[Vision Board创客营]--使用openmv识别阿尼亚

[Vision Board创客营]使用openmv识别阿尼亚
🚀🚀五一和女朋友去看了《间谍过家家 代号:白》,入坑二刺螈(QQ头像也换阿尼亚了😄 😆 😊 😃),刚好不知道做什么项目来交作业,突然想到可以做一个阿尼亚识别器,于是有了这篇文章。 🚀🚀水平较菜,大佬轻喷。😰😰😰
介绍
🚀🚀Vision-Board 开发板是 RT-Thread 推出基于瑞萨 Cortex-M85 架构 RA8D1 芯片,为工程师们提供了一个灵活、全面的开发平台,助力开发者在机器视觉领域获得更深层次的体验。
🚀🚀Vision Board搭载全球首颗 480 MHz Arm Cortex-M85芯片,拥有Helium和TrustZone技术的加持。SDK包里集成了OpenMV机器视觉例程,配合MicroPython 解释器,使其可以流畅地开发机器视觉应用。
环境搭建
🚀🚀环境搭建可以查看这个Vision Board 环境搭建文档(https://docs.qq.com/doc/DY2hkbVdiSGV1S3JM),特别需要注意的就是,版本一定要新,我使用之前老版的RASC是不行的,如果开发过程中遇到奇奇怪怪的问题,可以首先检查自己版本的问题。
🚀🚀我们使用openmv只需要烧录官方的openmv demo就好了,官方视频教程以及文档已经很详细了,我就不重复介绍了,只需要把demo烧录进来就好了。
训练模型
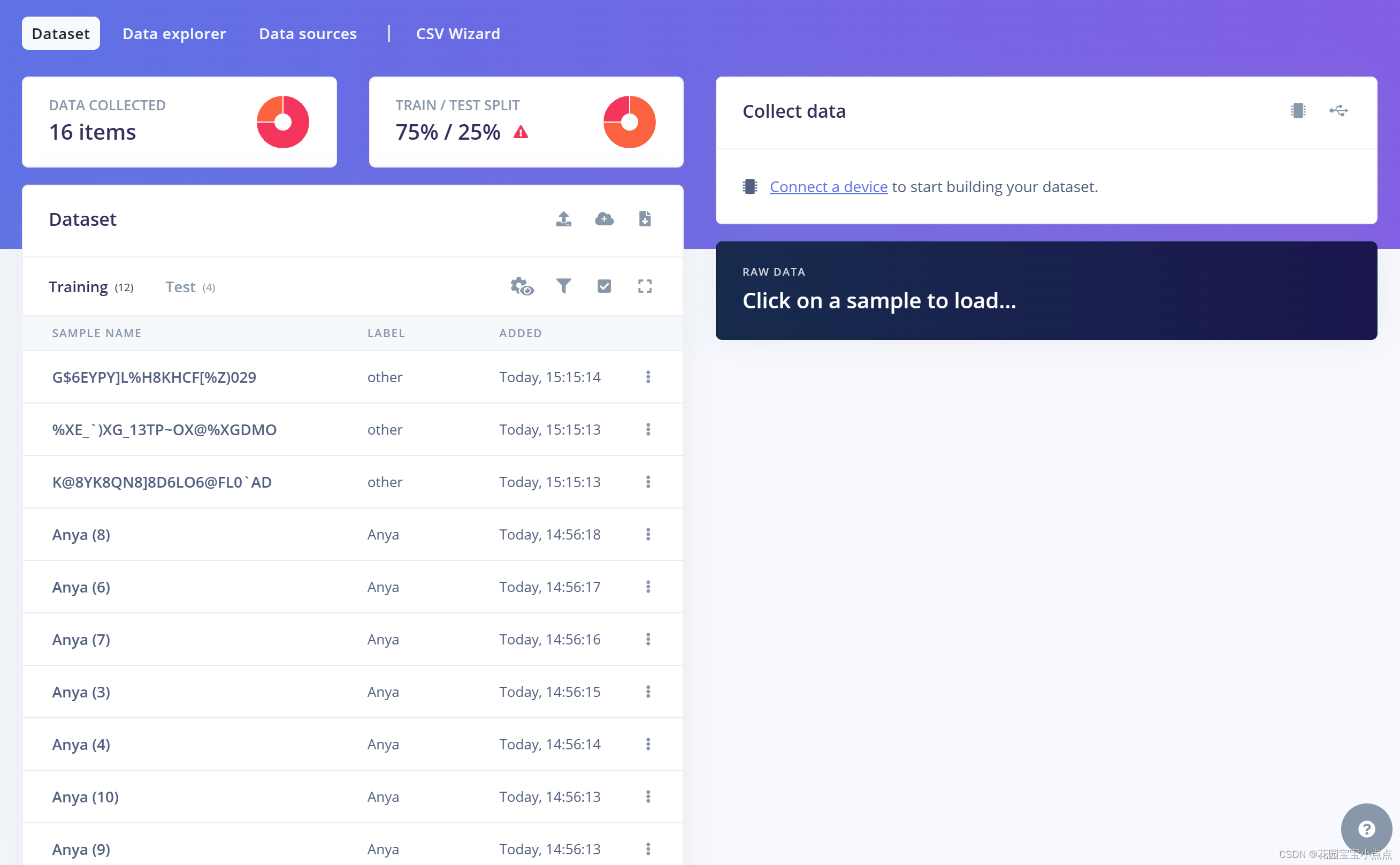
🚀🚀训练模型我们使用的是edge impulse (https://studio.edgeimpulse.com/),首先准备大量的阿尼亚图片作为数据集,这里我测试的时候只选了11张,肯定是太少了,大家可以多几张,这样效果会更准确,识别精度更高,我这里只是测试学习用的,大家请勿模仿。
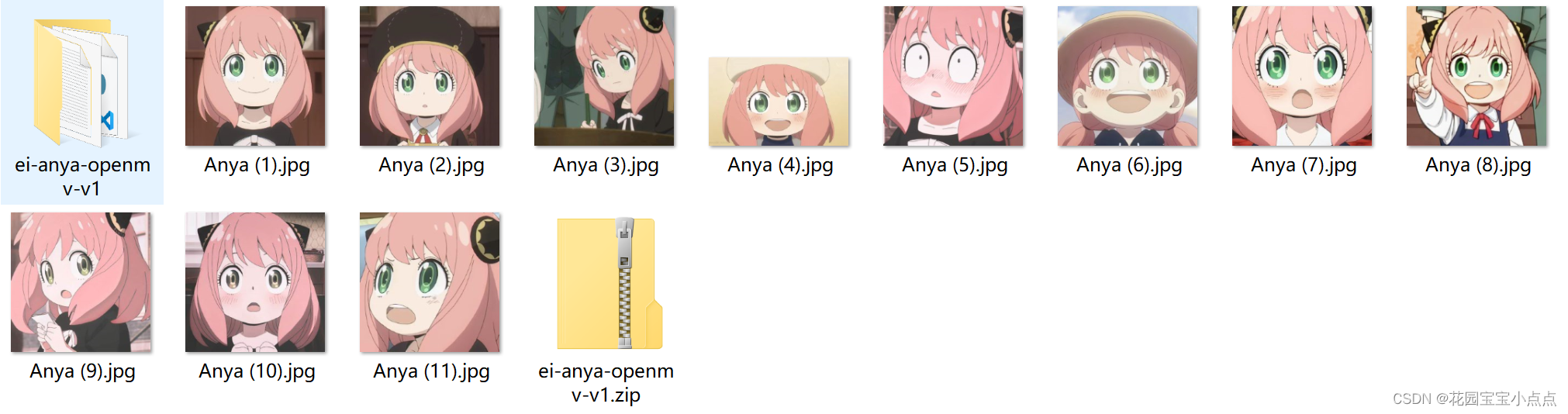
🚀🚀然后我们还需要准备一份其他的图片用来训练,因为训练模型必须两类及以上,这里我选择了几张花园宝宝的图片(就不一一展示了),大家可以自己更换其他的:

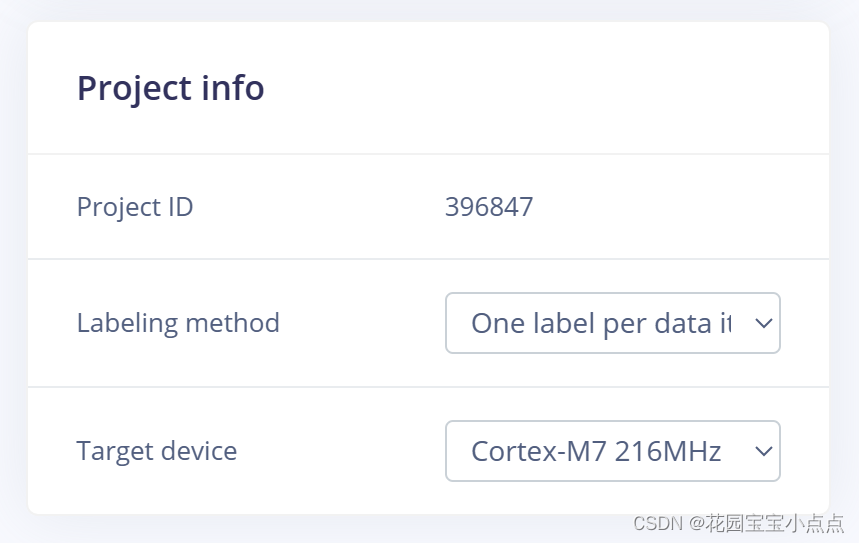
🚀🚀之后我们进入edge impulse,进行简单的设置,选择One label per data item(每个数据项一个标签)以及M7,然后就可以上传图片进行训练了。
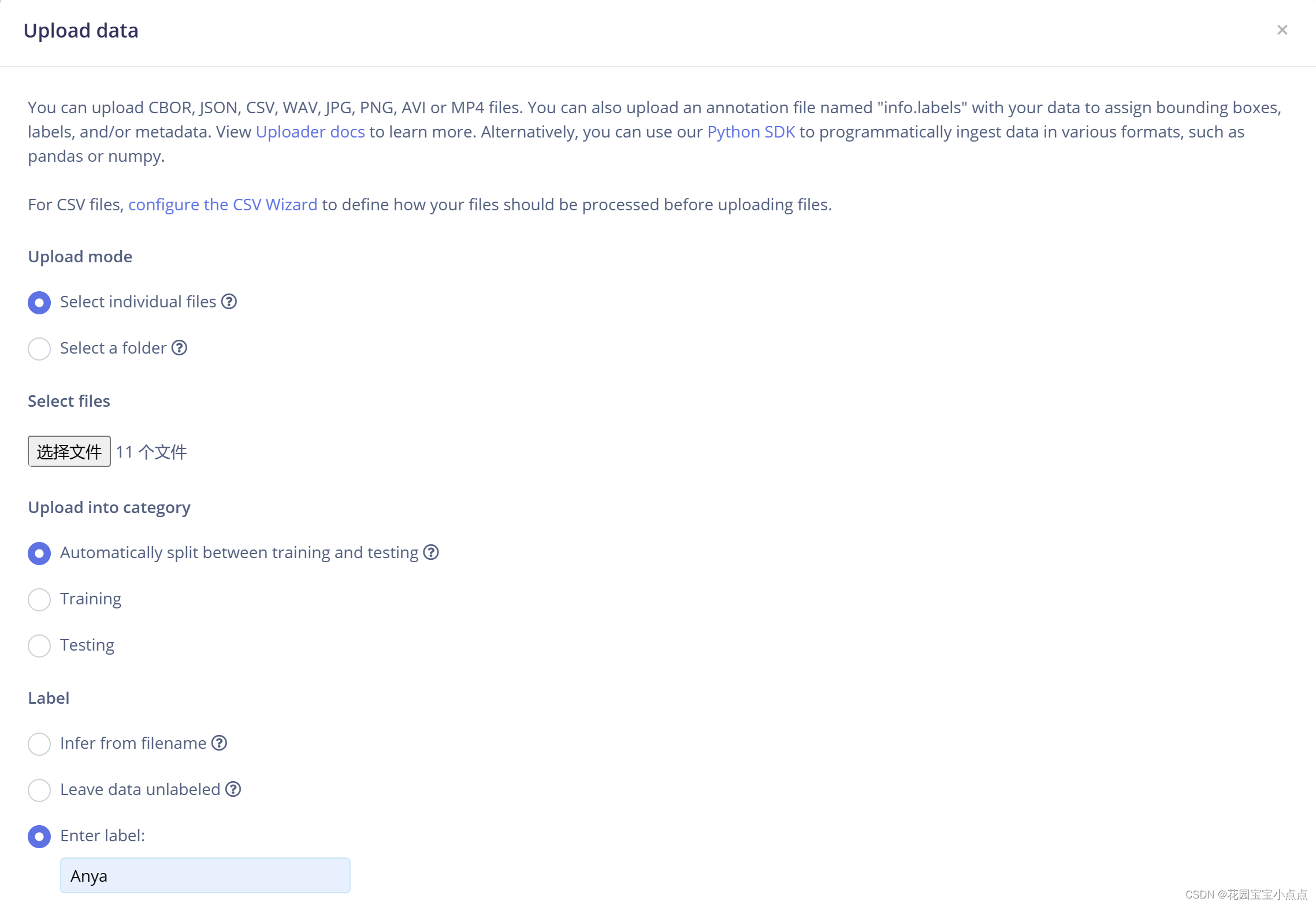
上传图片
🚀🚀选择图片进行上传,我们先上传阿尼亚的图片。
🚀🚀这个地方注意,如果上传失败,大概率网络问题,要关闭加速器(神奇,我特地开的加速器😰)。
🚀🚀再上传其他的,如下所示:
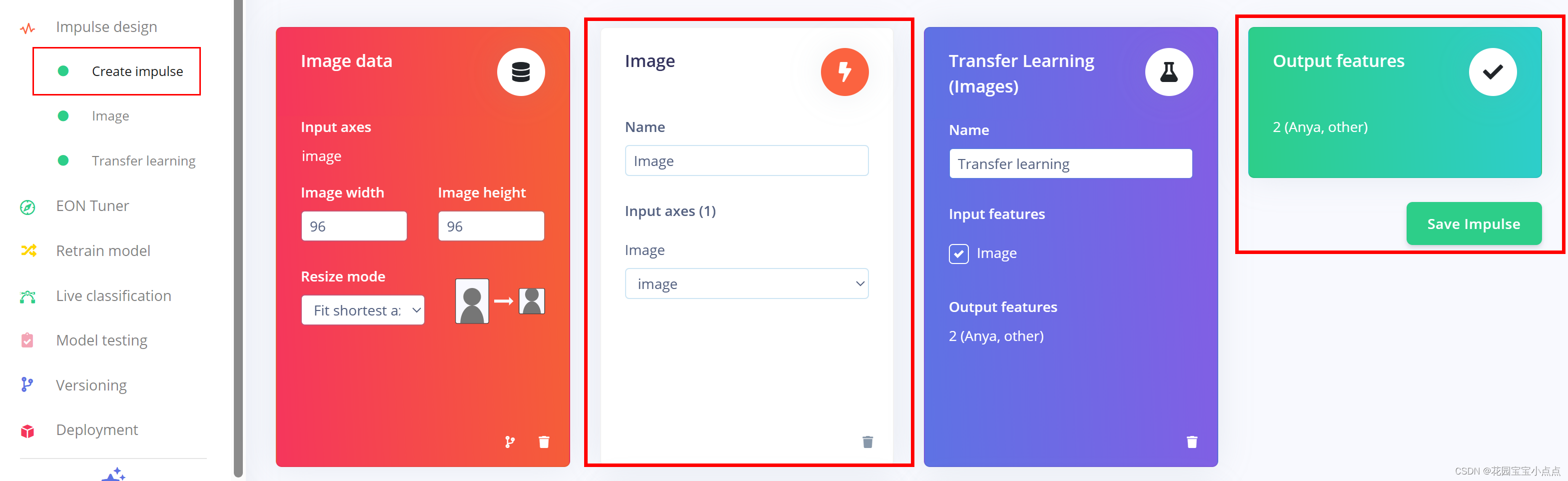
生成模型
🚀🚀之后就到impulse design里面训练模型,差不多一直默认就好,比较简单。
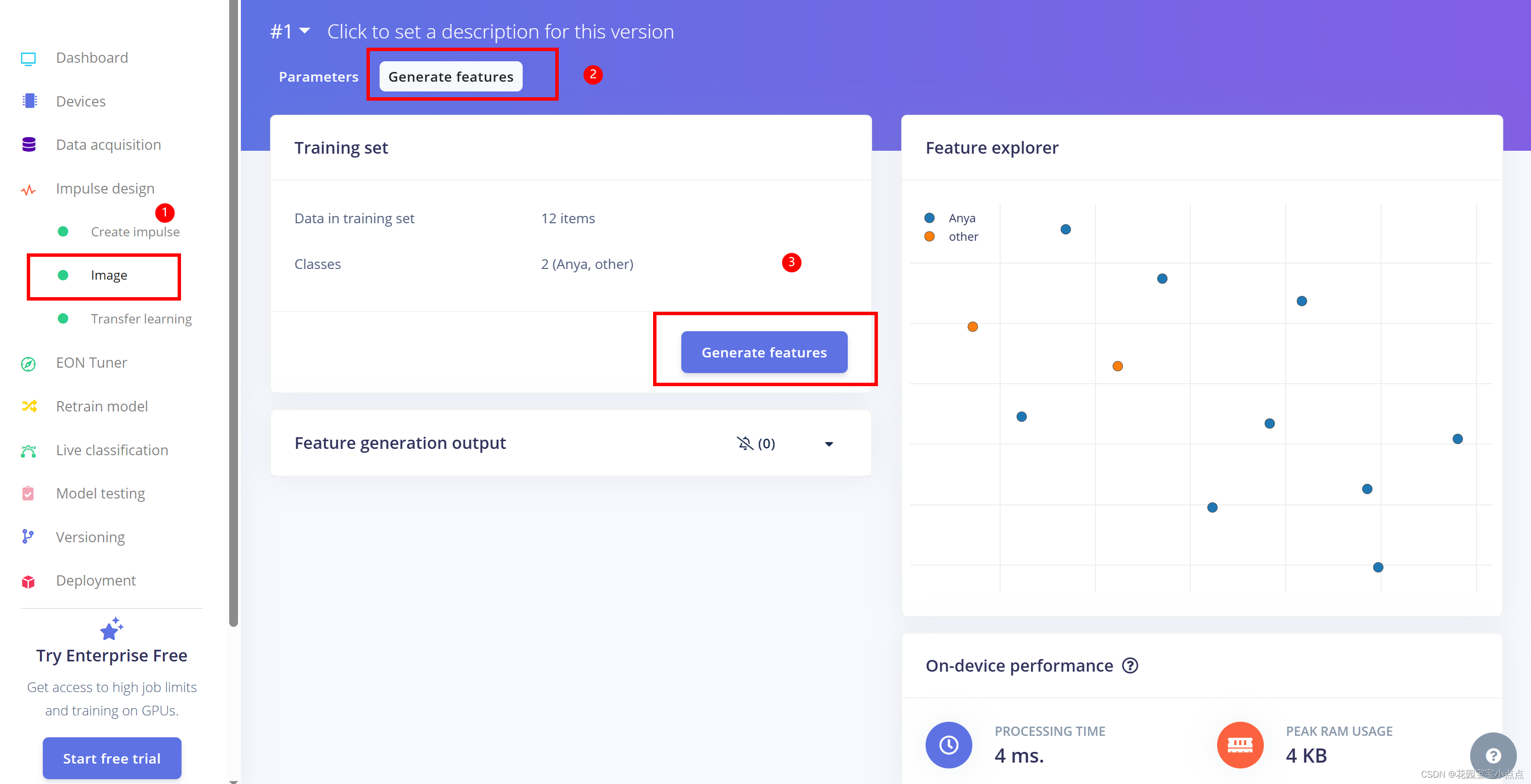
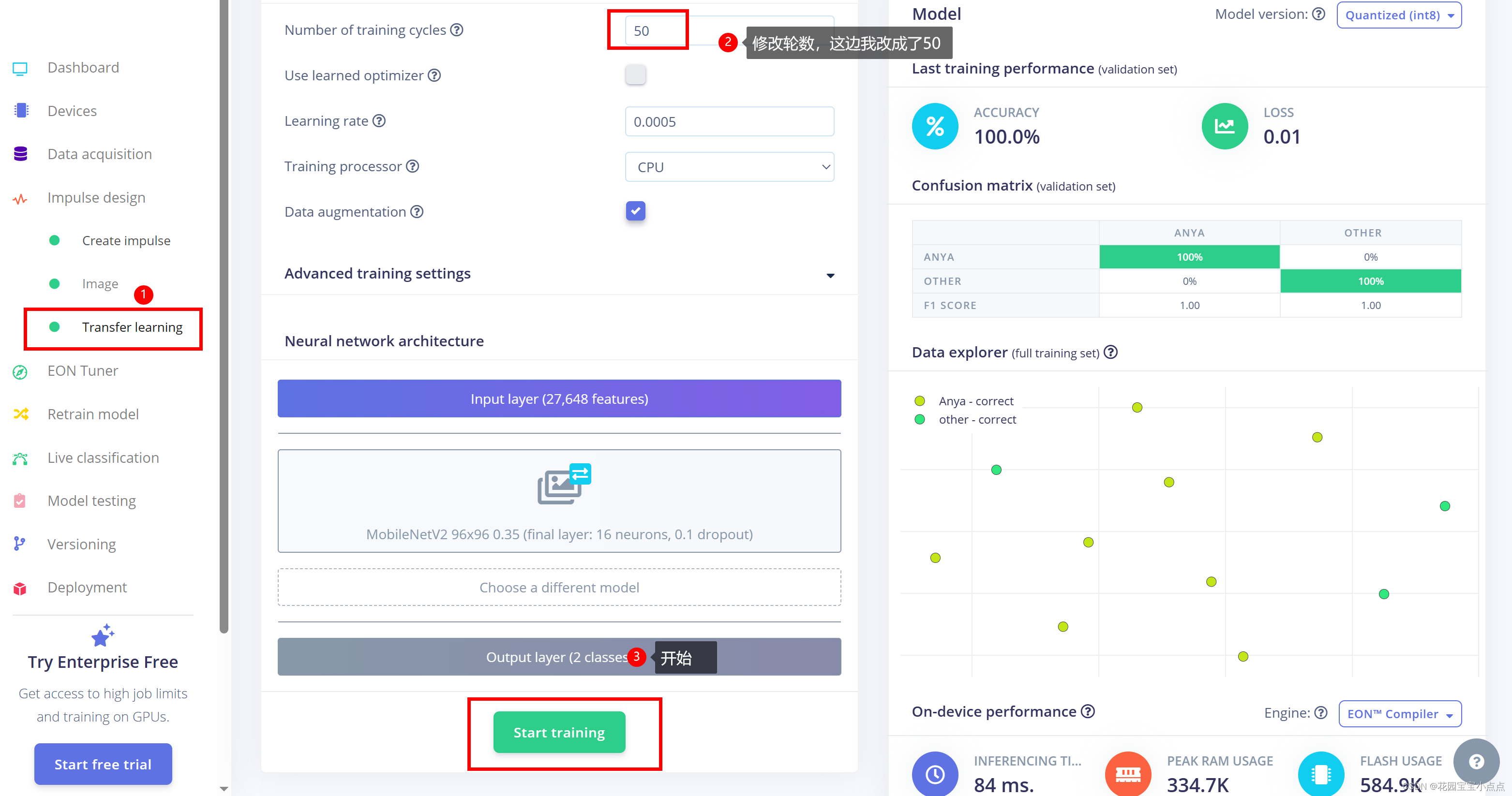
🚀🚀训练结束就好了,然后直接生成模型。
🚀🚀就会有一个压缩包下载,我们打开压缩包就能发现模型,到这里,训练模型部分就结束了。
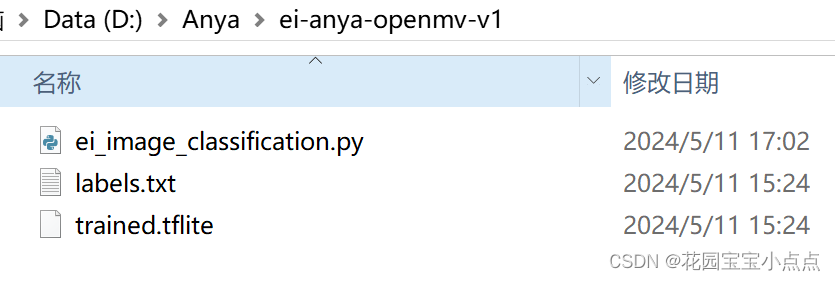
使用
🚀🚀然后我们把labels.txt和trained.tflite放入openmv的SD里面去,同时需要新建一个captures文件夹用来存放图片,复制py文件到openmv IDE 里面去,就可以直接运行了,这里我对自动生成的程序做了一点修改,加上了LED灯,拍摄以及红框,结果如下(简陋的代码,甚至没封装,太懒了😭😭😭):
# This work is licensed under the MIT license.
# Copyright (c) 2013-2023 OpenMV LLC. All rights reserved.
# https://github.com/openmv/openmv/blob/master/LICENSE
#
# Hello World Example
#
# Welcome to the OpenMV IDE! Click on the green run arrow button below to run the script!
import sensor, image, time, os, tf, uos, gc
from machine import LED
sensor.reset() # Reset and initialize the sensor.
sensor.set_pixformat(sensor.RGB565) # Set pixel format to RGB565 (or GRAYSCALE)
sensor.set_framesize(sensor.QVGA) # Set frame size to QVGA (320x240)
sensor.set_windowing((240, 240)) # Set 240x240 window.
sensor.skip_frames(time=2000) # Let the camera adjust.
net = None
labels = None
led = LED("LED_BLUE")
try:
# load the model, alloc the model file on the heap if we have at least 64K free after loading
net = tf.load("trained.tflite", load_to_fb=uos.stat('trained.tflite')[6] > (gc.mem_free() - (64*1024)))
except Exception as e:
print(e)
raise Exception('Failed to load "trained.tflite", did you copy the .tflite and labels.txt file onto the mass-storage device? (' + str(e) + ')')
try:
labels = [line.rstrip('\n') for line in open("labels.txt")]
except Exception as e:
raise Exception('Failed to load "labels.txt", did you copy the .tflite and labels.txt file onto the mass-storage device? (' + str(e) + ')')
clock = time.clock()
last_capture_time = time.time()
while(True):
clock.tick()
img = sensor.snapshot()
for obj in net.classify(img, min_scale=1.0, scale_mul=0.8, x_overlap=0.5, y_overlap=0.5):
img.draw_rectangle(obj.rect())
# This combines the labels and confidence values into a list of tuples
predictions_list = list(zip(labels, obj.output()))
x1, y1, w1, h1 = obj.rect()
margin = 10 # 设置一个边距,避免紧贴头像边缘
x1 += margin
y1 += margin
w1 -= margin * 2
h1 -= margin * 2
if (predictions_list[0][1] > 0.95):
img.draw_rectangle((x1, y1, w1, h1), color=(255, 0, 0)) # 在检测到的对象周围绘制红色矩形框
led.on()
print("Anya")
print("********")
if time.time() - last_capture_time >= 2: # 检查距离上次拍照是否已经超过两秒
img.save("/captures/Anya_capture_%s.jpg" % str(time.time())) # 使用时间戳作为文件名保存图片
last_capture_time = time.time() # 更新上次拍照时间
print("Shooting a photo of Anya was successful")
else:
led.off()
print("Other")
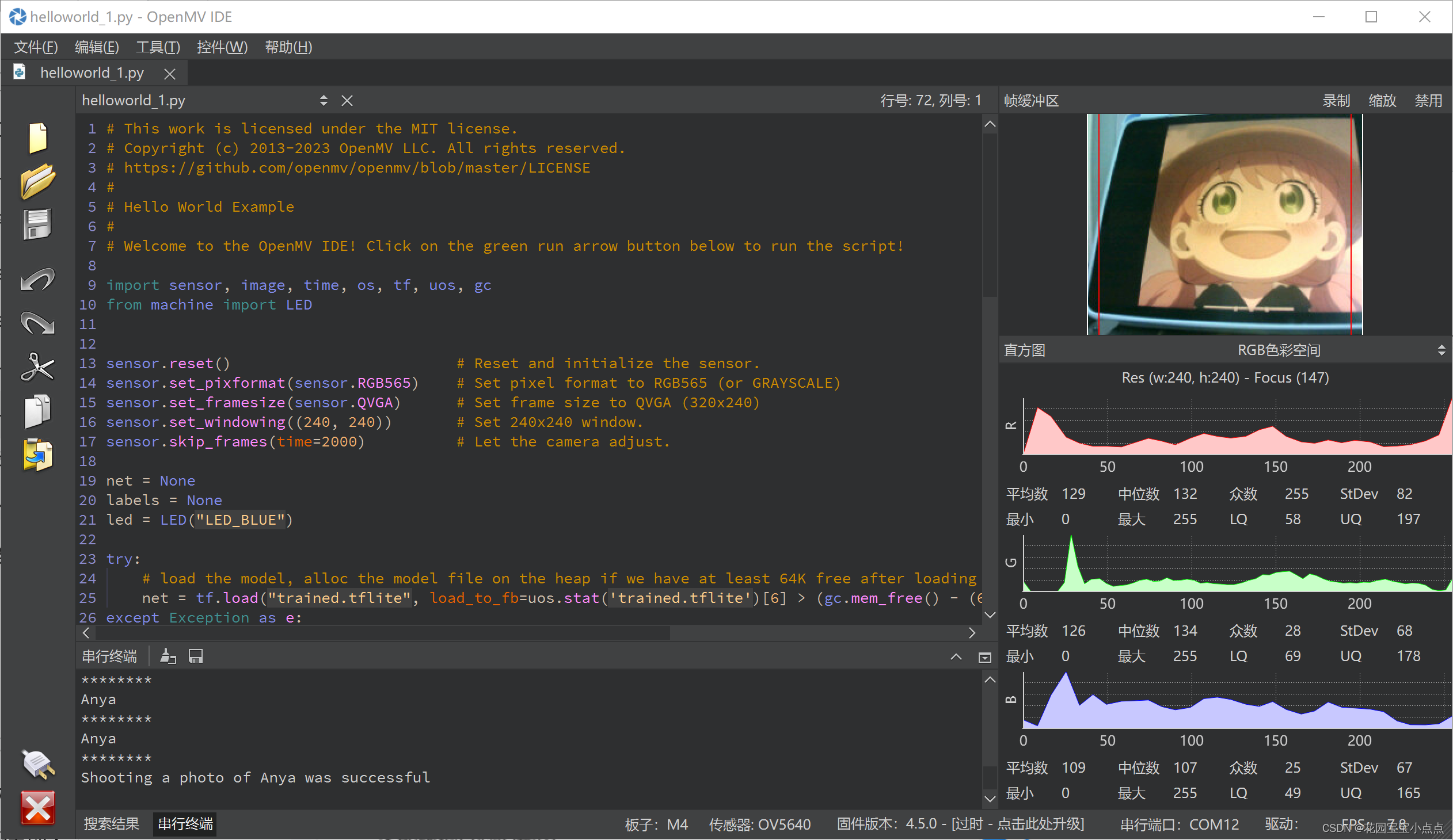
print("********")🚀🚀然后我们运行看一下结果:
🚀🚀我们注意到4个地方,一个是终端打印了Anya,第二个是拍照功能,第三个是红框,第四个是LED灯亮了。
🚀🚀我们打开文件夹看一下拍摄的图片:
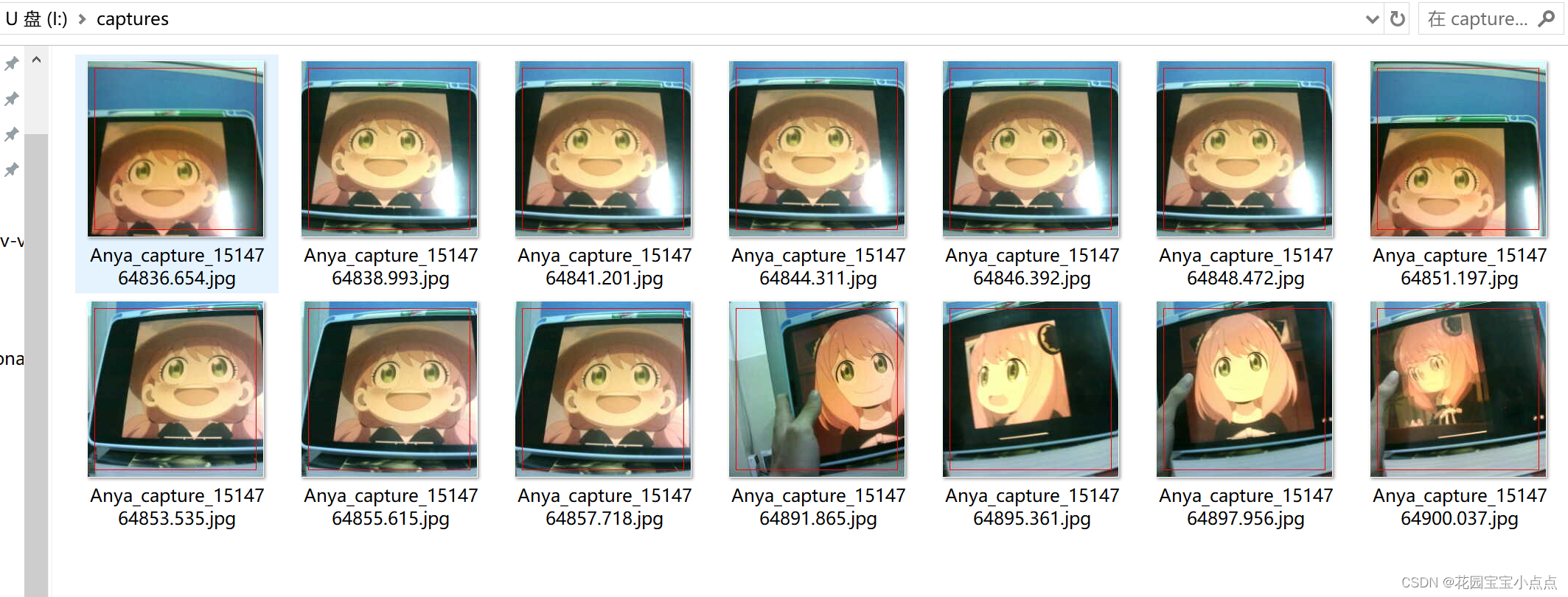
🚀🚀差不多到这里就结束了,模型训练其实还不是很准,大家可以多高一点数据集,不要像我这样懒。
结语
🚀🚀因为是第一次接触,所以很多地方不太懂,请大家见谅,不过这个确实很好玩,哈哈哈!