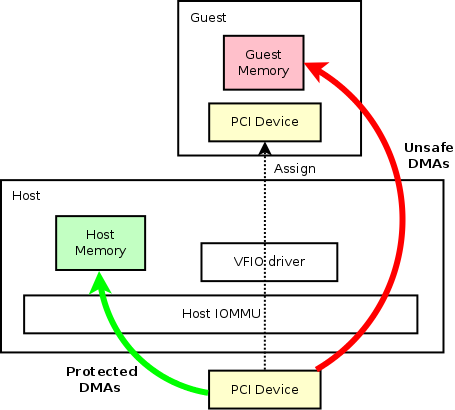
让我们考虑上面的通用 PCI 设备,它是连接到主机系统的真实硬件。 主机可以使用通用内核驱动程序来驱动设备。 在这种情况下,该设备的所有读/写都将受到主机 IOMMU 的保护,这是安全的。 受保护的 DMA 以绿色箭头显示。 PCI 设备也可以分配给来宾。 通过利用主机内核中的 VFIO 驱动程序,该设备可以由任何用户空间程序(如 QEMU)进行专门管理。 在分配了设备的来宾中,我们应该能够看到与主机中完全相同的设备(如虚线所示)。 在这里,虚拟机管理程序能够修改设备信息,例如功能位等。 通过将设备分配给访客,我们可以在访客中获得与主机中相同的性能。 另一方面,当设备分配给客户时,客户内存地址空间完全暴露给硬件 PCI 设备。 因此,当设备对客户系统执行 DMA(尤其是写入)时,不会有任何保护。 恶意写入可能会立即破坏客户端。 那些不安全的 DMA 用红色箭头显示。 这就是为什么我们需要在来宾中使用 vIOMMU来加强保护
使用案例 1:使用 vIOMMU 进行访客设备分配
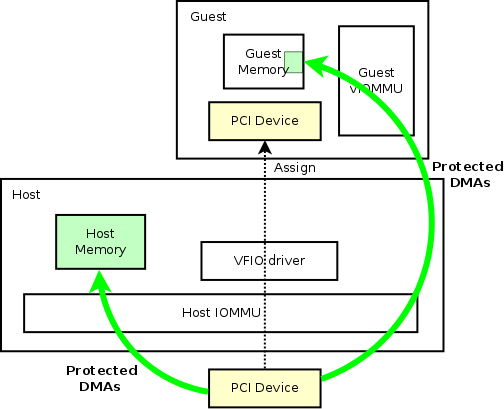
为了保护来宾内存免受恶意分配设备的影响,我们可以在来宾中拥有 vIOMMU,就像主机 IOMMU 对主机所做的那样。上图中,唯一的区别是我们引入了 guest vIOMMU 来做 DMA 保护。 这样,来宾 DMA 现在就安全了。 在这里,我们的用例针对的是使用内核驱动程序的来宾。 值得一提的是,目前,此用例可能会对分配的设备产生重大性能影响。 来宾 IOVA 映射的动态分配将导致虚拟机管理程序进行大量工作,以便将影子页表与真实硬件同步。 但是,在内存映射是静态的情况下,不应对性能产生重大影响(下面的DPDK 是一个用例)。 对于动态内存映射的一般情况,需要做更多的工作来进一步减少保护带来的负面影响
使用案例 2:使用 vIOMMU 进行访客设备分配 - DPDK 场景
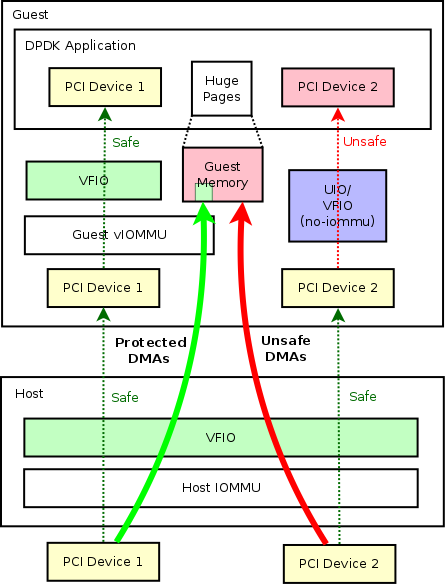
DPDK(即所谓的DataPlane Development Kit)广泛应用于高性能场景,它将内核空间驱动程序移至用户空间以获得更好的性能。 通常,DPDK程序可以直接在裸机内运行,以在特定硬件上达到最佳性能。 同时,它还可以在来宾内部运行,以驱动主机分配的设备或虚拟设备(例如 virtio 设备)。对于提到的来宾 DPDK 用例,主机仍然可以继续利用 DPDK 来最大程度地提高虚拟交换机中的数据包传递 。 OVS-DPDK 就是一个很好的例子。 然而,DPDK 引入了一个问题,因为我们不能真正信任任何用户空间应用程序,所以我们也不能信任 DPDK 应用程序,特别是如果它可以通过硬件完全访问系统内存并污染内核地址空间。 这里,vIOMMU 不仅可以保护硬件错误等恶意设备,还可以保护客户机免受 DPDK 等有缺陷的用户空间驱动程序的影响(通过客户机中的 VFIO 驱动程序)。 实际上,DPDK 应用程序至少可以通过三种方式管理用户空间中的设备(这些方法大多是通用的,并且不限于 DPDK 用例):
- VFIO
- VFIO no-iommu 模式
- UIO, UIO 将被过时,因为它缺乏 的功能和不安全性。
让我们考虑一个带有两个 PCI 设备的客户 DPDK 应用程序的用例。 为了阐明上述方法的区别,我使用了不同的方法将设备分配给 DPDK 应用程序:如上图, PCI 设备 1 和 PCI 设备 2 是分配给来宾 DPDK 的两个设备 应用程序。 在主机中,这两个设备都使用内核 VFIO 驱动程序分配给来宾(这里我们不能使用“VFIO no-iommu 模式”或“UIO”,但背后的原因超出了本页的范围:)。 而在guest中,当我们将设备分配给DPDK应用程序时,我们可以使用上述三种方法之一。 但是,只有当我们使用通用 VFIO 驱动程序(需要 vIOMMU)分配设备时,我们才能获得安全分配的设备。 通过“UIO”或“VFIO no-iommu 模式”分配设备都是不安全的。 在我们的例子中,PCI 设备 1 是安全的,而 PCI 设备 2 是不安全的
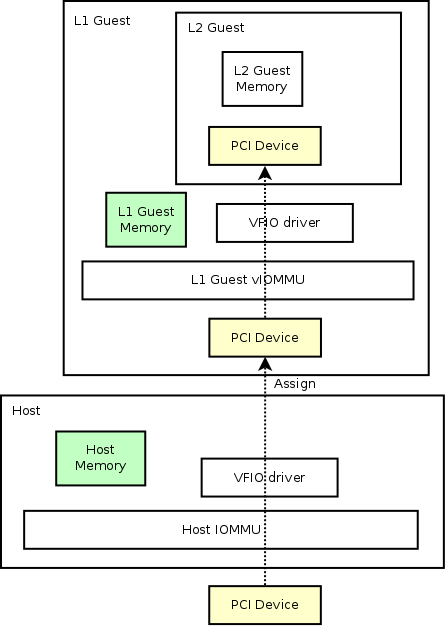
用例 3:嵌套访客设备分配
使用 vIOMMU 进行设备分配的另一个用例是,嵌套设备分配将像魔术一样发挥作用。正如我们在第一部分中提到的,设备分配需要 IOMMU 才能工作。 在这里,要将 L1 来宾设备分配给 L2 来宾,我们还需要 L1 来宾内部的 vIOMMU 来构建设备分配工作所需的页面映射。 嵌套设备分配如下所示:
Virtio 设备
Virtio 设备很特殊,因为默认情况下它们会绕过 DMA Remapping 重新映射(不在内核驱动程序中使用它)。 我们需要一些特殊参数来显式启用 DMA 重映射。 而对于中断重映射,它不依赖于设备类型,因此它的启用/禁用就像其他非 virtio 设备一样
为 virtio-net-pci 设备启用 DMAR(DMA重映射) 的最简单命令行是:
qemu-system-x86_64 -M q35,accel=kvm,kernel-irqchip=split -m 2G \
-device intel-iommu,intremap=on,device-iotlb=on \
-device ioh3420,id=pcie.1,chassis=1 \
-device virtio-net-pci,bus=pcie.1,netdev=net0,disable-legacy=on,disable-modern=off,iommu_platform=on,ats=on \
-netdev tap,id=net0,vhostforce \
$IMAGE_PATH这里我们额外需要这些东西:
模拟 vIOMMU 需要“device-iotlb=on”。 这使得设备 IOTLB 支持 vIOMMU,并且它与下面的ats=on 成对使用。 还需要一台 ioh3420 设备。 它用于确保 virtio-net-pci 设备位于 PCIe 根端口下 需要 virtio 设备是: 在创建的PCIe根端口下, 确保使用现代 virtio, 确保 iommu_platform=on , 设置“ats=on”,它与上面的“device-iotlb=on”部分使用。 除了 virtio-net-pci 之外,其他类型的 virtio PCI 设备也需要类似的东西。
容器/组/设备的关
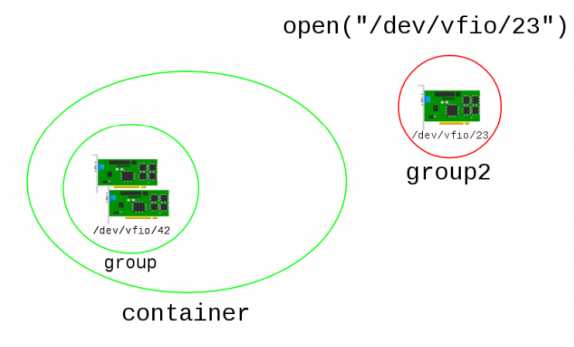
VFIO与PCI关系
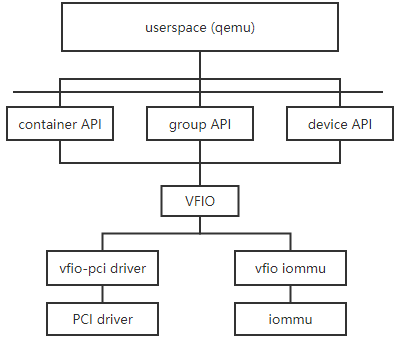
Qemu/容器/组/设备间的数据结构关系
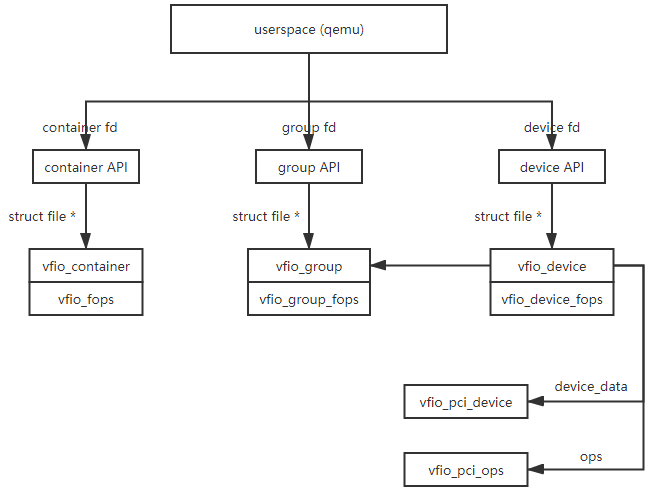
组/IOMMU/容器/IOMMU域/VFIO_PCI设备间的数据结构关系
VFIO内核源码分析
加载vfio-pci模块
vfio, Documentation/driver-api/vfio.rst
echo 1 | sudo tee /sys/module/vfio_pci/parameters/enable_sriov
modprobe vfio-pci enable_sriov=1 -> module_init(vfio_pci_init) -> vfio/pci:将 pci_driver 代码从 vfio_pci_core.c 中拆分出来,将 vfio_pci 驱动程序拆分为两个逻辑部分,即实现“对任何 PCI 设备的通用 VFIO 支持”的“struct pci_driver”(vfio_pci.c)和代码库( vfio_pci_core.c),帮助在 PCI 设备之上实现 struct vfio_device。 vfio_pci.ko 继续在 sysfs 下提供相同的接口,此更改不会对功能产生影响。 以下补丁将把 vfio_pci 和 vfio_pci_core 变成一个单独的模块。 这是为了允许另一个模块提供 pci_driver 并允许该模块自定义 VFIO 的设置方式、注入其自己的操作以及轻松扩展供应商特定的功能。 此时,vfio_pci_core 仍然包含许多混合到其中的 vfio_pci 功能。 后续补丁将移出更多大型物品,但需要另一个清理系列才能清除所有物品
vfio_pci_core_set_params
pci_register_driver(&vfio_pci_driver)
vfio_pci_fill_ids()
pci_add_dynid(&vfio_pci_driver, vendor, device, subvendor, subdevice, class, class_mask, 0) -> 将新的 PCI 设备 ID 添加到此驱动程序并重新探测设备
static struct pci_driver vfio_pci_driver = {
.name = "vfio-pci",
.id_table = vfio_pci_table,
.probe = vfio_pci_probe,
.remove = vfio_pci_remove,
.sriov_configure = vfio_pci_sriov_configure,
.err_handler = &vfio_pci_core_err_handlers,
.driver_managed_dma = true,
};
vfio_pci_probe
vfio_pci_is_denylisted
vdev = vfio_alloc_device(vfio_pci_core_device, vdev, &pdev->dev, &vfio_pci_ops) -> container_of(_vfio_alloc_device
vfio_init_device(device, dev, ops) -> vfio:添加统一 vfio_device 生命周期的帮助程序,其想法是让 vfio 核心管理 vfio_device 生命周期,而不是重复跨驱动程序的逻辑。 这也是将struct device添加到vfio_device的准备步骤。 新的助手对和 vfio_device 中的 kref: - vfio_alloc_device() - vfio_put_device() 驱动程序可以注册 @init/@release 回调来管理包装 vfio_device 的任何私有状态。 然而,vfio-ccw 不适合这个模型,因为它的私有结构混合了父级和 mdev 信息,因此生命周期混乱,因此必须在 vfio 设备的生命周期之外分配/释放。 根据之前的讨论,IBM 人员不会在短期内解决这个问题。 不必等待这些修改,而是引入另一个帮助程序 vfio_init_device(),以便 ccw 可以调用它来初始化预分配的 vfio_device。 ccw 技巧的进一步含义是 vfio_device 无法在 vfio 核心中统一释放。 相反,需要*每个*驱动程序来实现@release并释放内部的vfio_device。 那么ccw可以自行选择延迟免费。 另一个技巧是 kvzalloc() 用于满足 gvt 的需要,gvt 使用 vzalloc(),而所有其他都使用 kzalloc()。 因此,驱动程序应该调用帮助程序 vfio_free_device() 来释放 vfio_device,而不是假设 kfree() 或 vfree() 是适用的。 稍后,一旦 ccw 混乱得到修复,我们就可以删除这些技巧并完全处理 vfio 核心中的结构分配/释放。 所有现有用法转换为新模型后,现有 vfio_{un}init_group_dev() 将被弃用
ida_alloc_max
init_completion(&device->comp)
ret = ops->init(device) -> vfio_pci_core_init_dev
INIT_LIST_HEAD(&vdev->dummy_resources_list)
INIT_LIST_HEAD(&vdev->ioeventfds_list)
INIT_LIST_HEAD(&vdev->vma_list)
INIT_LIST_HEAD(&vdev->sriov_pfs_item)
xa_init(&vdev->ctx) -> vfio/pci:使用xarray进行中断上下文存储,中断上下文在分配中断时静态分配。 分配后,通过使用向量作为索引直接访问数组的元素来管理上下文。 当中断被禁用时,存储被释放。 启用 MSI-X 后,可以动态分配单个 MSI-X 中断。 需要中断上下文的动态存储来支持这一点。 将中断上下文数组替换为 xarray(类似于内核用作 MSI 描述符存储的数组),它可以支持动态扩展,同时保持使用向量作为索引的自定义。 使用动态存储,不再需要在分配中断时预分配中断上下文。 MSI 和 MSI-X 中断上下文仅在中断启用时使用。 因此,它们的分配可以被延迟,直到中断使能为止。 只有启用的中断才会有关联的中断上下文。 是否已分配中断(Linux irq number存在)成为是否允许中断的标准
device_initialize(&device->device)
dev_set_drvdata(&pdev->dev, vdev) -> vfio/pci:让所有 VFIO PCI 驱动程序将 vfio_pci_core_device 存储在 drvdata 中,在 drvdata 中拥有一致的指针将允许下一个补丁使用某些核心代码帮助程序中的 drvdata。 在 vfio_pci_core_register_device() 内使用 WARN_ON 来检测错过此的驱动程序
vfio_pci_core_register_device(vdev)
if (pdev->hdr_type != PCI_HEADER_TYPE_NORMAL)
if (pci_num_vf(pdev)) -> 防止绑定到启用了 VF 的 PF,VF 可能正在被主机或其他用户使用。 如果 VF 已经存在,我们就无法捕获它们,也无法跟踪 VF 用户。 此处禁用 SR-IOV 将开始删除 VF,这将解除驱动程序的绑定,如果该 VF 也被 vfio-pci 使用,则驱动程序很容易发生阻塞。 直接拒绝这些PF,让用户去整理就好了
vfio_assign_device_set -> vfio/pci:转向设备集基础设施,PCI 希望拥有通常的 open/close_device() 逻辑,但略有不同,即 open/close_device() 必须在由所有 vfio_device 共享的单锁下完成 PCI“重置组”。 复位组以及设备集由 pci_reset_bus() 接触的设备决定,可以是整个总线,也可以只是插槽。 依靠核心代码来完成 reflck 所做的一切并完全删除 reflck -> vfio:为打开/释放vfio_device_ops提供更好的通用支持,当前驱动程序ops有一个打开/释放对,每次打开或关闭设备FD时都会调用一次。 添加一组额外的 open/close_device() 操作,这些操作在设备 FD 第一次打开和最后一次关闭时调用。 分析表明所有驱动程序都需要这种语义。 有些人将其开放编码作为其 reflck 实现的一部分,有些人只是有错误并且完全错过了它。 为了保留 PCI 和 FSL 所依赖的当前语义,引入“设备集”的概念,它是一组在打开时共享相同锁的 vfio_device。 设备集是通过提供“set_id”指针来建立的。 所有提供相同指针的 vfio_device 将连接到相同的单例内存并锁定整个集合。 这有效地取代了名称奇怪的 reflck。 转换后,set_id 将源自: - fsl_mc_device (fsl) 的 struct device - struct pci_slot (pci) - struct pci_bus (pci) - struct vfio_device(所有) 该设计确保上述指针有效 只要 vfio_device 已注册,它们就会形成可靠的唯一密钥以将 vfio_device 分组。 此实现使用 xarray 而不是搜索驱动程序核心结构,这简化了该区域中有些棘手的锁定。 以下补丁转换所有驱动程序
INIT_LIST_HEAD(&new_dev_set->device_list)
dev_set = __xa_cmpxchg -> 比较和存储, 调用此函数时,您必须已经持有 xa_lock。 如果需要分配内存,它将释放锁,然后重新获取它
vfio_pci_vf_init -> vfio_pci_probe() 相当复杂,有可选的 VF 和 VGA 子组件。 将它们移至清晰的 init/uninit 函数中,并在探测/删除中具有线性流程。 这修复了一些小错误: - vfio_pci_remove() 的顺序错误,vga_client_register() 删除通知程序并且位于 kfree(vdev) 之后,但通知程序引用 vdev,因此它可以在比赛中在 free 之后使用。 - vga_client_register() 可能会失败但被忽略 组织事物,因此销毁顺序与创建顺序相反
if (pdev->is_virtfn)
pci_physfn
list_for_each_entry(cur, &vfio_pci_sriov_pfs,
vdev->nb.notifier_call = vfio_pci_bus_notifier
if (action == BUS_NOTIFY_ADD_DEVICE
ret = bus_register_notifier(&pci_bus_type, &vdev->nb)
vfio_pci_vga_init -> Video Graphics Array (VGA) connector
vfio_pci_is_vga
aperture_remove_conflicting_pci_devices
vga_client_register(pdev, vfio_pci_set_decode)
vga_set_legacy_decoding(pdev, vfio_pci_set_decode(pdev, false))
vfio_pci_probe_power_state
pci_read_config_word(pdev, pdev->pm_cap + PCI_PM_CTRL, &pmcsr)
vfio_pci_set_power_state
pm_runtime_allow
vfio_register_group_dev -> vfio:简化中介设备的 iommu 组分配,重用 vfio_noiommu_group_alloc 中的逻辑,通过分解通用函数为中介设备分配假单设备 iommu 组,并用枚举替换 struct vfio_group 中的 noiommu 布尔字段以区分这三个 不同类型的团体
dev_set_name(&device->device, "vfio%d", device->index)
vfio_device_set_group(device, type)
vfio_group_find_or_alloc
vfio_noiommu_group_alloc
group = vfio_group_find_from_iommu(iommu_group) -> list_for_each_entry(group, &vfio.group_list
vfio_group_has_device
group = vfio_create_group(iommu_group, VFIO_IOMMU)
group = vfio_group_alloc(iommu_group, type)
cdev_init(&group->cdev, &vfio_group_fops)
INIT_LIST_HEAD(&group->device_list)
dev_set_name(&group->dev, "%s%d"
cdev_device_add(&group->cdev, &group->dev)
list_add(&group->vfio_next, &vfio.group_list)
or vfio_noiommu_group_alloc
vfio_device_add(device) -> vfio:为 vfio_device 添加 cdev,这会添加对 vfio_device 的 cdev 支持。 它允许用户直接打开 vfio 设备,而不使用旧容器/组接口,这是支持嵌套翻译等新 iommu 功能的先决条件。以这种方式打开的设备 fd 无法访问 设备,因为 fops open() 不会打开设备,直到成功的 VFIO_DEVICE_BIND_IOMMUFD ioctl(将在以后的补丁中添加)。 通过此补丁,注册到 vfio 核心的设备将同时创建旧组和新设备接口。 - 组接口:/dev/vfio/$groupID - 设备接口:/dev/vfio/devices/vfioX - 普通设备(“X”是跨 vfio 设备的唯一编号) 对于给定设备,用户可以识别匹配的 vfioX 通过搜索设备的 sysfs 路径下的 vfio-dev 文件夹。 以 PCI 设备 (0000:6a:01.0) 为例,/sys/bus/pci/devices/0000\:6a\:01.0/vfio-dev/vfioX 表示 /dev/vfio/devices/ 下匹配的 vfioX,并且 vfio-dev/vfioX/dev 包含匹配的 /dev/vfio/devices/vfioX 的主次编号。 用户可以通过打开/dev/vfio/devices/vfioX 来获取设备fd。 此补丁中的 vfio_device cdev 逻辑: *) __vfio_register_dev() 路径最终会为每个 vfio_device 执行 cdev_device_add()(如果配置了 VFIO_DEVICE_CDEV)。 *) vfio_unregister_group_dev() 路径执行 cdev_device_del(); cdev 接口不支持 noiommu 设备,因此 VFIO 仅为没有 IOMMU 的物理设备创建旧组接口。 noiommu 用户应使用旧组界面
device_add
vfio_device_group_register -> list_add(&device->group_next, &device->group->device_list)
vfio_device_debugfs_init -> vfio/migration:为热迁移驱动添加debugfs,热迁移过程涉及多个设备、软件和操作步骤。 任何一个节点出现错误都可能导致热迁移操作失败。 这个复杂的过程使得当功能出现故障时定位和分析原因变得非常困难。 为了在热迁移失败时快速定位问题原因,我在vfio热迁移驱动中添加了一组debugf, commit, https://github.com/ssbandjl/linux/commit/2202844e4468c7539dba0c0b06577c93735af952
vdev->debug_root = debugfs_create_dir(dev_name(vdev->dev),
vfio_dev_migration = debugfs_create_dir("migration",
debugfs_create_devm_seqfile(dev, "state", vfio_dev_migration,
static const struct vfio_device_ops vfio_pci_ops = {
.name = "vfio-pci",
.init = vfio_pci_core_init_dev,
.release = vfio_pci_core_release_dev,
.open_device = vfio_pci_open_device,
.close_device = vfio_pci_core_close_device,
.ioctl = vfio_pci_core_ioctl,
.device_feature = vfio_pci_core_ioctl_feature,
.read = vfio_pci_core_read,
.write = vfio_pci_core_write,
.mmap = vfio_pci_core_mmap,
.request = vfio_pci_core_request,
.match = vfio_pci_core_match,
.bind_iommufd = vfio_iommufd_physical_bind,
.unbind_iommufd = vfio_iommufd_physical_unbind,
.attach_ioas = vfio_iommufd_physical_attach_ioas,
.detach_ioas = vfio_iommufd_physical_detach_ioas,
};Qemu中热迁移下的调试文件系统架构(debugfs)
整个debugfs目录将基于CONFIG_DEBUG_FS宏的定义。 如果不启用该宏,vfio.h中的接口将为空定义,并且不会执行debugfs目录的创建和初始化, debugfs将创建一个公共根目录“vfio”文件,然后为每个实时迁移设备创建一个dev_name()文件。 首先,在此设备目录下创建“迁移”的统一状态采集文件。 然后,创建一个公共实时迁移状态查找文件“state”
+-------------------------------------------+
| |
| |
| QEMU |
| |
| |
+---+----------------------------+----------+
| ^ | ^
| | | |
| | | |
v | v |
+---------+--+ +---------+--+
|src vfio_dev| |dst vfio_dev|
+--+---------+ +--+---------+
| ^ | ^
| | | |
v | | |
+-----------+----+ +-----------+----+
|src dev debugfs | |dst dev debugfs |
+----------------+ +----------------+加载VFIO模块
modprobe vfio, vfio.ko
static struct vfio {
struct class *device_class;
struct ida device_ida;
} vfio; -> VFIO 是一种安全的用户级驱动程序,可与虚拟机和用户级驱动程序一起使用。 VFIO 利用 IOMMU 组来确保使用中的设备的隔离,从而允许非特权用户访问。 VFIO 旨在取代 KVM 设备分配和 UIO 驱动程序(在目标平台包含功能足够的 IOMMU 的情况下)。 此版本 VFIO 的新增功能是支持通过 IOMMU 核心管理的 IOMMU 组,并对 API 进行了修改,删除了组合并接口。 我们现在回到一个更类似于原始 VFIO 且支持 UIOMMU 的模型,其中从 /dev/vfio/vfio 获取的文件描述符允许访问 IOMMU,但仅在添加组之后,避免了以前此类类型的权限问题 模型。 IOMMU 支持现在也是完全模块化的,因为 IOMMU 在不同平台上具有截然不同的接口要求。 VFIO 用户能够查询和初始化他们选择的 IOMMU 模型。 请参阅后续文档提交以获取进一步的描述和使用示例
commit, https://github.com/ssbandjl/linux/commit/cba3345cc494ad286ca8823f44b2c16cae496679
module_init(vfio_init)
ida_init(&vfio.device_ida)
vfio_group_init()
INIT_LIST_HEAD(&vfio.group_list)
vfio_container_init
INIT_LIST_HEAD(&vfio.iommu_drivers_list)
misc_register(&vfio_dev)
if (IS_ENABLED(CONFIG_VFIO_NOIOMMU))
vfio_register_iommu_driver(&vfio_noiommu_ops)
list_add(&driver->vfio_next, &vfio.iommu_drivers_list)
vfio.class = class_create("vfio") -> /dev/vfio/$GROUP
alloc_chrdev_region(&vfio.group_devt, 0, MINORMASK + 1, "vfio") -> register_chrdev_region 需要开发者指定设备的主设备号,而 alloc_chrdev_region 则是由内核自动分配主设备号
vfio_virqfd_init() -> create_singlethread_workqueue("vfio-irqfd-cleanup")
vfio.device_class = class_create("vfio-dev")
vfio_cdev_init(vfio.device_class)
alloc_chrdev_region(&device_devt, 0, MINORMASK + 1, "vfio-dev")
vfio_debugfs_create_root -> vfio_debugfs_root = debugfs_create_dir("vfio", NULL)
static struct miscdevice vfio_dev = {
.minor = VFIO_MINOR,
.name = "vfio",
.fops = &vfio_fops,
.nodename = "vfio/vfio",
.mode = S_IRUGO | S_IWUGO,
};
static const struct file_operations vfio_fops = {
.owner = THIS_MODULE,
.open = vfio_fops_open,
.release = vfio_fops_release,
.unlocked_ioctl = vfio_fops_unl_ioctl,
.compat_ioctl = compat_ptr_ioctl,
};
static const struct vfio_iommu_driver_ops vfio_noiommu_ops = {
.name = "vfio-noiommu",
.owner = THIS_MODULE,
.open = vfio_noiommu_open,
.release = vfio_noiommu_release,
.ioctl = vfio_noiommu_ioctl,
.attach_group = vfio_noiommu_attach_group,
.detach_group = vfio_noiommu_detach_group,
};
vfio_fops_open
INIT_LIST_HEAD(&container->group_list)
include/uapi/linux/vfio.h
vfio_pci_sriov_configure -> vfio_pci_core_sriov_configure
if (nr_virtfn)
list_add_tail(&vdev->sriov_pfs_item, &vfio_pci_sriov_pfs)
pm_runtime_resume_and_get
vfio_pci_set_power_state
pci_enable_sriov
pci_disable_sriov
vfio_df_ioctl_bind_iommufd
static const struct file_operations vfio_group_fops = {
.owner = THIS_MODULE,
.unlocked_ioctl = vfio_group_fops_unl_ioctl,
.compat_ioctl = compat_ptr_ioctl,
.open = vfio_group_fops_open,
.release = vfio_group_fops_release,
};
vfio_group_fops_open
struct vfio_group *group
group->opened_file = filep
filep->private_data = group典型IOCTL流程(ioctl接口)
vfio_group_fops_unl_ioctl
switch (cmd)
case VFIO_GROUP_GET_DEVICE_FD
vfio_group_ioctl_get_device_fd
vfio_device_open_file
vfio_df_group_open
vfio_df_open
vfio_df_device_first_open
device->ops->open_device(device) -> vfio_pci_open_device
vfio_pci_core_enable
pci_enable_device
pci_try_reset_function
pci_read_config_word(pdev, PCI_COMMAND, &cmd)
vfio_pci_zdev_open_device -> vfio-pci/zdev:添加打开/关闭设备挂钩,在vfio-pci open_device期间,传递与vfio组关联的KVM(如果存在)。 这是为了将特殊指示符 (GISA) 传递给固件,以允许 zPCI 解释工具仅用于与 vfio-pci 设备关联的特定 KVM。 在 vfio-pci close_device 期间,取消注册通知程序
return zpci_kvm_hook.kvm_register(zdev, vdev->vdev.kvm) -> 启用 zPCI 指令的解释执行 + 适配器中断、s390x KVM vfio-pci 的转发。 这是通过在 VFIO 组与 KVM 来宾关联时触发例程、向固件传输特殊令牌(GISA 名称)以使该特定来宾能够在该 zPCI 设备上解释执行来完成的。 然后,加载/存储解释启用由用户空间控制(基于 SHM 位是否放置在虚拟函数句柄中)。 适配器事件通知解释是通过新的 KVM ioctl 从用户空间控制的。 通过允许解释 zPCI 指令以及向 guest 虚拟机传送中断的固件,我们可以降低 zPCI 的 guest SIE 退出频率。 从 guest 配置的角度来看,您可以按照与以前相同的方式传递 zPCI 设备,并且默认情况下使用解释支持(如果在 kernel+qemu 中可用)。 将跟进更新的 QEMU 系列的链接。 变更日志 v7->v8: - 修复 ioctl 文档 (Thomas) - 从 ioctl 中删除 copy_to_user,来自旧版本 (Thomas) - KVM_S390_ZPCIOP_REG_AEN:未定义标志失败 (Thomas) - kvm_s390_pci_zpci_reg_aen:清理主机标志设置 (Thomas) 并修复意外的错误 位反转 - CONFIG_VFIO_PCI_ZDEV_KVM:添加意外遗漏在帮助文本中的“say Y”(Jason) - 重构“vfio:删除 VFIO_GROUP_NOTIFY_SET_KVM”之上的 vfio-pci-zdev 片段(Jason) - open_device/ close_device 现在将直接调用 kvm 注册例程。 将 open_device 调用移至 vfio_pci_core_enable,以便可以传播错误。 对于奇偶校验,将 close_device 调用移至 vfio_pci_core_disable -> commit, https://lwn.net/Articles/897230/
vfio_config_init -> 对于每个设备,我们分配一个 pci_config_map 来指示占用每个双字的能力,从而指示我们用于读写的 struct perm_bits。 我们还分配一个虚拟化配置空间,用于跟踪我们为用户模拟的位的读取和写入。 从设备填充初始值。 在所有 vfio-pci 设备之间使用共享 struct perm_bits 可以使我们免于为每个设备的 virt 和 write 分配 cfg_size 缓冲区。 我们可以删除 vconfig 并为需要模拟位的每个区域分配单独的缓冲区,但指针数组的大小将相当(至少对于标准配置空间)-> 关键数据结构, struct vfio_pci_core_device, 将pci硬件能力和配置通过vfio的pci设备暴露给上层
map = kmalloc(pdev->cfg_size, GFP_KERNEL_ACCOUNT) -> 配置空间、caps 和 ecaps 都是双字对齐的,因此我们可以使用每个双字一个字节来记录类型。 但能力的长度没有要求,所以能力之间的差距需要字节粒度
vfio_fill_vconfig_bytes -> vfio:添加PCI设备驱动,添加PCI设备对VFIO的支持。 PCI 设备公开用于访问设备的配置空间、I/O 端口空间和 MMIO 区域的区域。 PCI 配置访问在内核中虚拟化,使我们能够通过防止各种访问同时减少跨各种用户空间驱动程序的重复支持来确保系统的完整性。 I/O 端口支持读/写访问,而 MMIO 还支持足够大小区域的 mmap。 使用 eventfds 向用户空间提供对 INTx、MSI 和 MSI-X 中断的支持 -> commit, https://github.com/ssbandjl/linux/commit/89e1f7d4c66d85f42c3d52ea3866eb10cadf6153
vdev->rbar[0] = le32_to_cpu(*(__le32 *)&vconfig[PCI_BASE_ADDRESS_0]);
...
vfio_cap_init
vfio_ecap_init
vdev->has_dyn_msix = pci_msix_can_alloc_dyn(pdev)
vfio_pci_core_finish_enable
vfio_pci_probe_mmaps
for (i = 0; i < PCI_STD_NUM_BARS; i++) -> 6
dummy_res->resource.name = "vfio sub-page reserved"
eeh_dev_open -> eeh_dev_open - 增加 PE 的直通设备计数,@pdev:PCI 设备 增加指定 PE 的直通设备计数。 结果,在 PE 上检测到的 EEH 错误将不会被报告。 PE 所有者将负责检测和恢复 -> Extended Error Handling -> 基于 IBM POWER 的 pSeries 和 iSeries 计算机包括 PCI 总线控制器芯片,这些芯片具有检测和报告各种 PCI 总线错误情况的扩展功能。 这些功能的名称为“EEH”,即“扩展错误处理”。 EEH 硬件功能允许清除 PCI 总线错误并“重新启动”PCI 卡,而无需重新启动操作系统。 这与传统的 PCI 错误处理相反,在传统 PCI 错误处理中,PCI 芯片直接连接到 CPU,错误会导致 CPU 机器检查/检查停止条件,从而完全停止 CPU。 另一种“传统”技术是忽略此类错误,这可能导致用户数据或内核数据的数据损坏、适配器挂起/无响应或系统崩溃/锁定。 因此,EEH 背后的想法是,通过保护操作系统免受 PCI 错误的影响,并赋予操作系统“重新启动”/恢复各个 PCI 设备的能力,操作系统可以变得更加可靠和健壮。 其他供应商基于 PCI-E 规范的未来系统可能包含类似的功能, ref, https://android.googlesource.com/kernel/common/+/bcmdhd-3.10/Documentation/powerpc/eeh-pci-error-recovery.txt
vfio_group_ioctl_get_status
iommu_group_dma_owner_claimed -> Query group dma ownership status -> 多个设备可以放置在同一个 IOMMU 组中,因为它们无法相互隔离。 这些设备必须完全受内核控制或用户空间控制,不能混合。 这在 iommu 核心中添加了 dma 所有权管理,并公开了设备驱动程序和设备用户空间分配框架(即 VFIO)的多个接口,以便可以在一开始就检测到用户和内核控制的 dma 之间的任何冲突。 面向设备驱动程序的接口是 int iommu_device_use_default_domain(struct device *dev); void iommu_device_unuse_default_domain(struct device *dev); 通过调用 iommu_device_use_default_domain(),设备驱动程序告诉 iommu 层设备 dma 是通过内核 DMA API 处理的。 iommu 层将管理 IOVA 并使用默认域进行 DMA 地址转换。 面向设备用户空间分配框架的接口是 int iommu_group_claim_dma_owner(struct iommu_group *group, void *owner); 无效 iommu_group_release_dma_owner(struct iommu_group *group); bool iommu_group_dma_owner_claimed(struct iommu_group *group); 如果 DMA 所有者声明接口返回失败,则必须禁止设备用户空间分配
vfio_group_ioctl_set_container
f = fdget(fd)
container = vfio_container_from_file(f.file)
vfio_container_attach_group
driver->ops->attach_group(container->iommu_data, group->iommu_group, group->type) -> vfio_noiommu_attach_group
list_add(&group->container_next, &container->group_list)
vfio_container_get(container)
iommufd = iommufd_ctx_from_file(f.file)
iommufd_vfio_compat_set_no_iommu
or iommufd_vfio_compat_ioas_create -> 确保创建了 compat IOAS,@ictx:要操作的上下文 兼容性 IOAS 是 vfio 兼容性 ioctls 操作的 IOAS,因为它们的 ABI 中没有 IOAS ID 输入。 仅附加组应该会导致内部 ioas 的默认创建,如果已经以某种方式分配了现有 ioas,则这不会执行任何操作
ioas = iommufd_ioas_alloc(ictx) -> iommufd:vfio容器FD ioctl兼容性,iommufd可以通过将/dev/vfio/vfio容器IOCTL映射到io_pagetable操作来直接实现它们。 用户空间应用程序可以针对 iommufd 进行测试并确认兼容性,然后只需进行一些小更改即可打开 /dev/iommu 而不是 /dev/vfio/vfio。 出于测试目的,/dev/vfio/vfio 可以符号链接到 /dev/iommu,然后所有应用程序将使用兼容性路径,无需更改代码。 后续系列允许 iommufd 直接提供 /dev/vfio/vfio,这也允许 rlimit 模式同样工作。 该系列仅提供 iommufd 方面的兼容性。 实际上将其链接到 VFIO_SET_CONTAINER 是一个后续系列,在求职信中有一个链接。 在内部,兼容性 API 使用普通的 IOAS 对象,该对象与 vfio 一样,在连接第一个设备时自动分配。 用户空间还可以使用 IOMMU_VFIO_IOAS ioctl 直接查询或设置此 IOAS 对象。 这允许混合和匹配新的仅 iommufd 功能,同时仍然使用 VFIO 样式映射/取消映射 ioctl。 虽然这足以操作 qemu,但它有一些差异: - 资源限制依赖于内存 cgroup 来限制用户空间可以执行的操作,而不是模块参数 dma_entry_limit。 - VFIO P2P 未实现。 vfio 的 DMABUF 补丁是 iommufd 导入特殊 DMABUF 的解决方案的开始。 这是为了避免进一步传播 follow_pfn() 安全问题。 - 尚未完成对迂腐兼容性细节(例如 errnos 等)的全面审核 - powerpc SPAPR 被遗漏,因为它未连接到 iommu_domain 框架。 似乎对 SPAPR 的兴趣很小,因为它目前在 v6.1-rc1 中不起作用。 他们必须转换到 iommu 子系统框架才能享受 iommfd。 以下内容不会被实现,我们希望将它们从 VFIO type1 中删除: - 软件访问“脏跟踪”。 正如求职信中所讨论的,这将在 VFIO 中完成
ioas = iommufd_object_alloc(ictx, ioas, IOMMUFD_OBJ_IOAS)
iopt_init_table(&ioas->iopt) -> iommufd:提供 IOVA 到 PFN 映射的数据结构 这是 IOAS 数据结构的其余部分。 提供一个名为 io_pagetable 的对象,该对象由指向 iopt_pages 的 iopt_areas 以及镜像 IOVA 到 PFN 映射的 iommu_domains 列表组成。 顶部是 iopt_areas 的简单区间树,指示 IOVA 到 iopt_pages 的映射。 xarray 跟踪域列表。 基于附加的域,存在区域的最小对齐(可能小于 PAGE_SIZE)、无法映射的保留 IOVA 的间隔树以及始终可映射的允许 IOVA 的 IOVA。 “访问”的概念指的是类似于 VFIO mdev 的东西,它访问 IOVA 并使用“struct page *”进行基于 CPU 的访问。 外部提供了一个 API,该 API 符合 IOCTL 接口对映射/取消映射和域附加的要求。 API 提供“复制”原语,通过重新使用 iopt_pages,在与现有映射不同的 IOAS 中建立新的 IOVA 映射。 这是提供单钉扎的基本机制。 其设计目的是支持预注册流程,其中用户空间将设置一个没有域的虚拟 IOAS,映射到内存中,然后建立将所有 PFN 固定到 xarray 中的访问权限。 然后,可以使用副本在不同的 IOAS 中创建新的 IOVA 映射,并附加 iommu_domains。 复制后,将从 xarray 中读取 PFN 并将其映射到 iommu_domains 中,从而避免任何 pin_user_pages() 开销
iopt->area_itree = RB_ROOT_CACHED
iopt->allowed_itree = RB_ROOT_CACHED
iopt->reserved_itree = RB_ROOT_CACHED
xa_init_flags(&iopt->domains, XA_FLAGS_ACCOUNT)
xa_init_flags(&iopt->access_list, XA_FLAGS_ALLOC)
INIT_LIST_HEAD(&ioas->hwpt_list) -> iommufd:添加一个硬件页表对象,hw_pagetable 对象将内部结构 iommu_domain 暴露给用户空间。 当任何 DMA 设备连接到 IOAS 以通过 iommu 驱动程序控制 io 页表时,需要 iommu_domain。 为了与 VFIO 兼容,当 DMA 设备连接到 IOAS 时,会自动创建 hw_pagetable。 如果兼容的 iommu_domain 已存在,则与其关联的 hw_pagetable 将用于附件。 在最初的系列中,hw_pagetable 对象没有 iommufd uAPI。 下一个补丁提供面向驱动程序的 IO 页表附加 API,允许驱动程序接受 IOAS 或 hw_pagetable ID,并让驱动程序返回从 IOAS 自动选择的 hw_pagetable ID。 期望驱动程序将通过其自己的 FD 提供 uAPI,以将其设备附加到 iommufd。 这允许用户空间了解设备到 iommu_domains 的映射并覆盖自动连接。 未来的硬件特定接口将允许用户空间使用带有 IOMMU 驱动程序特定参数的 iommu_domains 创建 hw_pagetable 对象。 该基础设施将允许将这些域链接到 IOAS 和设备
iommufd_object_finalize -> 允许并发访问该对象,一旦另一个线程可以看到该对象指针,就可以防止对象销毁。 除了特殊的仅内核对象之外,没有内核方法可以可靠地销毁单个对象。 因此,所有创建对象的 API 都必须使用 iommufd_object_abort() 来处理错误,并且只有在对象创建不会失败时才调用 iommufd_object_finalize()
old = xa_store(&ictx->objects, obj->id, obj, GFP_KERNEL)
vfio_group_ioctl_unset_container
vfio_group_detach_container
driver->ops->detach_group(container->iommu_data,VFIO代码示例
# vfio code demo:
int container, group, device, i;
struct vfio_group_status group_status =
{ .argsz = sizeof(group_status) };
struct vfio_iommu_type1_info iommu_info = { .argsz = sizeof(iommu_info) };
struct vfio_iommu_type1_dma_map dma_map = { .argsz = sizeof(dma_map) };
struct vfio_device_info device_info = { .argsz = sizeof(device_info) };
/* Create a new container */
container = open("/dev/vfio/vfio", O_RDWR);
if (ioctl(container, VFIO_GET_API_VERSION) != VFIO_API_VERSION)
/* Unknown API version */
if (!ioctl(container, VFIO_CHECK_EXTENSION, VFIO_TYPE1_IOMMU))
/* Doesn't support the IOMMU driver we want. */
/* Open the group */
group = open("/dev/vfio/26", O_RDWR);
/* Test the group is viable and available */
ioctl(group, VFIO_GROUP_GET_STATUS, &group_status);
if (!(group_status.flags & VFIO_GROUP_FLAGS_VIABLE))
/* Group is not viable (ie, not all devices bound for vfio) */
/* Add the group to the container */
ioctl(group, VFIO_GROUP_SET_CONTAINER, &container);
/* Enable the IOMMU model we want */
ioctl(container, VFIO_SET_IOMMU, VFIO_TYPE1_IOMMU);
/* Get addition IOMMU info */
ioctl(container, VFIO_IOMMU_GET_INFO, &iommu_info);
/* Allocate some space and setup a DMA mapping */
dma_map.vaddr = mmap(0, 1024 * 1024, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, 0, 0);
dma_map.size = 1024 * 1024;
dma_map.iova = 0; /* 1MB starting at 0x0 from device view */
dma_map.flags = VFIO_DMA_MAP_FLAG_READ | VFIO_DMA_MAP_FLAG_WRITE;
ioctl(container, VFIO_IOMMU_MAP_DMA, &dma_map);
/* Get a file descriptor for the device */
device = ioctl(group, VFIO_GROUP_GET_DEVICE_FD, "0000:06:0d.0");
/* Test and setup the device */
ioctl(device, VFIO_DEVICE_GET_INFO, &device_info);
for (i = 0; i < device_info.num_regions; i++) {
struct vfio_region_info reg = { .argsz = sizeof(reg) };
reg.index = i;
ioctl(device, VFIO_DEVICE_GET_REGION_INFO, ®);
/* Setup mappings... read/write offsets, mmaps
* For PCI devices, config space is a region */
}
for (i = 0; i < device_info.num_irqs; i++) {
struct vfio_irq_info irq = { .argsz = sizeof(irq) };
irq.index = i;
ioctl(device, VFIO_DEVICE_GET_IRQ_INFO, &irq);
/* Setup IRQs... eventfds, VFIO_DEVICE_SET_IRQS */
}
/* Gratuitous device reset and go... */
ioctl(device, VFIO_DEVICE_RESET);
struct vfio_device_bind_iommufd bind = {
.argsz = sizeof(bind),
.flags = 0,
};
struct iommu_ioas_alloc alloc_data = {
.size = sizeof(alloc_data),
.flags = 0,
};
struct vfio_device_attach_iommufd_pt attach_data = {
.argsz = sizeof(attach_data),
.flags = 0,
};
struct iommu_ioas_map map = {
.size = sizeof(map),
.flags = IOMMU_IOAS_MAP_READABLE |
IOMMU_IOAS_MAP_WRITEABLE |
IOMMU_IOAS_MAP_FIXED_IOVA,
.__reserved = 0,
};
iommufd = open("/dev/iommu", O_RDWR);
bind.iommufd = iommufd;
ioctl(cdev_fd, VFIO_DEVICE_BIND_IOMMUFD, &bind);
ioctl(iommufd, IOMMU_IOAS_ALLOC, &alloc_data);
attach_data.pt_id = alloc_data.out_ioas_id;
ioctl(cdev_fd, VFIO_DEVICE_ATTACH_IOMMUFD_PT, &attach_data);
/* Allocate some space and setup a DMA mapping */
map.user_va = (int64_t)mmap(0, 1024 * 1024, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, 0, 0);
map.iova = 0; /* 1MB starting at 0x0 from device view */
map.length = 1024 * 1024;
map.ioas_id = alloc_data.out_ioas_id;;
ioctl(iommufd, IOMMU_IOAS_MAP, &map);
/* Other device operations as stated in "VFIO Usage Example" */DPDK使用VFIO
helloworld -> examples/helloworld/main.c
main(int argc, char **argv)
rte_eal_init(int argc, char **argv)
rte_eal_get_configuration
eal_get_internal_configuration
rte_cpu_is_supported
RTE_COMPILE_TIME_CPUFLAGS -> #define RTE_COMPILE_TIME_CPUFLAGS RTE_CPUFLAG_SSE,RTE_CPUFLAG_SSE2,RTE_CPUFLAG_SSE3,RTE_CPUFLAG_SSSE3,RTE_CPUFLAG_SSE4_1,RTE_CPUFLAG_SSE4_2,RTE_CPUFLAG_AES,RTE_CPUFLAG_AVX,RTE_CPUFLAG_AVX2,RTE_CPUFLAG_AVX512BW,RTE_CPUFLAG_AVX512CD,RTE_CPUFLAG_AVX512DQ,RTE_CPUFLAG_AVX512F,RTE_CPUFLAG_AVX512VL,RTE_CPUFLAG_PCLMULQDQ,RTE_CPUFLAG_RDRAND,RTE_CPUFLAG_RDSEED
rte_cpu_get_flag_enabled
rte_cpu_feature_table
__get_cpuid_max(feat->leaf & 0x80000000, NULL)
const struct feature_entry rte_cpu_feature_table[]
__atomic_compare_exchange_n
eal_reset_internal_config
internal_cfg->iova_mode = RTE_IOVA_DC -> default memory mode
eal_log_level_parse -> set_log demo: ./app/test-pmd --log-level='pmd\.i40e.*,8' -> 现在正确设置 --log-level=7 不会打印来自 rte_eal_cpu_init() 例程的消息
eal_save_args -> Connecting to /var/run/dpdk/rte/dpdk_telemetry.v2
handle_eal_info_request
rte_tel_data_start_array
rte_tel_data_add_array_string
rte_eal_cpu_init -> eal:不要对CPU检测感到恐慌,可能没有办法优雅地恢复,但是应该通知应用程序发生了故障,而不是完全中止。 这允许用户继续使用“慢路径”类型的解决方案。 进行此更改后,EAL CPU NUMA 节点解析步骤不再发出 rte_panic。 这与 rte_eal_init 中的代码一致,该代码期望失败返回错误代码 -> 使用物理和逻辑处理器的数量填充配置 此函数是 EAL 专用的。 解析 /proc/cpuinfo 以获取计算机上的物理和逻辑处理器的数量, /sys/devices/system/cpu
eal_cpu_socket_id -> NUMA_NODE_PATH "/sys/devices/system/node"
eal_cpu_detected -> eal:不缓存 lcore 检测状态,我们仅在服务核心和 -c/-l 选项的控制路径中使用此状态。 使用--lcores 时,该值不会更新。 在需要的地方使用内部助手
eal_parse_args
while ((opt = getopt_long
eal_parse_common_option
-l 和 -c 选项是选择 DPDK 使用的内核的两种方法。 它们的格式不同,但对所选核心的检查是相同的。 使用中间数组将特定的解析检查与常见的一致性检查分开。 解析函数现在专注于验证传递的字符串,而不执行其他操作。 我们可以报告所有无效的核心索引,而不仅仅是第一个错误。 在错误日志消息中,当核心列表不连续时,将 [0, cfg->lcore_count - 1] 报告为有效范围是错误的
eal_service_cores_parsed
rte_eal_parse_coremask
update_lcore_config
-n -> conf->force_nchannel = atoi(optarg)
eal_create_runtime_dir -> eal:即使不使用共享数据,也创建运行时目录,当不需要多进程并且DPDK使用“no-shconf”标志运行时,遥测库仍然需要一个运行时目录来放置用于遥测连接的unix套接字。 因此,我们可以更改代码以尝试创建目录,而不是在设置此标志时不创建目录,但如果失败则不会出错。 如果成功,则遥测将可用,但如果失败,DPDK 的其余部分将在没有遥测的情况下运行。 这确保了“内存中”标志将允许 DPDK 运行,即使整个文件系统是只读的
/var/run/dpdk
eal_get_hugefile_prefix
eal_set_runtime_dir
strlcpy(runtime_dir, run_dir, PATH_MAX)
eal_adjust_config
eal_auto_detect_cores -> eal:限制核心自动检测,当未指定以下选项时,此补丁使用 pthread_getaffinity_np() 来缩小使用的核心范围: * coremask (-c) * corelist (-l) * 和 coremap (--lcores) 这样做的目的 patch的目的是在容器环境下部署DPDK应用程序时省略这些核心相关选项,以便用户在开发应用程序时不需要决定核心相关参数。 相反,当应用程序部署在容器中时,请使用 cpu-set 来限制可以在该容器实例内使用哪些核心。 而容器内的DPDK应用程序只是依靠这种自动检测机制来启动轮询线程。 注意:之前有部分用户使用隔离CPU,默认可以排除。 请添加任务集等命令来使用这些核心。 测试示例: $taskset 0xc0000 ./examples/helloworld/build/helloworld -m 1024
rte_thread_get_affinity_by_id
eal_proc_type_detect
main_lcore_parsed -> eal:重命名lcore master和slave,将master lcore替换为main lcore,并将slave lcore替换为worker lcore。 保留旧函数和宏,但将它们标记为在此版本中已弃用。 “--master-lcore”命令行选项也已弃用,任何使用都会打印警告并使用“--main-lcore”作为替换
compute_ctrl_threads_cpuset -> eal:限制控制线程启动 CPU 亲和力,在不属于 eal coremask 的任何内容上生成 ctrl 线程对系统的其余部分来说不太礼貌,尤其是当您非常小心地使用工具将进程固定在 cpu 资源上时 像任务集(linux)/cpuset(freebsd)。 我们不再引入另一个 eal 选项来控制在哪个 cpu 上创建这些 ctrl 线程,而是以启动 cpu 亲和力作为参考并从中删除 eal coremask。 如果没有剩下 cpu,那么我们默认为主核心。 cpuset 在 init 时计算一次,然后原始 cpu 关联性就会丢失。 引入了一个RTE_CPU_AND宏来抽象linux和freebsd各自宏之间的差异 -> taskset -c 7 ./master/app/testpmd --master-lcore 0 --lcores '(0,7)@(7,4,5)' --no-huge --no-pci -m 512 -- -i --total-num-mbufs=2048
RTE_CPU_AND
eal_check_common_options -> sanity checks -> eal:分解选项健全性检查,无需对常见选项进行重复检查。 为选项 -c 和 -m 设置一些标志以简化检查
Main lcore
mbuf_pool ...
eal_usage
eal_common_usage -> help
eal_plugins_init -> eal: 在设备解析之前调用插件 init,默认 eal_init 代码调用 0. eal_plugins_init 1. eal_option_device_parse 2. rte_bus_scan IOVA 提交:cf408c224 错过了在 eal_option_device_parse、rte_bus_scan 之前调用 eal_plugins_init 以及下面引入的共享模式回归:使用 CONFIG_RTE_BUILD_SHARED_LIB=y: 'net_vhost 0 ,iface=/tmp/vhost-user2' -d ./install/lib/librte_pmd_vhost.so -- --portmask=1 --disable-hw-vlan -i --rxq=1 --txq=1 --nb -cores=1 --eth-peer=0,52:54:00:11:22:12 EAL:检测到 4 个 lcore 错误:无法解析设备“net_vhost0”EAL:无法解析设备“net_vhost0,iface” =/tmp/vhost-user2' main() 中发生恐慌:无法初始化 EAL
如果我们不是静态链接,请添加默认驱动程序加载路径(如果它作为目录存在)。 (在 EAL 上使用带有 NOLOAD 标志的 dlopen,如果 EAL 共享库尚未加载,即它是静态链接的,则将返回 NULL
is_shared_build
#define EAL_SO "librte_eal.so
handle = dlopen(soname, RTLD_LAZY | RTLD_NOLOAD)
eal_plugin_add -> eal:支持从目录加载驱动程序,添加对目录的支持作为 -d 的参数,以从给定目录加载所有驱动程序。 此外,可以在构建时配置中设置默认驱动程序目录,在这种情况下,在初始化 EAL 时将始终使用该目录。 与使用 -d 手动加载单个驱动程序相比,这大大简化了共享库配置的使用,并允许发行版建立一个嵌入式驱动程序目录,以便与第 3 方驱动程序等无缝集成
-> #define RTE_EAL_PMD_PATH "/usr/local/lib/x86_64-linux-gnu/dpdk/pmds-23.1"
TAILQ_FOREACH
eal_plugindir_init
eal_dlopen
rte_config_init
rte_eal_config_create
mem_cfg_fd = open(pathname, O_RDWR | O_CREAT, 0600)
retval = ftruncate(mem_cfg_fd, cfg_len)
retval = fcntl(mem_cfg_fd, F_SETLK, &wr_lock)
eal_get_virtual_area -> eal:修复多进程的内存配置分配,目前,内存配置将在不使用虚拟区域预留基础设施的情况下进行映射,这意味着它将被映射到任意位置。 这可能会导致在辅助进程中映射共享配置失败,因为 PCI 白名单参数在主进程已分配共享内存配置的空间中分配内存。 通过使用虚拟区域预留来为内存配置预留空间来修复此问题,从而避免该问题并保留共享配置(希望如此)远离任何正常的内存分配
rte_mem_page_size -> eal:引入内存管理包装器,引入独立于操作系统的包装器,用于跨DPDK使用的内存管理操作,特别是在EAL的公共代码中: * rte_mem_map() * rte_mem_unmap() * rte_mem_page_size() * rte_mem_lock() Windows使用不同的API进行内存映射 和保留,而 Unices 通过映射来保留内存。 引入 EAL 私有函数以支持公共代码中的内存预留: * eal_mem_reserve() * eal_mem_free() * eal_mem_set_dump() 包装器遵循仅限于 DPDK 任务的 POSIX 语义,但它们的签名故意与 POSIX 签名不同,以更加安全和更具表现力。 新符号是内部的。 由于包装很薄,因此不需要特殊维护
eal_get_baseaddr -> Linux 内核使用一个非常高的地址作为服务 mmap 调用的起始地址。 如果存在寻址限制并且 IOVA 模式为 VA,则该起始地址对于这些设备来说可能太高。 但是,可以在进程虚拟地址空间中使用较低的地址,因为 64 位有大量可用空间。 当前已知的限制是 39 或 40 位。 将起始地址设置为 4GB 意味着有 508GB 或 1020GB 用于映射可用的大页。 这对于大多数系统来说可能已经足够了,尽管具有寻址限制的设备应该调用 rte_mem_check_dma_mask 以确保所有内存都在支持的范围内
return 0x7000000000ULL -> 28GB = int("0x700000000", 16)/(1<<30)
or
return 0x100000000ULL -> 4GB
eal_mem_reserve
int sys_flags = MAP_PRIVATE | MAP_ANONYMOUS;
sys_flags |= MAP_HUGETLB
mem_map(requested_addr, size, PROT_NONE, sys_flags, -1, 0)
RTE_PTR_ALIGN
mapped_mem_cfg_addr = mmap(rte_mem_cfg_addr,
cfg_len_aligned, PROT_READ | PROT_WRITE,
MAP_SHARED | MAP_FIXED, mem_cfg_fd, 0);
eal_mcfg_update_from_internal
mcfg->single_file_segments = internal_conf->single_file_segments
rte_eal_config_attach
eal_mcfg_wait_complete
__rte_mp_enable
rte_eal_using_phys_addrs -> eal:根据PA可用性计算IOVA模式,目前,如果总线选择IOVA作为PA,则在缺乏对物理地址的访问时,内存初始化可能会失败。 对于普通用户来说,这可能很难理解出了什么问题,因为这是默认行为。 通过验证物理地址可用性,在 eal init 中尽早发现这种情况,或者在没有表达明确的偏好时选择 IOVA。 总线代码已更改,以便它在不关心 IOVA 模式时进行报告,并让 eal init 决定。 在Linux实现中,重新设计rte_eal_using_phys_addrs(),以便可以更早地调用它,但仍然避免与rte_mem_virt2phys()的循环依赖。 在 FreeBSD 实现中,rte_eal_using_phys_addrs() 始终返回 false,因此检测部分保持原样。 如果编译了librte_kni并加载了KNI kmod, - 如果总线请求VA,如果物理地址可用,则强制使用PA,就像之前所做的那样, - 否则,将iova保留为VA,KNI init稍后将失败
rte_eal_has_hugepages -> no_hugetlbfs -> default use hugepage
rte_mem_virt2phy
return RTE_BAD_IOVA
rte_bus_get_iommu_class
if (internal_conf->no_hugetlbfs == 0)
hugepage_info_init
create_shared_memory
map_sharee_memory
...
RTE_LOG(DEBUG, EAL, "IOMMU is not available, selecting IOVA as PA mode.\n")
rte_eal_get_configuration
eal_hugepage_info_init
eal_log_init
rte_eal_vfio_setup // DPDK设置VFIO
rte_eal_memzone_init
eal_hugedirs_unlock
rte_eal_malloc_heap_init
rte_eal_tailqs_init
rte_eal_timer_init
eal_check_mem_on_local_socket
rte_thread_set_affinity_by_id
eal_thread_dump_current_affinity
RTE_LCORE_FOREACH_WORKER(i)
eal_worker_thread_create(i)
rte_eal_mp_remote_launch sync_func
rte_eal_mp_wait_lcore
rte_service_init
if (rte_bus_probe())
rte_vfio_is_enabled
rte_service_start_with_defaults
eal_clean_runtime_dir
rte_log_register_type_and_pick_level
rte_telemetry_init
eal_mcfg_complete
rte_eal_remote_launch(lcore_hello, NULL, lcore_id)
lcore_hello
...
rte_eal_vfio_setup
rte_vfio_enable("vfio")
for (i = 0; i < VFIO_MAX_CONTAINERS; i++) -> 64
for (j = 0; j < VFIO_MAX_GROUPS; j++) -> 64
vfio_available = rte_eal_check_module(modname) -> vfio:避免在模块未加载时启用,当内核支持 vfio 功能时未加载 vfio 模块时,例程仍尝试打开容器以获取文件描述。 此操作不安全,当然会收到错误消息: EAL: Detected 40 lcore(s) EAL: unsupported IOMMU type! EAL: VFIO 支持无法初始化 EAL: 设置内存...这可能会让用户感到困惑,这个补丁使用户更合理、更流畅
/sys/module/vfio
default_vfio_cfg->vfio_container_fd = rte_vfio_get_container_fd()
open(VFIO_CONTAINER_PATH, O_RDWR) -> open /dev/vfio/vfio
or vfio_get_default_container_fd
static const struct vfio_iommu_type iommu_types[]参考
Linux kernel vfio, https://docs.kernel.org/driver-api/vfio.html
IOMMUFD, https://docs.kernel.org/userspace-api/iommufd.html
VFIO虚拟化中介设备, https://docs.kernel.org/driver-api/vfio-mediated-device.html
vfio-pci 设备特定驱动程序验收标准(vfio-pci-core模块), https://docs.kernel.org/driver-api/vfio-pci-device-specific-driver-acceptance.html
VFIO驱动分析: https://terenceli.github.io/%E6%8A%80%E6%9C%AF/2019/08/21/vfio-driver-analysis
VFIO简介: https://insujang.github.io/2017-04-27/introduction-to-vfio/
VFIO详解: https://zhuanlan.zhihu.com/p/651145174
RedHat红帽VFIO简介: https://awilliam.github.io/presentations/KVM-Forum-2016/#/1
VFIO代码分析(7)QEMU中VFIO实例化2: https://blog.csdn.net/flyingnosky/article/details/123748011
Intel VT-d虚拟化技术与VFIO: https://wiki.qemu.org/Features/VT-d
Linux管道工大会: https://lpc.events/blog/current/index.php/2023/08/21/vfio-iommu-pci-mc-cfp/
晓兵(ssbandjl)
博客: https://cloud.tencent.com/developer/user/5060293/articles | https://logread.cn | https://blog.csdn.net/ssbandjl | https://www.zhihu.com/people/ssbandjl/posts | https://chattoyou.cn
DPU专栏
https://cloud.tencent.com/developer/column/101987
技术会友: 欢迎对DPU/智能网卡/卸载/网络,存储加速/安全隔离等技术感兴趣的朋友加入DPU技术交流群
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。