腾讯给机会了?有点简单啊!

大家好,我是小林。
今天分享一位同学面试腾讯的Java后端面经,考察的知识点,主要是这些,范围是网络、Java、mysql、redis、算法。
相比其他同学的腾讯面经,这次的面经问题都还算比较简单和基础的,没有太难的题目。

网络
介绍一下网络模型
OSI 网络模型,该模型主要有 7 层,分别是应用层、表示层、会话层、传输层、网络层、数据链路层以及物理层。
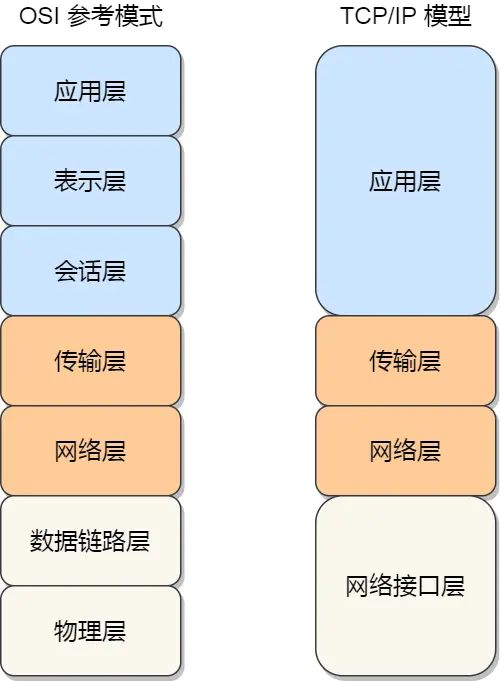
- 应用层:应用层最接近终端用户。大多数应用程序都位于这一层。我们从后端服务器请求数据,无需了解数据传输的具体细节。这一层的协议包括 HTTP、SMTP、FTP、DNS 等。
- 表现层:这一层处理数据编码、加密和压缩,为应用层准备数据。例如,HTTPS 利用 TLS 实现客户端与服务器之间的安全通信。
- 会话层:该层用于打开和关闭两个设备之间的通信。如果数据量较大,会话层就会设置检查点,避免从头开始重新发送。
- 传输层:该层处理两个设备之间的端到端通信。它在发送方将数据分解成段,然后在接收方重新组装。这一层有流量控制,以防止拥塞。这一层的主要协议是 TCP 和 UDP。
- 网络层:这一层实现不同网络之间的数据传输。它进一步将网段或数据报分解成更小的数据包,并使用 IP 地址找到通往最终目的地的最佳路由。这一过程被称为路由选择。
- 数据链路层:这一层允许在同一网络的设备之间传输数据。数据包被分解成帧,这些帧被限制在局域网内。
- 物理层:这一层通过电缆和交换机发送比特流,因此与设备之间的物理连接密切相关。
TCP/IP 网络模型共有 4 层,分别是应用层、传输层、网络层和网络接口层,每一层负责的职能如下:
- 应用层,负责向用户提供一组应用程序,比如 HTTP、DNS、FTP 等;
- 传输层,负责端到端的通信,比如 TCP、UDP 等;
- 网络层,负责网络包的封装、分片、路由、转发,比如 IP、ICMP 等;
- 网络接口层,负责网络包在物理网络中的传输,比如网络包的封帧、 MAC 寻址、差错检测,以及通过网卡传输网络帧等;
TCP/IP 这一模型更贴近现实世界的互联网通信,将七个 OSI 层压缩为这四个关键层。
tcp、ip分别位于哪一层?
- tcp 在传输层
- ip 在网络层
应用层有哪些协议?
HTTP、HTTPS、CDN、DNS、FTP 都是应用层协议
dns的全称了解么?
DNS的全称是Domain Name System(域名系统),它是互联网中用于将域名转换为对应IP地址的分布式数据库系统。DNS扮演着重要的角色,使得人们可以通过易记的域名访问互联网资源,而无需记住复杂的IP地址。
DNS 中的域名都是用句点来分隔的,比如 www.server.com,这里的句点代表了不同层次之间的界限。
在域名中,越靠右的位置表示其层级越高。
毕竟域名是外国人发明,所以思维和中国人相反,比如说一个城市地点的时候,外国喜欢从小到大的方式顺序说起(如 XX 街道 XX 区 XX 市 XX 省),而中国则喜欢从大到小的顺序(如 XX 省 XX 市 XX 区 XX 街道)。
实际上域名最后还有一个点,比如 www.server.com.,这个最后的一个点代表根域名。
也就是,. 根域是在最顶层,它的下一层就是 .com 顶级域,再下面是 server.com。所以域名的层级关系类似一个树状结构:
- 根 DNS 服务器(.)
- 顶级域 DNS 服务器(.com)
- 权威 DNS 服务器(server.com)
根域的 DNS 服务器信息保存在互联网中所有的 DNS 服务器中。
这样一来,任何 DNS 服务器就都可以找到并访问根域 DNS 服务器了。
因此,客户端只要能够找到任意一台 DNS 服务器,就可以通过它找到根域 DNS 服务器,然后再一路顺藤摸瓜找到位于下层的某台目标 DNS 服务器。
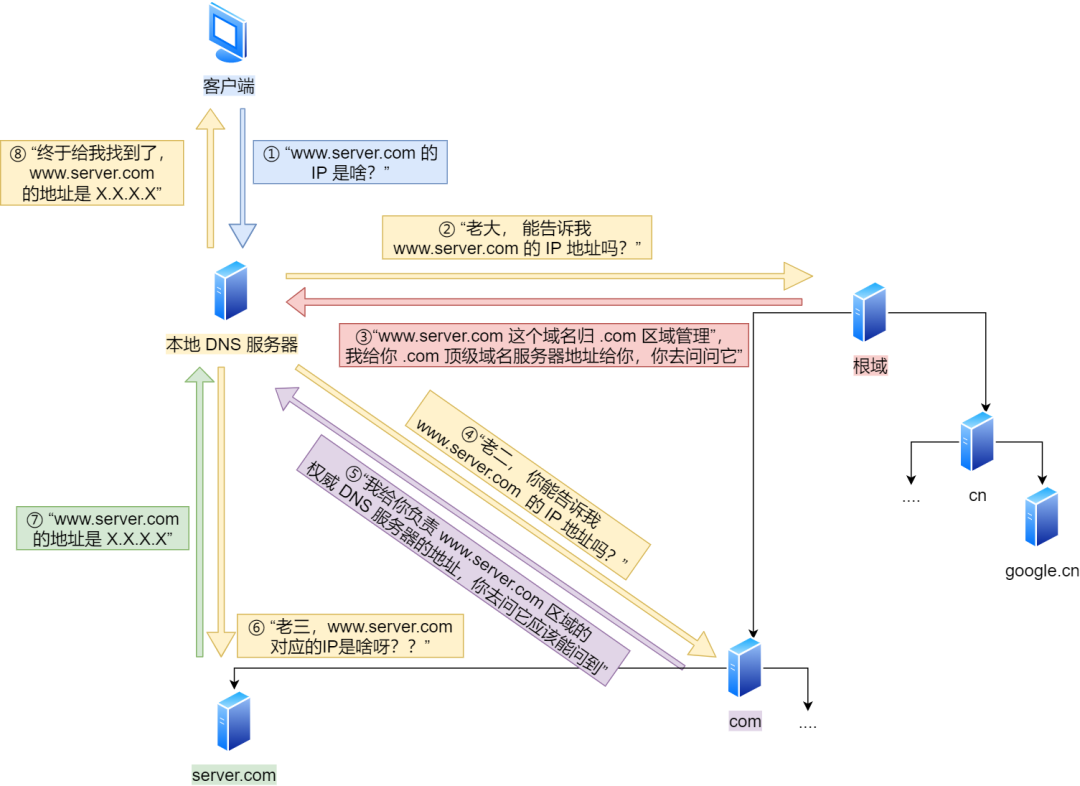
域名解析的工作流程
- 客户端首先会发出一个 DNS 请求,问 www.server.com 的 IP 是啥,并发给本地 DNS 服务器(也就是客户端的 TCP/IP 设置中填写的 DNS 服务器地址)。
- 本地域名服务器收到客户端的请求后,如果缓存里的表格能找到 www.server.com,则它直接返回 IP 地址。如果没有,本地 DNS 会去问它的根域名服务器:“老大, 能告诉我 www.server.com 的 IP 地址吗?” 根域名服务器是最高层次的,它不直接用于域名解析,但能指明一条道路。
- 根 DNS 收到来自本地 DNS 的请求后,发现后置是 .com,说:“www.server.com 这个域名归 .com 区域管理”,我给你 .com 顶级域名服务器地址给你,你去问问它吧。”
- 本地 DNS 收到顶级域名服务器的地址后,发起请求问“老二, 你能告诉我 www.server.com 的 IP 地址吗?”
- 顶级域名服务器说:“我给你负责 www.server.com 区域的权威 DNS 服务器的地址,你去问它应该能问到”。
- 本地 DNS 于是转向问权威 DNS 服务器:“老三,www.server.com对应的IP是啥呀?” server.com 的权威 DNS 服务器,它是域名解析结果的原出处。为啥叫权威呢?就是我的域名我做主。
- 权威 DNS 服务器查询后将对应的 IP 地址 X.X.X.X 告诉本地 DNS。
- 本地 DNS 再将 IP 地址返回客户端,客户端和目标建立连接。
至此,我们完成了 DNS 的解析过程。现在总结一下,整个过程我画成了一个图。
上传下载视频使用的应用层协议是什么?
上传下载视频通常使用的应用层协议是HTTP或者FTP。HTTP常用于Web服务器和客户端之间的通信,而FTP专门设计用于文件传输。
Java
Java为什么要有Integer?
Integer对应是int类型的包装类,就是把int类型包装成Object对象,对象封装有很多好处,可以把属性也就是数据跟处理这些数据的方法结合在一起,比如Integer就有parseInt()等方法来专门处理int型相关的数据。
另一个非常重要的原因就是在Java中绝大部分方法或类都是用来处理类类型对象的,如ArrayList集合类就只能以类作为他的存储对象,而这时如果想把一个int型的数据存入list是不可能的,必须把它包装成类,也就是Integer才能被List所接受。所以Integer的存在是很必要的。
泛型中的应用
在Java中,泛型只能使用引用类型,而不能使用基本类型。因此,如果要在泛型中使用int类型,必须使用Integer包装类。例如,假设我们有一个列表,我们想要将其元素排序,并将排序结果存储在一个新的列表中。如果我们使用基本数据类型int,无法直接使用Collections.sort()方法。但是,如果我们使用Integer包装类,我们就可以轻松地使用Collections.sort()方法。
List<Integer> list = new ArrayList<>();
list.add(3);
list.add(1);
list.add(2);
Collections.sort(list);
System.out.println(list);
转换中的应用
在Java中,基本类型和引用类型不能直接进行转换,必须使用包装类来实现。例如,将一个int类型的值转换为String类型,必须首先将其转换为Integer类型,然后再转换为String类型。
int i = 10;
Integer integer = new Integer(i);
String str = integer.toString();
System.out.println(str);
集合中的应用
Java集合中只能存储对象,而不能存储基本数据类型。因此,如果要将int类型的数据存储在集合中,必须使用Integer包装类。例如,假设我们有一个列表,我们想要计算列表中所有元素的和。如果我们使用基本数据类型int,我们需要使用一个循环来遍历列表,并将每个元素相加。但是,如果我们使用Integer包装类,我们可以直接使用stream()方法来计算所有元素的和。
List<Integer> list = new ArrayList<>();
list.add(3);
list.add(1);
list.add(2);
int sum = list.stream().mapToInt(Integer::intValue).sum();
System.out.println(sum);
Integer相比int有什么优点?
int是Java中的原始数据类型,而Integer是int的包装类。Integer和 int 的区别:
- 基本类型和引用类型:首先,int是一种基本数据类型,而Integer是一种引用类型。基本数据类型是Java中最基本的数据类型,它们是预定义的,不需要实例化就可以使用。而引用类型则需要通过实例化对象来使用。这意味着,使用int来存储一个整数时,不需要任何额外的内存分配,而使用Integer时,必须为对象分配内存。在性能方面,基本数据类型的操作通常比相应的引用类型快。
- 自动装箱和拆箱:其次,Integer作为int的包装类,它可以实现自动装箱和拆箱。自动装箱是指将基本类型转化为相应的包装类类型,而自动拆箱则是将包装类类型转化为相应的基本类型。这使得Java程序员更加方便地进行数据类型转换。例如,当我们需要将int类型的值赋给Integer变量时,Java可以自动地将int类型转换为Integer类型。同样地,当我们需要将Integer类型的值赋给int变量时,Java可以自动地将Integer类型转换为int类型。
- 空指针异常:另外,int变量可以直接赋值为0,而Integer变量必须通过实例化对象来赋值。如果对一个未经初始化的Integer变量进行操作,就会出现空指针异常。这是因为它被赋予了null值,而null值是无法进行自动拆箱的。
那为什么还要保留int类型?
包装类是引用类型,对象的引用和对象本身是分开存储的,而对于基本类型数据,变量对应的内存块直接存储数据本身。
因此,基本类型数据在读写效率方面,要比包装类高效。除此之外,在64位JVM上,在开启引用压缩的情况下,一个Integer对象占用16个字节的内存空间,而一个int类型数据只占用4字节的内存空间,前者对空间的占用是后者的4倍。
也就是说,不管是读写效率,还是存储效率,基本类型都比包装类高效。
数据库
有MySQL为什么还要有Redis?
主要是因为 Redis 具备「高性能」和「高并发」两种特性。
1、Redis 具备高性能
假如用户第一次访问 MySQL 中的某些数据。这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据缓存在 Redis 中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了,操作 Redis 缓存就是直接操作内存,所以速度相当快。
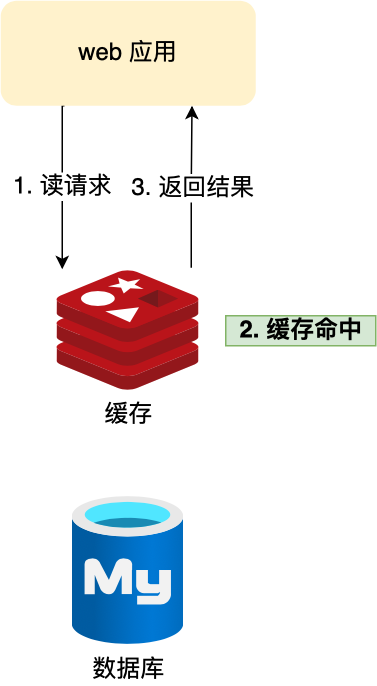
如果 MySQL 中的对应数据改变的之后,同步改变 Redis 缓存中相应的数据即可,不过这里会有 Redis 和 MySQL 双写一致性的问题,后面我们会提到。
2、 Redis 具备高并发
单台设备的 Redis 的 QPS(Query Per Second,每秒钟处理完请求的次数) 是 MySQL 的 10 倍,Redis 单机的 QPS 能轻松破 10w,而 MySQL 单机的 QPS 很难破 1w。
所以,直接访问 Redis 能够承受的请求是远远大于直接访问 MySQL 的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。
为什么既要用MySQL还要用Redis?
- redis 是内存数据库,读写速度非常快,适合缓存热数据,但是有数据丢失的风险,而且不是关系型数据库,没办法实现一些关联查询的需求。
- mysql 是关系型数据库,可以实现一些复杂的查询需求,而且数据是存储到磁盘的,支持 ACID 特性,保证数据的一致性、可靠性和持久性。
MySQL用于持久化数据存储和复杂查询,而Redis用于缓存热数据、提高读取速度和处理高并发访问。这样的组合可以充分发挥两者的优势,提升系统的整体性能和稳定性。
Redis的缓存失效会不会立即删除?
不会,Redis 的过期删除策略是选择「惰性删除+定期删除」这两种策略配和使用。
- 惰性删除策略的做法是,不主动删除过期键,每次从数据库访问 key 时,都检测 key 是否过期,如果过期则删除该 key。
- 定期删除策略的做法是,每隔一段时间「随机」从数据库中取出一定数量的 key 进行检查,并删除其中的过期key。
那为什么我不过期立即删除?
在过期 key 比较多的情况下,删除过期 key 可能会占用相当一部分 CPU 时间,在内存不紧张但 CPU 时间紧张的情况下,将 CPU 时间用于删除和当前任务无关的过期键上,无疑会对服务器的响应时间和吞吐量造成影响。所以,定时删除策略对 CPU 不友好。
高并发场景,Redis单节点+MySQL单节点能有多大的并发量?
- 如果缓存命中的话,4 核心 8g 内存的配置,redis 可以支撑 10w 的 qps
- 如果缓存没有命中的话,4 核心 8g 内存的配置,mysql 只能支持 5000 左右的 qps
那Redis的并发量大概是一个什么样的数量级?
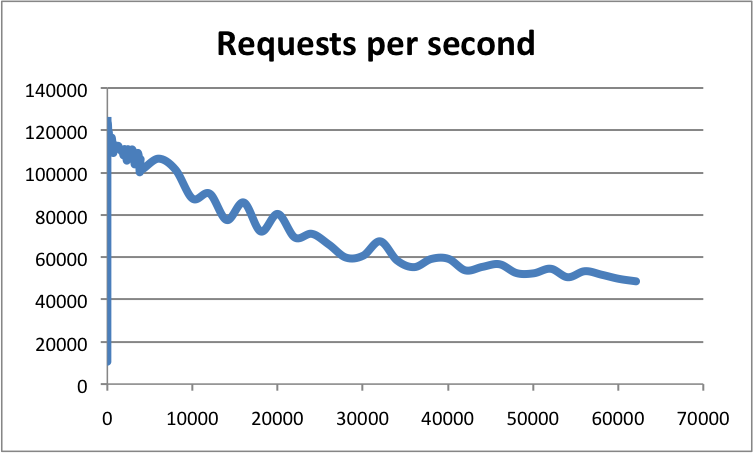
官方使用基准测试的结果是,单线程的 Redis 吞吐量可以达到 10W/每秒,如下图所示:
之所以 Redis 采用单线程(网络 I/O 和执行命令)那么快,有如下几个原因:
- Redis 的大部分操作都在内存中完成,并且采用了高效的数据结构,因此 Redis 瓶颈可能是机器的内存或者网络带宽,而并非 CPU,既然 CPU 不是瓶颈,那么自然就采用单线程的解决方案了;
- Redis 采用单线程模型可以避免了多线程之间的竞争,省去了多线程切换带来的时间和性能上的开销,而且也不会导致死锁问题。
- Redis 采用了 I/O 多路复用机制处理大量的客户端 Socket 请求,IO 多路复用机制是指一个线程处理多个 IO 流,就是我们经常听到的 select/epoll 机制。简单来说,在 Redis 只运行单线程的情况下,该机制允许内核中,同时存在多个监听 Socket 和已连接 Socket。内核会一直监听这些 Socket 上的连接请求或数据请求。一旦有请求到达,就会交给 Redis 线程处理,这就实现了一个 Redis 线程处理多个 IO 流的效果。
索引已经建好了,那我再插入一条数据,索引会有哪些变化?
插入新数据可能导致B+树结构的调整和索引信息的更新,以保持B+树的平衡性和正确性,这些变化通常由数据库系统自动处理,确保数据的一致性和索引的有效性。
如果插入的数据导致叶子节点已满,可能会触发叶子节点的分裂操作,以保持B+树的平衡性。
那索引的底层原理是什么呢?
mysql 默认的存储引擎 innodb 中,是用 b+树作为索引的数据结构。有了索引,数据能按照索引有序存储,这样我们就可以用二分查找的方式快速检索数据。
B+树的原理是什么呢?
B+Tree 是一种多叉树,叶子节点才存放数据,非叶子节点只存放索引,而且每个节点里的数据是按主键顺序存放的。每一层父节点的索引值都会出现在下层子节点的索引值中,因此在叶子节点中,包括了所有的索引值信息,并且每一个叶子节点都有两个指针,分别指向下一个叶子节点和上一个叶子节点,形成一个双向链表。
主键索引的 B+Tree 如图所示:(图中叶子节点之间我画了单向链表,但是实际上是双向链表,原图我找不到了,修改不了,偷个懒我不重画了,大家脑补成双向链表就行):
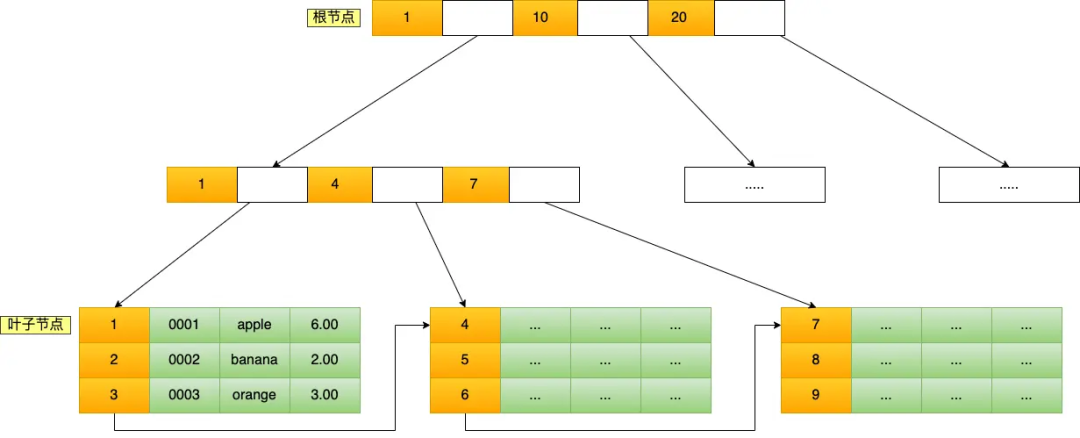
image.png
比如,我们执行了下面这条查询语句:
select * from product where id= 5;
这条语句使用了主键索引查询 id 号为 5 的商品。查询过程是这样的,B+Tree 会自顶向下逐层进行查找:
- 将 5 与根节点的索引数据 (1,10,20) 比较,5 在 1 和 10 之间,所以根据 B+Tree的搜索逻辑,找到第二层的索引数据 (1,4,7);
- 在第二层的索引数据 (1,4,7)中进行查找,因为 5 在 4 和 7 之间,所以找到第三层的索引数据(4,5,6);
- 在叶子节点的索引数据(4,5,6)中进行查找,然后我们找到了索引值为 5 的行数据。
数据库的索引和数据都是存储在硬盘的,我们可以把读取一个节点当作一次磁盘 I/O 操作。那么上面的整个查询过程一共经历了 3 个节点,也就是进行了 3 次 I/O 操作。
B+Tree 存储千万级的数据只需要 3-4 层高度就可以满足,这意味着从千万级的表查询目标数据最多需要 3-4 次磁盘 I/O,所以B+Tree 相比于 B 树和二叉树来说,最大的优势在于查询效率很高,因为即使在数据量很大的情况,查询一个数据的磁盘 I/O 依然维持在 3-4次。
为什么B+树做索引会比B树做索引好一点?
B 树和 B+ 都是通过多叉树的方式,会将树的高度变矮,所以这两个数据结构非常适合检索存于磁盘中的数据。但是 MySQL 默认的存储引擎 InnoDB 采用的是 B+ 作为索引的数据结构,原因有:
- B+ 树的非叶子节点不存放实际的记录数据,仅存放索引,因此数据量相同的情况下,相比存储即存索引又存记录的 B 树,B+树的非叶子节点可以存放更多的索引,因此 B+ 树可以比 B 树更「矮胖」,查询底层节点的磁盘 I/O次数会更少。
- B+ 树有大量的冗余节点(所有非叶子节点都是冗余索引),这些冗余索引让 B+ 树在插入、删除的效率都更高,比如删除根节点的时候,不会像 B 树那样会发生复杂的树的变化;
- B+ 树叶子节点之间用链表连接了起来,有利于范围查询,而 B 树要实现范围查询,因此只能通过树的遍历来完成范围查询,这会涉及多个节点的磁盘 I/O 操作,范围查询效率不如 B+ 树。
那数据库中新增一条数据,索引会有哪些变化?
InnoDB 创建主键索引默认为聚簇索引,数据被存放在了 B+Tree 的叶子节点上。也就是说,同一个叶子节点内的各个数据是按主键顺序存放的,因此,每当有一条新的数据插入时,数据库会根据主键将其插入到对应的叶子节点中。
如果我们使用自增主键,那么每次插入的新数据就会按顺序添加到当前索引节点的位置,不需要移动已有的数据,当页面写满,就会自动开辟一个新页面。因为每次插入一条新记录,都是追加操作,不需要重新移动数据,因此这种插入数据的方法效率非常高。
如果我们使用非自增主键,由于每次插入主键的索引值都是随机的,因此每次插入新的数据时,就可能会插入到现有数据页中间的某个位置,这将不得不移动其它数据来满足新数据的插入,甚至需要从一个页面复制数据到另外一个页面,我们通常将这种情况称为页分裂。页分裂还有可能会造成大量的内存碎片,导致索引结构不紧凑,从而影响查询效率。
举个例子,假设某个数据页中的数据是1、3、5、9,且数据页满了,现在准备插入一个数据7,则需要把数据页分割为两个数据页:
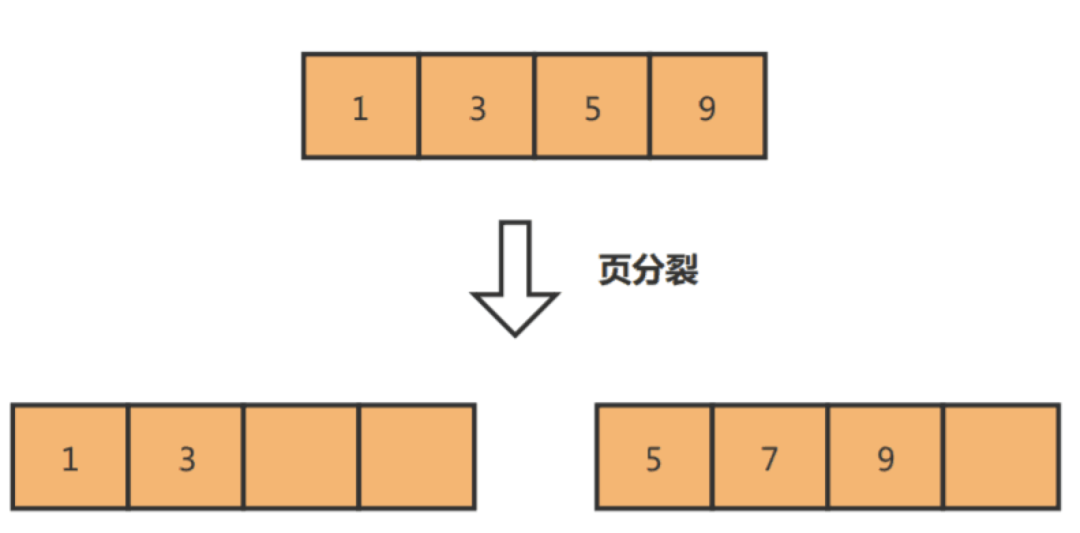
出现页分裂时,需要将一个页的记录移动到另外一个页,性能会受到影响,同时页空间的利用率下降,造成存储空间的浪费。而如果记录是顺序插入的,例如插入数据11,则只需开辟新的数据页,也就不会发生页分裂:
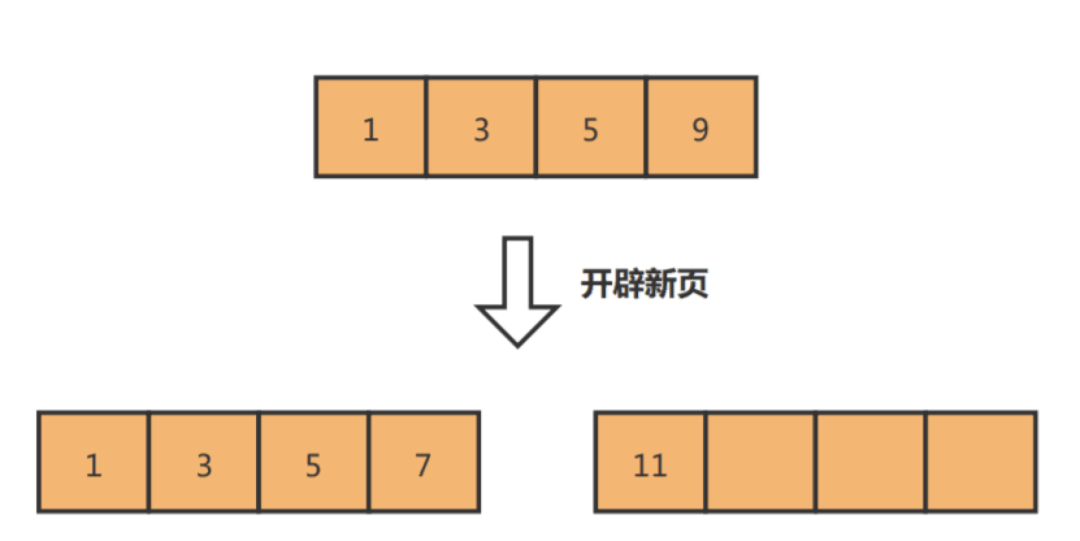
因此,在使用 InnoDB 存储引擎时,如果没有特别的业务需求,建议使用自增字段作为主键。
那如果当前对应节点满了怎么办?
会发生页分裂的问题,这个会影响性能,所以一般推荐主键索引要有递增的趋势的。
算法
算法:151.反转字符串中的单词
双端队列支持从队列头部插入的方法,因此我们可以沿着字符串一个一个单词处理,然后将单词压入队列的头部,再将队列转成字符串即可。
class Solution {
public String reverseWords(String s) {
int left = 0, right = s.length() - 1;
// 去掉字符串开头的空白字符
while (left <= right && s.charAt(left) == ' ') {
++left;
}
// 去掉字符串末尾的空白字符
while (left <= right && s.charAt(right) == ' ') {
--right;
}
Deque<String> d = new ArrayDeque<String>();
StringBuilder word = new StringBuilder();
while (left <= right) {
char c = s.charAt(left);
if ((word.length() != 0) && (c == ' ')) {
// 将单词 push 到队列的头部
d.offerFirst(word.toString());
word.setLength(0);
} else if (c != ' ') {
word.append(c);
}
++left;
}
d.offerFirst(word.toString());
return String.join(" ", d);
}
}
复杂度分析:时间复杂度:O(n),空间复杂度:O(n)