大语言模型应用指南:以ChatGPT为起点,从入门到精通的AI实践教程
大语言模型应用指南:以ChatGPT为起点,从入门到精通的AI实践教程

2018 年,OpenAI 发布了首个大语言模型——GPT,这标志着大语言模型革命的开始。这场革命在 2022 年 11 月迎来了一个重要的时刻——OpenAI 发布了备受瞩目的ChatGPT。在接下来的不到一年的时间里,大语言模型的生态系统迅速壮大并蓬勃发展。
大语言模型的生态系统可以分为模型层、框架层和应用层,如图所示。
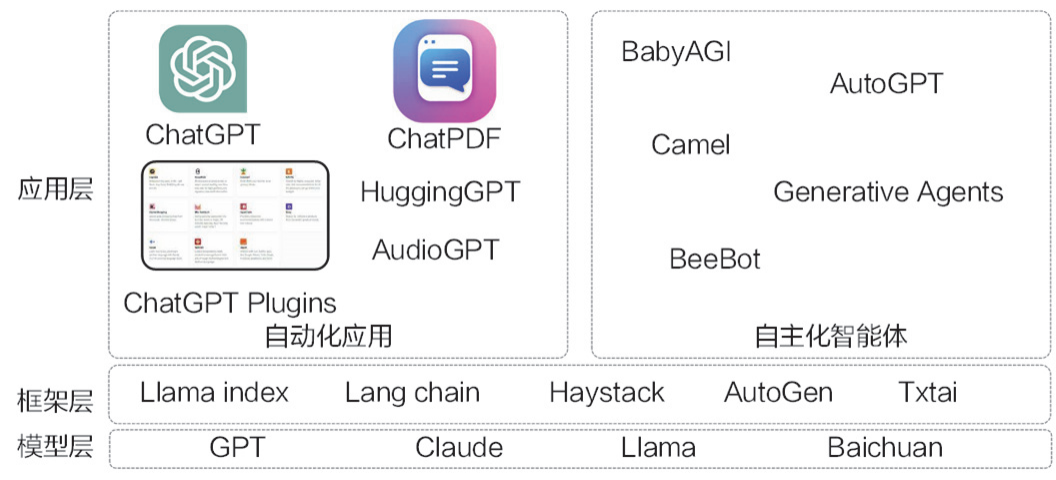
模型层提供了基础的大语言模型能力,包括开源和闭源两类。闭源模型的代表有OpenAI 的 GPT 系列和 Anthropic 的 Claude 系列。毫无疑问,目前 OpenAI 的 GPT 系列模型在整个行业中处于领先地位,其性能远超其他大语言模型。开源模型的代表是 Meta推出的 Llama2。闭源模型就像移动互联网时代的 iOS 操作系统,更易于上手、技术门槛较低。而开源模型类似移动互联网时代的 Android 系统,对使用者的技术要求更高,但具备更强的可定制性。不管是开源模型还是闭源模型,都提供了模型微调的能力。OpenAI 甚至提供了神经网络的文本向量化功能。
框架层提供了基于大语言模型的开发框架,帮助开发者更快地构建与大语言模型相关的应用。目前市场上涌现出许多出色的开发框架,它们提供了各领域针对大语言模型二次开发的抽象。除了开发框架,还有向量数据库、知识图谱等重要的周边模块。
应用层是基于大语言模型开发的最终应用,ChatGPT 可以说是其中最知名和热门的。这些应用大致可以分为两类:一类是自动化应用,代表产品是 ChatGPT,这类应用需要人类的参与和反馈;另一类是自主 Agent 系统,代表产品是 AutoGPT,这类应用不需要人类主动参与,自主 Agent 系统可以在得到初始命令后进行自主迭代。应用层仍在不断发展,特别是自主 Agent 系统,这是一个充满前景和想象的领域。
在介绍完大语言模型的生态之后,让我们来展望一下大语言模型的未来。在这里,我们将进行简单的预测。
在应用层面,我们可以预见应用将沿着无状态、有状态,以及具备自主决策能力的趋势不断演化。自主 Agent 系统将成为重要的应用方向。当前的自主 Agent 系统模块之间主要使用自然语言进行信息传递和状态的存储,然而在未来,这种传递信息和存储状态的方式可能演变为神经网络编码的向量。
在框架层,不同框架对于基于大语言模型应用的基础模块抽象正在逐渐达成共识,例如对长期记忆和 RAG 框架的抽象和对提示模板的抽象。这一趋势将有助于不同框架更好地协同发展,实现互相兼容,从而推动更广泛的应用和创新。
在模型层,大语言模型未来的发展主要包括以下 5 个方向。
- 数据是最重要的竞争优势,它扮演着护城河的角色,可以实现循环增值。闭源大语言模型的制造商会经常探索新的产品形态,以不断积累新的数据。例如,OpenAI 推出了 ChatGPT,这一产品通过用户对回答内容的“赞”和“踩”来评估模型回答的质量,甚至可以根据用户对同一问题的提问次数来粗略估计模型回答的质量(对于高质量的回答,用户通常不会重复提问)。另外,OpenAI后续推出的 Plugin 等功能,也为后期的 function calling 功能积累了高质量的、真实的涉及工具使用的训练数据。
- 上下文窗口的大小将不断扩展,但不一定一味地追求无限扩展,通常,百万量级的 token 就足以支持大部分应用场景。除此之外,工程端会不断优化,降低大语言模型的使用成本。
- 缓解幻觉和偏见问题将成为关键目标,这是大语言模型成为可靠系统的关键。
- 逐渐支持多模态的输入和输出,为更多领域的应用带来创新和可能性。这将催生更多新型的提示工程,类似前文提到的视觉参考提示。
- 不断探索突破自回归模型的局限性,尝试将系统 2 纳入训练框架,同时探索根据问题的难度自适应地分配计算资源,以提高效率和效果。无论是训练范式(目前主要是“下一个 token 预测”)还是神经网络结构,在未来都可能再次迎来全新的变革。
2023年11月,OpenAI的创始成员Andrej Karpathy提出了一个引人入胜的观点:未来,大语言模型极有可能发展到与当前计算机操作系统的地位相当。
他形象地比喻说,我们可以将大语言模型及其周边生态系统看作一种崭新的操作系统。
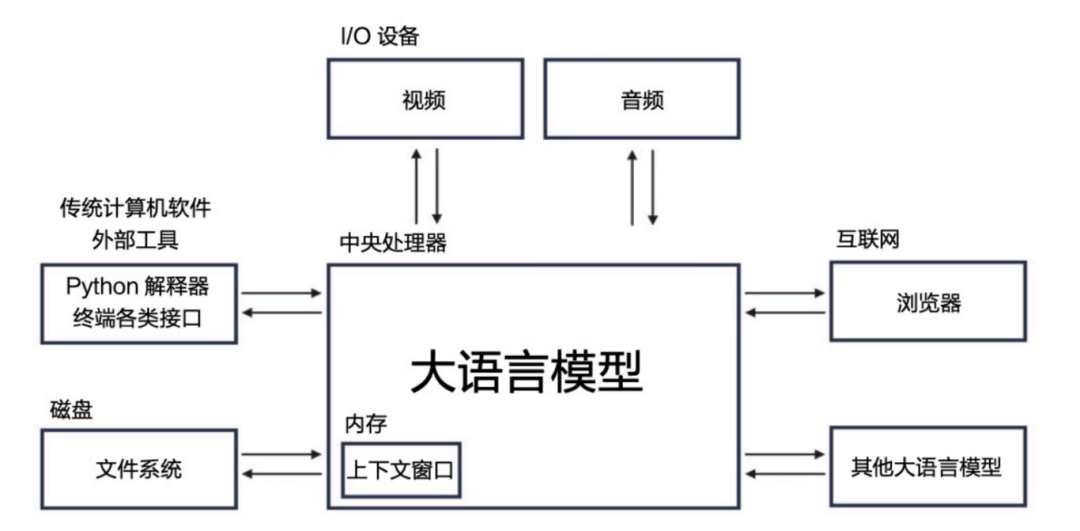
大语言模型就像计算机中的中央处理器,它的批处理大小相当于CPU的核心数,而每秒处理的 token数量则相当于CPU的主频,以Hz为单位。这些参数决定了模型的计算能力和处理速度。而语言模型的上下文窗口大小则相当于计算机的内存大小,它决定了模型能够同时考虑的信息量和短期记忆的大小。
外部数据在语言模型中扮演着长期记忆的角色,类似于计算机的磁盘。这些外部数据的组织方式就像计算机磁盘中的文件系统一样,它们存储和管理着模型需要的信息,供其随时调取。此外,语言模型接收和输出的文本、音频、视频相当于计算机的输入输出设备,它们是模型与外界交互的媒介。
最后,大语言模型不仅可以与其他模型进行网络通信,还能够通过浏览器访问互联网上的信息,以及利用外部工具执行传统的计算机操作。这种广泛的联接和应用使得语言模型在信息处理和应用方面具有了前所未有的能力和灵活性。
LLM as OS, Agents as Apps: Envisioning AIOS, Agents and the AIOS-Agent Ecosystem论文的作者也持有与Andrej Karpathy 相似的观点。
在这篇论文中,作者提出了 AIOS-Agent 生态系统的概念,并将其与现今的操作系统(OS) -应用程序(App)生态系统进行了比较。下面展示了它们之间的类比关系。
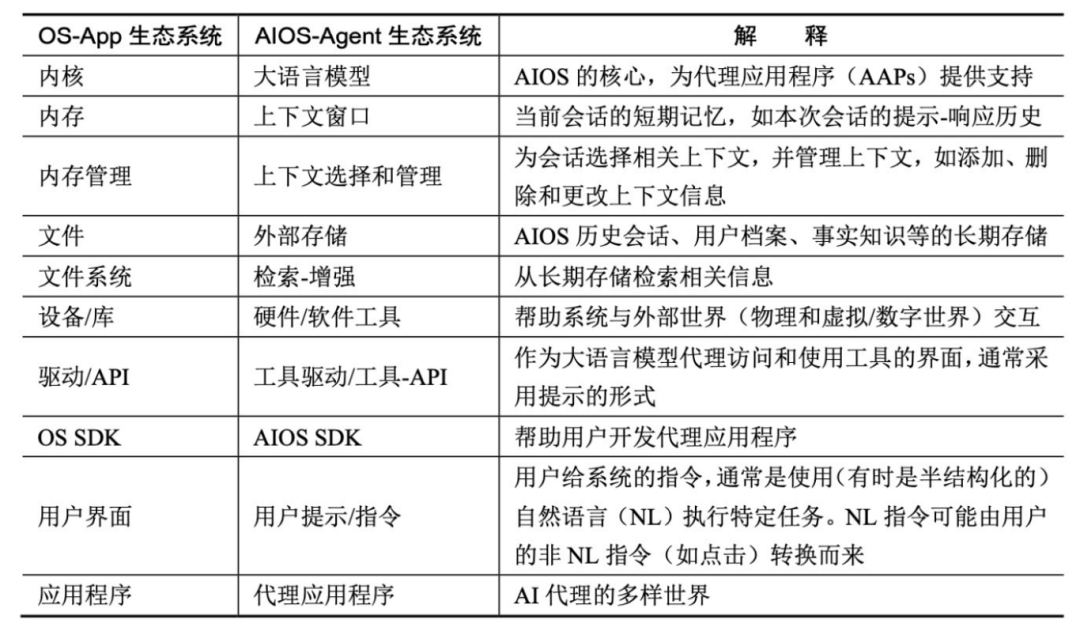
未来,大语言模型很有可能以这种全新形态融入人类的日常生活和工作中。人类将从移动互联网时代迈入智能时代,应用的载体也将由应用程序逐渐转变为基于大语言模型的智能体。


未来,大语言模型极有可能发展到与当前计算机操作系统的地位相当,因此,应用大语言模型可以说是每个人不可或缺的技能。
《大语言模型应用指南:以ChatGPT为起点,从入门到精通的AI实践教程(全彩)》一书将帮助大家更好地理解和使用大语言模型,即使你对人工智能技术或编程技术一窍不通,也不用担心。本书将用通俗易懂的语言和例子,讲述大语言模型的基本原理、基础使用方法和进阶开发技巧。
本书特色
- 一是以通俗易懂的方式解释复杂概念,通过实例和案例讲解大语言模型的工作原理和工作流程、基本使用方法,包括大语言模型常用的三种交互格式、提示工程、工作记忆与长短期记忆,以及外部工具等,使读者能够全面了解和掌握这一先进技术的应用和二次开发;
- 二是紧跟当前大语言模型技术的更新动态,介绍GPTs的创建,以GPT-4V和Gemini为例讲述多模态模型的应用,还包括无梯度优化、自主Agent系统、大语言模型微调、RAG框架微调、大语言模型安全技术等。
无论是学术研究者、工程师,还是对大语言模型感兴趣的普通读者,都可以通过本书获得大语言模型的前沿研究成果、技术进展和应用案例,从而更好地应用大语言模型解决实际问题。