LLMZip:使用大语言模型实现无损文本压缩

题目:LLMZip:Lossless Text Compression using Large Language Models 作者:Chandra Shekhara Kaushik Valmeekam, Krishna Narayanan, Dileep Kalathil, Jean-Francois Chamberland, Srinivas Shakkottai 文章地址:https://arxiv.org/abs/2306.04050 内容整理:张俸玺 本文通过使用大语言模型(LLMs)来预测文本序列中的下一Token,并结合传统的无损压缩技术,探索了文本数据压缩的新方法。文章特别介绍了LLaMA-7B模型在预测和压缩方面的应用,并展示了该方法在实验中相较于现有技术如BSC、ZPAQ和paq8h的优越性。文章结果显示,利用最新的大语言模型进行文本压缩不仅可以提高压缩率,还能更准确地估计语言的熵,为未来文本处理技术的发展提供了新的可能性。主要内容包括: 预测与压缩的关联:说明了如何利用语言模型的预测能力来进行数据压缩,这是基于Shannon早期关于英语的熵估计理论。 压缩算法:描述了如何将语言模型的预测结果与算术编码相结合,以实现更有效的文本压缩。 实验结果:通过在不同的文本数据集上测试,验证了LLaMA-7B模型压缩性能的有效性,特别是在text8数据集上获得了优异的压缩比。
目录
- 引言
- 主要思想
- 使用LLMs压缩文本
- 熵界
- 编码方案
- 实验结果
- 结论
引言
学习、预测和压缩之间存在着密切的联系。ChatGPT的成功吸引了公众的广泛关注,并将学习与预测之间的联系推向了前沿。LLaMA和GPT-4等大型语言模型带来的主要进步是,它们能够根据已知的前几个单词(Token)来出色地预测段落中的下一个单词(Token)。
预测与压缩之间的联系早在1951年由香农探索,以估计英语的熵。基于过去值对时间序列中第i个值进行良好预测,可以有效转化为优秀的压缩算法的思想,在信息理论中扮演了突出的角色。许多语音、图像和视频压缩算法显式或隐式地利用了这一理念。在英文文本的无损压缩背景下,将语言模型与算术编码结合的想法已成为一个非常有效的范例。这种压缩方案的性能在很大程度上取决于预测器的有效性,每当预测能力有重大进展时,我们都有必要研究其对压缩性能的影响。实际上,在2018年,在Mohit Goyal等人提出的DeepZip中,使用循环神经网络(RNN)作为预测器,并报告了对某些类型的源的改进结果。他们的方案仍然没有超过如BSC和ZPAQ等最先进的文本压缩算法。
因此,现在研究使用如LLaMA-7B这样的大语言模型是否可以获得更好的压缩结果和更精确的英语熵估计是很自然的。本文展示了当使用LLaMA-7B大语言模型作为预测器时,使用text8数据集的1MB部分估计得出的熵的渐进上界为0.709比特/字符。这个数值与最先进的文本压缩算法之间仍存在一定差距。但当LLaMA-7B与算术编码器结合用于压缩时,作者在text8数据集的1MB部分得到了0.7101比特/字符的压缩比,这显著优于使用BSC、ZPAQ和paq8h在整个100MB的text8数据集上获得的压缩比。
主要思想
下面使用以下例子来描述本文主要思想,这与Shannon在《A convergent gambling estimate of the entropy of english》一文中提出的用于估算英语熵的方法几乎相同。主要区别在于使用代表可变长度字母组的Token,在于使用大语言模型而非人类来预测下一个Token。考虑句子的一部分,其内容如下:
My first attempt at writing a book
我们的目标是将这句话转换成尽可能短的比特序列,以便可以从比特序列中重构原始序列。这句话首先可以被分割成一个单词(Token)序列。
'My','first','attempt','at','writing','a','book'
一个具有记忆能力M的语言模型(例如,设
)根据观察过去的M个单词来预测句子中的下一个单词。具体来说,它会生成一个按顺序排列的下一个单词的选择列表及其概率。如图1中所示,在第5个epoch,模型接受前4个单词作为输入,并预测句子中的下一个单词可能是像“reading”、“writing”、“driving”、“cooking”等单词。主要思想是计算句子中实际单词(“writing”)在此列表中的排序,并称之为
。假设排名从0开始,即最可能的单词排名为0,第二可能的单词排名为1,依此类推。在这个例子中,“writing”的排名为
。
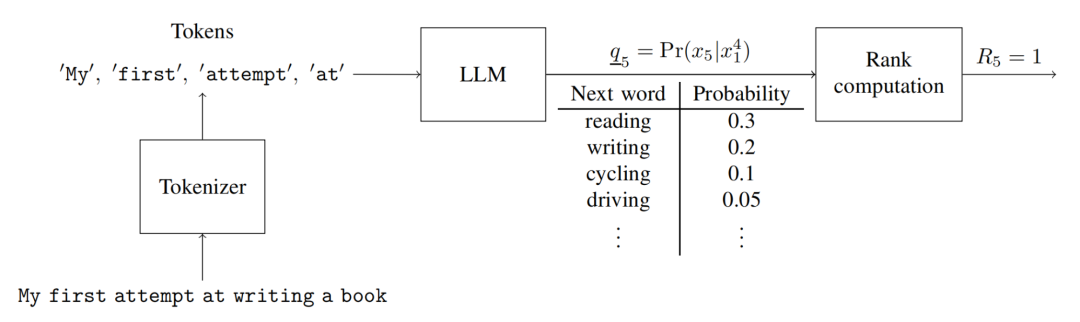
图1 Schematic showing the prediction at epoch 5 for a language model with memory 4
然后,我们在句子中向前移动一个单词,在第6个epoch,我们尝试基于第2到第5个单词来预测第6个单词,如图2所示。在这个例子中,给定第2到第5个单词,最可能的第6个单词确实是我们希望编码的句子中的同一个单词“a”,因此,该单词的排名
将是0。
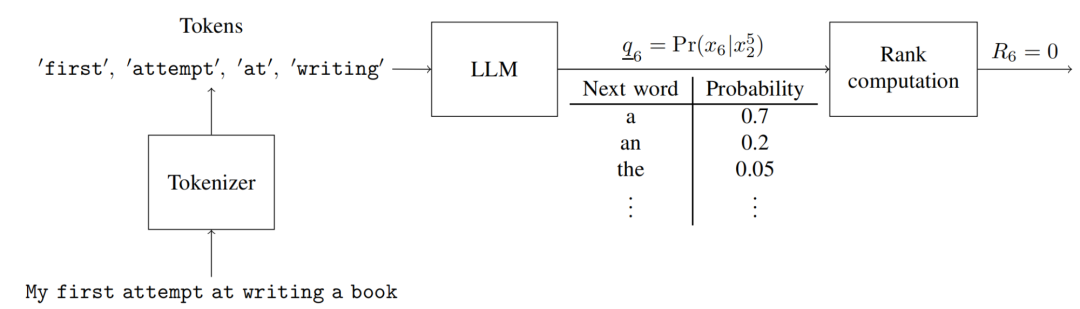
图2 Schematic showing the prediction at epoch 6 for a language model with memory 4
如果语言模型效果好,我们期望编码的单词通常会出现在列表的顶部,因此排序将是0。所以如果我们查看排名序列,很可能会有许多0,且随着排名1、2等的增加概率将逐渐减小。在这个例子中,可以预见排序将会是这样的:
1,0,0,...
由于含有许多“0”的排名序列通常具有结构化模式,所以它是可压缩的。因此,关键思想是使用标准的无损压缩算法,如zip、算术编码(AC)或霍夫曼编码,将排序转换为比特进行压缩,如图3所示。这些压缩算法通过利用数据中的重复或可预测模式来有效减少所需的比特数,从而在保持数据完整性的同时最大化压缩效率。
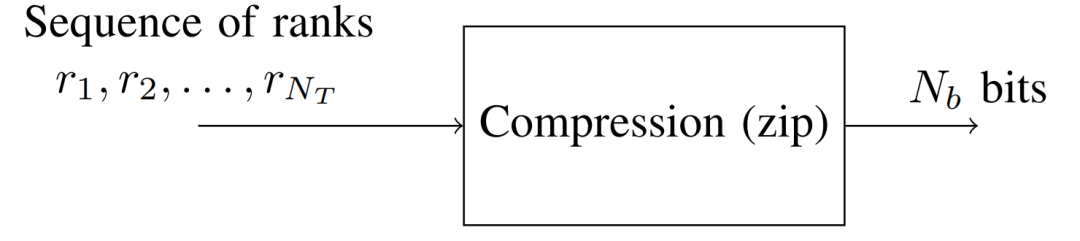
图3 Schematic showing the compression of the sequence of ranks to a bit sequence
当我们想要重构序列时,我们首先需要解压和解开比特以获得排名序列,然后使用相同的语言模型,逐epoch地生成下一个单词的排名有序列表,并在第i个epoch选择列表中排名为
的单词。然后使用该单词作为输入来确定下一个单词,依此类推。注意,这要求在编码器和解码器端使用相同的大语言模型(LLM)。
讨论编码排名的想法是为了建立直觉,通过直接使用LLM产生的概率结合算术编码可以实现更好的压缩效果。这种方法利用了算术编码在处理概率数据时的高效性,能够根据实际概率密度更紧凑地编码信息,从而达到更高的压缩率。
使用LLMs压缩文本
让
表示由
字母组成的英语中的一个句子,并假设每个字母来自字母表
。假设我们有一个
Tokens的字典
。我们首先将
解析为一个由
表示的
tokens序列。
和
之间有一对一的映射,因此,压缩
与压缩
相同。可以被认为是由大写字母
表示的随机变量的实现。
具有记忆能力M的语言模型是一个预测器,其操作方式如下:在第i个epoch,它接收tokens
并为基于过去的M个Tokens的序列中的下一个Token产生概率质量函数(pmf)
。PMF向量
是按降序排序的,并将排序后的PMF向量记为
,是整数1到
的排列,表示为:
主要的衡量指标是压缩率
,定义为:
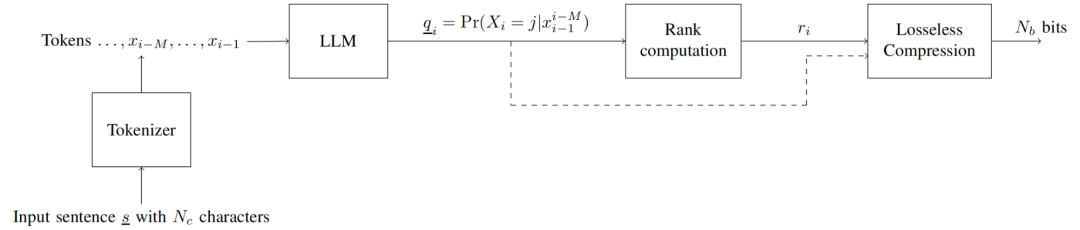
图4 Schematic showing the prediction at epoch i
熵界
文中将式(3)右侧的表达式称为
的渐近上界,并用
表示。式(3)中的分子是指表示Tokens
所需的平均位数,式(3)中的分母是每个Token的平均字符数。因此,
的单位是位/字符。最近,几种语言模型的性能在text8数据集上,使用称为比特每字符(bpc)的度量进行了评估。作者认为bpc与本文的渐近上界相同。
编码方案
作者考虑了三种无损压缩块的设计方案,如图3所示。
1.使用zlib压缩秩:第一种方案使用zlib压缩算法对秩序列进行编码。作者称该方案为LLaMA+zlib,并以
表示该方案的压缩比。
2.逐令牌压缩:第二种方案使用逐令牌无损压缩方案,该方案使用时变码本在第i个epoch使用prefix-free code对Token
进行编码,假设
是token对应的真实概率分布。prefix-free code的自然选择是霍夫曼编码。为了简单起见,作者使用无前缀的代码,其中Token
的码字长度为
。由于这种长度的选择满足Kraft不等式,因此能够保证存在这种长度的记为
的无前缀码。该方案的压缩比
由下式给出:
3.算术编码:上述两种方案都很直观,但性能还有待提高。将LLM的输出与无损压缩方案结合起来的一种非常有效的方法是使用算术编码。算术编码很适合接受时变概率,在算术编码方案中,作者使用
作为Token
在时间上的概率。这里称该方案的压缩比为
。众所周知,算术编码作为一种压缩方案几乎是最优的。因此,该方案的压缩比预计为:
实验结果
在本文中,使用LLaMA-7B作为大语言模型,并使用SentencePiece tokenizer。这个分词器生成一个包含32,000个词汇的字典。由于语言模型是基于这个分词器训练的,所以使用这个分词器与LLM结合至关重要。应当注意,分词器和模型是基于包括大写字母、特殊字符等在内的大量文本语料库训练的。这与许多关于估算英语熵的研究形成对比,这些研究中的输入字母表仅限于小写字母。这使得在这些模型之间进行完全公平的比较变得困难。通过使用预训练的LLM处理仅包含小写字母的输入,由此所产生的结果可能对LLM不公平。
尽管如此,作者还是使用了从http://mattmahoney.net/dc/text8.zip获取的text8数据集来基准测试LLaMA-7B在文本压缩方面与其他最新成果的性能。Mohit Goyal等人在Deepzip中提到,ZPAQ算法在text8数据集上获得了最佳的压缩比,为1.4比特/字符。在"text8 results"(http://mattmahoney.net/dc/textdata.html)中,展示了paq8h算法提供了1.2比特/字符的压缩比。据作者所知,这似乎是报道中的最佳性能。因此作者使用这两种算法作为基准。作者没有独立运行ZPAQ或paq8h算法,而是直接引用了现有文献中的结果。
LLaMA-7B的性能在表1中显示了10个不同批次的结果,每个批次包含100,000个标记(token)。这1M个标记的平均性能也在表格的最后一行显示。可以看到,使用LLaMA-7B结合算术编码压缩的结果显示压缩比为0.7101比特/字符。这显著优于先前提到的最新成果,并且非常接近作者所计算的上界。使用LLaMA+zlib算法和LLaMA+TbyT压缩的性能也优于已知的最新成果。
表1还显示了Hugo Touvron等人在Llama中所提到的上界。值得注意的是,这里的熵上界低于Shannon在《Prediction and entropy of printed english》中计算的、Cover和King在《A convergent gambling estimate of the entropy of english》中的以及基于神经网络在《Focus your attention (with adaptive IIR filters)》中的更近期估计。
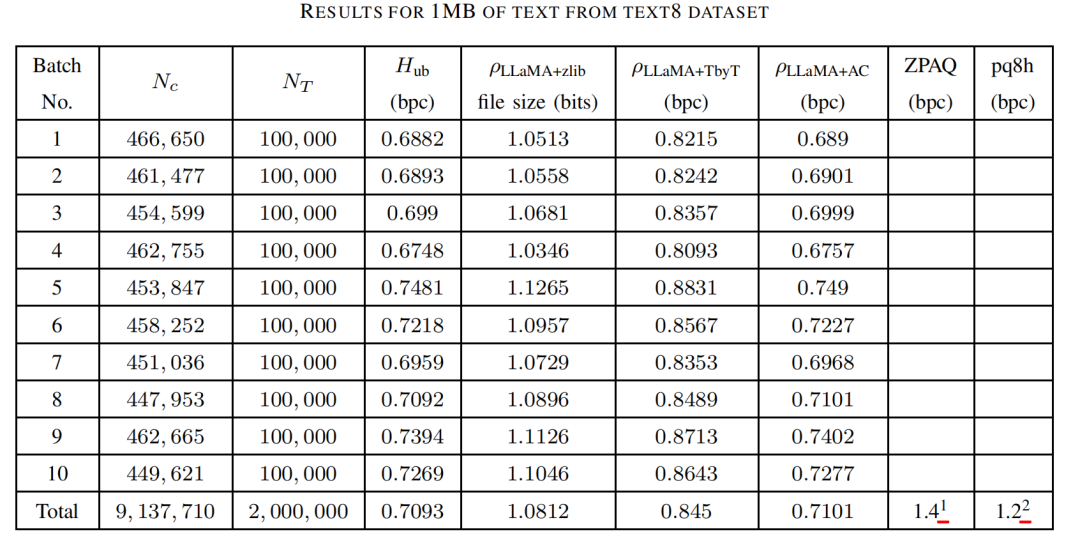
表1 在Text8数据集1MB数据上的运行结果
表2显示了LLM的记忆容量(M)对压缩性能的影响。如预期的那样,随着M的增加,压缩性能有所提高。作者还观察到,推理时间与输入记忆长度大致成线性关系,即拥有511个标记的记忆的批次比拥有31个标记的记忆的批次在推理速度上慢大约16倍。这种现象说明,虽然增加模型的记忆长度可以提高压缩效果,但同时也会显著增加处理时间,这可能在实际应用中需要进行权衡。
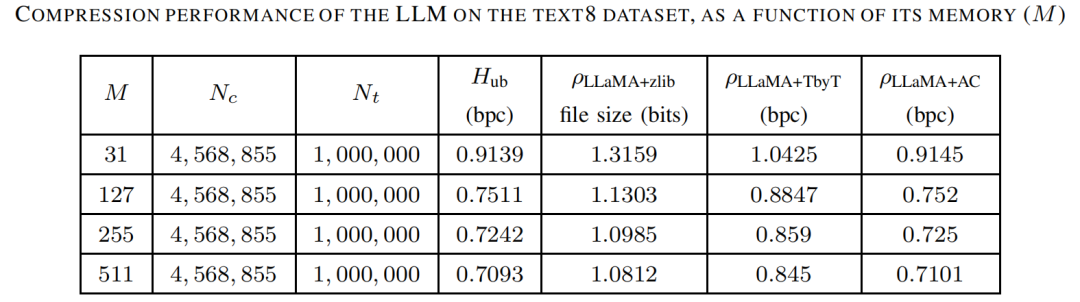
表2 LLM在text8数据集上随记忆容量变化的压缩表现
众所周知,压缩比的估计可能因输入文本的不同而显示出较大的差异,因此应谨慎解读这些结果。使用10个批次的100,000个标记计算得出的熵上界和压缩比的均值和标准偏差显示如表3所示。作者也未能在整个100MB的text8数据集上运行LLaMA-7B。因此,LLaMA-7B与最新成果的比较是基于不同输入大小获得的估计值。
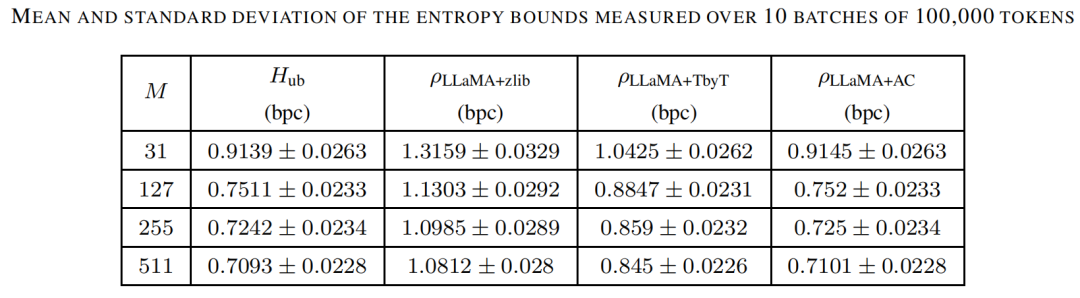
表3 测量自10个批次100,000个标记的熵界均值与方差
这种大小的差异可能影响模型的性能评估,因为不同的数据量可能导致模型表现的不同。尤其是在处理大型数据集时,模型可能无法展现出在较小批次数据上的性能。此外,因为使用了不同的批次和数据大小,这可能引入了额外的变异性和潜在的偏差,这需要在解释结果时加以考虑。
确实,如果LLaMA-7B模型是在包括维基百科文章的语料库上训练的,而text8数据集派生自维基百科,那么针对text8数据集的结果可能会偏乐观。这种情况通常被称为数据泄露,即训练数据包含了测试集的一部分,从而可能导致模型在测试集上表现异常好。因此,在评估LLaMA-7B模型的压缩性能时,需要考虑到这一点,并可能需要在更多样化或与训练集不重叠的数据集上进一步验证性能,以获得更全面和准确的评估。这样的步骤有助于确保评估结果能更真实地反映模型在实际应用中的表现。
因此,作者还在2023年5月25日发表的Project Gutenberg旗下的一本书上测试了LLaMA-7B的性能。作者提取了与100,000个标记相对应的文本,应用了与text8数据集相同的文本预处理方法,以清洗书籍中的文本数据。结果得到的文本数据仅包含小写字母和空格,与text8数据集一样。表4显示了LLM在该书籍上的压缩性能。可以看到,与text8数据集上的性能相比,压缩比和熵上界略有上升;尽管如此,熵的渐进上界仍低于当前已知模型在中给出的上界。同样,基于LLaMA-7B的压缩器的压缩比优于已知的text8数据集的最新成果。LLaMA结合算术编码的压缩比仅为0.8426比特/字符,非常接近估计的H(S)上界。
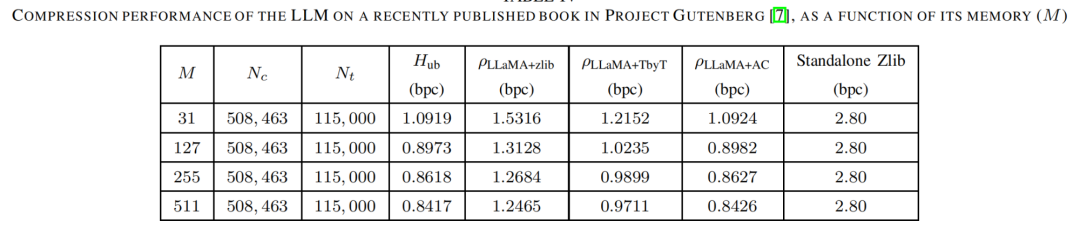
表4 LLM对近期出版书籍文本的压缩表现
这表明即使在与训练数据不直接相关的新材料上,LLaMA-7B仍然能够展现出优秀的压缩性能。这增强了对模型广泛适用性的信心,表明它不仅在特定类型的数据上表现良好,而且在更广泛的文本类型上也能维持高效的性能。这样的结果为将LLaMA-7B用于其他语言和文本类型,以及其他模态(如图片、视频)的实际应用提供了有力的支持和潜在的优势。
为了对比以LLaMA为基础的压缩器与标准文本压缩器的性能,作者还直接在输入文本上运行了zlib算法。结果显示的压缩比为2.8比特/字符(显示在最后一列)。显然,基于LLaMA的压缩器的性能远优于此。zlib算法可能未针对压缩小文本样本进行优化,因此,在较长文本上,zlib算法和LLaMA+zlib的压缩比可能会有所提高。这一结果强调了使用高级语言模型如LLaMA-7B进行文本压缩的潜力。基于这些模型的压缩器能够更有效地利用文本的语言结构特性,从而实现更低的比特率。这在短文本上的性能提升尤其明显,这可能是因为LLaMA-7B能够更精准地捕捉较小样本的统计依赖性。这些发现表明,对于需要高效压缩的应用场景,如移动设备和网络通信,采用基于大语言模型的压缩方法可能是一个值得探索的方向。同时,这也提示在实际应用中应考虑不同压缩算法对不同文本长度的适应性。
结论
本文的结论指出,利用大语言模型(如LLaMA-7B)进行文本压缩能够显著提高压缩效率,并且可以达到比传统文本压缩算法(如BSC、ZPAQ和paq8h)更优的压缩比。文章通过实验数据证明了这种基于语言模型的预测能力和算术编码结合的压缩方法,在处理大规模文本数据时,不仅压缩效果好,而且能够提供较低的熵估计,从而推动了信息理论和数据压缩技术的进步。这表明随着语言模型预测能力的提高,未来在数据压缩领域有望实现更高效和精确的压缩策略。