ByteDance| 将MoE 整合至多模态LLMs,降低了推理成本,多模态性能达到SOTA!
ByteDance| 将MoE 整合至多模态LLMs,降低了推理成本,多模态性能达到SOTA!

点击上方“AINLPer“,设为星标
更多干货,第一时间送达
引言
目前多模态LLMs主要通过增加文图对( text-image)数据和增强LLMs来提升性能,然而,此类方法计算成本较高,同时忽略了从视觉方面提升模型能力的重要性。
为此,作者提出了CuMo,将MoE应用于多模态LLM,该方法在视觉编码器和多层感知器(MLP)连接器中整合了Top-K稀疏门控MoE块,有效提升了模型在多模态任务上的性能,同时保持了较低的推理成本。在不同模型尺寸的多模态任务基准测试中达到了SOTA。
https://arxiv.org/pdf/2405.05949v1
背景介绍
GPT-4v的出现激起了开源社区将大语言模型(LLM)转化为多模态大模型(MLLM)的热情。当前的多模态LLM通常结合预训练的视觉编码器和LLM,并通过视觉指令调优数据来进行微调,以增强模型的视觉理解能力。为了进一步扩展多模态LLM,先前的努力主要集中在使用更广泛的文图对(text-image)数据集进行训练,并采用更强大的LLM,这显著增加了训练工作量和算力成本。
在视觉方面,研究者们也尝试了多种方法,如使用多个视觉编码器、更大的视觉编码器和先进的视觉-语言连接器来提高多模态任务的性能,然而,这这些技术增加了额外的参数和视觉Token,影响了扩展效率。
在模型扩展方面,混合专家(Mixture-of Experts ,MoE) 模型已然成为了模型扩展、增强模型性能的主流技术,特别是在自然语言处理 (NLP) 领域。MoE 的一个显著优势是它们能够在远少于 Dense 模型所需的计算资源下进行预训练,且与Dense模型相比,达到相同的质量水平,MoE模型需要的时间更短。尽管如此,MoE模型的开发和优化主要针对LLM,而将MoE应用于多模态LLM,尤其是在视觉方面的扩展,目前还鲜有探索。
基于以上背景,本文作者提出了CuMo,将 Top-K 稀疏门控 MoE 模块集成到视觉编码器和多模态 LLM 的 MLP 连接器中,降低了成本,提升了模型在多模态任务上的性能。
CuMo
CuMo模型架构如下图所示,它将Top-K MoE模块合并到CLIP视觉编码器和视觉语言 MLP 连接器中,从而从视觉方面提高了多模态 LLM 能力。
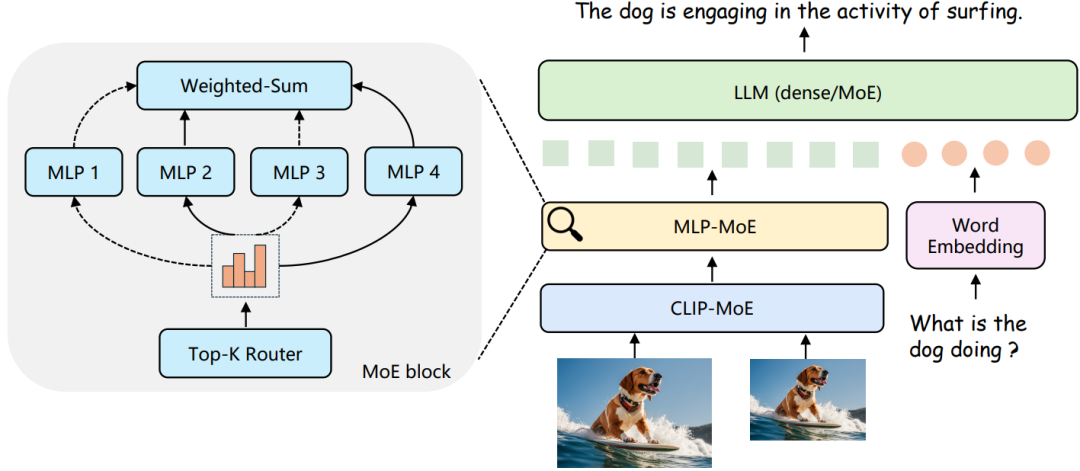
「MLP-MOE」 MLP连接器将视觉Token转换为词嵌入空间,从而对齐视觉Token和文本Token之间的尺寸。视觉语言连接器的有效架构是包含两个线性层的MLP块。本文从单个 MLP 块开始,并将其替换为Top-K稀疏 MoE 块,合并一个Top-K路由和一组用于将视觉Token投影到词嵌入空间的Experts。
「CLIP-MoE」 视觉编码器主要是从图像中提取特征,形成视觉Token序列,供大模型(LLM)进行推理使用。CLIP作为多模态LLM中常用的预训练视觉编码器,非常适合处理多模态应用中的图像。CLIP的视觉编码部分采用ViT模型,该模型在Transformer编码器中包含连续的MLP块。为了进一步提升模型的性能和扩展性,本文作者将每个MLP块替换为Top-K稀疏混合专家(MoE)块,并保留了MoE块输出旁的跳跃连接,以此来优化视觉编码过程。
「LLM(dense/Moe)」 作者对比了co-upcycled LLM和预训练MoE-based LLM,以Mistral-7B为基础模型,尽管Mistral-7B-MoE在部分基准测试中略胜Mistral-7B。但由于其专家的知识基础较窄,与具有更广泛知识基础的预训练模型Mixtral 8x7B相比,后者的性能显著更佳。因此,LLM并未像CLIP视觉编码器和MLP连接器一样进行co-upcycled。
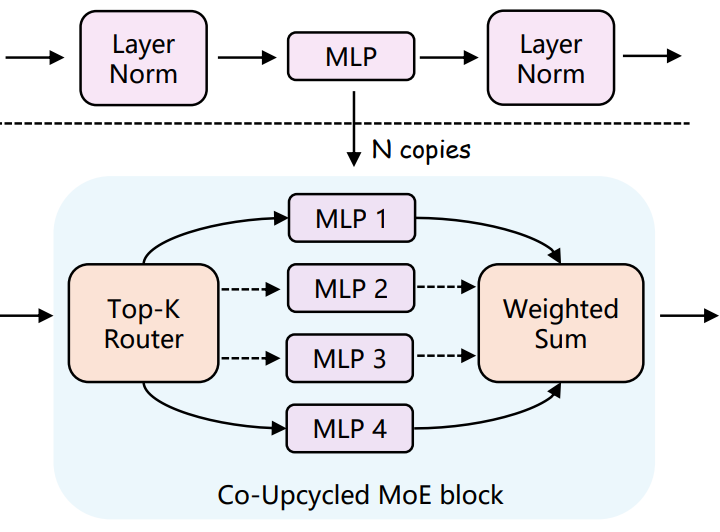
「Co-Upcycling MoE」 本文在训练过程中,还遇到了模型难以收敛的挑战,尤其在从头开始训练新增的MoE块时。尽管尝试降低学习率,但这种方法的效果反而不如基线模型。为了改善这一状况,本文采用了共同循环利用的方法,即利用预训练的多层感知器(MLP)初始化集成了稀疏门控MoE块的模块,以替换原有的MLP块,如下图所示。结果表明,该方法不仅增强了训练过程的稳定性,还显著提升了模型的整体性能
「三阶段训练策略」 CuMo模型通过一个三阶段的训练策略来增强训练的稳定性,该策略确保了模型在不同阶段的逐步优化和稳定性提升。如下图所示:
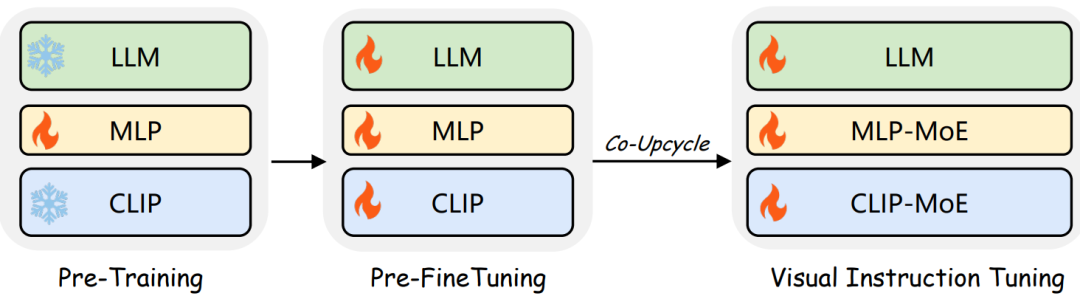
具体来说,第一阶段,专注于对MLP连接器进行预训练,而视觉编码器和大模型(LLM)已基于大规模数据完成了它们的预训练。第二阶段为预微调,此时使用高质量的标题数据来训练模型的所有参数,以便在模型中引入MoE块之前激活和预热整个系统。最后,在第三阶段,进行视觉指令的微调,此时多模态LLM利用共同循环利用的MoE块进行扩展,并专门针对视觉指令调整数据进行训练,以进一步提升模型在多模态任务上的性能。
实验结果
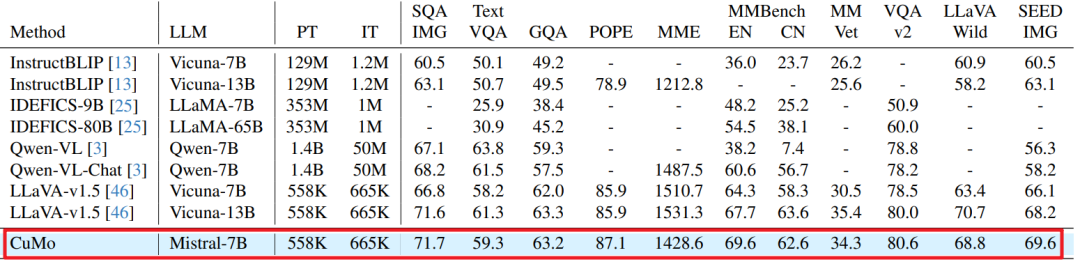
CuMo模型与其它指令跟随多模态LLMs进行了比较,如下图所示。CuMo Mistral-7B在多个基准测试中优于其他基于7B的顶尖多模态LLMs,并且与许多13B模型的性能相当。
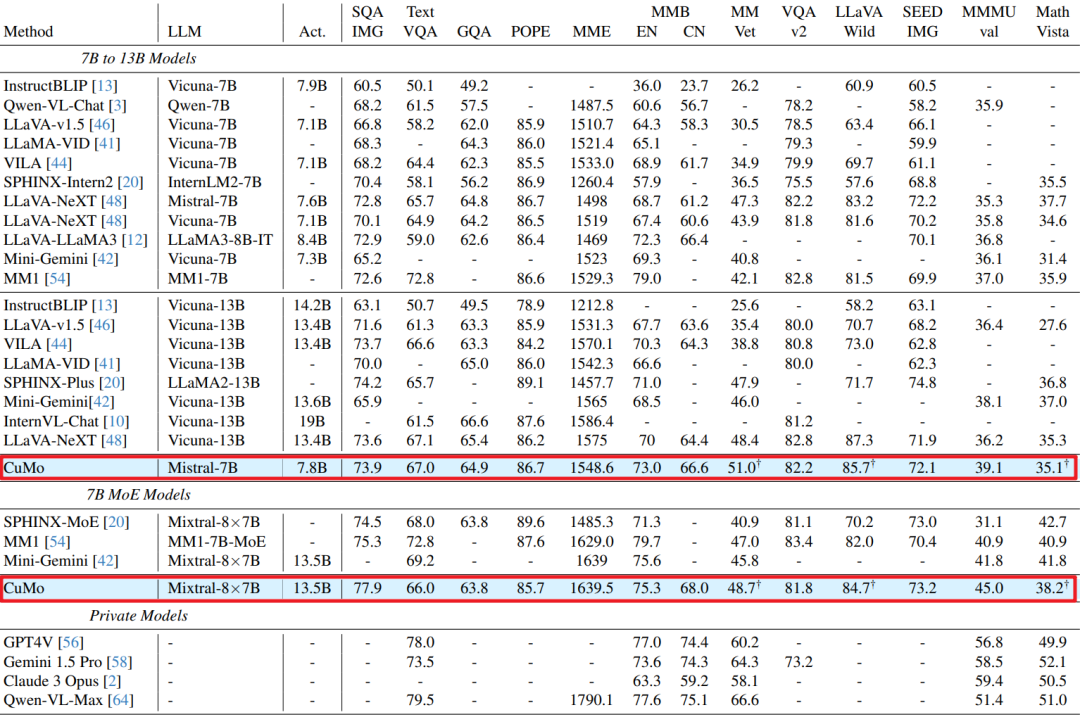
下表展示了CuMo Mistral-7B在有限训练数据下的性能,即使在训练数据较少的情况下,CuMo仍然优于其他7B模型,并且与LLaVA v1.5 Vicuna-13B的性能相当。