打破视频标注成本壁垒,图像字幕引领文本到视频检索训练新趋势,超越零样本CLIP Baseline !
打破视频标注成本壁垒,图像字幕引领文本到视频检索训练新趋势,超越零样本CLIP Baseline !


作者描述了一个研究文本到视频检索训练的协议,该协议使用 未标注 的视频,作者假设(i)没有任何视频的标签,即无法访问 GT 字幕的集合,但(ii)可以访问以文本形式标记的图像。 使用图像专家模型是一个现实情况,因为相对于昂贵的视频标注方案,标注图像更便宜且具有可扩展性。 最近,像CLIP这样的零样本图像专家为视频理解任务建立了一个新的强大 Baseline 。 在本文中,作者利用这一进展,并从两种类型的模型实例化图像专家:一个文本到图像检索模型提供了一个初始主干,以及图像字幕模型为 未标注 视频提供监督信号。作者展示,使用图像字幕自动标注视频帧可以实现文本到视频检索训练。 这个过程无需手动标注成本就使特征适应目标领域,因此优于强大的零样本CLIP Baseline 。 在训练过程中,作者从多个视频帧中采样与视觉内容最匹配的字幕,并根据每个字幕的相关性对帧表示进行时间池化。 作者进行了广泛的消融研究以提供见解,并通过在三个标准数据集ActivityNet、MSR-VTT和MSVD上的文本到视频检索任务中超越CLIP零样本 Baseline ,证明了这个简单框架的有效性。
1 Introduction
近年来,自动视频理解的研究经历了多次范式转变。随着神经网络的兴起,最初的问题是如何设计一种架构来输入时空信号[49, 68]。鉴于有限的视频训练数据,焦点随后转向了从图像分类预训练借用参数初始化[7]。为了提供视频预训练,一项工作已经在标注视频分类数据集上做出了昂贵的努力[27]。
另一方面,研究界正从封闭词汇识别训练转向,因为语言建模的进步启发了在给定开放词汇文本输入的情况下检索视觉数据的进展,弥合了完全监督的视频检索方法的局限,因为这些方法由于视频标注的高成本而受限。即使是使用网络规模的视频-文本对进行训练[4]也没有超过CLIP图像-文本预训练[8],尽管人类为了在股票网站上销售他们的视频而手动输入了丰富的描述。另一方面,从无标签视频中学习的方法通常假设没有任何标签,即使是图像,特别关注自监督训练,以数据本身的结构作为训练信号。
在本文中,作者提出了一个问题:外部现成的图像专家是否可以提供监督信号?作者探讨了最近发布的健壮图像字幕生成器的可用性,分别是ClipCap[46]和BLIP[32],它们从大规模图像-文本对训练中受益。例如,ClipCap使用了CLIP视觉预训练和GPT-2语言模型预训练[56]。当应用于视频帧时,作者观察到,尽管输出文本含有噪声,但它们包含高质量的描述,这促使作者进行此次探索。
尽管使用自动图像字幕的想法很吸引人,但将这种噪声标签纳入训练引入了额外的挑战。为了解决这个问题,作者首先采用了一种过滤方法,通过计算CLIPScore指标[25]选择更好地描述帧的字幕。这种跨模态相似度的度量与[32]中的过滤步骤类似。此外,作者集合了多个图像字幕生成器以获得更大的标签池。作者在消融实验中验证了这些步骤的好处。
在这项工作中,作者测试现成的图像字幕模型是否可以作为视频检索任务的自动标注策略。作者提出了一个简单的框架来回答这个问题。作者主要的 Baseline 以及权重初始化都是CLIP[55]。作者对这个模型进行微调,以便在对比检索训练之后,视频帧嵌入和自动字幕映射到跨模态联合空间。由于一个字幕可能不足以代表视频,作者引入了多字幕训练,通过扩展[5]的 Query 评分方法有效地使用每个视频的多个文本标签。这是为了克服自动标签中的潜在噪声,同时也是一种数据增强方法。此外,由于作者的方法不需要手动标注,作者可以在训练过程中超越单一数据集,结合多个数据源。这在较小数据集上特别提高了性能。作者通过实验证明,用图像字幕生成模型为无标签视频帧生成伪标签是一种简单而有效的策略,它比 Baseline 提高了性能。
作者的贡献有三方面:
- 作者提出了一种新的简单方法来训练视频检索模型,该方法使用自动帧标题,这些标题构成免费的标签进行监督(见图1)。据作者所知,在开展这项研究之前,现成的标题生成尚未用于此类目标。
- 在三个文本到视频检索基准上,作者超越了零样本的最新CLIP模型。
- 作者提供了广泛的消融研究,关于如何选择高质量标题的设计选择,包括多个图像标题生成器,使用多标题 Query 评分的时间池化,以及结合多个数据集。代码和模型将公开可用。
2 相关工作
作者简要概述了文本到视频检索、 未标注 视频上的自监督学习、伪标签和标题生成相关的研究。
文本到视频检索。 文本到视频检索的方法最近才开始训练端到端的神经网络模型,这得益于(i)来自ViT[16]的强大初始化和(ii)大规模视频数据集:带有来自语音的ASR基文本监督的噪声HowTol00M数据[45],或者更近期的手动标注的更干净的WebVid数据[4]。文本到图像检索的进展随后推动了文本到视频检索的进步。最近的方法采用了CLIP图像 Backbone ,并探索添加时间建模的可能性(例如,CLIP2TV[20],CLIP4Clip,CLIP2Video[17],CLIP-ViP[79],TS2-Net,ViFi-CLIP[57])。他们的结果表明,简单地对帧嵌入进行平均仍然是一个难以超越的强大 Baseline 。一些研究已经探索了视频的细粒度对比学习[84][41; 83],例如,同时考虑帧-词和帧-句子比较[41]。Bain等人[5]提出了一种简单而有效的方法,通过基于 Query 评分的加权平均来池化视频帧表示。在这项工作中,作者将此方法扩展到使用多个标题而不是每个视频的单个标签。作者还使用CLIP[55]作为作者的 Baseline 以及初始化。与其他检索方法[4; 40; 43]一样,作者采用对比目标[51]。与这些假设手动标注视频数据[4; 5; 40]或噪声语音信号[43; 77]的方法不同,作者从自动标题标注获取作者的监督。在作者的实验中,作者展示了在HowTo100M[45]或WebVid[4]的视频文本对上训练的先前模型相比的零样本性能优势。
无监督学习在 未标注 视频上的应用。 一个相关的研究方向是对 未标注 视频进行表示学习,这通常被称为自监督学习。在这一类别中,有几项工作以类似于图像设置中的SimCLR [10] 或BYOL [23] 的方式,对视频进行实例区分。大多数方法也利用了视频的多模态特性,例如,在训练中结合音频信号 。一个流行的方法是使用未筛选的教学视频(如HowTo100M [45])中的噪声语音信号。通过ASR获得的文本直接被视为相应的标签,然后用于对比目标 。
设计了多实例训练,VideoCLIP 进行了增强检索的预训练,Support-set [53] 定义了多任务字幕目标。这些自监督工作可能与作者的方法互补,但作者在本研究中的重点不同,因为作者寻求来自提供伪标签的外部图像模型的监督,这可以被视为自监督的一条替代路径。
伪标签。 作者的工作也与伪标签(或自我标签)方法相关。与这些工作中考虑的半监督 [30; 64; 65] 或小样本 [76] 设置不同,作者的伪标签不需要对当前问题进行任何标注。特别是,[76] 的同时进行的工作利用图像专家辅助视频-语言学习,但需要一组小规模的标记视频。以类似的方式,VideoCC [48] 利用图像-文本数据集为音频视觉检索的视频自动分配字幕,但受到有限图像字幕数据集来源的限制。作者的工作与 [48] 的区别在于,作者为多个视频帧生成字幕,而不是从这样一个有限集中检索。尽管这两种方法可能具有潜在的互补性,但在作者的附录中,作者展示了最近邻检索字幕的性能不如生成字幕。
在文本-图像预训练中,BLIP [32] 和 BLIP-2 [31] 采用了一种引导式的图像字幕方法,这属于半监督类别,即它们从一组标记的图像开始训练(而作者从未在标记的视频上训练)。实际上,作者采用BLIP作为作者的图像字幕器之一,以获得自动视频标签。在作者的实验中,作者还研究了使用BLIP初始化与CLIP相比的影响。
标题生成。人们对于生成文本描述给定视觉内容的任务越来越感兴趣[3; 11; 13; 15; 52; 61; 71; 80]。尽管许多研究专注于将目标信息作为额外指导进行整合(例如,Oscar [34],VLP [89]),但这些方法在类似于目标检测模型域(例如,COCO数据集[35])上的表现良好。ClipCap [46]在没有使用显式的目标检测模块的情况下,在跨不同域的数据集上显示出强大的性能。相反,[46]利用了两种强大的预训练模型(CLIP [55] 和 GPT-2 [56])并学习图像特征与语言生成之间的映射模型。最近,BLIP [32],BLIP-2 [31]和CoCa [85]通过联合学习图像标题扩展了对比CLIP训练。Align and tell [75]还在训练过程中将视频标题生成头整合到他们的文本-视频检索模型中。OFA [74]进一步在统一框架下支持了各种图像-语言任务,其中通过提示视觉问答模型“图像描述了什么?”来进行标题生成。最近,CapDec [50]在冻结的CLIP图像编码器之上附加了一个文本解码器,通过利用仅包含文本的数据来训练具有CLIP文本编码器的自动编码器。
在作者的工作中,作者采用ClipCap [46]和BLIP [32]作为作者的图像标题生成专家,从中作者为 未标注 视频获取监督信号。尽管它们都仅是基于图像的模型,作者发现它们在视频帧上的表现令人满意。由于训练数据的限制[52; 71],视频标题生成模型的性能目前落后于图像标题生成方法。未来的工作可以探索它们的性能改进。最近的工作如ClipVideoCap [81],Lavander [33],CLIP4Caption [67],HiREST [87],和TextKG [24]取得了有希望的结果。然而,作者在这项工作中的设置不考虑访问标记视频。
3 Training with automatic captions
在本节中,作者首先描述了如何为视频标注自动生成字幕,然后介绍作者的多字幕视频检索训练,最后给出作者实验设置的实现细节。
作者方法的概述如图2所示。总的来说,作者首先通过将图像字幕模型应用于视频帧来为每个视频构建一组标签。鉴于这些噪声帧级字幕(来自多个图像字幕生成器),作者根据它们的CLIPScore [25]对它们进行排序,以选择高质量的字幕。作者采用了一种多字幕 Query 评分的对比视频文本检索训练方法,其中作者将所有选定的字幕纳入目标中。接下来,作者将详细说明这些步骤。
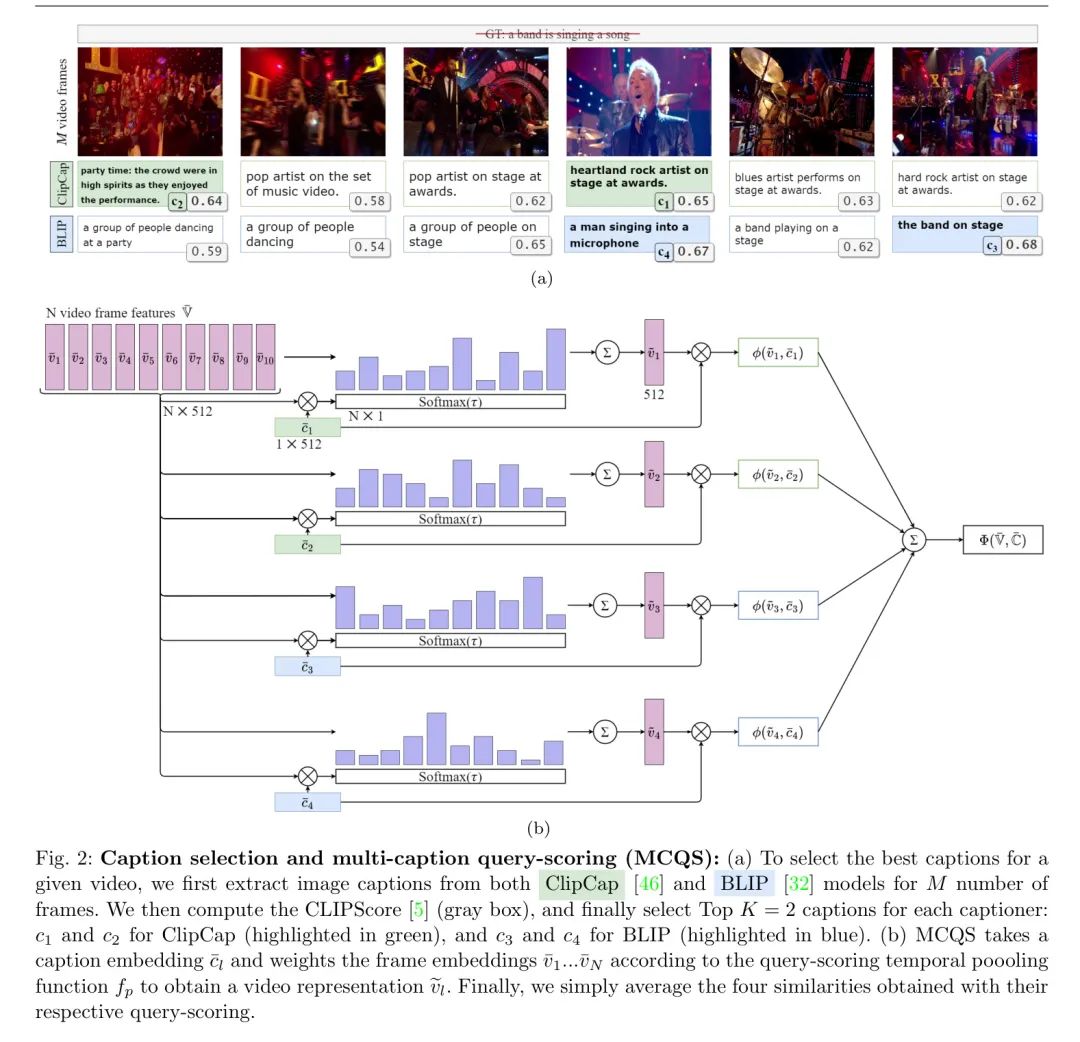
选择高质量字幕。给定一个由帧组成的 未标注 训练视频,作者从视频中选取帧(),并使用个图像字幕生成器提取字幕,形成一个初始标签集,其中。然后作者为每帧获得个文本描述,每个视频总共得到个标签。尽管作者在实验中调查了从字幕中形成标签的几种变体,但作者的最终策略如下。作者选择初始标签的一个子集,主要是为了消除那些不能很好代表相应视频帧的噪声字幕。为此,作者采用CLIPScore [25]作为衡量字幕与其对应帧之间跨模态相似性的方法。对于每个字幕生成器,作者保留CLIPScores最高的前-个字幕(K<ml=k\times i个标签。作者将这个子集称为\mathbb{c}^{\prime}。请注意,由于视频内的视觉相似性,一些字幕在帧之间可能是重复的;因此作者推测,这种子集选择不会导致信息的大量丢失。,作者使用视觉编码器在个视频帧上计算视觉嵌入()。同样,作者从相应的标签集使用文本编码器计算文本嵌入,以获得正面的文本表示,其中(与具有相同的嵌入维度)。为了获得单个视频嵌入,作者对视频帧表示进行时间池化。受到[5]中引入的 Query 评分的启发,作者的池化依赖于文本表示,通过加权平均简单实现,其中帧权重与文本的相似度成比例。然后,将池化的视频嵌入与文本进行比较,以获得单个相似度。[5]与作者不同,作者有多个文本。因此,作者多次应用 Query 评分,并获得多个相似度,作者通过简单的平均操作将它们组合起来(使用加权平均的实验没有带来改进;见第4.2节)。更正式地说,
函数
表示视频帧嵌入集合
与字幕嵌入集合
之间的相似性,其中
是余弦相似度,
是 Query 评分[5]的时间池化函数,也输入文本:
在作者的实验中,作者设置softmax温度超参数
。
从一批
个视觉-文本对样本中,
,作者使用InfoNCE [51] 的对称对比损失进行训练,即,将批次中的所有其他样本视为负样本:
最终的损失是视频到字幕(
)和字幕到视频(
)检索损失项的和。接下来,作者详细说明优化过程。
实现细节。作者从ClipCap [46] 和BLIP [32]模型中实例化了两个图像字幕生成器(
)。ClipCap模型在谷歌概念性字幕图像文本数据集[63]的3M图像上进行预训练,使用CLIP [55]图像 Backbone 网与GPT-2 [56]文本生成模型之间的MLP映射。BLIP通过使用引导程序共同训练检索和字幕生成,使用129M图像(包括LAION [60]的子集)。作者使用公开可用的模型,该模型在COCO数据集[35]上进一步微调。给定一个字幕生成器,作者从等间隔的帧中提取每个视频的
个字幕。作者凭经验设置每个字幕生成器的高质量字幕数量为前
(即
)。在单个GTX1080 GPU上,ClipCap和BLIP的字幕生成成本分别为0.65 fps和0.93 fps。
作者使用Adam [28]优化器和余弦衰减[38]的学习率计划来最小化方程式5中的损失函数,如[40]中所述。对于ActivityNet,作者在16个Tesla V100 GPU上训练10个周期,初始学习率为
,小批量大小为
。对于MSR-VTT和MSVD,作者在4个NVIDIA GeForce GTX 1080上训练10个周期,初始学习率为
,小批量大小为
。
除非另有明确说明,否则作者双重编码器模型的权重在所有实验中均从CLIP [55]预训练初始化,无论是图像编码器(
)还是文本编码器(
)。图像编码器架构在所有实验中遵循ViT-B/16 [16]。文本编码器架构遵循GPT-2 [56]。这两个编码器都是基于Transformer的[69],操作嵌入维数为
。
作者将帧大小调整为224×224分辨率后输入到模型中。在训练期间,作者基于段落进行
随机帧采样(如[72; 4]中所示,注意这些并不一定与
个标题匹配)。这样得到的时空原始视频输入尺寸为224×224×10。每个视频帧都独立通过图像编码器,使用对应于[cls]标记的输出来获得512维的嵌入。如上所述,通过 Query 打分获得时间上的聚合,即对帧进行加权平均,权重是通过帧文本相似性获得的。因此,得到视频 Level 的表示维度为512。在训练期间,作者使用方程式1中的多标题 Query 打分方法。在测试时,作者在10个等距帧的中心空间裁剪上计算视觉嵌入。在评估期间,由于作者只有一个 Query 文本,多标题 Query 打分是不可能的。因此,作者使用常规的 Query 打分方法进行评估。
4 Experiments
作者首先在4.1节中描述了用于报告实验结果的 数据集和评估指标。然后在4.2节中呈现作者的消融研究,量化了以下因素的影响:(i)字幕模型,(ii)字幕选择,(iii)结合字幕生成器,(iv)每个视频使用多个字幕进行训练,以及(v)结合数据集。接下来,作者在4.3节中呈现了与最先进技术的比较,然后在4.4节中介绍使用BLIP初始化而不是CLIP的实验。最后,作者在4.5节中提供了定性分析,并在4.6节中讨论了局限性。
Datasets and evaluation metrics
作者在三个已建立的文本到视频检索基准上进行实验,分别是ActivityNet [29],MSR-VTT [78]和MSVD [9]数据集。
ActivityNet Captions [29] 包含了20k个YouTube视频。视频被分割成42k个片段,平均长度为45秒。作者使用了训练集中的10,009个视频,并在"val1"划分(4917个视频)上进行评估。注意,作者为每个片段提取等间隔的标题,而不是每个视频。
MSR-VTT [78] 由10k个YouTube视频组成。视频长度从10秒到32秒不等,平均为15秒。作者按照[4; 36; 40; 83]中的方法使用Training-9k划分进行训练,并像[40; 86]中那样在1k划分上报告单一视频文本对的结果。
MSVD [9] 包括1970个视频,分为1200个训练视频,100个验证视频和670个测试视频。该数据集包含短视频(约1秒)和长视频(约60秒)。鉴于数据集的大小较小,作者使用三个不同的种子进行训练,并在测试划分上平均结果。
正如之前所解释的,尽管这些数据集包含 GT 标题,作者在训练过程中并不使用它们(在完全监督设置下的实验见第A节)。作者报告了标准的评估协议:对所有实验的文本到视频(T2V)在排名1和5的召回率。排名
的召回率(R@
)量化了正确视频位于前
个结果中的次数。召回率越高,性能越好。
Ablation study
本研究探索性地测试了是否可以为 未标注 视频提供训练信号的标题。答案是肯定的;然而,作者在设计上做出了一些选择。在这里,作者提供了消融研究来衡量对这些决定的敏感性。更具体地说,作者调查了用于模型的标题生成模型以及提供的标题质量的影响。为了进一步提高结果,作者在训练期间使用了每个视频的多个标题,并组合数据集以训练单一模型。
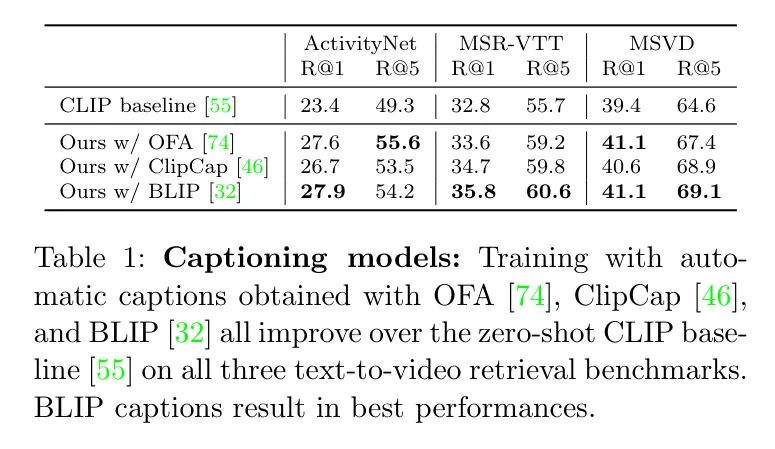
(一)标题生成模型。第一个设计选择是使用哪种图像标题生成模型。在表1中,作者进行了比较研究,实验了三种最新的标题生成模型:OFA [74],ClipCap [46] 和 BLIP [32]。更具体地说,作者使用了最好的可用模型预训练权重:用2千万公开可用的图像文本对训练的OFA-huge,用Conceptual Captions训练的ClipCap,以及用1.29亿图像训练并针对COCO进行微调的BLIP-Large。BLIP模型由于预训练量相较于其他两个模型大,获得了最好的结果。结果还证明了使用标题可以优于强大的CLIP Baseline [55],作者使用冻结的CLIP平均视频帧嵌入。注意,这与CLIP4Clip [40]中使用的均值池化方法相同。在这个实验中,作者在训练期间从两个最好的标题中随机选择一个。接下来,作者评估这种选择的影响。
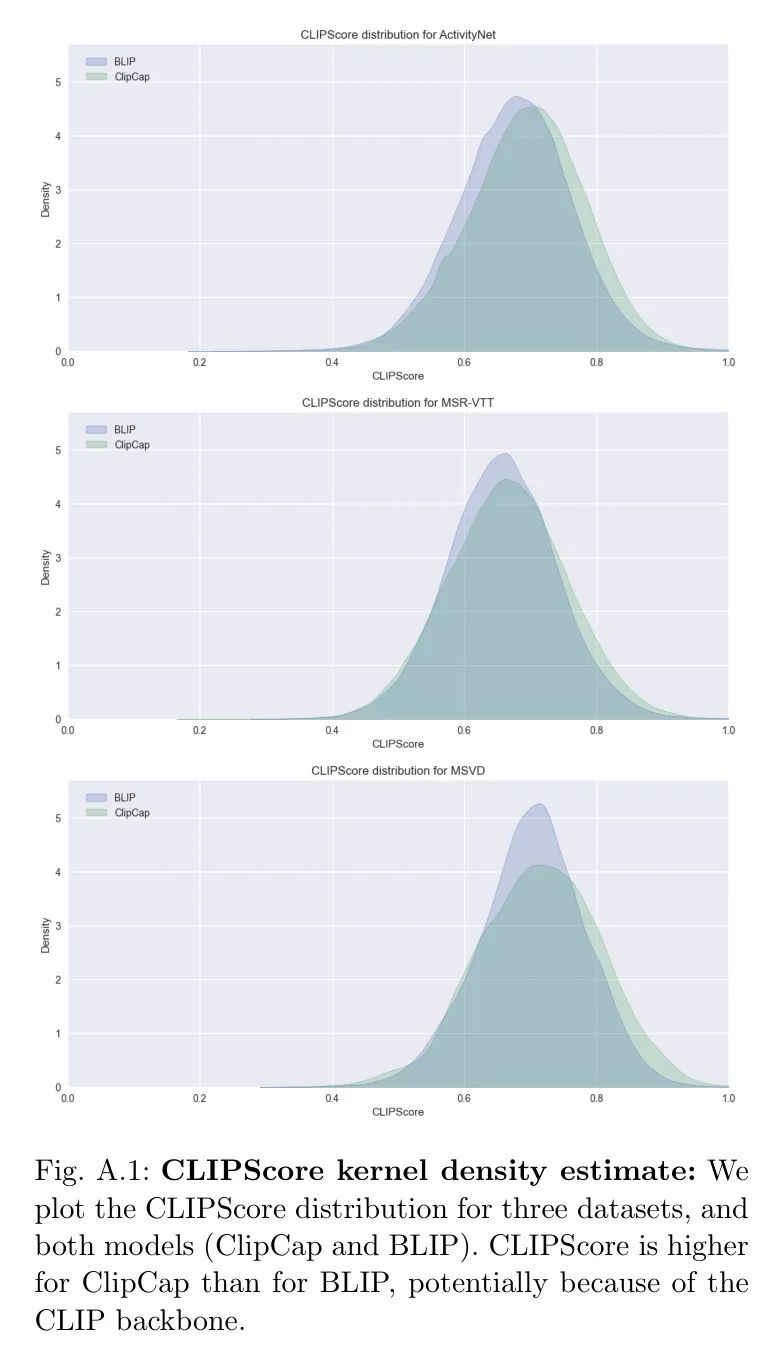
(二)标题选择。自动生成的标题在质量上有所不同。作者选择与图像文本兼容性高的标题,以消除训练中潜在噪声。上述图像标题生成模型没有输出置信度分数;因此,作者使用CLIP-Score [25] 作为生成的标题与相应输入视频帧之间的质量度量。
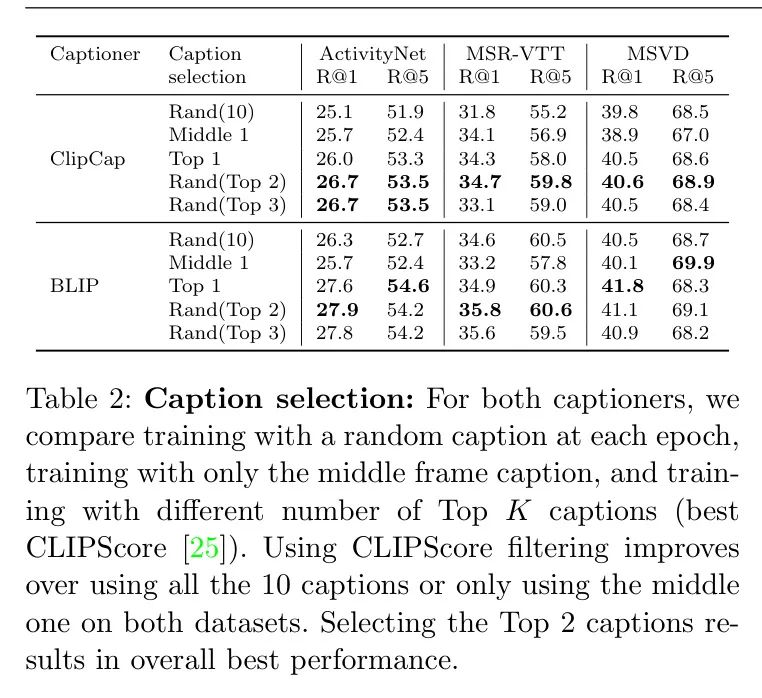
在表2中,作者评估了这种过滤是否有益。在这个实验设置中,作者用单个标题作为视频标签进行训练。作者针对每个标题生成器进行了五种不同变体的实验:(a) 在每个纪元随机选择10个提取标题中的一个;(b) 只使用对应中间帧的标题(即所有纪元中使用相同的标签);(c) 只使用最佳标题(基于CLIPscore指标的前1名);(d) 在每个纪元随机选择两个最佳标题中的一个;(e) 在每个纪元随机选择三个最佳标题中的一个。结果表明CLIPScore是一个有效的过滤方法,可以保留质量最高的标题。在所有三个数据集上,以及两种标题生成器(ClipCap和BLIP)上,使用最佳标题(们)略优于使用所有标题或中间帧的标题。特别是在ActivityNet数据集上,视频相对较长,中间帧的标题可能不具有代表性。然而,标题的数量与质量之间存在权衡。每个视频有更多标题可以避免过拟合,这可能起到数据增强的作用。另一方面,标题质量之间的差异开始增加。作者经验发现,选择两个最佳标题构成了一个好的折中方案,总体上带来了有希望的性能。然而,前1、2或3名(最后三行)之间的差异并不显著。
(三)组合标题生成器。一种在不降低标题质量的情况下增加每个视频标题数量的方法是从每个标题生成器中选择最佳的
个标题来形成标签集。在表3中,作者通过采用两个标题生成器ClipCap和BLIP,来测试这一假设,然后将它们的标签进行集成。结果显示,在大多数度量标准上,比单个标题生成器的性能略好。人们可能还会进一步扩展到更多标题生成器
。
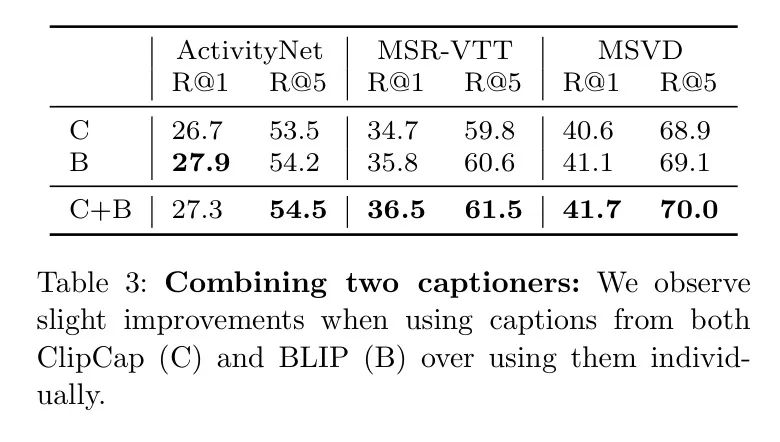
请注意,作者也可以从两个标题生成器结合的所有标题中选取前
个。这相当于从20个标题中选取最好的2个(每个标题生成器10个)。然而,这种方法会导致较差的结果,可能是由于不同的CLIPScore分布(可能是因为CLIP Backbone 网络而对ClipCap有轻微偏好),以及给定的标题生成器在连续帧中输出重复标题的倾向。作者在第D节中提供了进一步的分析。
(iv) 多标题 Query 评分(MCQS)。到目前为止,作者在每个训练迭代中只使用一个标题作为视频标签(即使这是从4个标题的集合中随机选择的)。在这里,作者探讨如何有效地结合多个标题以获得更丰富的视频标签,可能捕捉到超出单一帧标题的全局内容。在表4中,作者将多标题 Query 评分(MCQS)与之前使用的单个标题 Query 评分(QS)进行了比较,这些标题来自ClipCap和BLIP。
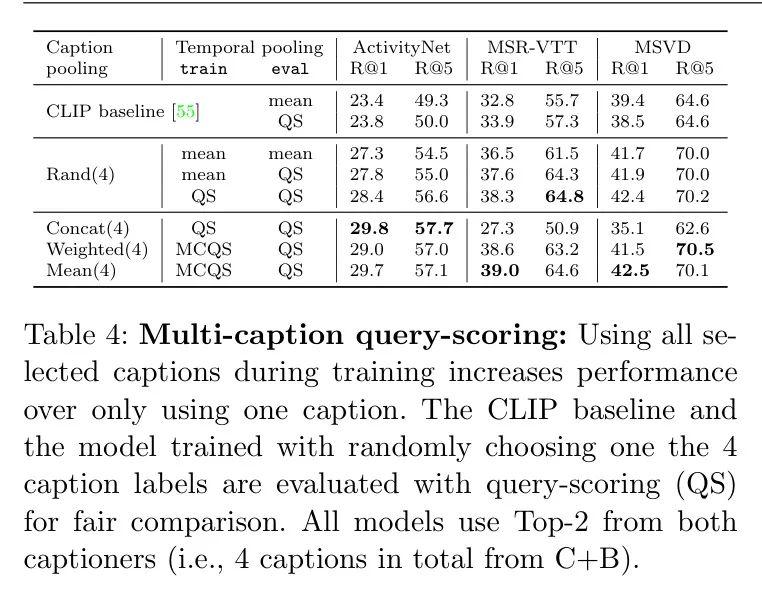
作者首先评估QS对统一平均 Baseline 的影响(即只在测试时对CLIP Baseline ,以及对一个随机选择标题 Baseline 的训练时)。从表4中的第一个观察结果是,QS在评估时略微提高了 Baseline (CLIP的33.9 vs 32.8,Rand在MSR-VTT R@1的37.6 vs 36.5)。使用QS进行训练和评估则进一步提升了性能(38.3 vs 37.6)。
在表4的后面三行中,作者探讨了使用多个标题的作者方法的三个变体:a) 将标题拼接成单个文本并仅使用普通的QS,b) 加权,c) 在MCQS中使用平均相似度池化。简单的拼接在MSR-VTT和MSVD上的性能显著下降,可能是因为在训练期间由于更长的句子导致的分布偏移(训练时4个句子 vs 评估时1个句子)。另一方面,ActivityNet的结果保持相似甚至略有改善,因为标准的评估协议在测试时也拼接了 GT 描述[40]。MCQS中的平均相似度池化在所有数据集上相对于CLIP和单个标题 Baseline 都获得了总体改进。当基于ClipScore动态加权相似度时(使用0.1的softmax温度),作者观察到性能下降。因此,作者保持方法简单,并在与多个标题联合训练MCQS时使用相似度的平均值。
(v) 使用多个数据集进行训练。鉴于作者的框架不需要手动标注的视频,因此作者不受数据集训练划分固定大小的限制,可以使用更多的数据进行训练。在表5中,作者比较了以下情况下性能的差异:(i) 在同一数据集上进行训练和评估(自身)与 (ii) 通过结合多个数据集进行训练以使用更多的数据(组合)。得到的组合训练集在视频片段数量方面来自每个数据集的分布如下:约79%来自ActivityNet,约19%来自MSR-VTT,约2%来自MSVD。这些百分比表示每个数据集对组合训练集的相对贡献,这是根据每个数据集中可用的视频总数得出的,采用统一采样方法,由于ActivityNet的大小较大,因此其代表性更高。这种联合训练对两个相对较大的数据集(ActivityNet和MSR-VTT)的性能有所改善,对较小的MSVD数据集则改善更为显著。在附录C.1节中,作者还报告了跨数据集评估的情况(例如,用ActivityNet训练并在MSR-VTT上评估)。这个实验为作者的方法在不同数据集领域的泛化能力提供了额外的见解。额外的优势是获得单一模型,而不是多个特定于数据集的模型。如果提供足够的计算资源,未来的工作可以尝试包含更大规模的数据集。
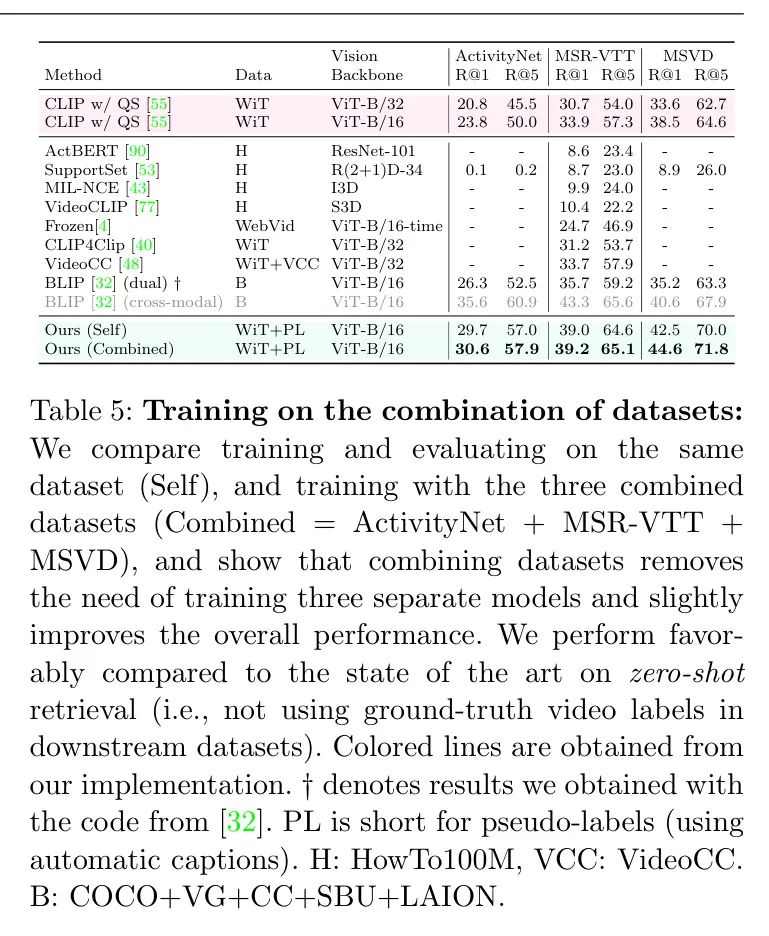
Comparison with the state of the art
在表5中,作者总结了主要针对MSR-VTT的其他零样本方法的表现,作者的方法与现有技术水平相比表现良好。表中被着色的行来自作者的实现,在可比较的设置下(例如,使用QS);未着色的行对应于其他研究。红色行表示作者的 Baseline ,绿色行展示作者最终的模型。需要注意的是,CLIP4Clip [40]的零样本版本与作者的CLIP Baseline [55]相似,因为它们都使用冻结的CLIP对帧嵌入进行均值池化。一个区别在于作者使用了 Query 评分,这在表4中已经进行了消融研究。另一个区别可能是由于不同的超参数,例如帧数(作者的为
,而[40]中为12)。需要注意的是,与其他研究相比,作者可以访问训练视频(在表5中用PL表示),尽管没有对应的 GT 标签。另一方面,一些具有竞争力的方法需要外部的大型视频来源,如WebVid [4]和VideoCC [48]。其他方法依赖于HowTo100M数据[44; 53; 77; 90]中的噪声语音信号,但它们的表现仍然不佳。
在先前的工作中,BLIP [32]在MSR-VTT和ActivityNet上获得了比作者更高的性能。然而,BLIP模型在本质上与双编码器方法不同,因为BLIP还包含一个跨模态编码器,用于额外的图像文本匹配(他们在论文中的ITM)作为一个分类任务。这个分类头获得的匹配分数随后与双编码器获得的余弦相似性进行集成。已知跨模态编码器比双编码器表现更好;然而,它们效率较低[42]。因此,在表5中作者将这一行涂灰以突出这一区别。另一方面,作者通过仅考虑单模态嵌入之间的余弦相似性(类似于CLIP的精神)来计算BLIP双编码器的性能。结果要低得多,例如,对于MSR-VTT,R@1的得分为35.7,即低于(i)他们的集成结果43.3和(ii)作者使用仅双编码器的最佳模型39.2。接下来,作者扩展作者的研究,以评估作者的方法在这种更近期的跨模态BLIP编码器上作为初始化(而不是CLIP)的适用性。
BLIP initialization
为了评估作者的方法在各种模型初始化中的适用性,作者尝试使用了除了主要的CLIP模型之外的其他 Backbone 网络。特别是,作者引入了BLIP模型[32],该模型有和没有COCO微调两种版本。BLIP的实现细节在附录的E节中进行了总结。
在表6中,作者比较了(a)CLIP和BLIP,(b)BLIP预训练的两个版本,(c)高效的 双编码器版本和昂贵的重排与BLIP的跨模态版本,如[32]中所做,(d)是否采用自动字幕进行作者的微调。在所有数据集和模型配置中,作者发现除了最后两行外,作者的自动字幕微调一致优于 Baseline 。对于CLIP Backbone 网络,改进比BLIP更为显著,后者 Baseline 性能已经接近完全监督方法(见附录的表A.1)。换句话说,随着底层 Backbone 网络 Baseline 结果越好,性能增益越边缘化。
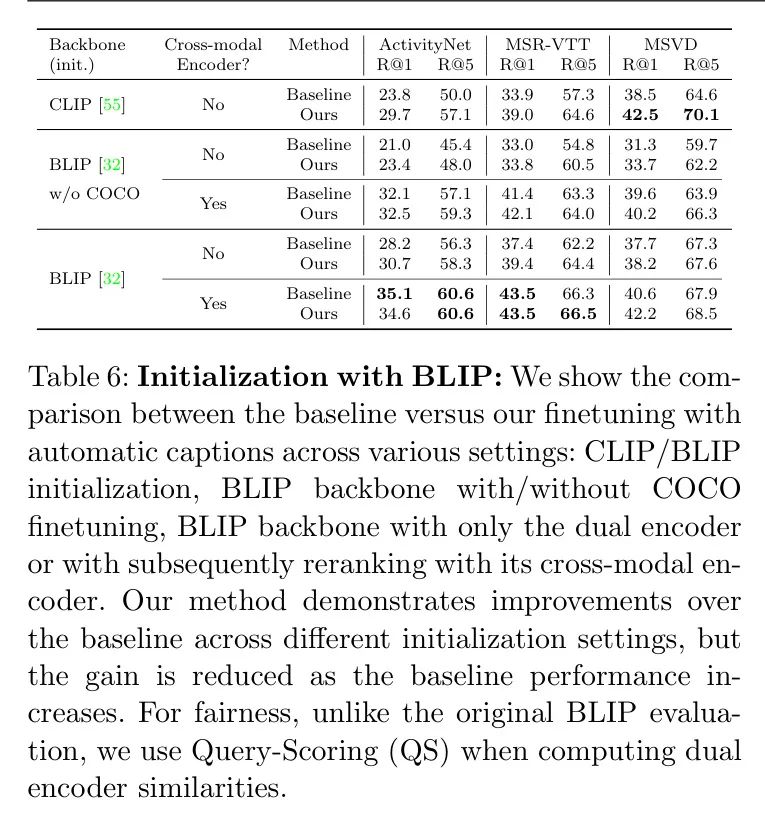
作者进一步注意到,尽管跨模态编码器的重排操作通常会带来性能提升,但其效率显著低于仅使用双编码器。具体来说,在[32]中,使用双编码器获得初始检索,然后使用昂贵的跨模态编码器对顶部-k(k=128)检索到的视频进行重排。没有跨模态编码器时,采用作者方法的CLIP基础模型显示出更优越的性能(参考表6中“跨模态编码器”下标为"No"的行)。作者还澄清了BLIP Baseline 对于双编码器和跨模态编码器配置的性能与表5略有不同,这是因为在评估中纳入了QS以进行公平比较;例如,对于双编码器,MSR-VTT R@1显示有QS和无QS的分别为37.4和35.7;对于跨模态编码器,分别为43.5和43.3。对于跨模态编码器设置,QS仅在双编码器检索阶段使用,在重排阶段不使用,因为编码器输入所有帧,无需如[32]中进行时间池化。
作者通过指出使用图像字幕对文本-视频检索数据集进行伪标记,可以在不产生任何人工标注成本的情况下微调文本到图像的 Backbone 网络,从而显著提升性能,例如比冻结的CLIP(例如,在ActivityNet上为23.8 vs 30.6,在MSR-VTT上为33.9 vs 39.2,在MSVD上为38.5 vs 44.6,见表5)。
文本 Query : 绿色衬衫的男子正在敲击手鼓。男子斜视并交谈。摄像机拉近到手鼓然后又拉远,绿色衬衫的男子继续敲鼓。
Qualitative analysis
在图3中,作者展示了在所有三个数据集上对几个示例的文本到视频的结果。对于每个测试示例,作者展示了:(a)文本 Query
(b)与文本 Query 相对应的真实视频(带有蓝色边框的第一列)
(c)排名前5的视频的中间帧(按相似度从高到低排序)
(d)如果视频匹配正确视频,则用绿色边框突出显示,否则用红色边框。
请注意,作者只可视化中间帧,这可能不代表整个视频。作者观察到,检索到的视频大多数包含与 Query 文本相关的信息。例如,对于文本 Query :“卡通片中的一个女人骑马并平静地说话”,所有检索到的视频都显示卡通。此外,有时即使正确视频没有排在第一位,也可能有多个有效选项。作者在第F节提供更多示例。
Limitations
在这里,作者讨论了这项工作的几个局限性。首先,作者指出图像字幕生成并不一定能捕捉到视频的动态内容。特别是,有些视频可能只有在观察几个帧之后才能被识别。同样,作者采用的时序池化方法相对简单,忽略了帧的顺序。然而,时序建模的努力并没有在检索基准测试[5]中带来增益。为了尝试融合时序信息,作者初步分析了使用文本摘要技术对字幕序列进行处理,但并没有得到一致的改进(见附录B)。作者实验的另一个局限性是在目标数据集的训练集中对视频进行训练。即使作者不使用它们的标签,这个设置也确保了最小的领域差距。未来的工作可以利用大量的 未标注 视频集合来消除这一需求。
5 Conclusion
作者展示了一个简单而有效的框架,利用图像字幕模型作为文本到视频检索数据集的监督来源。作者通过一系列全面的实验,证明了与强大的零样本CLIP Baseline 相比,作者取得了显著的改进。未来有几个有前景的发展方向。人们可以探索除了字幕之外更多图像专家的整合,例如开放词汇目标检测。伪标签方法可以扩展到第4.6节提到的更多种类的视频数据。可以研究自监督表示学习方法的互补性,以增加 未标注 视频中监督信号。另一个未来的方向是探索将一系列图像字幕合并成单个视频字幕的方法。
Appendix
本附录提供了在全监督设置下的实验(附录A部分),替代方法的结果(附录B部分),额外的评估(附录C部分),关于选择字幕和组合字幕生成器的分析(附录D部分),关于BLIP初始化实验的实施细节(附录E部分),额外的定性结果(附录F部分),以及数据可用性声明(附录G部分)。
Appendix A Fully-supervised setting
虽然作者的重点是零样本设置,在这种设置中无法获得标注的视频数据,但值得注意的是,对于小规模数据集,标注成本可能并不高得令人望而却步,从而允许进行完全监督的设置。在以下内容中,作者通过使用作者所使用数据集中的真实标题进行训练,微调作者提出的模型(第A.1节),并通过在多标题数据上展示MCQS的优势(第A.2节)来报告实验。
Finetuning with ground-truth captions
作者展示了作者提出的方法可以作为预训练步骤。在这里,作者尝试用自动生成的字幕初始化一个模型并进行训练,然后使用真实字幕进行微调以进一步提高性能。表A.1总结了这些结果。底部的灰色行比较了用真实字幕(i)从CLIP初始化(带有WiT+GT数据的行)微调模型,或者(ii)用作者的方法进行预训练后(最后一行带有WiT+GT+PL数据)微调模型。这种比较突显了使用作者提出的方法作为预训练步骤的好处,因为它在目标数据集上的性能进一步得到了提升。作者注意到,在使用真实数据训练时,无论是(i)从CLIP初始化进行微调还是(ii)使用伪标签进行预训练后进行微调,作者都保持所有超参数相同。
Multi-caption training on MSR-VTT
MSR-VTT视频配有每个视频的20个真实标注字幕。因此在完全监督的设置下,作者可以使用作者的MCQS方法进行训练。在表A.2中,作者展示了使用所有真实标注字幕与MCQS同时使用,比在每次训练迭代中随机抽取单个字幕的效果要好。
作者选择了两个CLIPScore [25]最高的,以及(iii)平均它们的嵌入向量。然后,作者将一个文本 Query (也用S-BERT嵌入)与这个视频表示使用余弦相似度进行比较。在表4中,作者总结了结果。在测试的两个文本编码中,S-BERT的表现优于CLIP文本编码器,因为S-BERT被专门训练用来检测相似的句子。然而,即使是表现最好的字幕瓶颈(即,使用S-BERT的BLIP)也比零样本CLIP Baseline 的结果要差。这种基于字幕的检索方法的性能不佳表明,字幕不足以直接用于检索,但它们可以提供训练的监督信号。
文本摘要。 如主论文第4.6节所述,作者探讨了使用文本摘要模型来组合给定视频中的多个字幕,作者的尝试导致了不一致的结果,如表5所示。作者尝试总结两个标注者的10个字幕(对ClipCap来说是Summ(10C),对BLIP来说是Summ(10B)),以及过滤和组合的4个字幕的总结(Summ(2C+2B))。为了总结字幕,作者使用了OpenAI中的Ada语言模型。作者从实验中发现,在摘要前随机抽样一个原始字幕有助于提供更长的字幕,其中包含局部和全局信息(即,当prepend列不为空时,表5的结果有所改善,例如,37.5对比35.9)。
Appendix C Additional evaluations
在本节中,作者报告了跨数据集评估(第C.1节)、在ActivityNet上的多字幕评估(第C.2节)以及视频到文本检索的性能指标(第C.3节)。
Cross-dataset evaluation
正如主论文第4.2节所提及,作者报告了跨数据集的评估结果。在表6中,作者使用了通过多标题 Query 评分训练的模型,其中对角线对应于第5节倒数第二行(在相同数据集上进行训练和评估)。有趣的是,在ActivityNet上评估MSR-VTT训练的性能几乎与使用ActivityNet视频训练的性能一样好。此外,仅在MSVD上训练的模型在所有数据集上的表现都很差(包括它自身),这是由于其规模较小。
在中。作者不是将多个标题连接成一个文本 Query ,而是可以使用视频的所有可用的描述作为文本 Query ,并使用作者的多标题 Query 评分方法进行评估。在表A.7中,作者观察到使用这种方法进一步提高了性能。
Video-to-text retrieval metrics
在主文中,作者仅报告了文本到视频检索的指标。在这里,在表A.8中,作者报告了视频到文本的指标。作者看到,作者的方法在这些指标上也比 Baseline 有所改进。
与BLIP的前2名相比。可以看出,大约只有7%的情况下,两个字幕生成器的前两个字幕来自完全相同的两个帧。超过44%的情况下,两个字幕生成器有一个共同的帧。最后,最常见的情况是,从10个可能的帧中选择了4个不同的帧:每个字幕生成器各选了2个。
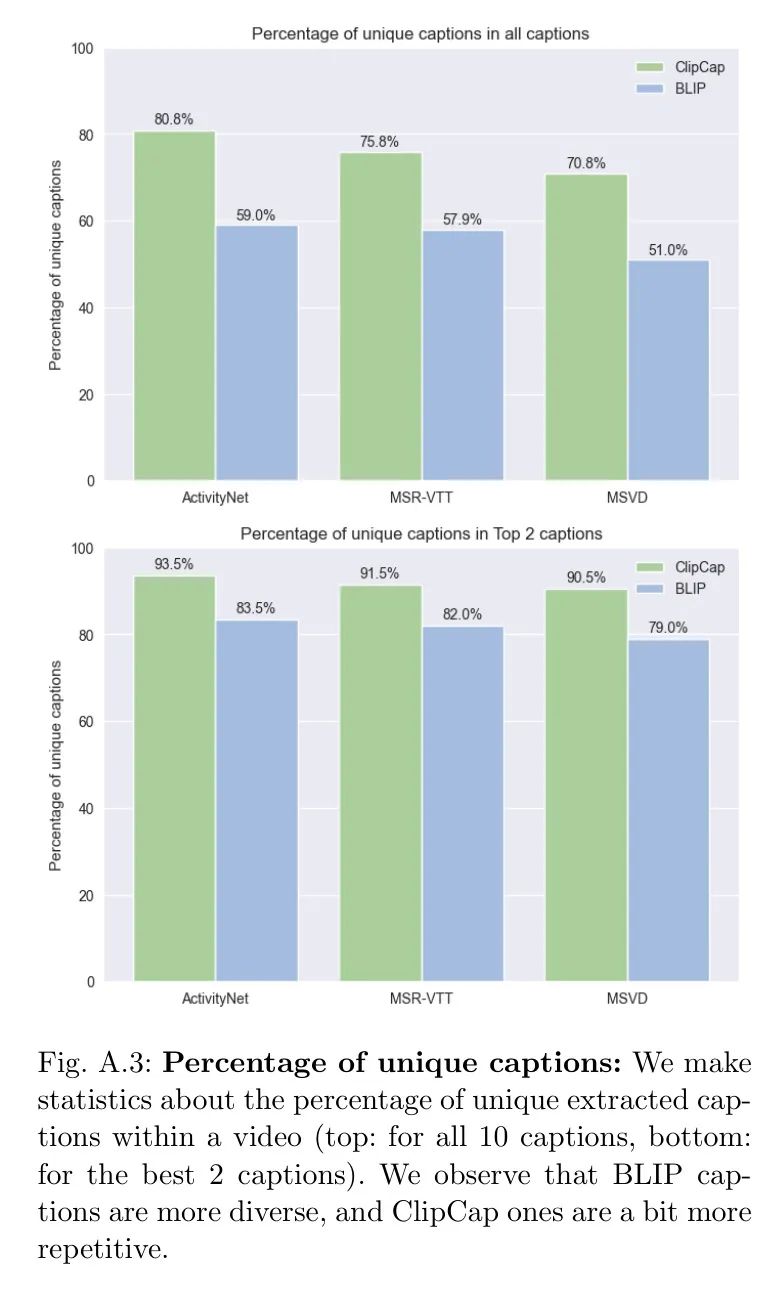
重复性字幕。 过滤字幕的另一个好处是,作者得到了一组重复性较低的字幕。参见图A.3,在使用10个字幕和前2个字幕时唯一字幕的百分比。作者还验证了在任何三个数据集中,两个字幕生成器之间重叠的字幕少于1%。这是另一个促使作者使用不同的字幕生成器以获得更多样化和丰富字幕的原因。
两个字幕生成器之外。作者在表11中探索了结合ClipCap(C)、BLIP(B)和OFA(O)三种不同字幕。结果并没有在两个指标上带来一致的改进(R@1更好,R@5更差),可能是因为与BLIP相比,OFA单独的表现效果不佳。
E Implementation details for the BLIP initialization experiment
作者在这里解释第6节中主干网络实验的BLIP实现细节。作者采用类似于BLIP的方法进行训练,其中图像-文本对比(ITC)损失表示为作者方程(5)中的
。对于图像-文本匹配(ITM)损失,作者通过帧数来扩展编码器的隐藏状态。作者使用4帧进行训练,使用8帧进行评估。作者采用与BLIP相同的ViT-B/16主干网络作为图像编码器,以及BERT架构[14]作为文本编码器。作者使用单个NVIDIA RTX A600以4帧训练模型,而评估则按照原论文中使用8帧进行。
Appendix F Additional qualitative results
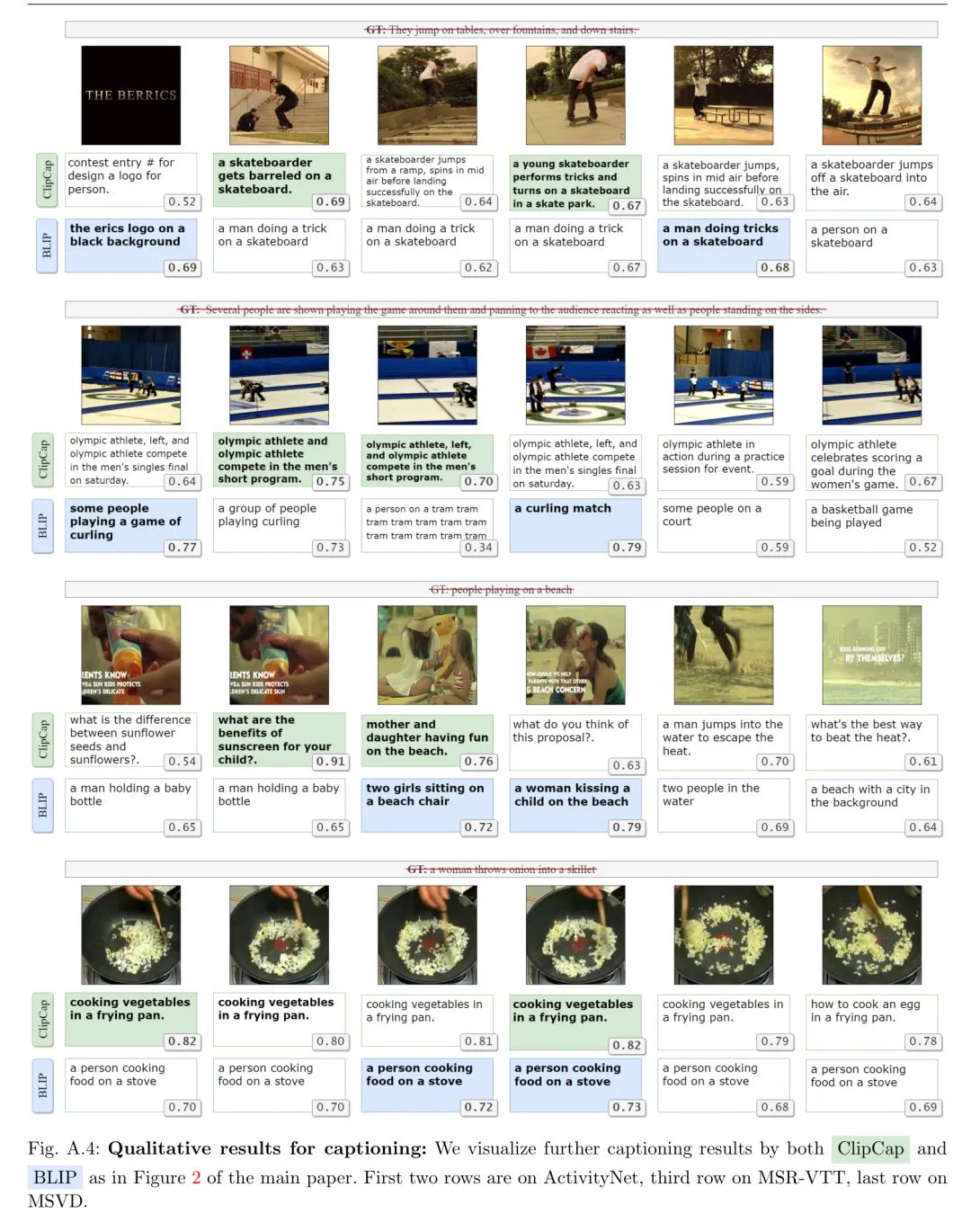
标题翻译保留。与主论文中的图2类似,在图4中,作者提供了更多来自ClipCap和BLIP的标题生成结果的例子,以及与图像嵌入相比的相应CLIPScores。在第二个视频的第三张图片或第三个视频的第一张图片中,作者看到当标题与帧不匹配时,CLIPScore较低。在最后一个视频中,作者看到了一个所有帧看起来都相似的短视频例子,提取的标题相同或几乎相同。
检索。 为了补充主论文中的图3,作者在图5中为三个数据集提供了额外的定性结果:ActivityNet(前两行),MSR-VTT(中间两行)和MSVD(后两行)。

Appendix G Data availability statement
作者在三个流行的文本到视频检索公共数据集上进行了实验,分别是ActivityNet [29],MSR-VTT [78]和MSVD [9]。以下是下载数据集的URL:
- ActivityNet
- MSR-VTT
- MSVD
作者用自动生成的字幕标签来补充这些数据集,并将与作者的代码和预训练模型一起发布。图A.4:字幕生成的定性结果: 作者在主论文图2的基础上,通过ClipCap和BLIP进一步可视化了字幕生成结果。前两行是ActivityNet上的结果,第三行是MSR-VTT上的结果,最后一行是MSVD上的结果。
图5:文本到视频检索的定性结果: 上方展示了作者最佳模型(Combined)的视频检索结果。这些示例属于ActivityNet(前两行)、MSR-VTT(第三和第四行)和MSVD(最后两行)的测试集。每个示例都展示了文本 Query 、 GT 视频(第一列,蓝色边框)以及从图库中检索到的前5个视频。每个视频仅使用中间帧显示,如果与 GT 视频匹配,则用绿色边框,否则用红色边框。总体而言,所有检索到的视频都与文本 Query 具有相似的语义意义,即使在正确视频没有在第一个排名检索到的情况下也是如此。
参考
[1].Learning text-to-video retrieval from image captioning.