Python 卖空算法教程(三)

原文:
zh.annas-archive.org/md5/ceefdd89e585c59c20db6a7760dc11f1译者:飞龙 协议:CC BY-NC-SA 4.0
第十章:优化投资范围
市场参与者通常觉得市场的广大相当令人生畏。因此,在我们开始将我们在前几章中涵盖的想法转化为结合的投资策略之前,我们将专门撰写一个简短的章节,将市场简化为可管理的投资范围。
在本章中,我们将从一些概念性的盲点开始,讨论长/短期业务,试图为你将要进行交易的现实世界提供一些有价值的背景信息。接下来,我们将跟随资金的脚步,通过考虑一些重大事件和主题,揭示投资者真正想要的是什么,以及这些事件和主题如何塑造交易者和市场运作的方式。
我们将涵盖以下主题:
- 避免做空陷阱
- 投资者真正想要什么?
避免做空陷阱
这一部分主要讲述的是应用智能过滤器来避免经典做空陷阱。随着从业者对做空变得更加熟悉,他们可能会重新审视其中一些要点。这里的大多数要点都来自于痛苦的经历。
流动性和市场影响
流动性是熊市的货币。如果你在没有重大市场影响的情况下无法退出一个头寸,那么你什么都不拥有,它拥有你。处理做空方面的流动性方式是完全不同的。在做多方面,随着更多投资者被吸引到不断上涨的价格中,流动性增加。早期的鸟儿最终会将头寸出售给一个更大的市场参与者群体。
在做空方面,当投资者清算他们的头寸时,这是一条单行道。经历了一次打击后,他们不会再回来进行第二轮。没有什么比 Kübler-Ross 模型更能真实地捕捉到长期市场参与者的情感之旅了。市场参与者为他们的损失而悲伤。甚至每个阶段在市场上都有独特的标志。兴趣减弱,随着市场参与者的减少,流动性也减少。早期的熊市比后期的熊市更具流动性。做空者离场时的流动性要比他们进场时的更低。
加入做空陷阱,你就有了一种制造爆炸性鸡尾酒的配方。你最不希望的是被困在一个大头寸的做空陷阱中,而没有办法在没有严重市场影响的情况下进行套保。在做空方面,处理流动性和市场影响的方式不是关于建立头寸所需的时间有多长,而是关于退出的难易程度。
这将投资范围限制在流动性不是问题的问题上。2008 年金融危机的解决使市场上瘾于量化宽松,也就是所谓的免费资金。简而言之,货币当局向世界注入止痛药,以缓解经济危机的痛苦。一旦货币当局暗示要逐渐停止,市场就会在撤资中螺旋下降,交易者会涌向更安全、更防御性更强的股票,这被称为“避险”。这迫使货币骑兵继续向系统注入更多的止痛药,这使得各种投机资产深陷泡沫领域。当风险是“开放的”,交易者正在寻找风险更高、利润潜力更大的股票时,中小市值股票就是行动发生的地方。与此同时,在空头方面,无聊的蓝筹股已经过时。当失败没有责任时,就没有安全玩法的动机。当风险是“关闭的”,市场参与者更多地投资于防御性更强的大型资本化公司,流动性仍然充裕。恢复长期小市值/短期大市值交易并不容易。空头中小市值股票是一项血腥的运动。流动性蒸发了,您可以在买卖价差中停泊一个超大型油轮。因此,利润可能会在第一次挤压时被抹去。
底线:将您的净市场敞口与一般市场环境和流动性水平相匹配。无论某些想法看起来多么诱人,只保留那些流动性不是问题的想法。
拥挤的空头
“猫王已经离开大厦。”
早在 2007 年,我就开发了一种名为“挤压盒子”(WMSD)的大规模空头毁灭武器。机制可能有违直觉,但它具有超现实的准确率来预测潜在的空头挤压。所需的只是一个仅持有多头的经理来持有微小的投机性长头寸。由于买卖平衡已经失衡,这将推动价格上涨并将游客冲出。他们会疯狂地买回,这将迅速演变成一次空头挤压。此时,仅持有多头的经理将轻松地退出他们的多头寸,获得舒适的利润。当我意识到这个程序直接伤害到我在对冲基金界的朋友时,这个 WMSD 被永久拆除了。
故事的寓意:从您的投资范围中消除所有拥挤的空头,借入利用率超过 50%的问题。它们甚至不应该出现在您的雷达上。想想那些经常闯红灯的人。一切都很顺利,直到他们在医院醒来。
赚钱的方法在卖空方面是找到机构投资者正在清算的东西,并跟随他们。 好的卖空故事通常弥补了不好的卖空交易。 每一点信息都附有一个刻板的价格标签。 不要等待所有的拼图拼合在一起。 当一个故事恶化到足以成为明显的卖空候选人时,机构投资者将清算他们的多头头寸。 唯一剩下的人将是争夺干枯骨头的卖空者。 这将引导我们使用一个简单而强大的供求指标,称为借款利用率。
借款利用率是用于卖空的借入量与可借供应股票量之比。 大型机构拥有借贷计划,他们出借他们的长期持有部分以换取费用。 当他们削减这些头寸时,供应就会枯竭。
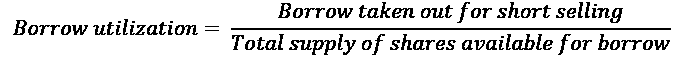
与此同时,随着卖空的流行,对借款的需求增加。 分子上的需求和分母上的供应是使借款利用率成为衡量机构所有权和流行度的最有效指标。 例如,借款利用率超过 50%仅意味着卖空欲望超过机构所有权。 由于机构是市场的主要参与者,风险/收益比显然会恶化。
根据公司的所有权结构,借款利用率可能会有很大的变化。 一些股东不参与借贷计划。 例如,持股密集的公司拥有很少的股东,这些股东由于不可言喻的原因经常无法欣赏到他们的宝贝成为恶意空头攻击的目标。
卖空是一项昂贵的运动。 卖空者要支付借款费用。 这些费用从普通担保(GC)的容易借入问题到难以借入或拥挤的空头问题的高利率都有。 随着借入逐渐减少,剩余池的质量会恶化。 更糟糕的是,难以借入的问题不仅仅可以获得高利率,使得莎士比亚的夏洛克都会脸红; 有时它们是可召回的。 这意味着出借人有权选择在短时间内撤回他们的借款。 这被称为“召回”。 当发生召回时,卖空者要么留在别处寻找借款,要么平仓。 召回有时会引发卖空压力。
最后一批做空游客往往过于兴奋,无暇考虑借入可召回的股票。一旦发生召回,他们无法定位借入,被迫平仓。由于卖出压力已经达到高潮,新的买入压力造成了供需失衡。股价轻松上涨。这触发了其他做空者止损,然后他们进行回补。这迅速演变成了一场全面的做空激励,不仅冲走了游客,也冲走了更有经验的做空者。底线是:远离其他做空者涉及低质量借入的问题。
拥挤的做空股票往往对市场的敏感性较低,比较热门的问题。当市场遭遇周期性的空当时,拥挤的做空几乎不动。与此同时,牛市中的高飞股票暴跌。相对而言,这意味着拥挤的做空表现优异,而做多则表现不佳。对于这种现象的一个可能解释是缺乏机构和零售投资者的参与。拥挤的做空中没有机构长期投资,因此当周期性回调发生时,没有人出售并推动股价下跌。底线:当拥挤的做空大幅下跌时,它们不会增强做多头寸。如果拥挤的做空者带来的唯一好处是满足昂贵的正确需要,那么这不是你应该采取的方法。
结论:就像节食者需要将冰淇淋和薯片远离手边一样,完全摒弃拥挤的做空股票。
高股息率的肥沃土壤
“他们说最好的武器是你从未必须开火的武器。我尊重地不同意。我更喜欢只需开火一次的武器。” – 托尼·斯塔克,《钢铁侠》
有时公司会增加其股息率以支撑股价。高股息率吸引了寻找更稳定现金流的价值投资者和零售投资者。这有效地阻止了做空者从事熊市活动。然而,尽管高股息率可能遏制了即时的做空压力,但它并不能阻止股价在长期内下跌。高股息率通常与停止增长的公司等同。它们已经停止增长,因此将现金重新分配给股东。这就是使高股息率股票领域成为盈利和平静做空的肥沃土壤的原因。
关于股息的好消息是它们是可预测的公司事件。有一些事件是做空者需要注意的。前两个是股权登记日和支付日。在这些时刻,做空者需要克制自己的热情。有时公司会决定在它们发布收益公告时提高股息。围绕这些日期安排交易,你会有一个惊喜的愉快时光。例如,投资者往往会在股息宣告日后立即减持。这加剧了进入股息支付日的下跌。
另一种将高收益股票重新定位为可行的做空候选者的方法是专注于导致股息一开始就很高的根本原因。成长型股票通常具有糟糕的股息收益率。它们需要现金来重新投资其业务。另一方面,稳定的成熟公司有多余的现金但长期前景不佳。少量的股息可以吸引投资者。
底线:价值陷阱隐藏在高股息之后。寻找高收益的表现不佳者,并在股息日期周围航行,你会发现时间过得惊人轻松。
股票回购
“一个人通常有两个做一件事的理由。一个听起来不错的,一个是真正的。” – 摩根大通
按照常规智慧,公司会在其股票被低估时在开放市场上回购股票。实际上,当涉及到时机不当的估值时,他们和卖方分析师一样毫无头绪。股票回购在 2007 年底达到峰值,2009 年 3 月触底。
支持股票回购的人认为,用他们的现金和廉价信贷来回购股票是没有比这更好的用途。这会产生涓涓细流的效应,惠及整个经济。
这种股东至上主义可以追溯到 80 年代由弗里德曼在 80 年代开创的一种思想流派。通过回购股票计划,公司已成为市场上越来越重要的参与者。前总统特朗普减税后的反弹主要是由公司回购自己的股票推动的。
对手们认为,现金从利益相关者(员工、客户、研发和供应商)那里被转移出来,然后转移到股东那里。简单地说,教练对球员斤斤计较,但对球迷慷慨解囊。大多数高管的薪酬来自股票期权。因此,他们有直接的激励来支持股价以填补他们的股票期权计划。最有效的方法是回购股票。这降低了流动性,膨胀了每股收益,并推高了股价。
2020 年的冠状病毒大流行粗暴地揭示了这种虚伪,并最终解决了争论。股票回购抽干了公司的生命力。这种对短期市场影响的过度关注与公司的长期利益不一致。当世界陷入封锁时,公司几乎立即发现自己资不抵债。他们的股价暴跌,但他们仍然不得不面对为回购而签订的贷款义务。在资本主义的历史上,皇帝从未如此茫然地四处游荡,赤裸裸地出现。
但是,对于卖空者来说,这并不是重点。公司的资金实力足以人为提升股价。因此,卖空者应避免对参与股票回购计划的公司进行卖空。好消息是,股票回购与市场波动高度相关。股票回购在最需要的时候,即在修正期间会消失。这意味着卖空季节已经开始并进入全面发展阶段。
底线:不要直接做空推出股票回购的公司。让它们自我腐蚀,并等待必然的脆弱性。
基本分析
“时间在我这边。” – 米克·贾格
基本分析为股市分析赋予了贵族的头衔。很少有事业像股票分析那样具有智力刺激性。市场体制的定义可以极大地简化基本分析的工作。
当基本分析师考虑市场体制时,他们实际上试图回答一个理论性问题。他们试图弄清楚为什么一支股票应该下跌,以及为什么现在应该发生这种情况。有很多原因。
他们最终可能会得到伸张正义。然而,他们承担了巨大的时间、声誉和最终业务风险。他们希望市场在投资者失去耐心之前同意他们的论点。期望获得一致的结果是不现实的,因为有太多的随机变量。
另一方面,将基本分析置于市场体制之下试图回答一个实际问题:为什么这支股票下跌?好消息是,答案通常可以归结为以下三个方面之一:
- 首先,这可能是暂时的错定价格。市场可能已经从牛市转向横盘。在一个活跃的牛市阶段之后,股票往往会暂停并消化进展。这个阶段被称为整理。股票可能有一段时间不涨不跌。如果是这样,解决方案很简单。待命的空头头寸看起来在经历了大幅度的回调之后会好很多。减持你的头寸。将资本重新配置到新的想法上。如果股票重新开始表现,将有充裕的时间重新建仓。
- 其次,如果一个行业内的几只股票开始齐头并进地表现不佳,这表明行业轮动。这减轻了分析师的工作负担:选择几乎任何一个表现不佳的行业的股票。
- 第三,如果一只股票的行为与其行业不符,这可能表明存在一些股票特定的问题。这是基本分析师大展身手的时候。这是发现真正有利可图的结构性空头的时候。价值陷阱经常被忽视,因为它们具有价值股票的所有外部特征。它们经常有慷慨的股息政策。相对于同行,估值打了折扣,这使它们在表面上看起来很有吸引力。然而,它们顽固地表现不佳。它们之所以便宜并且保持便宜是有原因的。基本分析师的工作是找出原因。
在卖空方面,传统的基本分析很难进行。信息的不对称是卖空者必须应对的问题。公司很少自愿公布坏消息。分析师保持他们的“买入”评级,直到命运的那一天,他们碰巧在媒体上读到公司前一天晚上申请破产的消息。
卖方拉拉队可能会有一些不情愿的边际效用。在误导性的“买入”评级的多年冻土草原上,低表现的暗号是“为长期投资者购买”。寻找评级不更新、收益模型积满灰尘的股票,甚至连维护研究都没有得到适当的维护。只需一个电话确认“那些是长期投资者的股票”,你就可以开展业务。
投资者真正想要什么?
长/短行业似乎每次市场“出现疲软迹象”时都会经历严重的存在危机。投资者被粗鲁地提醒,下行保护仅意味着几乎没有上行的有限下行。该行业一直是从“建立它们就会来”的产品供应模式运作的。如果目标是建立可持续的业务,那么是时候暂停一下,从投资者的角度审视世界了。这将为建立符合投资者需求的长/短产品提供至关重要的背景。
从 2007 年量化灾难中得到的教训
“于是,由沙子建造的城堡, 融入海洋, 最终。 —— 吉米·亨德里克斯
2007 年 8 月,横截面波动性让全球市场大吃一惊。虽然指数波动不大,但成分股在几天内纷纷跃升。很快,关于各种量化市场中性基金解除交易的传言开始传播。这标志着量化 1.0 的终结。
那些聪明的市场中性基金就像威尼斯比萨饼一样:菜单上有 37 种不同的名称,但每个人的面团都是一样的。它们的模型相当相似。由于它们是市场中性的,来自卖空的现金收益可以用来几乎无限地进行杠杆。一些基金将杠杆倍增到七倍,以放大原本乏味的回报。一段时间以来,一切都运作良好。所有基金经理所需要做的就是继续卖空更多股票,以匹配不断扩张的多头。这一切都进行得很顺利,直到 2007 年夏天,房地产泡沫开始腐烂。
每场雪崩都是由一个雪球开始的。那时,在市场的另一个角落,一些大型多策略交易公司被要求为他们的信用违约义务(CDO)和信用违约掉期(CDS)组合提供更多的抵押品。当他们无法为信贷账本筹集现金时,他们被迫清算他们最流动的资产类别。他们转向他们的量化市场中性账本。这是最初的雪球。在夏季中旬,流动性通常会枯竭。他们的空头账本不流动。当第一个商店开始平仓时,他们抬高了价格。这触发了他们邻居的止损。他们继续关闭自己的头寸。这引发了连锁反应,最终导致了混乱的横截面市场。这就是传染的定义。
人们有时会就什么构成良好质量而争论,但他们很少在糟糕的东西上产生分歧。每个人都发现自己处于同一糟糕境地。由于可用于卖空的股票有限,交易变得非常拥挤。多策略基金的清算加剧了问题。管理者最终意识到,解除空头头寸需要数周时间,他们开始将头寸减少到可控水平。流动性是主要风险。几乎所有人都在大致相同的模型下同时得出了相同的结论。匆忙平仓的精英量化交易员堪比金融版的大象在瓷器店里乱窜。
那时,市场中性基金被宣传为安全的投资工具:股票回报与低波动性。在许多人心中,市场中性意味着资本保护。因此,当一些基金在看似平静的市场上发布-3-4%的月度回报时,发生了两件事。首先,由于风险价值(VAR)增加,主要经纪商提高了保证金要求,迫使基金减少杠杆。其次,投资者让基金经理们苦恼不已:“救赎之歌”。
这些赎回迫使管理者关闭头寸,给基金增加了更多的波动性。减少了杠杆,增加了波动性,并且不断增加的赎回,将需要数月,甚至数年的时间来弥补损失。而且,声誉损失是不可挽回的。对于量化市场中性基金 1.0 来说,游戏已经结束。
这场崩溃始于一个简单的错误:那些基金的设计者犯了一个致命的假设,即空头将会与多头一致。有一段时间,确实如此。但随着基金规模的扩大,空头的独特动态回来困扰着他们。流动性枯竭了。空头变得拥挤。等到管理者意识到空头风险呈指数增长时,已经为时太晚了。
故事的寓意:如果你想经营一个可持续的多空业务,你需要从空头开始构建你的投资组合。
有关这个主题的更多信息,请参阅 Lehman Brothers 的 Matthew S. Rothman 博士于 2007 年 8 月 9 日撰写的《量化领域的动荡时期》。
接下来的两部分将进一步关注投资者真正想要的是什么。他们不是将资金放在复杂的长/空中,以购买低技术的交易所交易基金(ETF)所能做到的同样的苹果公司(AAPL)股票,后者成本只有一小部分。投资者希望低波动性的回报与市场波动不相关。
长/空行业的绿黄蜂综合症
“真实存在的比应该存在的更重要。太多人从应该是的角度看待真实存在。” – 布鲁斯·李,伟大的华裔美国哲学家
1966 年的电视系列剧《绿黄蜂》以布雷特·里德为特色,他白天是《每日哨兵报》的雄心勃勃的出版商,晚上则是作战的绿黄蜂,而他的忠实男仆卡托则是忠诚的。如果不是因为一位名叫布鲁斯·李的未知演员扮演的副手管家,那个很快被遗忘的节目永远不会进入那些神秘系列的世界。
长/空行业患有未解决的绿黄蜂综合症。许多长/空参与者是披着狼皮的羊。机敏灵活的对冲基金经理喜欢吹嘘自己在多头方面选择股票的优越分析能力。谁在乎呢?没有人需要对冲基金经理繁琐的“复杂性”来购买苹果公司。任何“无聊”的纯多头基金经理都将以较低的成本提供完全相同的服务。更好的是,任何低技术、低成本的普通香草 ETF 都会比任何主动管理者在时间上做得更好。
长/空市场参与者真正进入神话般的基金经理的阵容的是他们在其他人都不赚钱时赚钱的能力。这来自于被称为空头账簿的副手。
长/空行业是一个竞争激烈的领域。市场参与者知道他们必须立即开始吸引投资者。因此,他们默认在自己的舒适区内交易。他们大部分时间都在选择多头方面的股票。与此同时,对空头的无尽挫折使他们放弃了学习“黑暗艺术”的细节。尽管最初的意图是最好的,但空头账簿逐渐被边缘化为一种次要表演。
随着市场上涨,这种情况就会持续下去。一旦市场陷入“软墙”,被忽视的空头方无法弥补多头方的损失。当业绩出现突然下滑时,投资者会感到窒息。他们不得不忍受过高的费用,并容忍“alpha 挑战”式的回报。难怪当他们意识到下行保护实际上意味着损失少于市场时,他们会感到窒息。因此,长/空行业受到越来越多的愤世嫉俗的对待,也就不足为奇了。
从伯尼·麦道夫那里学到的教训
“当你看到我多次欺骗骗子和傻瓜而没有丝毫良心负担时,你会感到很有趣。” – 贾科莫·卡萨诺瓦
每个市场参与者都有一些能产生阿尔法收益的“秘密武器”。他们相应地推出适合自己投资风格的产品。他们奉行“建造它,他们就会来”的模式,相信仅靠阿尔法收益就足以吸引投资者。很快,他们就会想知道为什么其他具有平稳回报的参与者在激烈的资产管理竞争中超越了表现出色的市场巫师。
作为一种资产类别,系统性商品交易顾问(CTAs)几十年来一直主导着表现赛道。然而,根据朋友和畅销书作者迈克尔·科维尔的说法,他们的总资产管理规模占全球资产管理总规模的 0.4%。尽管长期表现优异,但他们的总资产管理规模仍然是一个可以忽略的数字。这让基金经理感到困惑。一方面,投资者们公开表示他们在寻找回报。另一方面,当到了付诸实践的时候,他们选择了其他的东西。好消息是金钱留下了痕迹。
在赞扬马多夫先生的营销才华之前,让我们搞清楚一件事。任何欺诈投资者的白领罪犯都应该在监狱里待上几十年。伯纳德·L·马多夫是私人部门小联盟中最伟大的骗子之一。几十年来,他欺骗了成千上万的投资者数十亿美元。他的故事为投资者的心态提供了宝贵的见解。
马多夫所提供的东西是如此强大,以至于它削弱了金融业一些最复杂的参与者的专业怀疑。在一次难得的监狱采访中,马多夫先生承认投资者“本应该知道更多”。下面是马多夫所谓的回报表:
标准普尔 500 指数 | 费尔菲尔德信托公司(马多夫) | |
|---|---|---|
年平均回报 | 7.7% | 11.0% |
复合回报 | 201.0% | 504.0% |
正收益月份 | 63.0% | 92.0% |
最大回撤 | -46.3% | -1.6% |
回撤持续时间(月) | 80 | 2 |
半相关 | 0.03 |
平均每年 11.04%的表现还算不错,但并非惊人。正如之前提到的,投资者们声称他们想要回报,但他们对回撤作出了反应。马多夫与众不同的地方在于有四点:
- 首先,回撤的持续时间:绝不能考验投资者的耐心。从零售投资者到机构资产配置者,每个投资者脑海中都有一个挥之不去的问题:“现在投资还来得及吗?”只有当贪婪或错过机会的恐惧比害怕赔钱更强烈时,他们才会把自己辛苦挣来的积蓄投入使用。在实践中,高峰时期的资金流入往往与牛市的顶峰相一致。那些订阅了“道指涨至 36,000 点”骗局并在 2000 年 8 月冒险投资的幼稚者,在他们在 2007 年 5 月收回资金之前,不得不忍受 80 个连续月的回撤。那正好是下一次暴跌的时间。相比之下,麦道夫先生总是营业。他只有连续两个月的回撤。每个月都是进入市场的好时机。这样短的回撤持续时间在统计学上是不太可能的。唯一接近的市场参与者是传奇人物爱德华·索普,讽刺的是他在丑闻爆发前 14 年就揭露了麦道夫。
- 第二是回撤的幅度:绝不能考验投资者的胃口。一旦陷入回撤,投资者会担心情况会变得有多糟糕。市场长期平均回报率可能为 7%,方便地忽略了其中的-40-50%的巨大回撤。即使正回报并不惊人,-1.56%的最大回撤使其看起来像是一种无风险投资。康尼曼-特沃斯基以更加精彩的方式制定了他们的前景理论:厌恶损失比追求利润更为强大。这说明了一个强大的概念:“你赚多少钱并不重要,只要你不亏损。”投资者可以设定并忘记。
- 第三是回撤的频率:绝不能考验投资者的神经。据说麦道夫的表现有 92%的时间是赚钱的,而标普指数只有 63%。标普指数有 6 年的年度回报率超过 20%。它也有 4 年的负双位数回报率。相比之下,麦道夫的欺诈平均回报率是 11.04%。然而,标普指数的复合回报率是 200%,而麦道夫的是 500%。
- 第四是半相关性(与标普指数下跌月份的相关性),或者在下跌市场中赚钱的能力。据称,麦道夫的半相关性是 3%,即每当市场下跌时他都能赚钱。这就敲定了交易。在所有人都跌倒时仍然屹立不倒的经理们脱颖而出。他们的电话响个不停,有意向的投资者络绎不绝。
在现实世界中,像麦道夫那样获得回报是统计学上不太可能的。然而,你越接近,你的提议就越具有吸引力。如果你成功地建立了一个介于麦道夫的圣杯和指数被动投资之间的产品,你将比竞争对手更具竞争力。
总结
这个简短的章节并不意味着要考验读者的脑细胞。它只是一个关于如何避免经典昂贵陷阱并满足投资者期望的实用提示集合。投资者不是为了长期想法而购买多空产品。他们想要低波动性的不相关回报。这一章考虑了投资者的期望,同时避免了将空头书籍视为更有趣的多头书籍的陷阱。如果将那些问题股票从你的视野中清除,它们就不会在你的脑海中出现,这将消除诱惑。
一旦你压缩了你的投资领域并了解了投资者对你的期望,就是时候扣动扳机了。在接下来的章节中,我们将把所有的东西整合起来,看看如何在实践中做到这一点。
第十一章:多空工具箱
仅多头投资组合从定义上来说与市场相关。引入空头组件使得管理者能够设计他们想要实现的绩效类型。我们将在本章中使多空投资组合管理对所有专注的市场参与者都可达。
创建一个多空投资组合需要合并两个相对组合:一个多头和一个空头。从仅多头或绝对多空转向相对强度多空投资组合一开始可能会让人感到不安。有许多动态因素。管理这种转变的有效方法是从目标出发:流动性、相关性、波动性和绩效。然后,专注于几个对这些目标影响最大的变量:总曝光和净曝光、净 beta 和浓度,它们构成了您在构建策略时的投资工具箱。
以下表格指示了这些变量中的每一个对我们的目标产生的影响。
流动性 | 相关性 | 波动性 | 表现 | |
|---|---|---|---|---|
总曝光 | ||||
净曝光 | ||||
净 beta | ||||
浓度 |
最后,我们实践我们所写下的。是时候进行一些有纪律的创造了,为您构建自己的投资策略提供逐步指南。在这个过程中,我们将涵盖以下主题:
- 导入库
- 总曝光:杠杆的战术性方法
- 净曝光:标题性的看涨/看跌方向性
- 净 beta:对市场的剩余敏感性
- 浓度:每一边的股票数量
- 其他曝光
- 设计您自己的授权
让我们从总曝光开始。这是您愿意承担的杠杆量。杠杆是一把强大的双刃剑。如果不正确使用,它会创造然后毁灭一个企业。
您可以通过以下链接访问本章所有图片的彩色版本:static.packt-cdn.com/downloads/9781801815192_ColorImages.pdf。您也可以通过该书的 GitHub 存储库访问本章的源代码:github.com/PacktPublishing/Algorithmic-Short-Selling-with-Python-Published-by-Packt。
导入库
对于本章和本书的其余部分,我们将使用 pandas、numpy、yfinance 和 matplotlib 库。因此,请记得首先导入它们:
# Import Libraries
import pandas as pd
import numpy as np
import yfinance as yf
%matplotlib inline
import matplotlib.pyplot as plt 总曝光
总敞口是多头和空头头寸的绝对总和。卖空股票会产生现金,可以用于进入更多的多头头寸。理论上,杠杆可以无限增加。实际上,主要经纪人限制杠杆为 3 或 4 倍,以限制他们的交易对手风险。没有人希望在市场出现迹象时立即处理保证金调用。
总敞口对以下方面直接产生影响:
- 流动性:杠杆越高,持仓规模越大。这直接影响市场影响力。这在卖空方面尤为明显,就像 2007 年的量化交易员所证实的那样。
- 波动性:杠杆放大了回报的波动性。
- 绩效:杠杆放大了回报:低杠杆下微不足道的 0.1%可以增加到 0.5%等等。
- 集中度:如果目标是保持波动率低,那么名字的数量应该与杠杆成比例地增加:总敞口增加意味着更多的名字,反之亦然。
总敞口最终反映了市场参与者对市场的信心。他们越自信,就越倾向于增加杠杆以抓住机会。在科技泡沫中,没有什么比增长型经理更像是糖果店里的孩子。相反,在动荡或不确定时期,市场参与者倾向于减少总敞口并增加现金敞口以保护资本。战略性地管理总敞口可以是在好时机提高绩效和在困难市场保护资本的强大工具。
市场参与者倾向于以以下两种方式管理总敞口。他们要么坚持固定的敞口水平,要么采取非结构化的方法。固定敞口的参与者在整个周期内保持相同水平的总敞口。保持固定总敞口水平的理由是简单性。参与者喜欢将名字数量保持在一个可以安全管理的水平上。在好时期他们可能会损失一些收益,但在连续亏损期间,他们可以将回撤保持在可控水平。另一方面,非结构化的参与者在好时期变得乐观,增加头寸,而在坏时期则囤积现金。
如果你的目标是以相对较低的波动率提供有吸引力的回报,可能会有一种更科学的方法。在接下来的章节中,我们将考虑一种简单、有效、分步骤的管理总敞口的方法。这个想法是允许总敞口跟随你的绩效周期。这被称为管理投资组合热度。
投资组合热度
在第二部分,外部游戏:制定稳健的交易边缘中,我们在进入交易之前讨论了头寸规模和风险管理。当我们已经投资并且市场意外地出现不愉快的转变时会发生什么?市场是生活的一个很好的反映。这就是当我们有其他计划时发生的事情。
我们既不能预测也不能控制世界上发生的事情。那些仍然相信自己可以预测任何事情的人肯定不应该负责管理养老基金。然而,我们可以通过以下两种方式控制投资组合中发生的事情:
- 首先,我们可以通过头寸大小控制投资组合中的风险量。在进入头寸之前,我们完全控制着将分配给下一笔交易的风险量。
- 其次,我们可以控制投资组合中所容忍的风险量。这些是现有的头寸。一些工作,一些不工作。一些脆弱。一些仍然处于风险之中。一些是无风险的。
这引出了开放风险、投资组合热度和相关性的概念:
- 开放风险是股票级别的潜在损耗。如果触发了止损,该头寸将以亏损还是盈利的方式关闭?如果是盈利的话,开放风险就是零。在金融业术语中,该头寸被称为自由携带。不管接下来发生什么,交易都不会亏钱。
- 投资组合热度是所有头寸上的开放风险的总和。开放风险是按方向和策略汇总的。例如,假设您进行了两种长/短策略交易:一种是均值回归,一种是趋势跟随。分别汇总这四个开放风险和资产曲线。在这种情况下,开放风险和最大潜在回撤是两码事。开放风险中的投资组合热度仅处理脆弱头寸。自由携带头寸受到一套不同的规则的约束。
- 相关性是长期书籍与短期书籍在总体上的运动方式。当市场下跌时,短期书籍并不总是带头。例如,长期股票的投机性问题下降得比低β股票更快更远。关键是假设“相关性趋于 1”,意味着一切都像板砖一样下跌。长期和短期投资组合的热度并不会互相抵消。理论上,人们会认为短期投资组合会弥补长期投资组合的下跌。实际上,在市场回调期间,做空有时会胜过做多。惊慌的动量买家抛售他们的长期持仓,从而导致价格下跌。因此,不要抵消长期和短期投资组合的热度。
投资组合热度需要保持在范围内。接下来,让我们看一下设定热度范围的几个一般原则。
投资组合热度范围
如果你承担了太多的风险,总有一天你就不会有生意可做。如果你没有承担足够的风险,你根本就不会有生意可做。因此,秘诀在于保持风险在范围内。
最大热度带应该定义如下。目标不是在全面减少总体敞口。目标是在头寸级别减少开放风险,这将导致总体敞口的收缩。股票具有不同的波动性特征。低波动性股票需要更大的头寸。例如,在防御性股票上减少风险与在高波动性股票上减少风险的影响大相径庭。这个系统比实际总体敞口带更有效。市场参与者应该牢记投资组合热度的上限。
存在一个理性的最大风险数字,可以确保资产曲线的最佳几何增长率。很好,但完全无关紧要。重要的是你的客户可以容忍多少风险。例如,如果客户表示可以接受 10%的回撤,那么您的可接受最大投资组合热度应该在 5%左右。总的来说,人们,尤其是客户,都极大地高估了他们对痛苦的耐受能力。此外,纠正局势需要时间和精力。上限实际上是一个业务决策。波动性是风险的副产品——在投资组合层面容忍的风险越多,投资组合中引入的波动性就越多。这将限制您能够针对的客户类型。例如,养老基金是厌恶波动性的。它将决定从数量到绩效和信息比率的一切。
当有疑问时,应该慎重行事。一个经典的解决方案是增加名称的数量,例如。此外,正如我们将在战术部署部分看到的那样,投资者是按照日历年来思考的。因此,您的上限容忍度根据是年初还是年底接近而变化。一切相等,风险应该从小开始,逐渐增加,在第三季度达到顶峰,到年底逐渐减少。将惊喜留给圣诞礼物,而不是给您的投资者的钱。
最小值可以这样定义。长/短经理最终根据其保护资本的能力进行评判。您的系统必须能够通过回撤交易。一个简单的经验法则是将最小值设定为最大值的一半。如果您预计投资者会在 10%的回撤时赎回您的份额,那么您的最大值应该约为 5%,最小值为 2.5%。
最坏的情况是,在重新回到原点之前,您可能会遭受 7.5%的回撤。此外,一旦绩效好转,第八章中介绍的凸性振荡器,头寸规模:资金管理模块中的金钱赚钱,将重新加速。
即使投资组合热量的差异看起来很小,对总风险敞口的影响可能看起来更加戏剧化。投资组合热量的+/-0.1%的差异很容易使总风险敞口产生 5-10%的变动。这将直接影响波动性、绩效和流动性,如市场影响所示。在实践中,这项技能有一些魔力。投资者将会看到纪律性的风险管理,这最终是他们愿意付出好钱的技能。
战术部署
牛市可能持续数年,但投资者倾向于以季度和年度时间段思考。如果投资者以日历年为单位思考,那么你也应该如此。因此,杠杆应该在整年战略性地部署。如果你在年初杠杆被搞得很高,而绩效一开始就大幅下滑,那么你将在余下的时间里不断地摆脱困境,而投资者则紧盯着你。压力对于做出良好的决策是不利的。另一方面,一旦你建立了绩效,就会有余地来运用杠杆。所以,每年都从最小杠杆开始。一年可能会开始缓慢。投资者会忘记一个缓慢的开始,但他们不会原谅一个艰难的开始。
相反,随着年末的临近,逐渐减少杠杆以在下一个周期开始时达到最小杠杆。投资组合热量的季节性管理在数学上没有意义。投资者很少在抽象数学中竞争诺贝尔奖。他们是人类。他们用直觉反应。
逐步投资组合热量和敞口管理
在第八章,仓位大小:在资金管理模块中赚钱中,我们使用股票曲线来计算应该分配给进入投资组合的交易的风险有多少。这是在个人层面上的每笔交易的风险。现在,我们将重新审视已经在投资组合中的位置的凸面振荡器。在进入之前的微观层面(每笔交易的风险)的关系在投资组合宏观层面(投资组合热量)上仍然成立。市场不断变化,因此风险应相应调整。每笔交易的风险在股票级别上在最大和最小范围内振荡。类似地,投资组合热量在最大和最小值之间振荡。这种方法的美妙之处在于其简洁的优雅。我们不专注于头寸的大小,只关注它们的未平仓风险。这迅速减少了杠杆,同时保持了成功的无风险头寸不受影响。
实施凸面振荡器对最大投资组合热量的影响直接影响所有风险敞口。让我们用一些逐步的数字示例来说明这一点。
第一步:凸度配置
股票/微观级别有效的东西在投资组合/宏观级别也有效。整体投资组合风险称为开放风险或投资组合热量。目标是尽可能长时间地以最大热度运行。随着回撤加剧,投资组合热量逐渐降低直至最低水平。此风险可以使用我们在第八章,头寸规模:金钱在资金管理模块中赚取中看到的risk_appetite()函数来降低:
def risk_appetite(eqty, tolerance, mn, mx, span, shape):
'''
eqty: equity curve series
tolerance: tolerance for drawdown (<0)
mn: min risk
mx: max risk
span: exponential moving average to smoothe the risk_appetite
shape: convex (>45 deg diagonal) = 1, concave (<diagonal) = -1, else: simple risk_appetite
'''
# drawdown rebased
eqty = pd.Series(eqty)
watermark = eqty.expanding().max() # all-time-high peak equity
drawdown = eqty / watermark - 1 # drawdown from peak
ddr = 1 - np.minimum(drawdown / tolerance,1) # drawdown rebased to tolerance from 0 to 1
avg_ddr = ddr.ewm(span = span).mean() # span rebased drawdown
# Shape of the curve
if shape == 1: #
_power = mx/mn # convex
elif shape == -1 :
_power = mn/mx # concave
else:
_power = 1 # raw, straight line
ddr_power = avg_ddr ** _power # ddr
# mn + adjusted delta
risk_appetite = mn + (mx - mn) * ddr_power
return risk_appetite 在下面的示例中,我们将构建一个由 10 支股票组成的虚构投资组合—5 支多头,5 支空头。我们将演示如何在个股水平进行投资组合热量降低。
步骤 2:回撤重新调整
我们的假想投资组合以标普 500 指数为基准。初始资本(K)设定为 100 万美元。贝塔(对市场的敏感性)已从 Yahoo Finance 网站中提取。股票数量和相对止损已校准为相对风险调整至投资组合的-0.50%。该投资组合运行时间从 2020 年 12 月 31 日到 2021 年 6 月 30 日。首先,我们将生成数据集:
port = np.nan
K = 1000000
lot = 100
port_tickers = ['QCOM','TSLA','NFLX','DIS','PG', 'MMM','IBM','BRK-B','UPS','F']
bm_ticker= '^GSPC'
tickers_list = [bm_ticker] + port_tickers
df_data= {
'Beta':[1.34,2,0.75,1.2,0.41,0.95,1.23,0.9,1.05,1.15],
'Shares':[-1900,-100,-400,-800,-5500,1600,1800,2800,1100,20800],
'rSL':[42.75,231,156,54.2,37.5,42.75,29.97,59.97,39.97,2.10]
}
port = pd.DataFrame(df_data,index=port_tickers)
port['Side'] = np.sign(port['Shares'])
start_dt = '2021-01-01'
end_dt = '2021-07-01'
price_df = round( yf.download(tickers= tickers_list,start= '2021-01-01' , end = '2021-07-01', interval = "1d",group_by = 'column',auto_adjust = True, prepost = True, treads = True, proxy = None)['Close'],2)
bm_cost = price_df[bm_ticker][0]
bm_price = price_df[bm_ticker][-1]
port['rCost'] = round(price_df.iloc[0,:].div(bm_cost) *1000,2)
port['rPrice'] = round(price_df.iloc[-1,:].div(bm_price) *1000,2)
port['Cost'] = price_df.iloc[0,:]
port['Price'] = price_df.iloc[-1,:]
print(port) 这里没有什么大秘密。我们使用字典和列表创建数据帧。然后我们从 Yahoo Finance 下载价格。成本设定为 2020 年 12 月 31 日,当前价格为 6 月底。在撰写本文时,这产生了以下数据帧。
贝塔 | 股票 | rSL | 方向 | rCost | rPrice | 成本 | 价格 | |
|---|---|---|---|---|---|---|---|---|
QCOM | 1.34 | -1900 | 42.75 | -1 | 40.16 | 33.26 | 150.85 | 142.93 |
TSLA | 2.00 | -100 | 231.00 | -1 | 187.87 | 158.16 | 705.67 | 679.70 |
NFLX | 0.75 | -400 | 156.00 | -1 | 143.96 | 122.91 | 540.73 | 528.21 |
DIS | 1.20 | -800 | 54.20 | -1 | 48.24 | 40.90 | 181.18 | 175.77 |
PG | 0.41 | -5500 | 37.50 | -1 | 36.59 | 31.40 | 137.43 | 134.93 |
MMM | 0.95 | 1600 | 42.75 | 1 | 45.82 | 46.22 | 172.10 | 198.63 |
IBM | 1.23 | 1800 | 29.97 | 1 | 32.71 | 34.11 | 122.85 | 146.59 |
BRK-B | 0.90 | 2800 | 59.97 | 1 | 61.73 | 64.67 | 231.87 | 277.92 |
UPS | 1.05 | 1100 | 39.97 | 1 | 44.34 | 48.39 | 166.54 | 207.97 |
F | 1.15 | 20800 | 2.10 | 1 | 2.34 | 3.46 | 8.79 | 14.86 |
与第四章,长/空头方法论:绝对和相对中介绍的relative()函数有一个小区别,后者有重新调整到系列开始的选项。我们选择使用连续系列。市场参与者一直在围绕头寸交易。重新调整很快变成了不必要的计算难题。因此,使用相同日期收盘价乘以一个常数—在本例中为 1000 是有意义的。止损和所有计算都基于相对系列。
接下来,让我们计算几个重要的指标:
- BV 代表账面价值。这是以基金货币(美元)计算的成本乘以所有开放头寸的股票数量。
- MV 代表市值。这是调整为货币(美元)的股票数量乘以当前收盘价。
- rMV 代表相对市值。
- 毛暴露是基金货币中所有市值的绝对总和,除以管理资产—在本例中为 K。
- 净暴露是所有市值的算术净总和,除以市值的绝对总和。
- 净 Beta 是市值乘以 Beta 的总和乘以市值的绝对总和。
现在让我们看一下代码:
BV = port['Shares'] * port['Cost']
MV = port['Shares'] * port['Price']
rMV = port['Shares'] * port['rPrice']
port['rR'] = (port['rCost'] - port['rSL'])
port['Weight'] = round(MV.div(abs(MV).sum()),3)
port['rRisk'] = -round(np.maximum(0,(port['rR'] * port['Shares'])/K),4)
port['rRAR'] = round( (port['rPrice'] - port['rCost'])/port['rR'],1)
port['rCTR'] = round(port['Shares'] * (port['rPrice']-port['rCost'])/ K,4)
port['CTR'] = round(port['Shares'] * (port['Price']-port['Cost'])/ K,4)
port_long = port[port['Side']>0]
port_short = port[port['Side']<0]
concentration = (port_long['Side'].count()-port_short['Side'].count())/port['Side'].count()
gross = round(abs(MV).sum() / K,3)
net = round(MV.sum()/abs(MV).sum(),3)
net_Beta = round((MV* port['Beta']).sum()/abs(MV).sum(),2)
print('Gross Exposure',gross,'Net Exposure',net,'Net Beta',net_Beta,'concentration',concentration)
rnet = round(rMV.sum()/abs(rMV).sum(),3)
rnet_Beta = round((rMV* port['Beta']).sum()/abs(rMV).sum(),2)
print('rGross Exposure',gross,'rNet Exposure',rnet,'rNet Beta',rnet_Beta) 输出将类似于以下内容:
Gross Exposure 3.327 Net Exposure 0.141 Net Beta 0.24 concentration 0.0
rGross Exposure 3.327 rNet Exposure 0.141 rNet Beta 0.24 3.327 的毛暴露是中度到高杠杆。毛暴露为 2 意味着资产管理 (AUM) 在多头和空头方面各杠杆一次。3.327 意味着 AUM 大约杠杆了 1.6 次。净和 r 净暴露为 0.141 意味着投资组合平衡均匀且轻微看涨。净和 r 净 Beta 为 0.24 意味着投资组合在残余上是看涨的。它不容易受到任何重大冲击。
总体而言,除了高度集中和持续性开放风险外,投资组合看起来很平衡。接下来,我们计算风险:
- R 是由 Van Tharp 博士在他的书籍《交易自由之路》中推广的一种度量方法。它简单地是成本与止损之间的差异。在这里,我们将使用相对版本的 R,或者 rR。
- 权重是基金货币(USD)中的市值,除以市值的绝对总和。
- r 风险是对权益的加权相对风险。该公式包含一个神秘的
np.maximum(0, (port['rR'] * port['Shares']))序列。一旦止损被重置超出当前止损,这将变为负数。这确保了开放风险保持为负。 - rRAR 是以初始相对风险单位表示的相对收益。这是最真实和最简单的风险调整收益指标。这将是我们的主要工具。
- rCTR 和 CTR 是相对和绝对贡献,或者是盈利与权益的比值。
接下来,让我们按方向和相对风险调整后的收益打印投资组合。
port[['Side', 'Weight', 'rRisk', 'rRAR', 'rCTR', 'CTR']].sort_values(by=['Side','rRAR'] ) 方向 | 权重 | r 风险 | rRAR | rCTR | CTR | |
|---|---|---|---|---|---|---|
TSLA | -1 | -0.020 | -0.0043 | 0.7 | 0.0030 | 0.0026 |
DIS | -1 | -0.042 | -0.0048 | 1.2 | 0.0059 | 0.0043 |
NFLX | -1 | -0.063 | -0.0048 | 1.7 | 0.0084 | 0.0050 |
QCOM | -1 | -0.082 | -0.0049 | 2.7 | 0.0131 | 0.0150 |
PG | -1 | -0.223 | -0.0050 | 5.7 | 0.0285 | 0.0138 |
MMM | 1 | 0.095 | -0.0049 | 0.1 | 0.0006 | 0.0424 |
IBM | 1 | 0.079 | -0.0049 | 0.5 | 0.0025 | 0.0427 |
UPS | 1 | 0.069 | -0.0048 | 0.9 | 0.0045 | 0.0456 |
BRK-B | 1 | 0.234 | -0.0049 | 1.7 | 0.0082 | 0.1289 |
F | 1 | 0.093 | -0.0050 | 4.7 | 0.0233 | 0.1263 |
仓位按方向和相对风险调整后的收益整齐排序。让我们使用 groupby() 方法应用于多头和空头账簿来查看汇总。
port[['Side', 'Weight', 'rRisk', 'rRAR', 'rCTR', 'CTR']].groupby('Side').sum() 这将产生以下表格:
权重 | r 风险 | rRAR | rCTR | CTR | |
|---|---|---|---|---|---|
方向 | |||||
-1 | -0.43 | -0.0238 | 12.0 | 0.0589 | 0.0407 |
1 | 0.57 | -0.0245 | 7.9 | 0.0391 | 0.3859 |
这给我们带来了侧面的大量总数。两侧表现良好。预期之中,净暴露已经扩大。空头已经缩小。这种错位是健康的空头的标志。多头也增加了。总的相对风险大约为-4.8%,分布在 10 个名称中。接下来,让我们削减对表现最慢的股票的敞口。
步骤 3:按比例分配开放风险
总风险暴露为 333%,开放风险为+13.9%,净 beta 为 0.24。让我们来看一个经典案例。管理层高层中的某人在管理罕见的大气层中暂停了纸牌游戏,并决定全面减少敞口。在执行交易员的英语中,这意味着削减杠杆。在整个投资组合中削减头寸大小没有标准的配方。市场参与者可以使用几种方法。这些方法从全面减少所有头寸到在最脆弱的头寸中进行外科手术般地削减边际风险。由于任何人都可以执行前者,让我们探讨如何以最小的努力完成后者。
假设性地,我们的目标是将开放风险从-4.8%降低到-2.8%。由于开放风险均匀分布,我们将在每一侧削减 1%的风险。该代码适用于分离的风险降低,但这将保持简单。逻辑是通过使用相对风险(rRisk)作为排序键来减少大小:port_long['rRisk'] / (port_long['rRisk'].sum(). 风险越高,削减越大,依此类推。
adjust_long = adjust_short = -0.01
pro_rata_long = port_long['rRisk'] / (port_long['rRisk'].sum() * port_long['rRAR'])
risk_adj_long = (abs(adjust_long) * pro_rata_long * K / port_long['rR'] // lot) * lot
shares_adj_long = np.minimum(risk_adj_long, port_long['Shares'])*np.sign(adjust_long)
pro_rata_short = port_short['rRisk'] / (port_short['rRisk'].sum() * port_short['rRAR'])
risk_adj_short = (abs(adjust_short) * pro_rata_short * K / port_short['rR'] // lot)*lot
shares_adj_short = np.maximum(risk_adj_short,port_short['Shares'])*np.sign(adjust_short)
port['Qty_adj'] = shares_adj_short.append(shares_adj_long)
port['Shares_adj'] = port['Shares'] + port['Qty_adj']
port['rRisk_adj'] = -round(np.maximum(0,(port['rR'] * port['Shares_adj'])/K),4)
MV_adj= port['Shares_adj'] * port['Price']
rMV_adj = port['Shares_adj'] * port['rPrice']
port['Weight_adj'] = round(MV_adj.div(abs(MV_adj).sum()),3)
print(port[['Side','rRAR','rRisk','rRisk_adj','Shares','Qty_adj', 'Shares_adj', 'Weight','Weight_adj']].groupby('Side').sum()) 首先要做的逻辑事情是先减少处于风险中的头寸。那些是最容易受到攻击的。带有止损超出成本的头寸可以暂时放过,直到所谓的通风系统面临困境。当止损超出成本时,开放风险为zero. np.maximum(0, (port['rR'] * port['Shares']))是粗糙的,但它有效。在我们的示例中,止损未被重置,所有头寸神奇地都有贡献。正如格劳乔·马克思曾经说过的:“除非老板提早离开,否则没有人会过早离开。”因此,我们仍然需要削减敞口。
我们将按侧面比例分配开放风险,并除以风险调整收益。这将根据侧面和开放风险调整收益对头寸进行排名。那些贡献最少的头寸从定义上来说是最危险的。
让我们考虑一下这段代码是如何工作的:
- 我们将-1%的风险降低因子纳入按比例分配中以计算股份数。我们乘以资本并除以成本和止损之间的相对距离
rR,以获得确切的股份数。我们找到了模数(//)与手数相乘,以达到一个整数。 - 风险降低不能大于现有股份数。在多头方面,我们取股份数或调整的最小值。在空头方面,我们取股份数或调整的最大值。
- 我们添加一个新的列,
Qty_adj,在其中我们附加要调整的股份。我们使用['Shares_adj'] = port['Shares'] + port['Qty_adj']来计算新的股份。 - 我们进行与之前相同的计算,以查看削减如何影响投资组合。我们打印出数据框。
这会产生一个聚合表,应该类似于以下内容(取决于您运行代码时股票的表现如何):
rRAR | rRisk | rRisk_adj | Shares | Qty_adj | Shares_adj | Weight | Weight_adj | |
|---|---|---|---|---|---|---|---|---|
Side | ||||||||
-1 | 10.8 | -0.0251 | -0.0164 | -8700 | 1300.0 | -7400.0 | -0.430 | -0.511 |
1 | 7.9 | -0.0245 | -0.0127 | 28100 | -5800.0 | 22300.0 | 0.571 | 0.490 |
多头方面的回报是一致的,因此需要大幅削减风险。
请注意,空头方面的调整风险尚未达到目标。正如我们将在下文看到的,表现出现了很大的差异,一些头寸几乎没有受到影响,而另一些头寸大幅减少。现在,这个示例只有少数头寸。这种不均匀的减少可能会发生。
print(port[['Side','rRAR','rRisk','rRisk_adj','Shares','Qty_adj', 'Shares_adj', 'Weight','Weight_adj']].sort_values(by=['Side','rRisk_adj' ], ascending=[True,False])) 扩展视图会得到类似以下内容的东西。
Side | rRAR | rRisk | rRisk_adj | Shares | Qty_adj | Shares_adj | Weight | Weight_adj | |
|---|---|---|---|---|---|---|---|---|---|
TSLA | -1 | 0.7 | -0.0043 | -0.0000 | -100 | 100.0 | 0.0 | -0.020 | 0.000 |
DIS | -1 | 1.2 | -0.0048 | -0.0030 | -800 | 300.0 | -500.0 | -0.042 | -0.039 |
NFLX | -1 | 1.7 | -0.0048 | -0.0036 | -400 | 100.0 | -300.0 | -0.064 | -0.071 |
QCOM | -1 | 2.7 | -0.0049 | -0.0041 | -1900 | 300.0 | -1600.0 | -0.082 | -0.102 |
PG | -1 | 4.5 | -0.0063 | -0.0057 | -5500 | 500.0 | -5000.0 | -0.222 | -0.299 |
MMM | 1 | 0.1 | -0.0049 | -0.0000 | 1600 | -1600.0 | 0.0 | 0.096 | 0.000 |
IBM | 1 | 0.5 | -0.0049 | -0.0011 | 1800 | -1400.0 | 400.0 | 0.079 | 0.026 |
UPS | 1 | 0.9 | -0.0048 | -0.0031 | 1100 | -400.0 | 700.0 | 0.069 | 0.065 |
BRK-B | 1 | 1.7 | -0.0049 | -0.0039 | 2800 | -600.0 | 2200.0 | 0.234 | 0.273 |
F | 1 | 4.7 | -0.0050 | -0.0046 | 20800 | -1800.0 | 19000.0 | 0.093 | 0.126 |
这与之前完全相同,尽管使用了两个不同的排序键。我们最初按照rRAR风险调整回报进行排序。现在,我们改为按rRisk_adj进行排序。那些没有贡献但仍然存在开放风险的头寸被减少了。在这一关键时刻,从这项练习中有两个重要的收获。
- 在这个练习中,权重被减少了。它也可以增加。它可以在一边增加,在另一边减少。
- 诚然,这是一项单调乏味的练习,没有特定的目标。然而,它有一个更加性感的绰号。一旦你打了个哈欠,带着你已经见过的胚胎资产配置方法的知识回顾一遍吧。
接下来,让我们看看这个-2%的风险减少如何影响所有主要变量:
print('Gross Exposure',gross,'Net Exposure',net,'Net Beta',net_Beta,'concentration',concentration)
gross_adj = round(abs(MV_adj).sum() / K,3)
net_adj = round(MV_adj.sum()/abs(MV_adj).sum(),3)
net_Beta_adj = round((MV_adj* port['Beta']).sum()/abs(MV_adj).sum(),2)
net_pos_adj = port.loc[port['Shares_adj'] >0,'Shares_adj'].count()-port.loc[port['Shares_adj'] <0,'Shares_adj'].count()
print('Gross Exposure_adj',gross_adj,'Net Exposure_adj',net_adj,
'Net Beta_adj',net_Beta_adj,'concentration adj',net_pos_adj)
rnet_adj = round(rMV_adj.sum()/abs(rMV_adj).sum(),3)
rnet_Beta_adj = round((rMV_adj* port['Beta']).sum()/abs(rMV_adj).sum(),2)
print('Gross Exposure_adj',gross_adj,'rNet Exposure_adj',rnet_adj,'rNet Beta_adj',rnet_Beta_adj) 我们的输出如下,还添加了一些有用的评论:
# Before risk reduction
Gross Exposure 3.327 Net Exposure 0.141 Net Beta 0.24 concentration 0.0
# After risk reduction: absolute
Gross Exposure_adj 2.243 Net Exposure_adj -0.021 Net Beta_adj 0.13 concentration adj 0
# After risk reduction: relative
Gross Exposure_adj 2.243 rNet Exposure_adj -0.021 rNet Beta_adj 0.13 仅仅将开放风险减少了 2%就将总暴露降低到了 3.327 至 2.243。净暴露从+0.141 变为-0.021。净贝塔从 0.24 降至 0.13。尽管净暴露基本中性,但调整后的投资组合仍然保持着多头。
在这种情况下,绝对和相对总数巧合地具有相同的值。正如你所见,只需稍微减少总暴露,就可以大幅减少总暴露,同时保持最健康的头寸。这是一个强大的练习,可以快速重新分配投资组合或策略的资源。
净暴露
净暴露是做多和做空头寸之间的百分比差异。净暴露是对市场方向性观点的近似反映:当为正时,看涨;为负时,看跌。净暴露对以下方面有直接影响:
- 流动性 是最常被忽视但又至关重要的组成部分之一。做多和做空头寸具有相反的动态。为了保持净暴露低,做空头寸需要不断补充。与此同时,借贷的供应是有限的。这导致借贷成本增加。始终注意借贷利用率。不要让它超过约 66%。
- 相关性:净暴露越低,相关性越低。例如,共同基金的相关性为 1,意味着它们模仿市场的波动。市场上涨,共同基金也上涨,反之亦然。
- 波动性:净暴露对波动性的影响最大。净暴露越低,波动性越低。然而,以零净暴露为目标具有自身的系统风险。它在稳定的市场中表现良好,但在主要市场转变时可能极为痛苦,如牛市到熊市。
- 绩效:净暴露越低,市场方向性对收益的影响就越小。
- 收益率:做空者需要承担股息。低净暴露意味着做多端收到的股息被做空端支付的股息抵消了。这对做空端的股票选择产生了影响:高股息率的股票在做空端往往被低估。
在做多/做空业务中,每个人都熟悉净暴露的概念。认真对待他们的做多/做空任务的人会倾向于较低的暴露度,而机会主义者则更自由地摆动。因此,平均净暴露是重新分类做多/做空市场参与者的一种快速而粗略的方法。以下是一些参与者可能落入的广泛分类:
- 超过+50%:这些是收取对冲基金费用的特殊情况的做多型基金。它们提供的不仅仅是下跌保护。它们不试图通过空头仓位对冲下跌。它们对空头头寸有着个别股票的看法。
- 超过+30%:这些市场参与者通常被称为定向对冲基金。这是多空俱乐部中相对不太复杂的一群。他们通常是资产聚合者,假装知道他们在空头方面在做什么,但他们在想法产生部门往往遇到困难。他们的特点是高相关性,有限的上行参与度和零下行保护。他们是对冲基金的寿司传送带。当一个失败时,下一个色彩鲜艳的就会出现。
- 净暴露度在-20%到+20%之间:最严肃的多空玩家在这个空间中运作。他们已经意识到,敞口控制和风险管理才是生意的关键。这种低净暴露度提供了低波动回报,但仍然受益于有限的市场定向性。
- 净暴露度在-10%到+10%之间 是市场中性基金的领域。Alpha 严格来自股票选择和仓位规模。只有少数策略可以适应这种暴露水平。请记住,低净暴露度并不等同于低风险。这些基金的风险通常在尾部。难以始终限制敞口。这通常会以某些因素为代价。可以把它想象成是在重新收紧一根弹簧。在某些时候,被压抑的能量可能会释放出来并造成损害。
多空车辆应该在下行市场中表现出色,或者至少保护资本。在全球金融危机(GFC)期间,它们没有做到铁打的营盘流水的效果。虽然它们在牛市中超过+50%甚至更多,但净敞口度很难降至+20%以下。尽管经理们可能宣称他们是熊市,但数字讲述了不同的故事。基金保持谨慎,但并非完全悲观。在+20%的净暴露度下,也许戴着拳击手套而不是赤手空拳,但仍然是同样的打击。
净暴露度可能是一个具有欺骗性的指标。低净暴露度不一定意味着低相关性。大多数市场参与者会采取几种手段来降低其净暴露度。最经典的技术是加大他们的少数空头赌注。集中度增加了波动性。另一种减少净暴露度的技术是卖出期货,其 beta 低于单个股票。这两种技术对相关性和波动性都有实质性影响。但是,净暴露度对于投资组合管理就像市盈率对于估值一样。这是一个足够好的快捷方式,但不应成为决策的唯一依据。最好将净暴露度与其他变量放在上下文中。因此,重要的是要超越净暴露度的头条数字,并通过净 beta 查看投资组合的构成。
净 beta
2005 年初,日本股市经历了一个史诗般的年份。感觉这一次不同。当日本当局决定逮捕乐天(JT:4753)的 CEO 兼新日本象征堀江财团时,派对戛然而止。高飞的小市值股票重新发现了牛顿物理学。
我们看好高飞的小市值股票,其业务模式奥妙,以及做空几个气喘吁吁的“结构性做空”以及指数期货。基金经理迅速对危机做出回应,通过卖出期货。尽管净头寸合理为+30%,但船正在迅速进水。作为自命不凡的风险管理者,我迅速提醒他,我们在贝塔、市值、交易所和流动性方面都有合成暴露。随着多头方面的小市值股票在 1.7 及以上,空头方面的令人痛苦的股票在 0.8,以及期货在空头方面为 1,我们的净贝塔值在 0.7 左右徘徊。正如一位投资者后来指出的那样,我们在上涨过程中的贝塔值为 1.5,在下跌过程中为 3。
贝塔是相对多空业务的核心概念。贝塔是对市场的敏感性。如果市场回报1,贝塔为 1.5 的股票将回报1.5。在数学术语中,这是股票收益与基准的斜率。净贝塔是调整后的多头和空头头寸之间的差异,以十进制值表示。它超越了净头寸的表面,以反映投资组合的基本方向敏感性。当风险存在且市场情绪良好时,高贝塔股票往往表现良好。市场奖励冒险者去冒更高风险的股票。流动性是任何市场的主要风险。因此,小市值股票的贝塔值高于大市值股票。高贝塔股票还是存在显着失败风险的行业,如科技或生物技术,或者存在资产负债表风险的金融行业。对对冲基金行业的批评者经常将对冲基金描述为贝塔交易商,或伪装成阿尔法的贝塔。批评者是正确的。相对多空投资组合在定义上是对贝塔的套利。同样,画家是一个把颜料抛向空白画布的人。
在牛市中,多头头寸的贝塔值将高于 1。空头头寸将由回报低于市场的股票组成,或者贝塔值低于 1。这可能导致净头寸在+20%左右,但净贝塔值牢固地在+0.5。表面上,净头寸可能看起来很低,但对市场的剩余敏感性可能会增加。在熊市中,多头头寸将由食品和公用事业等防御性股票构成,其贝塔值传统上低于 1。空头头寸将列出前一阶段所有领头的股票,它们正在排出它们的狂喜。这将导致净头寸在+5 至+20%之间,而净贝塔值在-0.1 至-0.5 之间。悲观的投资组合在多头方面拥有防御性股票,在空头方面拥有市场敏感性股票。
尽管净头寸暴露出的乐观态度明显,但负净 beta 表明了一种悲观的立场。在熊市中产生的负净头寸将产生 alpha,但会出现剧烈的波动。净 beta 是工具箱的一个重要组成部分。市场参与者本能地理解 beta 如何运作。稍加约束可以大幅提高平滑绩效。
接下来,让我们看看短期期货交易能带来什么。
卖出期货是做空的“垃圾食品”的三个原因
为了重申前一节中的声明,相对长/短期投资组合是对行业 beta 进行套利的。那些未能理解这一关键区别的不成熟市场参与者经常会卖出期货来减少其净头寸,而忽视了对净 beta 的影响。以下是卖出期货不是有效套期保值的三个原因。
卖出期货是对市值的一种押注
市场参与者经常会对做空端观点的稀缺性作出回应,通过卖出指数期货。
在多头方面,市场参与者喜欢通过寻找中小市值股票来展示他们的选股能力。这才是有趣和黄金机会所在。中小市值股票在牛市中的涨幅比蓝筹股更大。它们相对而言受到卖方分析师社区的覆盖较少。更容易接触到高管。找到几只涨了三倍或四倍的股票,一个新的选股传奇就诞生了。
与此同时,期货反映了指数的前几大市值。这使得做多中小市值股票/做空期货交易成为对市值的一种隐含押注。中小市值股票在牛市中表现优于大盘股,但在熊市中,市场对小型投机股票的态度并不那么友好。
卖出期货是对 beta 的一种押注
期货的 beta 值为 1。中小市值股票对市场的敏感性更高。它们是牛市中的跑马机,但在熊市中表现糟糕。当市场暴跌时,中小市值股票的跌幅比大型、沉闷的蓝筹股更快。在牛市中,做多中小市值股票/做空期货市场会拖累绩效,但在动荡的市场中不提供下跌保护。
对 beta 进行套期保值的唯一方法是采取深度净做空方法。
由于通过期货“套期保值”的市场参与者不太可能在首次进行做空操作时感到舒适,因此他们可能在牛市和熊市中始终保持净 beta 正值,或者通过做多股市获得收益。具有讽刺意味的是,对股票卖出期货在市场基准上实现超额收益。只有在该资产类别预计会在市场上实现超额收益时,这种策略才有效。对这种策略的不太光彩的描述称为beta 驯马手。
卖出期货是一种昂贵的懒惰形式
许多机构投资者已经通过期权和期货对互惠基金中的风险进行了对冲。他们已经有了对冲他们的多头注资的复杂性。他们不需要额外支付一群游客 2%和 20%的费用来做他们自己能做的事情。归根结底,卖出期货表明了不负责任的业余精神,这是投资者自全球金融危机以来已经敏锐意识到的事情。
如果你曾经想知道为什么即使在熊市阶段,尽管净暴露度低,你的业绩仍然不佳,净 beta 可能是罪魁祸首。如果目标是提供低相关性回报,那么较低的净 beta 就是起点。
集中度
集中度是指投资组合中的股票数量。净集中度是多头头寸减去空头头寸的差额,可以用总头寸的百分比或绝对值表示。
集中度直接影响:
- 流动性:建立和清算头寸会对市场产生影响。
- 波动性:如果目标是提供低波动性回报,那么集中度就是起点。名字的数量越多,波动性就越低。
- 表现:大规模的集中投注能够取得巨大成功。小额投注能够积累收益。
集中度通常被认为是一种投资风格的属性,因此没有得到应有的关注。这有点像大蒜——一种美味的调味品,在初次约会时不建议使用,但也是一种抗癌的超级食物和吸血鬼驱赶剂。
一些市场参与者认为,实现卓越表现的关键是在几个高信心大投注中取得成功。这可能是一种成功的策略,但这不是重点。表现最佳的产品不是最畅销的产品。跑车吸引的客户有限。
当涉及到资产配置时,投资者将大部分资产分配给低波动性的投资策略。他们出于一个简单的原因交易回报以换取稳定性。机构需要与明确的负债(如养老金支出)匹配合理可预测的资产。然后,他们将用较高波动性产品的小额分配提高回报。所以,对于任何经理来说,真正的问题是:你要针对哪一笔资金?你想游泳在低波动性产品的奥运规模的游泳池中,还是在可支配的赌博资金的小型游泳池中?
接下来,我们将挑战一些关于集中度的老生常谈。
人类的局限性
市场参与者经常认为,他们能够管理的股票数量存在自然的人类限制。超过一定数量的头寸,一切都变得模糊。他们跟不上信息流并做出及时决策。
这是一个投资组合管理系统问题。数据没有以一种有助于经理做出交易决策的方式结构化和可视化。我们将在第十三章,投资组合管理系统中讨论这个问题。
保值不是令牌
一些市场参与者进行少数大赌注,并保留一长串探索性的小仓位,称为对冲。一些奇特的对冲包括对商品的敏感性:中国、黄金、利率等。这些仓位通常太小,无法在个体基础上实质性地对冲风险,但总体上很重要。因此,它们是示范性的例子,允许市场参与者说他们已经对冲了他们的投资组合,抵御了外部风险。
长尾策略是小中市值长/短领域的经典。再次强调,这是一个投资组合管理系统问题,而不是风险管理策略。
低波动收益的悖论:结构性的负净集中度
可持续吸引和留住投资者的方法是在短侧比长侧结构性地拥有更多的名称,或者净负集中度。投资组合上通常长侧的名称比短侧多。当面对短侧想法的稀缺性时,市场参与者会倾向于放大其空头赌注以降低净暴露。他们最终通过称其超大头寸为“高信心空头”、“结构性空头”或“策略性空头”来合理化这些决定。
问题在于大量集中的赌注增加了波动性。由于空头一方的波动性极高,这导致了整个投资组合的波动性。现在,投资者希望波动性低。降低波动性的唯一方法是减少短侧的集中度。这意味着更小的赌注和更多样化的名称。正如我们在第五章中所看到的制度定义,这在相对长/短期投资组合中是可行的,但在绝对长/短期投资组合中要实现这一点要困难得多。空头一方需要比多头一方结构性地拥有更多的名称来补偿波动性。
关于集中度的实用提示
集中是三个变量的函数:平均名称数量、大赌注与小赌注的比率和交易成本。
平均名称数量
一个健康的投资组合在每一侧应该有 30 到 60 个名称。没有任何一个头寸过大以至于能够摧毁业绩,但足够大以在实质上做出贡献。此外,头寸数量仍然是可以管理的。
大赌注与小赌注的比率
第二个因素是大赌注与小赌注的比率。Fidelity 波士顿的一项内部研究测量了管理人员投资组合中最大头寸与最小头寸的比率、超额收益以及最终资产管理规模的保留情况。结果是一清二楚的:
- 大赌注与小赌注的比率越高,波动性越高。大量集中的赌注推动业绩,但缺点是收益波动率升高。这是投资者的一个巨大障碍。他们喜欢收益,但无法向老板证明波动性。
- 持仓管理比率低于 2.5 的经理与大赌注差距较大的经理相比,跟踪误差显著较低。他们的最大赌注不会大到足以推动其整个投资组合的波动性。低跟踪误差与资产管理规模的稳定性相关。用执行交易员的话说,这意味着当事情顺利时,你会被称为“股票选手”,但当你的风格不受青睐时,你会被归类为高跟踪误差风险。这相当于机构投资者的“没有人因为买 AAPL 而被解雇”。
大赢家将在买方扩大,在卖方收缩。在买方,赢家不应该使整个投资组合变得微不足道。相反,在卖方,它们不应该被允许消失。
维持一个健康、动态的投资组合的一个简单方法是追踪前 10 项的总权重与后 10 项的总权重之比。比率越高,集中度越高,因此波动性越大。将这个比率保持在 3 以下可以确保投资组合中既没有过大的赌注,也没有过小的仓位。
保持你的粉末干燥
最后,这是一个简单而强大的来自卖方的小贴士:拒绝小仓位。这在卖方是普遍存在的。在买方,即使是 0.50%的小赌注也可以变成强大的仓位。回到 1997 年 8 月,比尔·盖茨以 12 美元的价格购买了一家名为 AAPL 的垂死的便士股票的 200 万美元股权。然而,在卖方,成功的交易会缩水。即使一只股票下跌了 10%,-0.50%的初始赌注也只会回报+0.05%。加上交易成本和滑点,剩下的钱勉强够喝咖啡和吃可颂了。在卖方,保持干粉直到有机会。市场参与者经常因为害怕卖空而害怕。他们会采取太小以至于无法伤害但也太微不足道以至于无法做出贡献的仓位。因此,首先要做好风险管理,然后执行你的策略。这是一些与说这句话的绝地大师一样古老的建议:“要么做,要么不做,没有尝试。”
其他暴露
一些市场参与者喜欢追踪其他对冲,比如行业或部门风险,或者交易所和因子风险。
行业暴露
保持多元化的行业暴露是一个良好的做法。通常情况下,你不希望你整个长/短期部门的暴露看起来像是 1999 年技术长,2000 年技术短的情况。一些市场参与者喜欢完全对冲他们的行业暴露以减轻行业风险。这引入了另一层不必要的复杂性。在实践中,整个行业主导或落后于市场。一个例子是:在 2008 年,很难找到任何金融部门的股票属于买方。
只有在成对交易或套利策略中才适用行业中性。同一行业中的所有股票并不以相同的速度行进。行业中性引入了一个有趣的资本配置问题:应该反映底层行业的市值还是成分之间的差异?前一种分配将 passively 沿着广泛市场移动。行业的市值和暴露将被匹配。它会看起来是低风险的,但不能保证有吸引人的回报。相反,高的同一行业差异提供了更多捕捉阿尔法的机会,但偏离了行业市值。
只有在获胜者和失败者之间的同一行业差异明确定义时,行业中性才能产生阿尔法。科技行业是一个很好的例子,例如,看好 Facebook/空头 Twitter。
交易所曝光
谁提出“理性投资者”概念的人显然从未在狂欢的牛市中踏上交易大厅。获胜效应正在全力进行。睾丸酮在冷静,理性,自私的经济代理人身上疯狂地泵动,又被称为“股票投机者”。昨天高度投机的问题被封为“新的投资范式”。后向理性化唱着同样的老调: “这一次不同!”
这样的暴发户问题很少在古老的主要交易所上找到。它们在美国的纳斯达克,日本的 JASDAQ,韩国的 KOSDAQ 等上市。
在牛市期间,一个经典的策略是看好投机股票,空头蓝筹股。然而,这是单向行进的。反之效果不是那么好。看好蓝筹股并空头投机是一种难以在实践中执行的策略。在超过最大市值之后,借贷变得困难,流动性蒸发,买卖价差巨大。
流动性是熊市的货币。当市场动荡时,应坚持交易所主流的流动性资产。
因素曝光
2007 年量化基金的灾难清楚地证明了空头方面有着自己的动态,并且值得有其特有的因素。我们都会因为学者们的聪明才智而从进一步研究空头交易中受益良多。但是,由于关于最佳投资组合构建的讨论似乎在 70 年前现代投资组合理论(MPT)的前披头士时代达到了一个“永久性高原”,学者们没有太大的动力提出适用于空头方面的因素。
理论上,因素是有意义的。在回测的临床环境中,因素也表现良好。然而,在实践中,空头方面并非是分子烹饪的练习。AMZN 不是一系列因素。它是一家公司,一支股票和一个故事。
管理多头/空头投资组合比传统的仅多头投资组合更具创造力。它也会引发复杂性。因此,坐下来从头开始设计投资组合管理指南是明智而有趣的。我们将在本章的剩余部分进行介绍。
设计你自己的授权
“人们会按照他们写下的去生活,” – 罗伯特·西奥迪尼
金融是时尚行业中唯一一部分,去年的款式仍然畅销。资金毫不费力地流向去年的佼佼者。每个人或多或少都在做着同样的事情:基本面分析、公司访问、收益模型、技术分析。很难提出一个与众不同的理念。如果你想在潜在客户心中留下持久的印象,向他们展示他们很少看到的东西:一个经过记录的流程。他们可能选择今天不投资,但他们会记住你。
投资者喜欢将经理人归类。他们已经有了一定数量的类别。如果你不适合任何一个类别,他们可能不会为你新建一个,除非表现迫使他们这么做。因此,让他们的工作变得容易:告诉他们哪个类别最适合你。对外界而言,你的授权是你的身份。你越是完善它,你在投资者眼中就显得越可信。你将不再是 “下一个 [在此处插入最新的幸运股票选手的名字…]”,吹嘘自己的出色股票选择能力。你将成为一个有远见并有过程可依的人。没有什么比一个审慎的资金管理者更具吸引力,他能理解风险并进行计算的押注。
很少有市场参与者花时间明确规范其流程。坚持计划的最有效方法是将其写下来并对自己负责。如果你的目标没有明确规范,一切都将停留在空想中。以下是一种逐步方法,将帮助你澄清你的流程。首先,我们将从信号模块开始。其次,我们将进行头寸大小确定。第三,我们将添加敞口和风险管理。最后,我们将考虑你的目标。我们将用一系列问题探讨每个主题。
请准备好笔记本和你的交易日志。
第一步:策略规范化
“Persona 是拉丁文,意为演员戴的面具。” – 约瑟夫·坎贝尔
从你的策略概要开始。用 2-3 句话写下你的电梯演讲。这是你要求投资者将你放入的框架。如果你现在没有一个明确的想法也不要担心。当你完成这个过程时,这个框架会显露出来。
三分之二的车祸后住院的人仍然会自认为是高于平均水平的司机。我们认为我们是谁,我们内心深处的批评者对我们喊叫的是谁,我们公开声称自己是谁,以及我们做什么,都生活在一个同步的平行多元宇宙中。
我们不会走传统的成长对价值,基本面对量化,等等的路线。这不是一次营销行动。你不是在试图筹集资金。我们试图恢复你的个人所有方面的内在对齐。我们将会将你的策略形式化到可以被编程的地步。
信号模块
将你的表现与你操作的基准进行比较。你擅长哪些市场?更重要的是,你不擅长哪些市场?它们是向上趋势,向下趋势还是横向趋势?它们是否波动?你是在市场之前还是之后达到高峰?你是在市场之前还是之后复苏?你的表现是比市场更快还是更慢下跌和恢复?
计算短期滚动夏普比率,或者韧性指数。关注于它下跌和恢复的时刻。我们的目标是让你在连败时期变得坚韧。对于以下一组问题,请参考你的交易日志或者交易记录。不要将非标准行为标记为好或者坏。
列出按策略的所有入场类型,包括机会主义交易:
- 你的季度和年度滚动交易边缘分别是多少?下次有人问起你的交易边缘时,这些数字应该信手拈来。此外,这将听起来比对你独特的分析能力的模糊论文更加令人印象深刻。
- 你每一方的经典入场信号是什么?走得比一般的想法再远一步。翻阅你的交易日志。是什么在过去 50 次交易中导致你在每个仓位上那个特定时间动手的?如果你没有一个具体的原因,也写下来。
- 你多久进行一次机会主义交易?有时我们会从自动驾驶模式切换到手动模式。我们都会遇到不遵守我们标准规则的机会主义交易。例如,可能会出现一些坏消息导致股票暴跌。机会主义交易在投资组合中有一席之地。然而,当它们频繁或者占比重时,就会对结构和纪律产生合理的担忧。神圣的行业术语是“风格漂移”,这应该是一个主要的警告信号。
- 当你的策略不起作用时,你的交易频率会发生什么变化?你会交易更多还是更少?例如,是否会在完全停止交易之前经历虚假的正信号?比较连败开始时和结束时的入场数量。可能存在一些交易疲劳。你会放弃信号,因为你相信它们再次会是虚假的正信号。
- 你会分批进入吗?两边都是吗?你会进行多少次入场?回顾你的交易日志,并明确规则是什么促使你动手。是否有特殊情况?有交易你选择不分批进入的吗?
- 在符合入场标准的情况下,你放弃了哪些交易?不交易也是一种投资决策。从不进入的决定来看我们的交易选择,为你对系统的信任提供了有价值的视角。导致你拒绝这些信号的背景是什么?
- 如果你经常放弃交易,开始记录那些被拒绝的交易。还注意为什么拒绝它们的原因。
接下来,专注于你的退出,认真审视镜子里的自己:
- 你的止损规则是什么?在过去的 50 次交易中,你违反了止损规则多少次?在触发止损前是否关闭交易?规则是什么?你有多少次以百分比点数的形式覆盖了规则?
- 你使用移动止损吗?规则是什么?你的移动止损规则是否根据连胜/连败而变化。
- 你如何重设止损?
- 你会逐步减仓吗(减少头寸)?
- 你有时间退出策略吗?多少个周期?是否也适用于嵌入 P&L 的老头寸?你是否拖延时间退出?
- 你的有利退出策略是什么?在过去的 50 次交易中,你偏离了多少次?
- 在双方都有的情况下,你的滚动假阳性率是多少?如有疑问,请使用你的击球率。专注于回撤。在连续亏损期间,你是否扩大或缩小止损?
- 你会反向交易吗:从做多转为做空,反之亦然?
- 交易的模式是:亏损还是盈利?你是趋势跟随者,还是使用均值回归策略?
你真的做了功课还是仅仅是智力上回答了问题?好吧,然后回答这个:说出三个你的行动与你的信念不符的领域。在过去的 50 次交易中,最大连续止损次数是多少?与基准的相关性是多少?如果市场在接下来的 6 个月内保持横向,转为熊市或转为牛市会发生什么?一年中有多少个月你会处于亏损状态?
记住,当涉及测试系统的健壮性时,批评是一种健康的实践。站在你和系统成功之间的是你的自我。你可能会得出这样的结论:你的无懈可击的交易系统的结构完整性像瑞士奶酪一样。没必要责备自己。没有人生来就是黑带。这既不好也不坏。我们都必须度过那个阶段。这只是一个调整你引擎的邀请。
接下来,利用上述问题的答案绘制你策略的流程图。互联网上有许多免费的网站。
- 从经典的入场/退出案例开始
- 添加逐步加仓/逐步减仓
- 添加止损
- 添加最终退出
- 重复上述过程,带入特殊情况的入场
流程图是构建策略的强大工具。它们迫使我们进行逻辑思考。用条目和退出的顺序建立你的策略模板。然后填写触发这些事件的条件。实际上,所有的策略都可以归结为几个模板。它们从最简单的沃伦·巴菲特模板开始:买入后不做任何事情,一直到长/短期逆转的逐步退出/逐步进入。策略就像搭积木一样。当你努力优化你的交易优势时,你可以添加或减少积木。
记住,你在与严谨的人竞争,他们认真对待这个过程。你在澄清你的过程中迈出的每一步都会让你与那些不这样做的人区别开来。你的策略流程图是绝望时的一盏明灯,是狂喜时的理性之声。不要忽视这一部分。你认为有多少市场参与者会花时间澄清他们的策略?投资者可能只能用一只手数出能够制作出信号引擎流程图的经理的数量。他们今天可能不会和你一起投资,但他们会记住你的专业精神。
现在我们已经把引擎拆开了,让我们来看看变速器。
资金管理模块
这个模块包括头寸规模管理,应该考虑在我们本章中看到的市场变量的背景下:
- 你的头寸调整算法是什么?
- 它在你赢或输了一连串的比赛时会发生什么变化?在赢了或输了一连串比赛之后,它是什么样子?
- 对于你的风格,还有哪些其他位置大小调整算法更合适?
- 你每边有多少个名字?你的表现周期如何演变?
- 你的大/小头寸比是多少?
- 将你的敞口与市场进行对比:总敞口、净敞口、净 beta、投资组合热度、集中度、净交易(买入与卖出占总敞口的百分比)和表现。
- 在输掉一连串比赛时,你的敞口是什么样子?具体一点。
这是你在市场上的存在的传输部分。你的引擎在厚厚的市场中发出信号。市场向你扔东西。你的头寸大小、集中度和敞口管理决定了你选择如何应对。绘制那些数据。"你是谁?"图表是你将要建立的最重要的视觉工具。在一个图表上绘制以下元素:累积基准和策略收益、总敞口、净敞口、净 beta 和净交易(买入减卖出占总敞口的百分比)。那张图表将展示市场向你抛出的东西,以及你如何通过交易净买入/卖出、总体信心和净和净 beta 的方向性来应对。很少有数据可视化练习有这样的"哇"效果。
步骤 2:投资目标
新手对冲基金经理总是说他们想尽可能赚取更多的钱。老手想尽可能稳定地赚钱。有老交易员也有大胆的交易员。但没有老的大胆的交易员。追求回报或一致性是互相排斥的。老手只是简单地经受住了最初的自负,接受了自己的本性和能够取得的成就。
许多交易教练都会鼓励你在开始交易之前定义你的目标。他们会逼迫你去做一些你不是的事情。要么你征服自己,变成那些目标,要么你反抗,最终会交易其他完全不同的东西。人类在实现理想愿景方面表现糟糕。每个其他的多空玩家都说他们的目标是每年 15-20%的低相关回报。但现实是只有少数精英能够持续实现两位数的回报率。每个人都希望在 1 月 1 日拥有六块腹肌,但从三月开始健身房就空了。这个过程旨在从你的信念到你的行动中产生一致性。赚钱只是将内在信念从你的潜意识带到你的意识,再一直延伸到你的无意识习惯的过程。市场巫师并不比别人聪明,他们只是有着更聪明的交易习惯。
现在,你知道自己身在何处。你也知道自己想要去哪里。为了实现这一点,你知道需要发生哪些变化。你也对什么可以做什么不可以做有一个现实的看法。目标并非玄学般的愿望。你的目标可能很高远。但它们仍然扎根于现实。下一步是将你的目标具体化为一个投资组合管理过程。回到传输部分,关注变量。你的头寸大小算法是什么?使用你工具箱中的四个主要暴露来定义你的投资组合:总量、净量、净β、集中度。这些将决定相关性、波动率、回撤,并最终影响表现。
考虑到数据和条件路径的多维数组,这个练习很难模拟。例如,有些策略一年只有几次交易。如果你因为手头现金不足而错过了一次交易,而这个交易后来的表现比其他证券要好出 20%,你的整体结果就会被扭曲。这个问题没有简单的解决方法。这些回测问题超出了本书的即时范围。
第四步:设计你自己的任务:产品、市场、匹配
多空头像其他任何产品一样受供需法则的约束。多空投资组合就像牙膏或肥皂等其他商品产品一样。在没有销售发生之前,什么都不会发生。你的工作就是让那块肥皂变得不可抗拒。
一旦你明确了你的投资目标,那么就是进行现实检验的时候了。你的目标是否可实现?到现在为止,你应该对自己能适应的范围有个合理的了解。例如,你可能明白,在净暴露度在+/-5%、总暴露度在 200%的情况下,+30%的回报是非常不可能的。你也知道,将波动性减半将使你排队等候的时间缩短。
你的产品是否受欢迎?请记住,投资者宁愿把资金投入每个月回报 0.5%的产品,也不愿把资金投入每年有 9 个月处于亏损状态的产品,即使后者的回报率为+20%。
这是你考虑“产品、市场、适合度”过程的步骤。你的风格可能不完全符合市场需求,但只要你愿意做出调整,你仍然可能拥有一个有吸引力的产品。好消息是,你将与那些心态是“建造它,他们会来”的人竞争。
第五步:记录
每个市场参与者都遭受交易选择性遗忘的困扰。不幸的是,大多数市场参与者花费大量时间开发交易系统,却最终交易其他东西……每次我们放弃一个交易、超过止损、增加赌注,我们都在交易与我们原始系统不同的东西。
除非我们将我们的交易历史纳入我们当前的交易决策中,否则我们注定要重复同样的错误。像西西弗斯一样,我们将举起我们表现的巨石,只是看着它们在下一个故障时滚下来。
我们防止进一步损害的两种主要方式是通过头寸规模和拒绝交易。例如,我们都有自己的宿敌股票,我们尝试了多次都失败了。与其冒着第二次风险相同的金额,不如冒着更小的风险。海龟交易员有一个规则:经过 3 次失败后就停止尝试。
记录所有交易,按策略、方向和证券分类。例如,它可能是 ABC 股票,长期趋势跟踪。这样,你就能够计算出按策略、方向和股票分类的统计数据,如盈利预期和命中率。
这些统计数据对评估你的系统很有用。你的交易日志只能提供你是否遵循交易系统的不完整视图。除了你的交易历史,还有四个领域可以直接衡量你的遵循程度:进场、出场、头寸规模和记账。所有这些都与交易心理有关。
进场
除了你进入的交易,还要跟踪你放弃的交易。正如克劳德·德彪西所说:“音乐也是音符之间的沉默。”你没有选择的交易与你选择的交易一样定义了你。放弃一个否则有效的交易也是一种交易决策。它对你的投资风格有不同的看法。市场参与者放弃进场的原因大致有四个:
- 现金余额不足:这仍然是错过信号的头号原因。
- 对系统的不信任: 这是一种根深蒂固的失败和不足的恐惧。解决方法是有良好的统计数据并多做工作。
- 系统不完整:有些系统并不适用于尾部事件。在不稳定的环境中进行交易可能会危及业绩。
- 不处于正确的心态: 这是那种在深度连续亏损期间放弃免费钱的经典被击倒的交易员。这个问题有一个简单的解决方案:进行小额交易。
作为最后的警告,何时不进入头寸,一个对冲基金经理曾在品酒之后坦白承认,他的一个逆向交易是出于报复。他曾经通过交易将其视为多头,现在他正在通过做空报复他自己(以及他的投资者)。
退出
你会以某种方式退出交易。这将反映在你的交易日志中。可能并不立即显而易见的是,你在关闭头寸时是否遵循了你的系统。
特别注意止损。每次强行设置止损或过早获利时都要计数+ = 1。有时这可能是正确的决定,但这是偏离你的系统。每当你违背你的系统时,评估你的心态。
头寸大小
一个没有记录情绪的交易日志就像一部没有声音的电影。我们交易的是我们的情绪。这既体现在过度/不足的交易上,也体现在头寸大小上。兴奋的交易员过度交易并超大头寸。处于低迷状态的交易员错过了“免费钱”交易,并过于保守地下注。你必须努力像精神病患者一样交易,尽量减少情绪干扰。
跟踪你的情绪很简单。根据你的主观情绪稳定程度进行评分,从沮丧(-3),到每次交易进出时的平静的圣洁空间(0),再到统计上受挑战的 200%(过度)自信(+3)。几次进入后,就会有一个基准线。我在读范·萨普博士的时候发现了这个有趣的游戏。我个人发现无聊与对系统的遵循呈正相关。显然无聊是好事!
记录
反思和记录是将批判性眼光带入你的流程的有效技术。这将为你的工作带来创造力和客观性。记录并不是一种自由自在的自我责备练习。当情绪极端时,市场参与者常常口若悬河,但当事情进展顺利时却保持沉默。将你的日志结构化为四个部分:
- 语境:强调你在市场上所见的。这为你的交易决策提供了背景。也许你没有买入是因为那时世界看起来似乎快要结束了。
- 你的立场:这需要具体。养成给你的观点附加数字的习惯。例如,我的总收益率是 180%,高于 200%的平均水平,我的净β比一个月前高了+0.1。我持谨慎乐观态度。风险管理是一种语言。
- 策略改进:什么有效,什么无效。这是有趣的部分。
- 投资理念:Evernote 是一款优秀的日记软件。使用标签和笔记本来分类你的日记。
单单那种记录的纪律就足以让你脱颖而出,与股票投机者的无名熔岩区别开来。并不是每个投资者都会和你一起投资,但每个人都会记得你的记录纪律。
步骤 5:完善你的授权
“纪律就是做你讨厌的事情,像你热爱它一样。” – 迈克·泰森
这是一个迭代过程。花时间制定出一些你感觉舒服交易的东西,这将吸引投资者。上述过程是应用于股票市场的“刻意练习”。详细阐述你的流程将迫使你专注于策略的具体点。你的记录将提供即时反馈。这将提高信心,并将你与竞争对手区分开来。
总结
管理一个多空组合就像从家庭 SUV 升级到跑车一样。没有适当的训练,人们往往会将他们闪亮的新玩具带到越野赛道上。在这一章中,我们看了一下操纵你所需要吸引你想要的客户的回报的主要杠杆。这些是总曝光或杠杆、投资组合热度或开放风险、净暴露或方向性、净 beta 或对市场的剩余敏感性以及集中度或投资组合中名称的净数量。这些变量提供了对波动性、表现、相关性和流动性的访问,就像市场影响一样。
在接下来的章节中,我们将带你逐步了解如何构建一款股票多空产品的方法。我们将使用一种强大的技术将股票重新分类为看涨、看跌和横盘市场。从那里开始,我们将讨论执行:进场、出场、订单优先级。我们将以一个最被低估的工具,即投资组合管理系统,结束。但首先,让我们从一个主要的障碍开始:观点的稀缺。这种方法将使您能够在整个市场之前定位自己,并使您看起来像一个卖空大师。
第十二章:信号与执行
“我们有两只耳朵和一张嘴,这样我们可以听两次比说话多”, – 司提反
这一章将告诉您如何准确地设置订单优先级及其背后的原因。我们将研究如何使用相对序列管理投资组合,但在绝对序列中执行。我们将深入研究出场,从不盈利和盈利的情况开始。我们将考虑出场的心理卫生。然后,我们将转向一个热门话题:进入和重新进入。我们将提出直觉上反直觉但有效的低风险高回报的进入技巧。整本书都铺垫到了这一点和接下来的章节,所以我们将重新讨论书中的部分内容,提出一些综合我们迄今所见的一切的代码,并可视化结果。
在此过程中,我们将讨论以下主题:
- 导入库
- 时间就是金钱:订单时间的重要性
- 订单优先级
- 出口
- 进入
您可以通过以下链接访问本章中所有图像的彩色版本:static.packt-cdn.com/downloads/9781801815192_ColorImages.pdf。您还可以通过该书的 GitHub 存储库访问本章的源代码:github.com/PacktPublishing/Algorithmic-Short-Selling-with-Python-Published-by-Packt。
导入库
对于本章和本书的其余部分,我们将使用pandas、numpy、yfinance和matplotlib库。我们还将使用 ScientificPython 库中的find_peaks。所以,请记得首先导入它们:
# Import Libraries
import pandas as pd
import numpy as np
import yfinance as yf
%matplotlib inline
import matplotlib.pyplot as plt
from scipy.signal import find_peaks 时间就是金钱:订单时间的重要性
2005 年,日本市场经历了指数上涨。僵尸股再次复活了!2006 年 1 月底,警方实际上突袭了这个派对。他们逮捕了这个新日本典范的标志性人物。突然间,感觉就像是一个夜总会关门了。粗糙的霓虹灯突然间被打开。醉醺醺的人们在舞池里相互凝视,困惑不解。现实带着报复性回来了。漂浮的僵尸重新发现了牛顿物理学。不幸的是,对于任何单一问题的借贷的可用性和成本都是令人望而却步的,所以在我和美林证券股票借贷部门的伙伴们一起,我们想出了一个信用评级资产价格(CRAP)篮子交换的想法。我们倾入了所有我们能找到的僵尸。借贷成本是可以负担得起的 2%。价格将是当天收盘价。容量几乎是无限的。在复合 beta 达到 2.3 时,它比指数期货具有更大的扭矩。我们已经做好了生意。
但是当是时候下手时,负责人犹豫了。他抱怨说太波动了,太有风险了,太不正统了。因此,我们最终选择了“监视”它,一个花哨的词来制造《大富翁》的货币:-2%,-4%,-5%,日复一日。但他对这笔交易仍然不感到舒适。三周后,我得出结论:异国情调是一个度假胜地,而不是一个价值三亿美元的组合投资组合中的做空位置。然后,有一天,掉期进来了。我的名字也在上面。那天晚上我睡不着。第二天,它又额外跌了-2%。第三天,它再跌了-0.5%,但然后,它开始稳定下来。它上涨了+0.5%,+3%,+6%。我们完美地把握住了底部。但现在,史上最大的做空追击正在给做空者带来民主。最终,我们以巨额亏损平仓了一笔在不到两个月内下跌了-63%的做空仪器。
故事的寓意:时间就是金钱。有正确的想法是一回事。良好地执行它是另一回事。熊市反弹定期发生。生活中有三个确定性:税收、死亡,以及在二者之间,熊市反弹。一些市场参与者声称市场无法进行时机把握。在多头方面,市场更加宽容。构思和执行可以融合在一起。支持多头的上升漂移也惩罚了空头卖家。许多基本面空头卖家经常抱怨他们太早或有时太晚了。
订单优先级
进入是一个选择,退出是一个必要性。你可能随心所欲地进入,但你很少有机会按自己的意愿退出。在执行交易员的英语中,进入是限价单,而退出是止损单或市价单。长期持有者经常苦恼于现金余额。他们需要知道每天可以购买多少。长/短组合投资组合比传统的仅长仓簿记有更多的变动部分。事情很快就会变得混乱不堪。因此,为进入和退出设置“通行权”是明智的选择。在执行交易员的英语中,退出始终排在第一位。消耗现金的订单具有“通行权”。这可以总结如下:
- 买入做空是最高优先级。它的功能类似于买单。它消耗现金。做空对长期购买力和总体敞口产生影响。买入做空在极少数情况下可能触发保证金调用。
- 卖空是次高优先级。它释放了被困住的现金。
- 卖空:做空生成多余的现金。这些多余的现金可以用来购买更多的股票。一些司法管辖区要求做空者在下达做空订单之前先获得股票借出。未能这样做会导致裸卖空。这种做法指的是未事先找到借出就进行卖空。这本身并不违法,但严重不受欢迎。交易通常被重新分类为“未交付”,并进行关闭。如果你想被认真对待,就不要…
- 买入多单:再次强调,最重要的交易是最后进行的。只有当所有交易都排好队之后,才应该进行买入多单的订单。如果空头头寸没有平仓,但进入了多头头寸,这将减少现金余额。如果需要急忙平仓空头头寸,这可能会带来一些风险。
让我们回顾一下。首先是降低风险的交易。这些交易包括买入平仓和卖出多单。然后是旨在增加现金余额的交易:卖出空单和买入多单。
重新进入信号是一个案例,其中重复犯罪者应该被安排在前排。任何重新进入信号都是更长期趋势仍然有效的确认。此外,先前头寸已经嵌入了损益。因此,综合未平仓风险低于任何新进入的风险。然而,这也有局限性。增加已有头寸的操作被称为金字塔加码。就像生活中的一切一样,趋势会成熟。每个新头寸都会更接近趋势的成熟——最终是耗尽。这增加了集中风险和波动性。因此,通过例如每次重新进入时采取更小的头寸来降低风险是明智的。头寸规模最终会变得太小而被拒绝。
接下来,我们将更详细地看一下当我们以相对系列运行系统时会发生什么。
相对价格和绝对执行
虽然你的系统是基于货币调整和基准相对价格运行的,但是以美元发送一笔关于日本股票相对于 MSCI World 的订单,确实会引起交易台上一些滑稽的表情。这对你来说可能是昭然若揭的,但需要说明的是,交易员不擅长心灵读取。在现实世界中进行交流时,订单必须以本地货币进行下达。
由于系统是基于货币调整和基准相对价格运行的,所以止损不需要被翻译。实际上,止损与本地绝对价格无关。在前面的章节中,止损是基于相对价格而不是绝对价格的。这是因为你的系统应该是基于相对价格的。这意味着止损订单不需要在经纪人的服务器上停留。不需要挂止损订单的一个好处是它们不能被掠夺性的智能资金(高频交易(HFT)参与者)操纵。
订单类型
高频交易的出现严重丰富了交易订单的选项。想要优化执行超出击败成交量加权平均价格的市场参与者,欢迎探索订单执行的广阔领域。
为了本书的目的,让我们坚持一个简单的原则:入场是一个选择,退出是一个必要条件。这意味着退出交易要么是市场、止损或止损限价订单。入场要么是成交或取消,限价或止损限价订单。当我们扳动扳机时,我们希望成交。我们内心的白痴喜欢追逐,但我们的业绩记录讨厌糟糕的执行。你的入场和退出缺乏纪律将影响你的业绩记录,所以坚持计划。一点点克制会有回报。从相对系列到绝对系列的转换中会有一些小的滑点,但最终这一切都会平衡起来。
接下来,让我们讨论退出和入场——我们按照这个顺序讨论它们,因为如我们已经注意到的,退出应优先于入场。
退出
退出分为不盈利和盈利退出。前者旨在生存,而后者则建立繁荣。我们在第二部分,外在游戏:打造强大的交易边缘中大量讨论了退出。以下是一个逐步简短的概括,涵盖了退出的实际方面和心理卫生。
止损
止损对交易边缘公式中的四个变量中的三个直接可测量影响:胜率、败率和平均损失。仅因为这个原因,它总是位于优先级列表的顶部。记住,将专业空头卖家与游客区分开来的是设定止损并遵守它们的能力。接下来的内容可以视为一个重要的核查表。我们在整本书中都涵盖了这些话题,特别强调了第七章,提高您的交易边缘。
- 在逻辑上的表达位置设置止损,其中论点被无效化
- 设置一个损失缓和的跟踪止损:这有两个积极的影响:
- 它可以减少损失,并将盈利期望倾向于保本。
- 在心理上更容易处理和停止较小的持仓
- 持仓规模:在发送交易之前运行风险管理以计算您的暴露。
- 保守地设置固定止损
- 在跟踪止损上积极一点
接下来是心理准备。小额损失会消耗你的情感资本。不要忽视你的心理卫生。提醒一下,所有优秀的交易者都专注于心理资本,而平庸的人则担心移动平均持续时间或其他毫无意义的琐事。
事前评估
想象自己在亏损时关闭交易,并感受相关的负面情绪。重复这个过程并调整大小,直到你感到舒适接受损失。这样可以提前处理你的悲伤。按下发送按钮,对你的资金说再见,并考虑以下因素:
- 时间停止:削减或减少持仓规模。时间停止在心理上很难执行:“如果我再给它多一天、一周、一个月……”一个技巧是想象一个真实的时间浪费者,并将图像锚定到持仓位置。
- 减少损失:冥想,保持警觉。这可以防止急切或恐惧。损失是游戏的一部分。
- 止损:这是最坏的情况。如果您在事前作业上做了功课,这应该是个形式上的事情。首先,原谅自己。
事前评估可追溯到斯多哥哲学家和罗马皇帝马库斯·奥里利乌斯。这是最有效的视觉化练习之一,可以在压力下保持冷静。
齐格尼克效应
提醒自己以下内容:
- 一旦头寸消失在视线之外,您将在 2 周内几乎不会记得那个头寸。您的资本比由单个糟糕交易引起的脑雾更重要。
- 做出小的损失将确保您活着去做另一次交易。带上尺子(前额叶皮质)和战士心态来执行交易。
当您定期查看交易日志时,特别注意止损。注意自己的感受。这已经不像以前那样情绪化了。你看,这并不那么难。如果你微笑了,太好了。存储那种感觉。您正在建立一个明智交易战士的新神经路径。
盈利退出
下面是盈利退出的逐步方法:
- 提前决定风险降低的方法:目标价格、跟踪退出、期权。不要偏离。
- 不要等待熊市反弹。随着人们继续卖出以避免市场冲击,及时平仓。
- 这是平仓的最小数量,以保持交易盈亏平衡:

- 顺势而为熊市反弹。让它冲刷过去。如果您提前降低了风险,这不应该影响您的心态。当熊市反弹结束时,重新设置止损。
- 如果涨势的高点低于上一个高点,则重新进场;否则,不做任何操作。
让我们用一些 Python 代码来结束这一切。首先,我们将使用三个变量来设置目标退出价格:price、stop_loss 和 r_multiplier。我们计算 r 作为从 price 到 stop_loss 的距离。然后,我们应用一个乘数,恰当地命名为 r_multiplier。这个数字被添加回成本以计算目标价格。然后,我们将使用相同的 r_multiplier 计算要退出的数量。在第七章,提高交易优势中,我们看到了目标价格和要退出的数量之间的反向关系。
def target_price(price, stop_loss, r_multiplier):
r = price - stop_loss
return price + r * r_multiplier
def partial_exit(qty, r_multiplier):
if (qty * r_multiplier)!= 0:
fraction = qty / r_multiplier
else:
fraction = 0
return fraction
price = 100
stop_loss = 110
qty = 2000
r_multiplier = 2
pt = target_price(price, stop_loss, r_multiplier)
exit_qty = partial_exit(qty, r_multiplier)
print('target price', pt,'exit_quantity',exit_qty) 输出将如下所示:
target price 80 exit_quantity 1000.0 80%的头寸将会在此时退出。这样可以降低 100%的风险。接下来,让我们考虑如何确定进场时机。
进场
“把市场波动视为朋友而不是敌人;从愚蠢中获利,而不是参与其中。” – 沃伦·巴菲特
优秀的扑克玩家不是打自己的牌。他们打其他玩家的牌。要成功,您需要系统地将概率倾斜到您的有利。市场碰巧是一个概率游戏。取得伟大成功的方法不仅是打出你的手牌,还要打市场的无形之手。
玩转市场的第一种方法是我们在第五章,政权定义中看到的。让市场决定股票应该走哪一边。让我们诚实地说一秒钟。做空泡沫股票的市场参与者是被压抑的复仇交易者。在内心深处,他们对自己的阴影自我没有参与做多感到愤怒。也许他们关闭得太早了。也许他们完全忽视了那艘船。无论哪种方式,他们通过让别人的宝贵资金立即置于危险之中来发泄他们的挫败感。在对“公平”估值的成年人呼吁背后,隐藏着一个 6 岁孩子受伤的自尊心的“必须正确”的阴影需求。
没有比 TSLA 更好地说明这一现象的了。这是一家汽车制造商,处于一个声名狼藉的脆弱行业,被定价为科技股,其债券被定价为垃圾债。必须有所作为。这给了空头卖家充足的理由来猛烈袭击股票。在冠状病毒大流行之后,股价下跌到了$400。这给了空头卖家加倍努力的理由,只是在接下来的六个月里面临着急剧的三倍反弹。
如果做空者将跌幅视为一个机会性的买入机会,他们还会围攻吗?当然不会,他们会笑着跳着去银行。地球上的每个人,从瑙鲁到博博迪乌拉索,都会知道他们选中了那只股票有多聪明。现在,他们被苦苦降低到要求对那个粗鲁价格公正的地步。无论哪种方式,别人的钱不是一个有效的智商测试。再次,他们让自己的自尊心在市场的永恒舞蹈中踩到了自己的脚趾。当心那些玩弄伊卡洛斯股票的卡桑德拉,因为他们可能会将你拖入表现不佳的世界。在听从他们的建议时,为冥界的渡船人留下最后一枚硬币。如果做空游戏是关于玩弄市场的无形之手,那就让市场为你做繁重的工作。做空市场贬低的问题,并在需求旺盛的问题上做多。
第二种玩转市场的方法是掌握时机。多年来,我常常抱怨空头挤压。我进入一个头寸,感觉良好,然后在下一个熊市反弹中被无情地止损出局。财务资本受到损害,情感资本再次遭受侮辱。更重要的是,似乎教训被忽略了。然后有一天,空头挤压的能量突然映照在我的智力密度上。由于价格似乎会在我的“防线”止损线之外反弹,我所要做的就是等待下一个熊市反弹,看看新的海岸线,并获得更好的执行。
我开始将熊市反弹视为礼物。它们将他们的宝藏带到岸边供我们选择。一旦熊市反弹开始消退,价格就会像职业政客一样摇摆不定。做空者被困在岸上。乐观的多头持有者尚未被拖入新的深渊。分界线清晰。在执行交易员英语中,这是一个低风险高回报的入场价格,上方设有明确的止损线,并且可能会有下跌。等待市场开始下跌,然后沿着看跌趋势打印一个新的较低的高点来进入做空。顺便说一句,这是“买入跌势”技术在多头方面的镜像入场。
第三种玩市场的方式是执行。做空者面临着极不利的概率。如果你在股价下跌时做空,只要记住 90%以上的市场参与者只会做多,某个地方某人会将当前的弱势视为折价购买的机会。如果你在熊市股票反弹时做空,你可能会因为被抛售或者牛市的开始而被淘汰。作为一个做空者,只有在概率对你有利的狭窄时间窗口。为此,你需要密切关注价格走势。
一个很好的类比是豹子,是非洲四大动物中最小的。尽管豹子在智商、奔跑速度和武器方面胜过它们的猎物,但它们从不追逐。它们隐藏在树上等待猎物靠近它们。做空者需要以同样的方式行事。这是一个三步过程。
- 首先,你的制度分析(来自第五章,制度定义)应该已经确定了股票可能处于横向或熊市模式中的一种。与市场一致通常会倾向于增加你的获胜几率。
- 第二,宇宙已经被缩小为可投资候选股票的短列表。
- 第三,熊市反弹的退潮清晰地表明了牛市并不掌控局面。
市场指导两个步骤:设置和执行。一个步骤来自于分析:可投资候选股票的短列表。我们已经讨论过如何倾斜你的交易优势在第二部分,外部游戏:制定强大的交易优势中,但我们将重温一些关键想法:
- 首先,使用相对系列。
- 第二,通过制度对表现不佳者和表现优异者进行初步分类。
- 第三,在高点后进入做空或在低点后进入做多。
- 第四,将止损设置在一个合理的表达点。
- 第五,计划部分退出以减少风险。
让我们回到豹子。一旦它扑出去,它就不会在半空中停下来反思生活的意义、动物的残酷性或细胞层面素食饮食的比较优势。反省的时机已经过去。现在,是执行时间。游客会在他们认为是正确的船之后立即跳跃和游泳。专业人士将耐心等待市场上涨并冲洗游客。当反弹进入并翻转时,他们会站在一边,只有在那时他们才会坐在渡轮上。关于卖空的最好消息是熊市反弹的节拍的规律性。
翻转:熊市反弹的合气道
每个长时间练习这门手艺的卖空者在熊市反弹中都受过伤。一个简单的观念转变可以将这种能量从毁灭转变为利用的力量。
目标是尽早以合理的成功概率进入。短线挤压可能会棘手。它们总是超出预期并持续时间更长。
进入大师级别的卖空者的标志是在下一个大幅下跌中做对,但仍然低估了熊市反弹的能量。尊重市场,因为它们肯定不会尊重你。市场不知道你的名字,也不应该在乎。接受你将不得不为确认付出代价。等待局部高峰过去和翻转开始。稍后我们将用几张图来说明这一点,但现在让我们看看这种方法的优点。
这种翻转或潮汐滚动方法有一些优点:
- 风险管理:当前高点低于峰值。牛市不再掌控局势。如果峰值上升,则是早期迹象表明制度可能已经改变。趋势是你的朋友。
- 入场接近顶部。熊市处于混乱状态。牛市充满乐观。你是机会主义者。现在概率正倾向于你。
- 借贷可用性:熊市通常会冲洗掉游客。再次可以借贷。即使最喧哗的卖空者也害怕涉足水中。
- 更大的头寸大小:接近顶部的近距离需要比崩盘水平更大的头寸。你更接近一个合乎逻辑的止损。如果价格上涨超过当前顶部,则你已经制定好了退出计划
- 清晰的分界线:顶部是牛市和熊市的定论。有关供给、需求和波动率的信息是可用的。
以下是我们之前讨论过的一些其他经典入场方法。
移动平均线
移动平均线是简单、有效且足够稳健的信号。虽然没有完美的策略,但通常最好使用短期移动平均线,比如收盘价低于 5 天移动平均线。有关移动平均线交叉的更多信息,请参阅第五章,制度定义。
回撤
回调信号最高点的距离。这可以是从最高高点或最高低点开始的距离,以平均真实范围表示。把它看作是一种形式的移动止损。作为提醒,请看我们在第五章,制度定义中概述的回调摆动函数:
def retracement_swing(df, _sign, _swg, _c, hh_ll_dt, hh_ll, vlty, retrace_vol, retrace_pct):
if _sign == 1: # swing high
retracement = df.loc[hh_ll_dt:, _c].min() - hh_ll
if (vlty > 0) & (retrace_vol > 0) & ((abs(retracement / vlty) - retrace_vol) > 0):
df.at[hh_ll_dt, _swg] = hh_ll
elif (retrace_pct > 0) & ((abs(retracement / hh_ll) - retrace_pct) > 0):
df.at[hh_ll_dt, _swg] = hh_ll
elif _sign == -1: # swing low
retracement = df.loc[hh_ll_dt:, _c].max() - hh_ll
if (vlty > 0) & (retrace_vol > 0) & ((round(retracement / vlty ,1) - retrace_vol) > 0):
df.at[hh_ll_dt, _swg] = hh_ll
elif (retrace_pct > 0) & ((round(retracement / hh_ll , 4) - retrace_pct) > 0):
df.at[hh_ll_dt, _swg] = hh_ll
else:
retracement = 0
return df 下面,让我们再次提醒自己关于retest_swing函数。
重新测试
提供在第五章,制度定义中的摆动检测代码是基于重新测试的。价格打印出高点,然后是低点。价格试图攀升到新的高点,但失败了,并且低于先前的低点。距离前一次摆动越远,重新测试就越不嘈杂。作为提醒,请参阅源代码:
def retest_swing(df, _sign, _rt, hh_ll_dt, hh_ll, _c, _swg):
rt_sgmt = df.loc[hh_ll_dt:, _rt]
if (rt_sgmt.count() > 0) & (_sign != 0): # Retests exist and distance test met
if _sign == 1: # swing high
rt_list = [rt_sgmt.idxmax(), rt_sgmt.max(), df.loc[rt_sgmt.idxmax():, _c].cummin()]
elif _sign == -1: # swing low
rt_list = [rt_sgmt.idxmin(), rt_sgmt.min(), df.loc[rt_sgmt.idxmin():, _c].cummax()]
rt_dt,rt_hurdle, rt_px = [rt_list[h] for h in range(len(rt_list))]
if str(_c)[0] == 'r':
df.loc[rt_dt,'rrt'] = rt_hurdle
elif str(_c)[0] != 'r':
df.loc[rt_dt,'rt'] = rt_hurdle
if (np.sign(rt_px - rt_hurdle) == - np.sign(_sign)).any():
df.at[hh_ll_dt, _swg] = hh_ll
return df 接下来,我们将考虑一个富国银行的例子,其中重新测试和回调摆动都在起作用。如果一个方法失败,另一个可以补偿。
把所有东西都放在一起
现在是将想法结合起来,并在一个代码块中综合方法的时候了。在第五章,制度定义中,我们发布了富国银行与 S&P 500 的绝对和相对系列的图表:
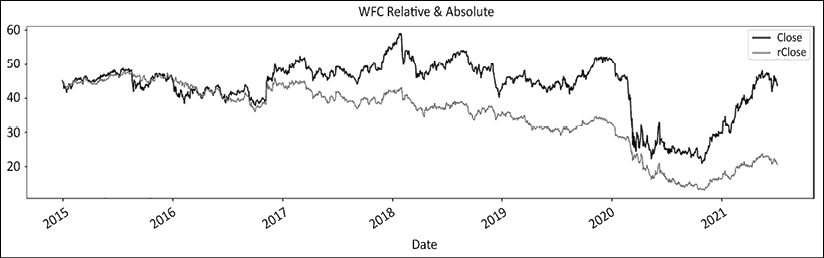
图 12.1:富国银行价格在绝对和相对于 S&P500 的图示从 2015 年 9 月开始
我们已经涵盖了几乎所有内容,所以没有真正需要对代码进行评论,除了两件事:
- 我们从初始化基准开始,并下载下面股票的数据。如果您想要为一系列股票重复此过程,请在
df下载行之前插入一个循环。 - 其次,我们通过列表推导重新初始化了
_o、_h、_l和_c属性。这在代码的下一部分将会有意义。
接下来,我们使用摆动检测函数计算了绝对和相对系列的摆动和制度。两次运行相同函数但分配了绝对或相对系列更有效。这就是为什么我们在之前重新初始化了_o、_h、_l和_c以及下面的摆动值。
### STEP 1: ### Graph Regimes Combo ###
def graph_regime_combo(ticker,df,_c,rg,lo,hi,slo,shi,clg,flr,rg_ch,
ma_st,ma_mt,ma_lt,lt_lo,lt_hi,st_lo,st_hi):
#### removed for brevity: check GitHub repo for full code ####
### Graph Regimes Combo ###
### STEP 2: ### RELATIVE
def relative(df,_o,_h,_l,_c, bm_df, bm_col, ccy_df, ccy_col, dgt, start, end,rebase=True):
#### removed for brevity: check GitHub repo for full code ####
### RELATIVE ###
### STEP 3: import library
from scipy.signal import *
### STEP 4: #### hilo_alternation(hilo, dist= None, hurdle= None) ####
def hilo_alternation(hilo, dist= None, hurdle= None):
#### removed for brevity: check GitHub repo for full code ####
#### hilo_alternation(hilo, dist= None, hurdle= None) ####
#### historical_swings(df,_o,_h,_l,_c, dist= None, hurdle= None) ####
def historical_swings(df,_o,_h,_l,_c, dist= None, hurdle= None):
#### removed for brevity: check GitHub repo for full code ####
#### historical_swings(df,_o,_h,_l,_c, dist= None, hurdle= None) ####
### STEP 5: #### cleanup_latest_swing(df, shi, slo, rt_hi, rt_lo) ####
def cleanup_latest_swing(df, shi, slo, rt_hi, rt_lo):
#### removed for brevity: check GitHub repo for full code ####
#### cleanup_latest_swing(df, shi, slo, rt_hi, rt_lo) ####
### STEP 6: #### latest_swings(df, shi, slo, rt_hi, rt_lo, _h, _l, _c, _vol) ####
def latest_swing_variables(df, shi, slo, rt_hi, rt_lo, _h, _l, _c):
#### removed for brevity: check GitHub repo for full code ####
#### latest_swings(df, shi, slo, rt_hi, rt_lo, _h, _l, _c, _vol) ####
### STEP 7: #### test_distance(ud, bs, hh_ll, vlty, dist_vol, dist_pct) ####
def test_distance(ud,bs, hh_ll, dist_vol, dist_pct):
#### removed for brevity: check GitHub repo for full code ####
#### test_distance(ud, bs, hh_ll, vlty, dist_vol, dist_pct) ####
#### ATR ####
def average_true_range(df, _h, _l, _c, n):
#### removed for brevity: check GitHub repo for full code ####
#### ATR ####
### STEP 8: #### retest_swing(df, _sign, _rt, hh_ll_dt, hh_ll, _c, _swg) ####
def retest_swing(df, _sign, _rt, hh_ll_dt, hh_ll, _c, _swg):
rt_sgmt = df.loc[hh_ll_dt:, _rt]
#### removed for brevity: check GitHub repo for full code ####
#### retest_swing(df, _sign, _rt, hh_ll_dt, hh_ll, _c, _swg) ####
### STEP 9: #### retracement_swing(df, _sign, _swg, _c, hh_ll_dt, hh_ll, vlty, retrace_vol, retrace_pct) ####
def retracement_swing(df, _sign, _swg, _c, hh_ll_dt, hh_ll, vlty, retrace_vol, retrace_pct):
#### removed for brevity: check GitHub repo for full code ####
#### retracement_swing(df, _sign, _swg, _c, hh_ll_dt, hh_ll, vlty, retrace_vol, retrace_pct) ####
### STEP 10: #### regime_floor_ceiling(df, hi,lo,cl, slo, shi,flr,clg,rg,rg_ch,stdev,threshold) ####
def regime_floor_ceiling(df, _h,_l,_c,slo, shi,flr,clg,rg,rg_ch,stdev,threshold):
#### removed for brevity: check GitHub repo for full code ####
#### regime_floor_ceiling(df, hi,lo,cl, slo, shi,flr,clg,rg,rg_ch,stdev,threshold) #### 下面是实际重要的代码,将打印出图 12.1所示的图形:
params = ['2014-12-31', None, 63, 0.05, 0.05, 1.5, 2]
start, end, vlty_n,dist_pct,retrace_pct,threshold,dgt= [params[h] for h in range(len(params))]
rel_var = ['^GSPC','SP500', 'USD']
bm_ticker, bm_col, ccy_col = [rel_var[h] for h in range(len(rel_var))]
bm_df = pd.DataFrame()
bm_df[bm_col] = round(yf.download(tickers= bm_ticker,start= start, end = end,interval = "1d",
group_by = 'column',auto_adjust = True, prepost = True,
treads = True, proxy = None)['Close'],dgt)
bm_df[ccy_col] = 1
ticker = 'WFC'
df = round(yf.download(tickers= ticker,start= start, end = end,interval = "1d",
group_by = 'column',auto_adjust = True, prepost = True,
treads = True, proxy = None),2)
#### removed for brevity: check GitHub repo for full code ####
rohlc = ['rOpen','rHigh','rLow','rClose']
_o,_h,_l,_c = [rohlc[h] for h in range(len(rohlc)) ]
rswing_val = ['rrg','rL1','rH1','rL3','rH3','rclg','rflr','rrg_ch']
rg,rt_lo,rt_hi,slo,shi,clg,flr,rg_ch = [rswing_val[s] for s in range(len(rswing_val))] 我们首先对绝对系列运行一个循环。我们使用上下限制度方法计算摆动和制度。在第一个循环结束时,我们使用相对系列重新初始化了_o、_h、_l、_c和摆动变量。现在我们已经计算出了富国银行在绝对和相对于 S&P 500 的摆动和制度。让我们可视化结果:
plot_abs_cols = ['Close','Hi3', 'Lo3','clg','flr','rg_ch','rg']
plot_abs_style = ['k', 'ro', 'go', 'kv', 'k^','b:','b--']
y2_abs = ['rg']
plot_rel_cols = ['rClose','rH3', 'rL3','rclg','rflr','rrg_ch','rrg']
plot_rel_style = ['grey', 'ro', 'go', 'yv', 'y^','m:','m--']
y2_rel = ['rrg']
df[plot_abs_cols].plot(secondary_y= y2_abs,figsize=(20,8),
title = str.upper(ticker)+ ' Absolute',# grid=True,
style=plot_abs_style)
df[plot_rel_cols].plot(secondary_y=y2_rel,figsize=(20,8),
title = str.upper(ticker)+ ' Relative',# grid=True,
style=plot_rel_style)
df[plot_rel_cols + plot_abs_cols].plot(secondary_y=y2_rel + y2_abs,figsize=(20,8),
title = str.upper(ticker)+ ' Relative & Absolute',# grid=True,
style=plot_rel_style + plot_abs_style) 我们将绘制三个独特的图表:绝对、相对和综合。因此,我们将绝对和相对参数存储在列表中。话不多说,这是三个图表:
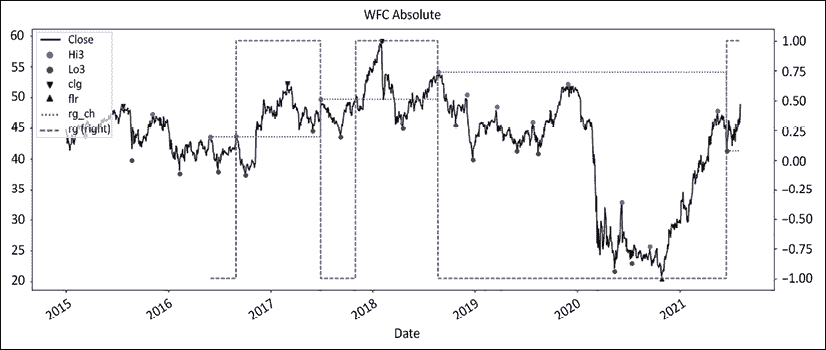
图 12.2:富国银行的绝对波动和上下限制度
制度一直是行为的一个公平预测因素,特别是在后半段。2020 年的涨势直到 2021 年出现摆动低点才导致制度变化。接下来,我们将绘制相对系列:
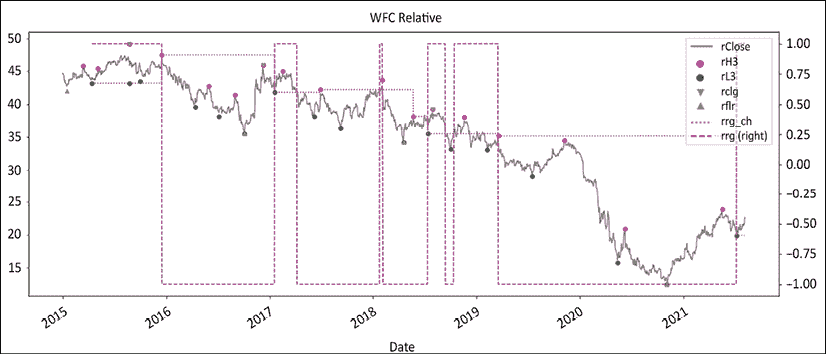
图 12.3:富国银行的波动和地板/天花板制度相对于标普 500 指数
正如我们在前面的章节中所看到的,当丑闻爆发时,富国银行受到了重创,直到 2021 年才恢复。制度看起来表面上更加紧张。一路上有相当多的看涨假阳性。它们的范围和持续时间都很短。请注意,价格线上方的红点如何构成良好的入场点和/或移动止损水平。当然,打印波动高点和发现它们之间存在一小段滞后时间。最后,我们将两者合并成一个图表:
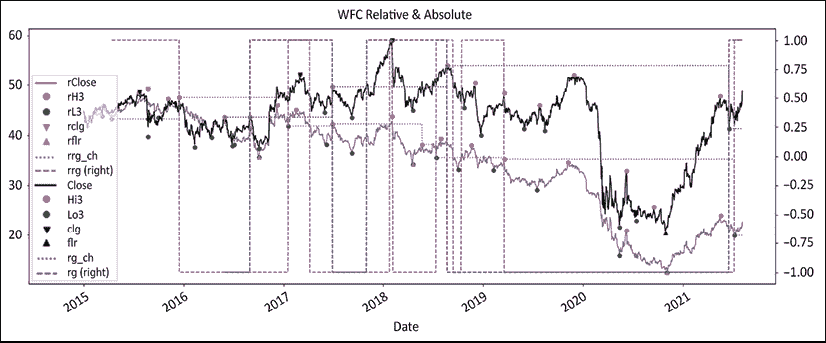
图 12.4:富国银行的波动和地板/天花板制度绝对和相对于标普 500 指数
这最后一个图表看起来比前两个更加嘈杂。请注意地板/天花板方法如何准确地命中了 2016 年 9 月的丑闻。相对系列在整个期间始终领先于制度。
让我们再次使用图表制度函数来可视化绝对和相对图表:
ma_st = ma_mt = ma_lt = lt_lo = lt_hi = st_lo = st_hi = 0
rg_combo = ['Close','rg','Lo3','Hi3','Lo3','Hi3','clg','flr','rg_ch']
_c,rg,lo,hi,slo,shi,clg,flr,rg_ch=[rg_combo[r] for r in range(len(rg_combo))]
graph_regime_combo(ticker,df,_c,rg,lo,hi,slo,shi,clg,flr,rg_ch,ma_st,ma_mt,ma_lt,lt_lo,lt_hi,st_lo,st_hi)
rrg_combo = ['rClose','rrg','rL3','rH3','rL3','rH3','rclg','rflr','rrg_ch']
_c,rg,lo,hi,slo,shi,clg,flr,rg_ch=[rrg_combo[r] for r in range(len(rrg_combo))]
graph_regime_combo(ticker,df,_c,rg,lo,hi,slo,shi,clg,flr,rg_ch,ma_st,ma_mt,ma_lt,lt_lo,lt_hi,st_lo,st_hi) 以下是绝对值中绘制的制度:深色表示亏损期:
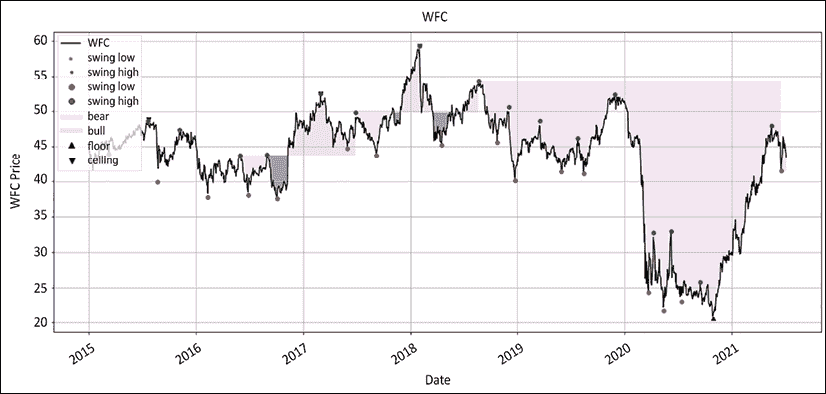
图 12.5:富国银行在绝对值中着色的地板/天花板制度
接下来,让我们看看相对系列:
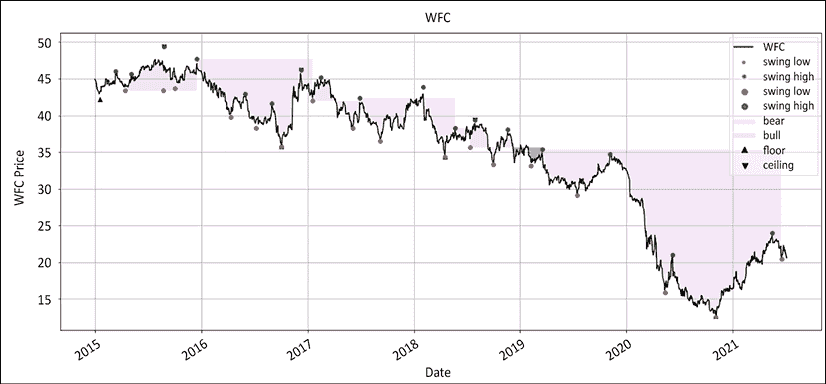
图 12.6:富国银行在相对于标普 500 指数的地板/天花板制度着色
这最后一个图表真正展示了过去几年中表现不佳的程度。有许多识别趋势耗尽的方法,例如随机指标、相对强弱指标、移动平均收敛/散开指标、德马克指标以及后者的祖先,斐波那契回调。其中大部分技术归结为将混乱带入秩序。不幸的是,普及并不一定表示统计上的稳健性。如果你仍然相信使用预测性技术分析,你可以将订单分成两部分,第一部分使用预测性分析,第二部分在确认预测准确后添加。当它奏效时,你的平均执行会稍微好一些,并且当它不奏效时,你不会破产。
最重要的是,记住一个人的崩溃对另一个人来说是“低吸买入”。这是空头市场;市场不合作。利用熊市反弹和空头挤压来确定你的入场时机。当每个人都卖光时出局。通过减少仓位和/或重设止损来尽量降低风险。
摘要
整本书都指向了这一章和下一章。总之,为了总结我们在前面章节中所涵盖的所有内容,请切换到相对系列并根据市场制度进行分类。在高点之后进入空头,或者在低点之后进入多头。设定一个在波动之上或之下的止损价格和一个目标价格以降低风险。使用你的成本、止损和风险预算来计算你的头寸规模。
为每个策略的每个多/空侧保留单独的风险预算。尊重你的止损并尊重你的策略。保持一个干净的交易日志。在路上完善你的授权。
在下一章中,我们将研究你工具箱中最被低估的工具之一:你的投资组合管理系统。成为一名选股专家和一名投资组合经理是两种需要不同技能的不同工作。在你选择管理投资组合的那一刻,你不再是一个股票骑手。你已经成为了一个稳定的马主。你的工作不是骑在马背上冲过终点线。你的工作是培育(或淘汰)那些在可预见的未来能(或不能)冲过终点线的马匹。
一个相对的多空投资组合与传统的仅多头投资组合甚至绝对的多空投资组合是完全不同的生物。到目前为止你所使用的任何工具都迫切需要进行根本性的升级。如果你想在市场上有一线生机,你需要一套钢铁侠的装备。
第十三章:投资组合管理系统
“托托,我觉得我们不再是在堪萨斯了。” – 多萝西,《绿野仙踪》
我在对冲基金世界的第一份工作是为一家管理资金不到 500 万美元的初创对冲基金建立和维护一个名为投资组合管理系统(PMS)的系统。创始人认为风险管理不是业务的一种装饰,而是业务本身。快进到现在,他们已经成为日本替代空间的主导者。在本章中,我们将继续上两章的工作,并介绍一个定制的 PMS,它可以显示投资组合的风险可视化。
为了说明健壮的 PMS 的重要性,让我们联系一下我们在本书中探讨过的一些概念。在第一章,《股票市场游戏》中,我们设定了市场是一个无限、复杂的随机游戏的背景。在第六章,《交易优势是一个数字,这就是公式》中,我们揭示了神奇、神秘和神话般的交易优势公式。在第八章,《头寸大小:在资金管理模块中赚钱》中,我们证明了头寸大小决定了绩效。我们在第十一章,《多空工具箱》中学到了我们工具箱中的工具。所以,我们知道头寸大小是关键因素,但我们还不知道哪些头寸会奏效,然而我们必须在管理风险敞口的同时保持正面期望。每天重复这个过程几年,以吸引并保留投资者。
在我的职业生涯中,朋友和同事们慷慨地展示了他们的 PMS。生存直接与他们 PMS 的质量相关。并不是每个拥有正确系统的人都成功了。但每一个没有系统的经理最终都崩溃了。
PMS 就像飞行仪器。任何新手都可以在晴朗的天空中驾驶飞机。仪器的存在是为了防止起飞和在夜间着陆、在雾中和湍流中的坠毁。没有仪器,不是每个人都能回家。市场并非一直是晴朗和顺利的。事情会出乎意料地变得丑陋。情绪确实会使我们偏离轨道。用执行交易员的术语来说,如果你没有一个坚实的 PMS,你怎么能说自己是一个投资组合经理呢?使用 Python 构建定制的 PMS 值得一本书,甚至是自己专门的文学流派,因此超出了本书的范围。然而,在本章中,我们将简要讨论一些基本概念和指导原则,希望能指导你:
- 糟糕的投资组合管理系统的症状
- 你的投资组合管理系统就是你的钢铁侠战衣
- 自动化枯燥的事情
- 构建一个健壮的投资组合管理系统
您可以通过以下链接访问本章中所有图像的彩色版本:static.packt-cdn.com/downloads/9781801815192_ColorImages.pdf。您还可以通过该书的 GitHub 存储库访问本章的源代码:github.com/PacktPublishing/Algorithmic-Short-Selling-with-Python-Published-by-Packt。
导入库
对于本章和本书的其余部分,我们将使用pandas,numpy,yfinance和matplotlib库。所以,请记得首先导入它们:
# Import Libraries
import pandas as pd
import numpy as np
import yfinance as yf
%matplotlib inline
import matplotlib.pyplot as plt 低效的投资组合管理系统的症状
当谈到改善业绩时,一个好的 PMS 是最低的果实。在 2005 年,我加入了一个对 PMS 非常丑陋的对冲基金,看着它可能会导致脑损伤。我立即进行了改进,至少是为了消除健康风险。突然间,问题儿童们就像圣诞树上的花环一样亮了起来。短线股票的波动性减少了,懒惰的狗,和不被赏识的赛犬都被迅速处理了。波动性下降了。表现更加一致了。夏普比率提高了。投资者注意到了。资产管理规模(AUM)增长了。就是这么简单。
每个人都想知道赢家的"秘密酱",但这是一个领域,"阿尔法挑战者"的经验可能会帮助我们避免无意中重复同样的错误。这是一个简单的练习,将帮助您判断您的系统是否需要升级。效率低下的 PMS 表现出以下一个或多个症状。
无效的资本配置
尽管投资组合经理们喜欢向公众展示出一个奥林匹克半神的形象,但只需几句话就可以将他们拉回现实:
- “好人最后完成”:一些股票取得了令人印象深刻的回报,但由于头寸较小而未被注意到。这些往往是探索性的小头寸。它们获得高回报,但由于没有足够的规模而贡献不佳。
- “肥猫不捉老鼠”:一些大头寸之所以有所贡献,只是因为它们的重量巨大。这是 PMS 的一个经典问题。它直接与上述问题相关。这些往往是占用了太多空间但回报微薄的高信仰度想法。
- “曾经我们是勇士”:这些是现在免费吃白食的老牌贡献者。这些是一段时间以来变得陈旧的想法。它们有很多嵌入式的历史贡献,但不再产生收益。我们在第七章,提升您的交易优势中已经解决了这种情况。
监测不足的风险检测
一个需要密切关注的关键指标是流动性,以避免“加州酒店综合症”。换句话说,你不能清算的东西就不是你拥有的,而是拥有你的。流动性是熊市的货币。是否有头寸不能在不产生严重市场冲击的情况下清算?以下是一个重新计算头寸规模所需天数以便以平均交易量的一部分退出的函数。对于一个空头卖方来说,最可怕的事情就是看到熊市反弹获得动力,并意识到你的头寸过大以至于无法幸免于难。很少有比被迫清仓更糟糕的感觉,只见其在熊市海啸后重新开始向下滑落。
一个简单的风险度量是将头寸规模重新表述为以平均交易量的一部分进行清算所需天数。以下代码简单地计算了平均交易量的一部分。头寸数量除以此分数:
ticker = 'UNG' #ETF natural gas
volume = yf.download(tickers= ticker,start= '2021-01-01', end = None, interval = "1d",group_by = 'column', auto_adjust = True, prepost = True,treads = True, proxy = None)['Volume']
def days_liquidation(quantity,volume,window,fraction):
avg_vol_fraction = volume.rolling(window).mean()* fraction
return round(quantity/avg_vol_fraction,2)
quantity = 100000
window = 63
fraction =0.01
days_liquidation(quantity,volume,window,fraction)[-1] 这产生了类似以下的输出:
3.52 我们可以生成图 13.1所示的图表:
plt.plot(days_liquidation(quantity,volume,window,fraction)) 我们从2021 年初开始下载了交易量数据。该函数将一个固定百分比乘以交易量的移动平均值。这一股数除以交易量的一部分:0.01,或1%。这个值是任意的,且故意设得很低以展示原理。在实践中,5-10%是合理的阈值。截至2021 年 6 月底,如果订单量不超过平均交易量的1%,则大约需要5 天时间来清算整个头寸。我们将系列中的最后一个数字打印出来并绘制了移动平均线:
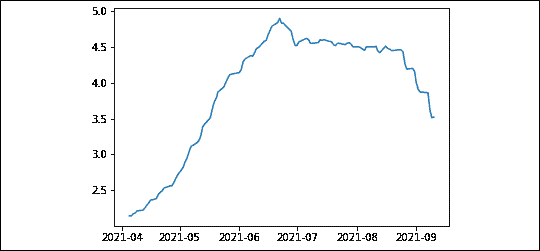
图 13.1: 以 3 个月平均交易量的 1%进行清算所需天数
上图显示流动性并非静态。最初,对于交易量占平均日交易量1%的头寸,清算大约需要2 天。随着流动性减少,清算所需天数增加到5 天,然后又回落到3.5 天左右。当价格朝着你不利的方向波动时,一周就仿佛是永恒。因此,应该密切监视流动性。
市场冲击是由于大宗交易引起的价格不利变动。当头寸超过日交易量的5%时,市场冲击就会开始。如果头寸量在日交易量的10%下持续时间超过5 天,那么就预期会产生一些严重的市场冲击。此外,熊市反弹的激烈程度不容小觑。在尝试从困境中解脱时,你将心理上处于被动状态。因此,始终要密切监视流动性,并在交易量减少时减少头寸。
高波动性
拥挤的空头有较高的平均借贷利用率。流动性将变薄,波动性将增加,回报将恶化。利用率或借贷费用的热度图是非常有价值的工具。在发布日期,遗憾的是没有免费的资源可以提供借贷利用率。作为一个捷径,当借贷费用大大高于平均水平时,可以假设受欢迎。处理拥挤的空头的最简单方法是随着受欢迎程度的提高减少头寸规模。再次强调,制定简单的规则,例如,如果利用率上升到 40%以上,则将头寸减半,每增加 10%再减半。到达 60%的利用率时,曝光将是原始规模的 25%。这只是一些思考。
爆炸并不显眼:人们希望感觉良好。在市场上,做自己感觉良好的事情很少是最赚钱的行动。处于风险中的股票必须在视觉上促使管理者采取行动。股票很少出现意外爆炸。它们通常会发出微妙的信号表明事情不如预期发展。
高相关性
多元化的目标是降低相关性。相关性很难避免。在第四章,多空方法:绝对和相对中,我们介绍了相对系列以减少与基准的相关性。然而,焦点从确定绝对顶部或底部转移到捕捉行业轮换,并相应地分配资产。投资组合内的相关性很难消除。坦率地说,我不知道如何在实践中做到这一点。迄今为止,我也没有遇到成功的方法。
曝光管理不善
有几种不同类型的曝光,可以通过以下方式表明投资组合管理不善:
- 净曝光:当投资组合的净曝光与当前的看涨/看跌观点不匹配时。这在熊市阶段尤其明显,当环境愁云密布时,净曝光仍然指向残存的乐观情绪。投资组合认知失调是指曝光不反映管理者的说法。
- 净贝塔暴露:大多数不足系统中缺乏真正的市场敏感性。当管理者只关注净曝光时,他们将低方向性与净市场敏感性混为一谈。净贝塔进一步超越净曝光,以反映对市场的敏感性。
- 市值暴露:做空期货是对冲的垃圾食品。正如我们在第十一章,多空对冲工具箱中看到的那样,小盘股和大盘股具有不同的风险特征。当市场整体情绪乐观时,小盘股表现良好,而大盘股是更安全的选择。净市值暴露反映了投资组合的整体乐观情绪。
- 总曝光:在好时机杠杆过多,在坏时机现金过多。总曝光是最容易减少或增加风险的杠杆。犹豫不决时,崩溃杠杆是最简单的风险政策。
- 交易所暴露:按市值和交易所暴露的暴露解释了很多好/坏的表现。正如我们在 第四章,长/短期方法论:绝对和相对 中所看到的,纳斯达克多年来一直优于标普 500。多年的轻松赚钱奖励了投机问题和那些押注于它们的人。当钱容易赚时,就容易赚钱。没有牛市曾经提高过任何人的智商。
总的来说,在资产管理行业,投资回报率最高的是定制的 PMS。随着信息差的缩小,市场参与者争先恐后地寻找优势。如果你能比你的同行更早地发现和解决问题,你就能获得可持续的竞争优势。
你的投资组合管理系统就是你的钢铁侠服
“你知道,我经常被问到的问题是,“托尼,你怎么在你的衣服里上厕所?” [长时间的停顿] 就是这样。” – 托尼·斯塔克,《钢铁侠》
托尼·斯塔克可能是个天才、亿万富翁、花花公子和慈善家。真正赋予他超能力的是他定制的钢铁侠服。他没有在 Macy’s 的货架上买他的衣服。他在车库里摧毁了几辆兰博基尼,打造了一些独特增强他战斗风格的东西。同样,你的 PMS 就是你的钢铁侠服。它是你交易策略的延伸。它的唯一目的是帮助你在不确定性下做出交易决策。因为没有人像你一样交易,所以它需要高度定制化。
经典错误是购买昂贵的现成软件包,认为更多的信息会导致更好的交易决策。软件解决方案主要是由中后台人员为前台专业人员设计的报告工具。你的 PMS 是一个交易工具,而不是报告工具。Barra 因子分解或街头共识每股收益不会告诉你今天应该买入或卖空哪家公司的多少股票。信息转化为知识,而知识并不直接转化为技能。建立技能的关键是专注于直接导致行动的信息。
在实践中,系统整合几个月后,投资组合经理经常以低技术的 Excel 电子表格来管理他们的投资组合,这些电子表格从那些闪闪发光的玩具中获取数据。他们买了一辆兰博基尼去挑牛奶。因此,在你急于购买市场上最昂贵的玩具之前,这里有几个原则可以帮助你澄清自己的需求。信息必须根据四个原则组织:清晰、相关、简单和灵活。
清晰:绕过左脑
在压力下,你的杏仁核会释放化学物质,降低前额叶皮层或“思考大脑”的活动。你的思维能力会受到影响。你的 PMS 需要清晰度:信息必须组织得让问题迅速显现出来。其次,左脑无法处理数字的行和列。它慢慢的,每秒 5 到 7 位。它不会做关联。一切都变得模糊成无生机的数字汤。与此同时,右脑处理信息的速度快一百倍,寻找模式,并做关联。幸运的是,数据可视化是数据科学的新趋势。视觉线索能够绕过思考较慢的大脑。当决策涉及多个因素时,按照数字进行绘画有助于建立关联。例如,将你在投资领域内的位置可视化为热图会立即告诉你是否在正确的轨道上,并在每个行业内选择最佳策略。我们将在本章结束时查看投资组合热图。
另一个话题是警报。你是否曾想过为什么灾难警报是如此讨厌?如果《欢乐颂》宣布即将发生地震、海啸或火山喷发,人们可能不会感到同样的紧迫感。我们天生倾向于远离痛苦,向着愉悦之处前进。警报的存在是为了迫使最不情愿行动的人采取行动。当一个位置需要处理时,尽可能地让警报烦人。警报越烦人,解决问题的可能性就越大。最好的警报是你必须在执行日常任务之前手动确认的那些。例如:假设某只股票已达到止损位。如果设置了警报,你必须点击它才能继续查看你的投资组合,那么可能会发生两种情况。要么你会迅速解决问题,要么你会彻底避免使用这个工具。当正确的需求超过了赚钱的必要性时,我们内心的白痴就会更加努力地自我破坏。
经典错误之一是为每个风险因素都设立多个页面。这意味着用户必须在页面之间来回切换并做笔记。每增加一点摩擦力都会增加信息泄漏的可能性。飞行员不应该在飞机上上上下下地查看液压和燃油表是否一切正常。如果你想要将不同的风险联系起来,你需要将所有相关信息汇总到一页摘要中,以便在后续页面进行深入了解。可以把它想象成汽车或飞机的仪表板。你需要的所有信息都在你面前展示着。
将事物放在上下文中。左脑不能有效处理数字。295%的总暴露只是一个数字。当它在显示基准、总和净暴露以及表现的图表上绘制时,这个数字就在上下文中了。它是市场表现、你的位置以及随时间的结果表现的视觉呈现。一张图胜过千言万语。让我们回顾一下在第十一章,多空工具箱中看到的例子。我们从以下股票代码模拟了一个投资组合。我们假设从 2020 年 12 月 31 日到 2021 年 6 月期间没有交易:
# Chapter 13: Portfolio Management System
K = 1000000
lot = 100
port_tickers = ['QCOM','TSLA','NFLX','DIS','PG', 'MMM','IBM','BRK-B','UPS','F']
bm_ticker= '^GSPC'
tickers_list = [bm_ticker] + port_tickers
df_data= {
'Beta':[1.34,2,0.75,1.2,0.41,0.95,1.23,0.9,1.05,1.15],
'Shares':[-1900,-100,-400,-800,-5500,1600,1800,2800,1100,20800],
'rSL':[42.75,231,156,54.2,37.5,42.75,29.97,59.97,39.97,2.10]
}
port = pd.DataFrame(df_data,index=port_tickers)
port['Side'] = np.sign(port['Shares'])
start_dt = '2021-01-01'
end_dt = '2021-07-01'
price_df = round( yf.download(tickers= tickers_list,start= '2021-01-01',
end = '2021-07-01', interval = "1d", group_by = 'column',auto_adjust = True, prepost = True, treads = True, proxy = None)['Close'],2)
bm_cost = price_df[bm_ticker][0]
bm_price = price_df[bm_ticker][-1]
port['rCost'] = round(price_df.iloc[0,:].div(bm_cost) *1000,2)
port['rPrice'] = round(price_df.iloc[-1,:].div(bm_price) *1000,2)
port['Cost'] = price_df.iloc[0,:]
port['Price'] = price_df.iloc[-1,:] 在第十一章,多空工具箱中,我们处理了port数据框。这次,我们将使用price_df可视化曝光。我们首先计算基准收益。然后,我们将计算相对和绝对的长期和短期市值。
我们将计算绝对和相对的曝光和收益。
price_df['bm returns'] = round(np.exp(np.log(price_df[bm_ticker]/price_df[bm_ticker].shift()).cumsum()) - 1, 3)
rel_price = round(price_df.div(price_df['^GSPC'],axis=0 )*1000,2)
rMV = rel_price.mul(port['Shares'])
rLong_MV = rMV[rMV >0].sum(axis=1)
rShort_MV = rMV[rMV <0].sum(axis=1)
rMV_Beta = rMV.mul(port['Beta'])
rLong_MV_Beta = rMV_Beta[rMV_Beta >0].sum(axis=1) / rLong_MV
rShort_MV_Beta = rMV_Beta[rMV_Beta <0].sum(axis=1)/ rShort_MV
price_df['rNet_Beta'] = rLong_MV_Beta - rShort_MV_Beta
price_df['rNet'] = round((rLong_MV + rShort_MV).div(abs(rMV).sum(axis=1)),3)
price_df['rReturns_Long'] = round(np.exp(np.log(rLong_MV/rLong_MV.shift()).cumsum())-1,3)
price_df['rReturns_Short'] = - round(np.exp(np.log(rShort_MV/rShort_MV.shift()).cumsum())-1,3)
price_df['rReturns'] = price_df['rReturns_Long'] + price_df['rReturns_Short']
MV = price_df.mul(port['Shares'])
Long_MV = MV[MV >0].sum(axis=1)
Short_MV = MV[MV <0].sum(axis=1)
price_df['Gross'] = round((Long_MV - Short_MV).div(K),3)
price_df['Net'] = round((Long_MV + Short_MV).div(abs(MV).sum(axis=1)),3)
price_df['Returns_Long'] = round(np.exp(np.log(Long_MV/Long_MV.shift()).cumsum())-1,3)
price_df['Returns_Short'] = - round(np.exp(np.log(Short_MV/Short_MV.shift()).cumsum())-1,3)
price_df['Returns'] = price_df['Returns_Long'] + price_df['Returns_Short']
MV_Beta = MV.mul(port['Beta'])
Long_MV_Beta = MV_Beta[MV_Beta >0].sum(axis=1) / Long_MV
Short_MV_Beta = MV_Beta[MV_Beta <0].sum(axis=1)/ Short_MV
price_df['Net_Beta'] = Long_MV_Beta - Short_MV_Beta rel_price框架是price_df数据框除以基准收盘价乘以 1,000 的结果。我们使用连续系列,不重新调整到系列的开始。索引在开始时的值有 4 位小数。因此,我们将相对价格乘以 1,000 以获得更容易处理的数字。我们将价格乘以股份数,按持仓的符号汇总,然后求和以获得相对的长期和短期市值。由于没有交易,除了收益外,市值没有变化。因此,我们使用市值的日变化来计算累积收益。正如我们在第十一章,多空工具箱中看到的,总暴露使用绝对系列。这是实际的资产负债表使用情况。
我们将主要的曝光和收益绘制在一张图上。然后我们绘制相对系列:
price_df[['bm returns','Returns','Gross','rNet_Beta','rNet' ]].plot(
figsize=(20,8),grid=True, secondary_y=['Gross'],
style= ['r.-','k','g--','g-.','g:','b:','c','c:'],
title = 'bm returns, Returns, Gross, rNet_Beta, rNet')
price_df[['bm returns', 'Returns', 'rReturns', 'rReturns_Long',
'rReturns_Short']].plot(figsize=(20,8),grid=True,
style= ['r.-','k','b--o','b--^','b--v','g-.','g:','b:'],
title= 'bm returns, Returns, rReturns, rReturns_Long, rReturns_Short')
price_df[['bm returns','Returns','rReturns',
'rReturns_Long','rReturns_Short','Returns_Long', 'Returns_Short']].plot(
figsize=(20,8),grid=True,secondary_y=['Gross'],
style= ['r.-','k','b--o','b--^','b--v','k:^','k:v',],
title= 'Returns: benchmark, Long / Short absolute & relative')
price_df[['bm returns',
'rReturns_Long','rReturns_Short','Returns_Long', 'Returns_Short']].plot(
figsize=(20,8),grid=True,secondary_y=['Gross'],
style= ['r.-','b--^','b--v','k:^','k:v',],
title= 'Returns: benchmark, Long / Short absolute & relative') 我们将有四张图。第一张是"你是谁?"图表:
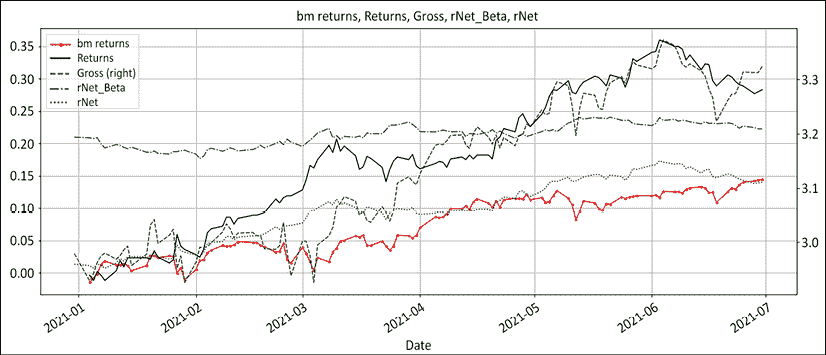
图 13.2:"你是谁"图表:市场回报和曝光
上面的图表是我个人最喜欢的。如果有一张图能总结一个经理的投资组合管理技能,那就是这张图。它展示了经理如何应对市场的挑战。基准市场回报是实线红色线,所有其他线都是经理的反应:
- 总暴露是虚线。杠杆是自信的直接体现。上升的总暴露显示了信心。
- 净暴露是虚线。净暴露象征着乐观情绪。上升的净暴露表明看涨情绪增长。由于投资组合的两边都表现不错,空头减少,而多头增值。这导致了净多头漂移。
- 净β是虚线。净β象征着风险偏好。当风险增加时,更多的投机性问题将出现在多头股票中,而防御性行业和股票将出现在空头。没有交易,所以净β只是市值演变的反映。
- 最后,实线黑线是回报。以这种方式管理曝光带来了这样的表现。
- 这张图表中唯一缺失的组件是净交易。将净多头/空头交易绘制成条形图,这将显示出响应。由于这个例子中没有交易,所以没有条形图。
接下来,让我们看看长头寸和空头寸如何影响绩效。我们最初的前提是,多空投资组合是两个相对头寸的总和。多头头寸必须胜过指数,而空头头寸必须落后于基准。这是它是如何实现的:
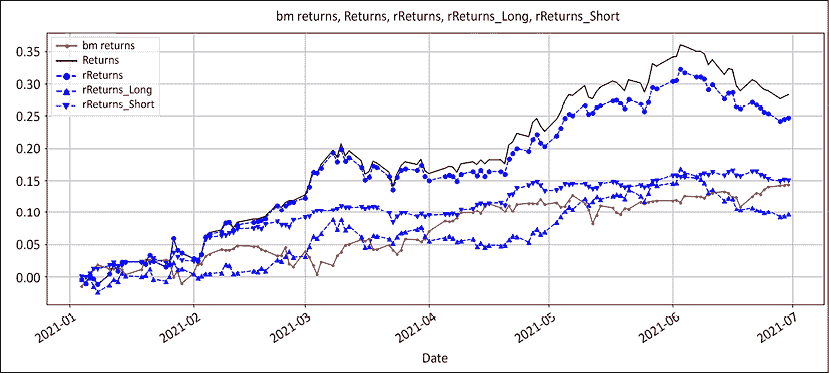
图 13.3:回报:基准、绝对、相对、多头和空头
在实践中,短时间内持续跑赢指数是极为罕见的。红色实线是基准。虚线蓝线是相对绩效,实线黑线是绝对绩效。
首先,多空绩效超过了指数。这是这本书将会得到的最接近虚构的部分。相对多头回报是向上的三角形。空头相对回报是向下的三角形。其次,请注意多头和空头相对回报与指数的接近程度。它们是超过指数的多余回报。将这与我们在《第四章》多空方法论:绝对和相对中看到的相对牛市或熊市中的股票数量相比较。它们在基准周围振荡。
要充分理解超额回报的含义,让我们将相对多头/空头回报与绝对回报进行比较:
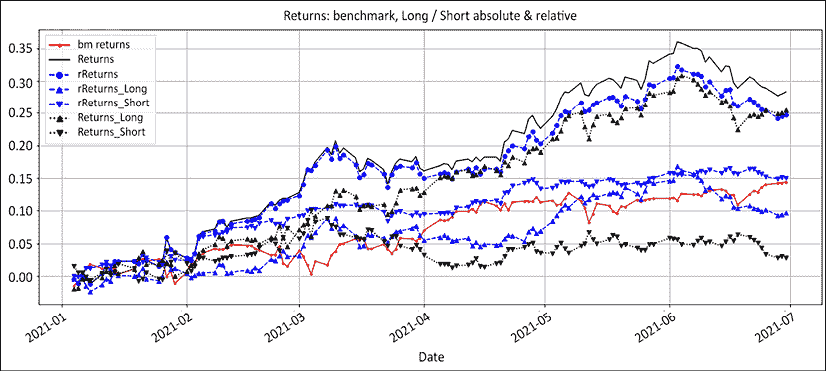
图 13.4:回报:基准、绝对、相对、多头和空头
这张嘈杂的图表显示了绝对多头和空头回报。这展示了一个原则,对许多绝对交易者来说仍然陌生。在牛市中从空头赚钱意味着尽可能少地亏损。保持平衡是一件好事。从你在熊市中的多头头寸来考虑一下。你不指望赚到任何钱,而且坦率地说,如果你的多头头寸不被清仓,你会感到高兴。
让我们删除绝对和相对净回报,集中关注多头和空头的绝对和相对回报,以强调这一点:
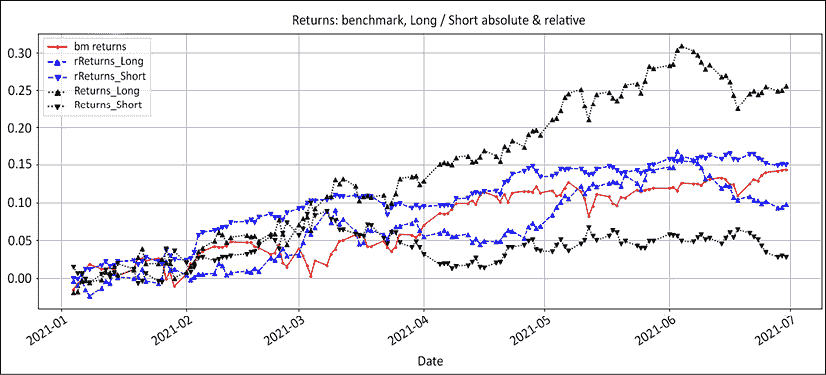
图 13.5:回报:基准、绝对、相对、多头和空头
用执行交易员的英语来说,在牛市中期望你的空头亏损。只需确保不让小伤口变成感染并使整个投资组合坏死。这是许多新手空头卖方犯的经典错误,他们经常缩小空头头寸。以下是这种三段论通常的推理方式:
- 多空领域是一项竞争激烈的运动。每一个基点的绩效都很重要。
- 这本短小的书正在泄漏阿尔法,金融黑话中意味着亏钱。
- 所以,让我们缩小空头头寸来止血阿尔法出血,并专注于多头。
这种思维方式通常会导致空头市场萎缩。这扩大了净暴露度,并增加了净贝塔。这直接增加了与市场的相关性和收益的波动性。这两个正是投资者愿意支付溢价以避免的。卖空是一种在不使用时会萎缩的肌肉。总之,专注于你的授权、你的暴露度以及相对于指数的超额收益。
关联性:钢铁侠自动收音机效应
尽管他的服装里有很多小工具,但你是否曾想过为什么托尼·斯塔克的钢铁侠装备中没有低科技的自动收音机?他还是 Stark Industries 的 CEO,也许他想知道市场专家对他的股价有什么看法。然而,在与坏人战斗时,倾听 CNBC 上的金融噪音显然是托尼·斯塔克无法承受的干扰。
钢铁侠自动收音机效应是市场参与者有时会引用人类对他们可以管理的股票数量的限制的原因。你的 PMS 并不在这里提供信息。它是你交易策略的延伸,这里是告诉你该做什么的地方。它将输出订单,这些订单要么来自你的策略信号,要么来自你的风险管理。你不需要知道你的夏普比率或共识 EPS 2 年后才能执行止损。你需要知道你的主要暴露度,以及根据你在第十一章,长/短工具箱中设计的授权来对冲你的投资组合需要交易多少股票。
每个人都有一个监视屏幕,显示他们的投资组合的情况。很少有市场参与者采取额外步骤构建一个交易屏幕,将他们的交易规则嵌入其中,并将信息处理成交易决策。
构建一个单独的交易表,每个交易决策都有一个列:止损,获利,时间退出,重新进入等等。让你的交易规则或投资流程在后台运行。当需要做出决策时,在相应的单元格中显示股票数量,否则留空。
例如,当一支股票达到了盈利目标时,只需打印出需要关闭的股票数量。
在第十一章,长/短工具箱中,我们进行了比例风险调整。首先,我们将重新发布代码。我们将展示调整前后的聚合数据。然后我们将打印出订单:
# Chapter 13: Portfolio Management System
adjust_long = adjust_short = -0.01
MV = port['Shares'] * port['Price']
port['Weight'] = round(MV.div(abs(MV).sum()), 3)
port['rR'] = (port['rCost'] - port['rSL'])
port['rRisk'] = -round(np.maximum(0,(port['rR'] * port['Shares'])/K), 4)
port['rRAR'] = round( (port['rPrice'] - port['rCost'])/port['rR'], 1)
port['rCTR'] = round(port['Shares'] * (port['rPrice']-port['rCost'])/ K,4)
port['CTR'] = round(port['Shares'] * (port['Price']-port['Cost'])/ K,4)
port_long = port[port['Side'] > 0]
port_short = port[port['Side'] < 0]
pro_rata_long = port_long['rRisk'] / (port_long['rRisk'].sum() * port_long['rRAR'])
risk_adj_long = (abs(adjust_long) * pro_rata_long * K / port_long['rR'] // lot) * lot
shares_adj_long = np.minimum(risk_adj_long, port_long['Shares'])*np.sign(adjust_long)
pro_rata_short = port_short['rRisk'] / (port_short['rRisk'].sum() * port_short['rRAR'])
risk_adj_short = (abs(adjust_short) * pro_rata_short * K / port_short['rR'] // lot)*lot
shares_adj_short = np.maximum(risk_adj_short,port_short['Shares'])*np.sign(adjust_short)
port['Qty_adj'] = shares_adj_short.append(shares_adj_long)
port['Shares_adj'] = port['Shares'] + port['Qty_adj']
port['rRisk_adj'] = -round(np.maximum(0,(port['rR'] * port['Shares_adj'])/K),4)
MV_adj= port['Shares_adj'] * port['Price']
rMV_adj = port['Shares_adj'] * port['rPrice']
port['Weight_adj'] = round(MV_adj.div(abs(MV_adj).sum()),3)
port.loc[port['Shares_adj'] != 0,'Shares_adj'] 我们决定在长空两侧风险上等比例更新,减少-0.01,这相当于将风险降低了 1%。比例调整的排序关键是相对风险调整收益。相对风险单位的相对表现越低,调整就越大。调整后的股票和需要交易的数量是:
QCOM -1500
NFLX -200
DIS -500
PG -5100
IBM 500
BRK-B 2100
UPS 800
F 19200 你可以调整 adjust_long 和 adjust_short 变量的值,以适应你想要进行的风险调整(正或负)。添加一个价格列,另一个订单类型列,这就是系统必须输出的全部内容。每次喝一杯葡萄酒时,你不需要了解关于苹果酸乳酸发酵和桶中陈年的任何知识。
简单:复杂性是一种懒惰的表现
当你为生命而战时,你不需要一身沉重、闪闪发光的阅兵服。你需要斯巴达装甲——轻便、有效、经过战斗考验。
当你开始构建你的 PMS 时,你会忍不住想要添加更多的花哨功能。复杂性是一种懒惰的表现。只构建必要的东西,而不是好看的东西。例如,如果你交易移动平均线,你不需要四列价格、第一和第二个移动平均线以及股票。这是信息过载。你只需要一列股数或交易的权重,只有当条件满足时才显示。
你的 PMS 不需要重复发明轮子。Prime 经纪人通过他们的 API 提供了许多你所需要的信息。例如,性能计算是一种资源浪费。它涉及公司行为,如股票拆分、股利和认购/赎回。这些都纳入修改后的 Dietz 时间序列性能计算,按股份类别分开。与此同时,你的 prime 经纪人将在每天早餐前通过他们的 API 提供净资产值(NAV)和性能计算。
经验法则是只显示会导致决策的信息,直接的,比如要进行的交易,或者间接的,比如开放风险水平。另一个例子是借用利用率。你的系统为 x 千股的做空交易。你开始流口水,但是系统也显示借用利用率大约是 40%。交易较小的规模可能更明智。
灵活性:信息不能转化为决策
使用 PMS 配备经理就像给近视眼人士配眼镜。起初,他们很高兴能看到任何东西。然后,他们开始要求更多。视力带来视野。一个经典错误是在弄清楚你需要什么之前购买昂贵的软件。软件解决方案是由中后台人员为前台战士构思的。这往往导致前台人员只使用软件功能的一小部分,并在 Excel 上构建一个独立的工具。
另一个错误是从一开始就将所有内容硬编码。您的 PMS 将随着您的发展而发展。每一个小的改进都会产生连锁反应。当人们开始锻炼时,晚上出去喝酒的前景就不那么吸引人了。没有人像你一样交易,所以没有人能够替代你。它不必完美,但必须首先工作。开始时,使其廉价和灵活。Excel、Google 表格、R、Python 和 Jupyter 笔记本足以开始实验。理论上,C++比 Python 更快。在实践中,C++比 Python 慢几个月,甚至几年。Python 是新的 Excel!
自动化枯燥的事情
所有市场参与者都想成为下一个吉姆·西蒙斯。没有人想要照顾管道。人们想做激动人心的事情。他们想要拿出十亿美元的创意来交易。他们不想照顾风险管理。本节介绍了一些耗时且最终令人厌烦的流程的示例,应该进行自动化以及原因。
交易对账是将下单与执行交易进行对账的过程。它显示了哪些交易以什么价格进行了。这是少数几个会让人觉得阅读税法是一项激动人心事业的任务之一。然而,这是一项重要的任务,因为这些数据被用于执行交易分析。价格是否击败了成交量加权平均价格(VWAP)?
更新 PMS 很无聊,但并不像看起来那么容易。公司会经历各种各样的公司行动,比如股息和股票拆分。这些公司行动会影响数据的一致性。这需要注意细节。
自动化交易订单路由。绝大多数算法交易员都已经自动化执行。毕竟,如果系统说“买这么多”或“卖那么多”,那就这么做。执行是自动的。自主交易员仍然在全面信任他们的系统方面有困难。如果系统输出一个荒谬的数字怎么办?或者,市场做了这个或那个?好吧,信任是建立的。一个简单的解决方案是默认进行自动执行,除非有手动覆盖。
构建健壮的投资组合管理系统
以下是构建健壮的 PMS 的快速逐步指南。请记住,每个 PMS 都需要高度定制。你正在构建自己的钢铁侠战衣。因此,本指南将保持相当模糊。
- 将您的策略形式化为简单的交易决策:买入/卖出、数量、价格。交易序列相当简单。绘制一个流程图并填充序列。
- 添加源自风险管理的决策:流动性、权重、借用利用率、净β值和总体和净敞口。我们之前看到整个投资组合的风险降低。
- 从您的监控工具中,为每个交易决策创建一个单独的交易表格,每个交易决策在单独的列中。这种极简监控工具对于大型投资组合尤其有效。
- 在你的视野之外,嵌入你的交易规则。这可以是表格最右侧的列,Excel 中的宏,以及 Python 中的脚本。你只需要你盘子上的香肠,而不是整个烹饪过程的视觉。
- 在你的视野中,使用股票代码作为行索引,使用交易决策作为列索引来索引你的投资组合。
- 决策可视化:如果触发了交易决策,请在相应的单元格中打印股票数量或权重,并将其他所有内容留空。这会增加视觉冲击力。
- 从基于规则的操作开始小规模尝试:止损或获利都是低成本高影响的决策。
- 随着时间的推移,建立一个综合工具。将你的交易历史添加到直接计算头寸大小。一个强大的工具是将你的投资组合监控工具和观察清单整合到市场热图中。
- 丢掉汽车收音机。随着你完善流程,你会有添加单元格和列的冲动。再努力一点,尽量保持尽可能多的内容在后台运行。
在 第十一章,多空工具箱 中,有一张扩展表格,其中列出了要交易的股票。我们按方向(多头或空头)和相对风险调整收益 (rRAR) 重新排序数据框。我们切片数据框以仅显示相关列:
port = port.sort_values(by=['Side','rRAR'])
port_cols = ['Side','Beta','Shares_adj','Weight', 'Weight_adj','CTR','rCTR',
'rRAR','rRisk','rRisk_adj']
port[port_cols] 一切看起来都像这样:
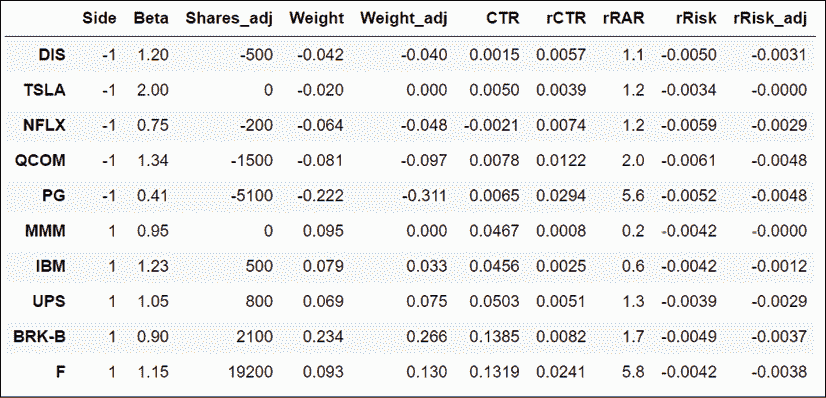
让我们将上述表格放在投资组合管理框架中加以解释。
- 让我们首先将投资组合的一侧和对市场的敏感性可视化。我们想知道高/低 beta 位于哪一侧。我们是看涨还是看跌?
- 接下来,我们想要做出我们的交易决策。我们不需要最终在最后一列得出结论。我们想要知道首先要做什么。然后,我们可以检查系统是否按预期工作。
- 我们已经知道调整会减少我们的总敞口。现在,我们想知道每个头寸的调整前后影响。这些是“权重”和“权重调整”列。
- 风险纯粹主义者会在权重旁边显示风险的影响。我们的资产配置重点是按绩效比例减少风险而不是按权重。我们首先想要修剪表现不佳的头寸。因此,我们显示贡献,“CTR”,“rCTR”以及相对风险调整收益,“rRAR”。
- 最后,我们显示“rRISK”和“rRisk_adj”之前和之后的相对风险。最后一列显示了股票级别的投资组合剩余风险。
这个概念框架已经被简化到其最基本的组成部分。每一列中的每个数字都有其存在的理由。即使是办公室纸牌和俄罗斯方块大师的顶尖人物,也就是合规和风险官员,也会同意这是根据行业中最严格的风险管理指南编制的,用俚语说就是“我不知道,看起来似乎不会炸掉农场”。
唯一的问题是,我们的左脑半球不具备处理这些信息的能力。这是一个大脑无法处理的单调数字汤,更不用说与之相关了。有意识的大脑每秒只能处理 5 +/-2 位信息。用执行交易员的术语来说,当你的眼睛从表格的一端移到另一端时,你的大脑已经忘记了它一开始需要寻找的东西。另一个不好的消息:你并不特殊。这种情况发生在每个人身上。此外,雷曼,如果你能记住这个表格,你会在二十一点桌上数牌时过得更好。
真正的问题是,我们如何将这种单调的数字汤转化为我们一瞥就能准确处理的东西?原来我们的大脑配备了右脑半球。它以闪电般的速度处理信息,将看似随机的数据片段进行关联。唯一的缺点是,数据需要重新打包成这种大脑能够处理的格式。用执行交易员的术语来说,让我们按照数字来绘制。我们将使用一个名为 Styler 的内置构造器。只需几行代码就能返回一个多功能的热图。这几行代码可以循环利用,以绘制市场回报的快速有效的热图。
perf_cols= ['rCTR', 'CTR','rRisk', 'rRisk_adj','rRAR']
desc_cols= ['Side','Beta','Weight','Weight_adj',]
sort_cols = ['Side','rRAR']
asc = [True,True]
port[port_cols].sort_values(by = sort_cols,ascending= asc).style.background_gradient(
subset = desc_cols, cmap = 'viridis_r').background_gradient(
subset = perf_cols, cmap = 'RdYlGn').format('{:.5g}') 我们运行一个多空头投资组合。出现在空头的数字通常带有负号。我们不希望我们的潜意识将空头仓位与负收益联系起来。因此,我们将描述性字段(desc_cols)与与绩效相关的字段(perf_cols)分离开来。您想要在单个数据框上显示的颜色图数量越多,就越简单地将它们堆叠在一起。
sort_values 方法被添加以进一步增强热图的多功能性。这个单调的数字汤只有在正确绘制时才会变得生动起来。西斯廷教堂的壁画可能看起来神圣,但它们背后只是一堵墙。
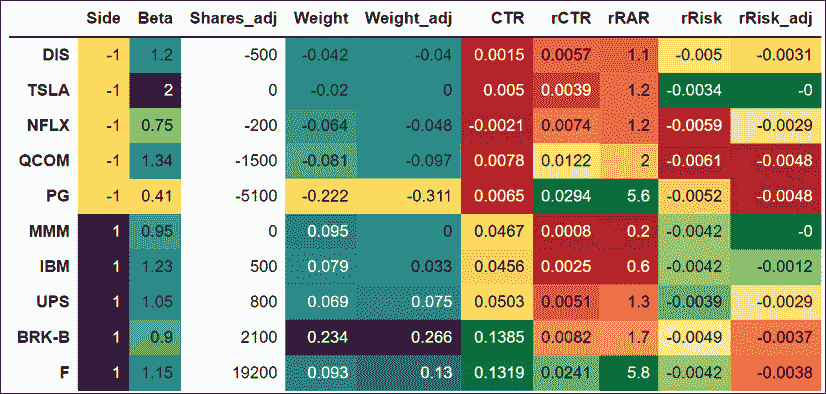
图 13.6:投资组合热图
这个热图按照多空头(long/short)和相对风险调整回报(rRAR)排序。数字被绘制后变得生动起来。这张表格可以进一步简化。再次指导原则是尽可能少地显示干扰。让我们注意到这个显示的改进:
- 首先,数量、成本、价格和止损列被隐藏起来。它们是重要信息,但不是关键信息。不关键的信息可能会分散注意力。如果触发了止损,您需要知道需要交易多少股票。在那之前,它们只是干扰。
- 在这个例子中,前五列严格是描述性的。要交易的股票数量没有额外的含义。因此,它不需要上色。
- 其他描述性列采用黄色到绿松石到紫色的颜色代码。侧面立即显示我们正在处理书的哪一面。贝塔显示我们是如何被斧头砍的。看起来大部分低贝塔的东西都在空头方向上。调整后的风险仍然很高的股票仍然是调整前/调整后最大的权重。
- 其他所有内容都采用了三色图案的颜色编码,从红色到橙色到绿色,表示每个单元格的健康状态或权重。这个系统有效。
这里有其他可视化想法。构建 PMS 时,专注于对你有共鸣的内容。这是你的钢铁侠装甲。有些人喜欢表格,并使用热图。有些人对图表有反应。在下一个代码块中,我们将以条形图的形式可视化信息。我们将使用不同的键对数据进行排序,以展示不同的视角。
bar_cols= ['Weight', 'Weight_adj','rRisk','rRisk_adj','rCTR', 'CTR','rRAR','Side']
col_style= ['lightgrey','dimgrey','lightcoral','red',
'forestgreen','lightseagreen','yellowgreen','whitesmoke']
sort_keys= ['Weight_adj','rCTR']
sec_y=['rRAR','Side']
sort= ['rRAR']
port[bar_cols].sort_values(by=sort).plot(kind='bar',
grid=True,figsize=(20,5),
secondary_y=sec_y,color=col_style, title= 'PORT, by '+str(sort))
sort= ['Weight_adj','rRAR']
port[bar_cols].sort_values(by=sort).plot(kind='bar',
grid=True,figsize=(20,5),
secondary_y=sec_y,color=col_style, title= 'PORT, by '+str(sort))
sort= ['Side','rRisk_adj']
port[bar_cols].sort_values(by=sort).plot(kind='bar',
grid=True,figsize=(20,5),
secondary_y=sec_y,color=col_style, title= 'PORT, by '+str(sort)) 代码中没有什么特别的,除了颜色代码。把颜色编码交给一个法国人,那个传说中的猪会有浅粉色和薰衣草色的口红,让人联想到夏季的莫奈花园。
我们使用了三个不同的排序键来展示三个不同的视角下的数据:
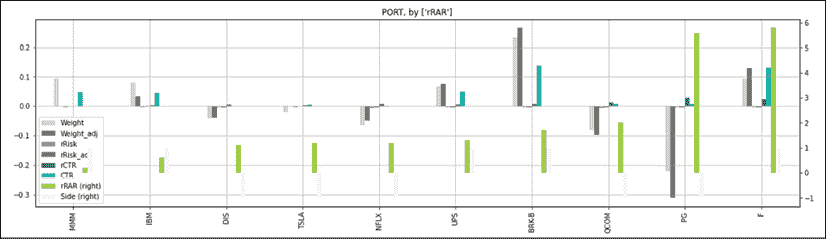
图 13.7:按“rRAR”排序的投资组合
排序键是 rRAR,无论侧面如何都按升序排序。总体而言,图表的前半部分被多头占据。牛市的潮水会推高所有股票。尽管空头书籍尚未产生大量绝对资金,但已经实现了巨额回报。
其次,我们按“权重”和“rRAR”排序:
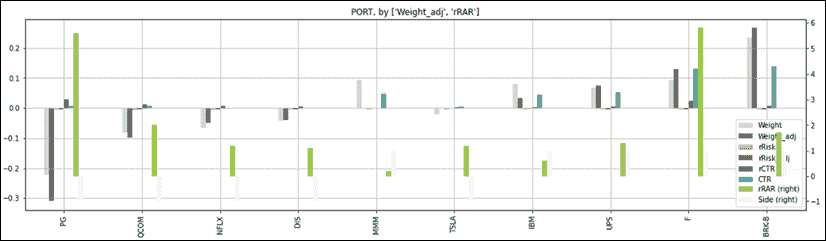
图 13.8:按“权重”和“rRAR”排序的投资组合
这将所有东西重新分类为长/短期书籍,并为投资组合提供“rRAR”视角。最重要的职位是最好的风险调整贡献者,这与该投资组合管理策略一致。
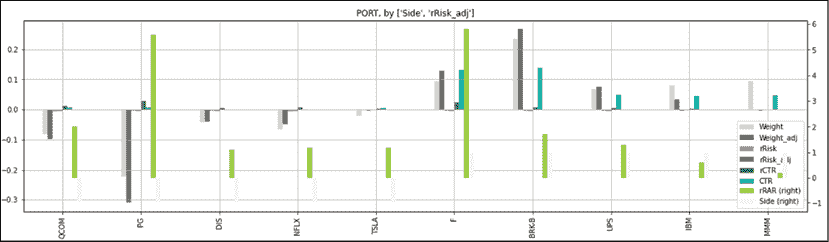
图 13.9:按“侧面”和“rRisk_adj”排序的投资组合
这按“侧面”和相对风险后调整的“rRisk_adj”排序。这将产生一个两面的图表,左边是空头,右边是多头。结果与该策略一致。表现最佳者拥有更大的权重和更高的风险。接下来,让我们看一下市场参与者最喜欢的跟踪工具:观察名单。
除非嵌入了一些交易决策,否则观察名单是惰性的。我们都错过了一些交易,只是因为我们没有关注。以下是一种逐步方法,可以确保您保持健康的可操作观察名单:
- 输入股票代码、目标水平、入场日期
- 自动化触发器:当价格达到目标水平时,打印要交易的股票数量,否则留空
- 淘汰陈旧的想法:定期按日期排序。每次审查后删除陈旧的想法
- 每天对列表进行一次排序
这个半自动化的观察清单将使您与竞争对手区分开来。市场参与者很少花时间正式化他们的计划。当其他人试图在恐惧中即兴发挥时,您将以合理的计划出现。
这个过程可能需要几周,甚至几个月,具体取决于您的正式化水平。定制的 PMS 将带来以下积极效果:
- 它将迫使您正式化您的过程。如果投资是一个过程,那么自动化就是合乎逻辑的结论。这个原则自工业革命开始就经受了时间的考验。计算机处理的发展已经加强了它。
- 它将揭示您的过程中的缺陷。自由裁量和半自动化的市场参与者有盲点。
- 它将减少情绪干扰:在监视屏幕上做出决策是 100%自由裁量的。运行算法是 100%系统化的。您将处于这个谱系的某个位置。
- 它减轻了压力:当所有决策在后台运行并且只在需要时显示时,您不需要担心并且采取预防性措施。
- 它释放了精神带宽,可以管理更多的名称或花更多时间思考。当您的系统与您的过程保持一致时,您将花费更少的时间担心,换句话说,消耗精神带宽,更多时间规划。
当您是一名分析师或业余零售交易者时,您是一名股票骑师。您支持一些股票。您参与其中,但您不会因为挂着百万美元的股票而难以入眠。当您选择成为投资组合经理时,您不再是一名骑师。您承担了稳定大师的责任。您的工作是在您的马厩中优化有限的资源。这就是为什么您需要一个 PMS。
概要
投资于 PMS 是您将会做出的最高回报投资决策。没有 PMS,您可能会偶尔运气好地挑选到一些正确的股票,但与稳健的 PMS 的纪律性一比,这些都不值一提。在感染坏疽并限制绩效之前,您将会补充优胜者并处理肉体创伤。您将成为更加纪律性的市场参与者。风险管理不是业务的一部分。它就是业务。投资组合经理不是从事挑选股票的业务。他们的业务是用他们要么挑选要么放弃的股票来管理风险。随着时间的推移,小的好处会复利,并使您与仍然相信挑选股票是成功关键的竞争对手有所区别。当您的投资组合管理成为您的钢铁侠装备时,您将与认为他们在交易一个系统的人竞争。
卖空是有风险的。市场不合作。然而,选择不学习卖空更加危险。你可能选择永远不参与卖空,但无论如何,学会卖空只会丰富你的技能库。我们真诚地希望这本书能引发关于卖空的讨论。这个领域已经被妖魔化和研究不足太久了。我们希望已经给予它应有的荣誉。
我们开始通过消除关于卖空的谬论,并解释为什么长期思维在卖空方面通常会失败。我们继续通过研究相对序列和制度定义来进行想法生成。这也涉及到头寸大小和风险管理。这本书的最后一部分远不止于长/短期投资组合的构建。它是关于设计一种投资者感兴趣的产品——无关联低波动回报——使用长/短期交易工具。
你将在附录,股票筛选中找到一个自动化的股票筛选工具,我们希望你会觉得有用!
附录:股票筛选
这个附录提供了一个股票筛选工具,它将让你把我们在本书中学到的一切付诸实践。它解决了市场参与者最迫切的问题:创意生成。我们将在标普 500 指数的所有成分股上建立一个筛选器。
事件的顺序如下:
- 从其维基百科页面下载所有当前标普 500 指数的成分股。
- 从 Yahoo Finance 批量下载 OHLCV 价格数据。我们将降低级别以处理每只股票。
- 计算调整后的相对系列。
- 计算制度——突破口、海龟、移动平均线(简单移动平均线(SMA)和指数移动平均线(EMA)),以及地板/天花板——在绝对和相对系列上。将有一个选项将每只股票保存为 CSV 文件。
- 创建包含每只股票最后一行的字典,并附加一个列表,从中我们将创建一个数据框。
- 总结制度方法并对数据框进行排序。你将有一个选项将这个最后一行数据框保存为 CSV 文件。
- 将包含维基百科信息的原始数据框与最后一行数据框合并。你将有一个选项将此数据框保存为 CSV 文件。
- 生成按行业和子行业分类的热力图。
- 如果你想要特别可视化任何股票,将会有一个单独的股票下载、处理和可视化模块在筛选的最后。
你可以通过以下链接访问本章节所有图像的彩色版本:
static.packt-cdn.com/downloads/9781801815192_ColorImages.pdf。你也可以通过本书的 GitHub 存储库访问本章的源代码:github.com/PacktPublishing/Algorithmic-Short-Selling-with-Python-Published-by-Packt。
导入库
我们首先导入标准库。pathlib已经被注释掉了。如果你想要在计算机或服务器上的某个地方保存 CSV 文件,你可以使用诸如pathlib或os之类的库。
# Appendix
# Data manipulation
import pandas as pd
import numpy as np
from scipy.signal import *
# import pathlib
# Data download
import yfinance as yf
# Data visualisation
%matplotlib inline
import matplotlib.pyplot as plt 当然,这是极具影响力的——我们将利用随后的片刻理智的消失迅速进行下一步。
定义函数
以下是本书中一直使用的函数。你可以在 GitHub 上找到完整版本。函数通常会以它们出现的章节为前缀。筛选将包括绝对和相对系列,因此我们需要相对函数。这将跟随经典的制度定义函数:
# CHAPTER 5: Regime Definition
### RELATIVE
def relative(df,_o,_h,_l,_c, bm_df, bm_col, ccy_df, ccy_col, dgt, start, end,rebase=True):
#### removed for brevity: check GitHub repo for full code ####
### RELATIVE ###
def lower_upper_OHLC(df,relative = False):
if relative==True:
rel = 'r'
else:
rel= ''
if 'Open' in df.columns:
ohlc = [rel+'Open',rel+'High',rel+'Low',rel+'Close']
elif 'open' in df.columns:
ohlc = [rel+'open',rel+'high',rel+'low',rel+'close']
try:
_o,_h,_l,_c = [ohlc[h] for h in range(len(ohlc))]
except:
_o=_h=_l=_c= np.nan
return _o,_h,_l,_c
def regime_args(df,lvl,relative= False):
if ('Low' in df.columns) & (relative == False):
reg_val = ['Lo1','Hi1','Lo'+str(lvl),'Hi'+str(lvl),'rg','clg','flr','rg_ch']
elif ('low' in df.columns) & (relative == False):
reg_val = ['lo1','hi1','lo'+str(lvl),'hi'+str(lvl),'rg','clg','flr','rg_ch']
elif ('Low' in df.columns) & (relative == True):
reg_val = ['rL1','rH1','rL'+str(lvl),'rH'+str(lvl),'rrg','rclg','rflr','rrg_ch']
elif ('low' in df.columns) & (relative == True):
reg_val = ['rl1','rh1','rl'+str(lvl),'rh'+str(lvl),'rrg','rclg','rflr','rrg_ch']
try:
rt_lo,rt_hi,slo,shi,rg,clg,flr,rg_ch = [reg_val[s] for s in range(len(reg_val))]
except:
rt_lo=rt_hi=slo=shi=rg=clg=flr=rg_ch= np.nan
return rt_lo,rt_hi,slo,shi,rg,clg,flr,rg_ch
# CHAPTER 5: Regime Definition
#### regime_breakout(df,_h,_l,window) ####
def regime_breakout(df,_h,_l,window):
#### removed for brevity: check GitHub repo for full code ####
#### turtle_trader(df, _h, _l, slow, fast) ####
#### removed for brevity: check GitHub repo for full code ####
#### regime_sma(df,_c,st,lt) ####
#### removed for brevity: check GitHub repo for full code ####
#### regime_ema(df,_c,st,lt) #### 地板/天花板方法论计算量更大。因此,它需要有自己的沙盒:
# CHAPTER 5: Regime Definition
#### hilo_alternation(hilo, dist= None, hurdle= None) ####
def hilo_alternation(hilo, dist= None, hurdle= None):
i=0
while (np.sign(hilo.shift(1)) == np.sign(hilo)).any(): # runs until duplicates are eliminated
#### removed for brevity: check GitHub repo for full code ####
#### historical_swings(df,_o,_h,_l,_c, dist= None, hurdle= None) ####
def historical_swings(df,_o,_h,_l,_c, dist= None, hurdle= None):
reduction = df[[_o,_h,_l,_c]].copy()
reduction['avg_px'] = round(reduction[[_h,_l,_c]].mean(axis=1),2)
highs = reduction['avg_px'].values
lows = - reduction['avg_px'].values
reduction_target = len(reduction) // 100
# print(reduction_target )
#### removed for brevity: check GitHub repo for full code ####
#### cleanup_latest_swing(df, shi, slo, rt_hi, rt_lo) ####
def cleanup_latest_swing(df, shi, slo, rt_hi, rt_lo):
'''
removes false positives
'''
# latest swing
shi_dt = df.loc[pd.notnull(df[shi]), shi].index[-1]
s_hi = df.loc[pd.notnull(df[shi]), shi][-1]
slo_dt = df.loc[pd.notnull(df[slo]), slo].index[-1]
s_lo = df.loc[pd.notnull(df[slo]), slo][-1]
len_shi_dt = len(df[:shi_dt])
len_slo_dt = len(df[:slo_dt])
#### removed for brevity: check GitHub repo for full code ####
#### latest_swings(df, shi, slo, rt_hi, rt_lo, _h, _l, _c, _vol) ####
def latest_swing_variables(df, shi, slo, rt_hi, rt_lo, _h, _l, _c):
'''
Latest swings dates & values
'''
shi_dt = df.loc[pd.notnull(df[shi]), shi].index[-1]
slo_dt = df.loc[pd.notnull(df[slo]), slo].index[-1]
s_hi = df.loc[pd.notnull(df[shi]), shi][-1]
s_lo = df.loc[pd.notnull(df[slo]), slo][-1]
#### removed for brevity: check GitHub repo for full code ####
#### test_distance(ud, bs, hh_ll, vlty, dist_vol, dist_pct) ####
def test_distance(ud,bs, hh_ll, dist_vol, dist_pct):
#### removed for brevity: check GitHub repo for full code ####
#### ATR ####
def average_true_range(df, _h, _l, _c, n):
atr = (df[_h].combine(df[_c].shift(), max) - df[_l].combine(df[_c].shift(), min)).rolling(window=n).mean()
return atr
#### ATR ####
#### retest_swing(df, _sign, _rt, hh_ll_dt, hh_ll, _c, _swg) ####
def retest_swing(df, _sign, _rt, hh_ll_dt, hh_ll, _c, _swg):
rt_sgmt = df.loc[hh_ll_dt:, _rt]
#### removed for brevity: check GitHub repo for full code ####
#### retracement_swing(df, _sign, _swg, _c, hh_ll_dt, hh_ll, vlty, retrace_vol, retrace_pct) ####
def retracement_swing(df, _sign, _swg, _c, hh_ll_dt, hh_ll, vlty, retrace_vol, retrace_pct):
if _sign == 1: #
retracement = df.loc[hh_ll_dt:, _c].min() - hh_ll
#### removed for brevity: check GitHub repo for full code ####
# CHAPTER 5: Regime Definition
#### regime_floor_ceiling(df, hi,lo,cl, slo, shi,flr,clg,rg,rg_ch,stdev,threshold) ####
def regime_floor_ceiling(df, _h,_l,_c,slo, shi,flr,clg,rg,rg_ch,stdev,threshold):
#### removed for brevity: check GitHub repo for full code #### 让我们将这段难以消化的代码分成两个简单的函数,swings()和regime()。我们所需要做的就是传递relative参数以获取绝对或相对系列。
def swings(df,rel = False):
_o,_h,_l,_c = lower_upper_OHLC(df,relative= False)
if rel == True:
df = relative(df=df,_o=_o,_h=_h,_l=_l,_c=_c, bm_df=bm_df, bm_col= bm_col, ccy_df=bm_df,
ccy_col=ccy_col, dgt= dgt, start=start, end= end,rebase=True)
_o,_h,_l,_c = lower_upper_OHLC(df,relative= True)
rt_lo,rt_hi,slo,shi,rg,clg,flr,rg_ch = regime_args(df,lvl,relative= True)
else :
rt_lo,rt_hi,slo,shi,rg,clg,flr,rg_ch = regime_args(df,lvl,relative= False)
df= historical_swings(df,_o,_h,_l,_c, dist= None, hurdle= None)
df= cleanup_latest_swing(df,shi,slo,rt_hi,rt_lo)
ud, bs, bs_dt, _rt, _swg, hh_ll, hh_ll_dt = latest_swing_variables(df, shi,slo,rt_hi,rt_lo,_h,_l, _c)
vlty = round(average_true_range(df,_h,_l,_c, n= vlty_n)[hh_ll_dt],dgt)
dist_vol = d_vol * vlty
_sign = test_distance(ud,bs, hh_ll, dist_vol, dist_pct)
df = retest_swing(df, _sign, _rt, hh_ll_dt, hh_ll, _c, _swg)
retrace_vol = r_vol * vlty
df = retracement_swing(df, _sign, _swg, _c, hh_ll_dt, hh_ll, vlty, retrace_vol, retrace_pct)
return df
def regime(df,lvl,rel=False):
_o,_h,_l,_c = lower_upper_OHLC(df,relative= rel)
rt_lo,rt_hi,slo,shi,rg,clg,flr,rg_ch = regime_args(df,lvl,relative= rel)
stdev = df[_c].rolling(vlty_n).std(ddof=0)
df = regime_floor_ceiling(df,_h,_l,_c,slo, shi,flr,clg,rg,rg_ch,stdev,threshold)
return df
# df[rg+'_no_fill'] = df[rg]
return df 这个筛选也允许对个别股票进行精彩的可视化。 要实现这一点,请运行 graph_regime_combo() 函数:
# CHAPTER 5: Regime Definition
### Graph Regimes ###
def graph_regime_combo(ticker,df,_c,rg,lo,hi,slo,shi,clg,flr,rg_ch,
ma_st,ma_mt,ma_lt,lt_lo,lt_hi,st_lo,st_hi):
'''
https://www.color-hex.com/color-names.html
ticker,df,_c: _c is closing price
rg: regime -1/0/1 using floor/ceiling method
lo,hi: small, noisy highs/lows
slo,shi: swing lows/highs
clg,flr: ceiling/floor
rg_ch: regime change base
ma_st,ma_mt,ma_lt: moving averages ST/MT/LT
lt_lo,lt_hi: range breakout High/Low LT
st_lo,st_hi: range breakout High/Low ST
'''
#### removed for brevity: check GitHub repo for full code #### 下面的两个函数尚未在书中提及。 使用它们,我们需要提取单个股票数据并将其聚合成一个数据框。 yf_droplevel() 函数从 batch_download 中获取多指数数据框的单个代码的 OHLC 列,并创建一个 OHLCV 数据框:
def yf_droplevel(batch_download,ticker):
df = batch_download.iloc[:, batch_download.columns.get_level_values(1)==ticker]
df.columns = df.columns.droplevel(1)
df = df.dropna()
return df 此函数插入到一个循环中,该循环将运行 batch_download 的长度。 last_row_dictionary(df) 函数将数据框中的最后一行创建为一个字典:
def last_row_dictionary(df):
df_cols = list(df.columns)
col_dict = {'Symbol':str.upper(ticker),'date':df.index.max().strftime('%Y%m%d')}
for i, col_name in enumerate(df_cols):
if pd.isnull(df.iloc[-1,i]):
try:
last_index = df[pd.notnull(df.iloc[:,i])].index[-1]
len_last_index = len(df[:last_index]) - 1
col_dict.update({col_name + '_dt': last_index.strftime('%Y%m%d')})
col_dict.update({col_name : df.iloc[len_last_index,i]})
except:
col_dict.update({col_name + '_dt':np.nan})
col_dict.update({col_name : np.nan})
else:
col_dict.update({col_name : df.iloc[-1,i]})
return col_dict 首先,我们列出列。 其次,我们用代码和日期填充它们,使每一行都能唯一识别。 第三,我们使用 enumerate 迭代返回索引和列名。 如果最后一行包含缺失值,我们将向列名添加 _dt 并查找最后一个出现的索引。 如果最后一行包含值,我们只需将列名添加为键和值。
这个字典将附加一个最后一行字典的列表。 然后,我们将从此列表创建一个数据框。 另一种方法是为每只股票创建一个数据框并进行追加,这种方法效果很好,但稍微耗时一些。
控制面板
在笔记本中散布的变量是错误的来源。 在处理数据之前,所有参数、变量、网站、列表和布尔值都集中在一个地方。 这是您可以在其中调整设置的地方:
website = 'https://en.wikipedia.org/wiki/List_of_S%26P_500_companies'
params = ['2014-12-31', None, 63, 0.05, 0.05, 1.5, 2,5,2.5,3]
start,end,vlty_n,dist_pct,retrace_pct,threshold,dgt,d_vol,r_vol,lvl= [params[h] for h in range(len(params))]
rel_var = ['^GSPC','SP500', 'USD']
bm_ticker, bm_col, ccy_col = [rel_var[h] for h in range(len(rel_var))]
window = 100
st= fast = 50
lt = slow = 200
batch_size = 20
show_batch = True
save_ticker_df = False
save_last_row_df = False
save_regime_df = False
web_df_cols = ['Symbol','Security','GICS Sector','GICS Sub-Industry']
regime_cols = ['rg','rrg',
'smaC'+str(st)+str(lt),'smar'+str(st)+str(lt), 'boHL'+str(slow),
'borr'+str(slow),'ttH'+str(fast)+'L'+str(slow),'ttr'+str(fast)+'r'+str(slow)]
swings_cols = ['flr_dt','flr','clg_dt', 'clg', 'rg_ch',
'Hi'+str(lvl)+'_dt','Hi'+str(lvl),'Lo'+str(lvl)+'_dt','Lo'+str(lvl),
'rflr_dt', 'rflr', 'rclg_dt', 'rclg', 'rrg_ch',
'rH'+str(lvl)+'_dt','rH'+str(lvl),'rL'+str(lvl)+'_dt','rL'+str(lvl) ]
symbol_cols = ['Symbol','date','Close']
last_row_df_cols = symbol_cols+['score']+regime_cols+swings_cols 我们使用的网站是 S&P500 的维基百科网页。 参数如下:
-
start:yfinance下载开始日期 -
end:yfinance下载结束日期 -
vlty_n: 持续时间,用于平均真实范围和标准偏差计算 -
dist_pct:test_distance()函数中的变量 -
retrace_pct:retracement_swing()函数中的变量 -
threshold: 用于地板/天花板制度定义的波动性单位 -
dgt:round()函数中的小数位数 -
d_vol:test_distance()函数中的波动性单位 -
r_vol:retracement_swing()函数中的变量 -
lvl: 指示应使用哪些摆动水平来计算制度定义—Hi2/Lo2 还是 Hi3/Lo3
rel_var 参数解释如下:
-
bm_ticker: 基准的 Yahoo Finance 代码 -
bm_col: 基准列的名称 -
ccy_col: 货币名称 -
window、st、fast、lt、slow: 突破和移动平均值的变量 -
batch_size: 从yfinance下载的批量大小 -
show_batch: 布尔值,显示下载的股票 -
save_ticker_df: 布尔值,提供保存个别股票数据框的选项 -
save_last_row_df: 布尔值,提供保存最后一行数据框的选项 -
save_regime_df: 布尔值,提供保存最后一行数据框的选项 -
web_df_cols: 要从原始维基百科数据框中显示的列 -
regime_cols: 重新排序的制度定义列 -
swings_cols: 地板/天花板列 -
symbol_cols:描述性字段,Symbol,date,Close -
last_row_df_cols:最后一行数据帧有 50 多列。 这将列数减少到最小。
数据下载和处理
我们将从维基百科下载股票列表开始。 这使用了我们在第四章中看到的强大的pd.read_html方法,Long/Short Methodologies: Absolute and Relative:
web_df = pd.read_html(website)[0]
tickers_list = list(web_df['Symbol'])
tickers_list = tickers_list[:]
print('tickers_list',len(tickers_list))
web_df.head() tickers_list可以通过填写tickers_list[:]的括号部分来截断。
现在,这就是发生动作的地方。 引擎室中有几个嵌套的循环。
- 批量下载:这是高级别循环。 OHLCV 以一系列批次的多索引数据帧下载。 迭代次数是股票清单长度和批量大小的函数。 505 个组成部分除以 20 的批量大小是 26(最后一批为 6 个股票长)。
- 删除级别循环:这将多索引数据帧分解为单个股票 OHLCV 数据帧。 迭代次数等于批量大小。 制度在此级别处理。
- 绝对/相对处理:有 2 个通过。 第一遍处理绝对系列的数据。 变量在最后重置为相对系列,然后在第二遍中相应处理。 有一个选项将股票信息保存为 CSV 文件。 最后一行字典在第二遍结束时创建。
接下来,让我们一步一步地进行过程:
- 基准下载收盘价和货币调整。 这需要执行一次,因此它放在序列的开头。
- 数据帧和列表实例化。
- 循环大小:循环
tickers_list所需的迭代次数。 - 外循环:批量下载:
-
m,n:沿着batch_list的索引。 -
batch_download:使用yfinance下载。 - 打印批次股票,如果要查看股票名称,则带有布尔值
- 下载批量。
-
try/except:附加失败列表。
-
- 第二个循环:单股票删除级别循环:
- 降级到股票级别。
- 计算摆动和制度:
abs/rel。
- 第三个循环:绝对/相对系列:
- 在绝对系列中处理制度。
- 重置变量为相对系列并第二次处理制度。
- 提供布尔值以提供
save_ticker_df选项。 - 使用最后一行值创建字典。
- 附加字典行的列表。
- 从字典创建数据帧
last_row_df。 -
score列:绝对和相对制度方法的横向求和。 - 将
last_row_df与web_df合并。 - 布尔值
save_regime_df。
让我们发布代码,然后进行进一步的解释:
# Appendix: The Engine Room
bm_df = pd.DataFrame()
bm_df[bm_col] = round(yf.download(tickers= bm_ticker,start= start, end = end,interval = "1d",
group_by = 'column',auto_adjust = True, prepost = True,
treads = True, proxy = None)['Close'],dgt)
bm_df[ccy_col] = 1
print('benchmark',bm_df.tail(1))
regime_df = pd.DataFrame()
last_row_df = pd.DataFrame()
last_row_list = []
failed = []
loop_size = int(len(tickers_list) // batch_size) + 2
for t in range(1,loop_size):
m = (t - 1) * batch_size
n = t * batch_size
batch_list = tickers_list[m:n]
if show_batch:
print(batch_list,m,n)
try:
batch_download = round(yf.download(tickers= batch_list,start= start, end = end,
interval = "1d",group_by = 'column',auto_adjust = True,
prepost = True, treads = True, proxy = None),dgt)
for flat, ticker in enumerate(batch_list):
df = yf_droplevel(batch_download,ticker)
df = swings(df,rel = False)
df = regime(df,lvl = 3,rel = False)
df = swings(df,rel = True)
df = regime(df,lvl = 3,rel= True)
_o,_h,_l,_c = lower_upper_OHLC(df,relative = False)
for a in range(2):
df['sma'+str(_c)[:1]+str(st)+str(lt)] = regime_sma(df,_c,st,lt)
df['bo'+str(_h)[:1]+str(_l)[:1]+ str(slow)] = regime_breakout(df,_h,_l,window)
df['tt'+str(_h)[:1]+str(fast)+str(_l)[:1]+ str(slow)] = turtle_trader(df, _h, _l, slow, fast)
_o,_h,_l,_c = lower_upper_OHLC(df,relative = True)
try:
last_row_list.append(last_row_dictionary(df))
except:
failed.append(ticker)
except:
failed.append(ticker)
last_row_df = pd.DataFrame.from_dict(last_row_list)
if save_last_row_df:
last_row_df.to_csv('last_row_df_'+ str(last_row_df['date'].max())+'.csv', date_format='%Y%m%d')
print('failed',failed)
last_row_df['score']= last_row_df[regime_cols].sum(axis=1)
regime_df = web_df[web_df_cols].set_index('Symbol').join(
last_row_df[last_row_df_cols].set_index('Symbol'), how='inner').sort_values(by='score')
if save_regime_df:
regime_df.to_csv('regime_df_'+ str(last_row_df['date'].max())+'.csv', date_format='%Y%m%d') last_row_list.append(last_row_dictionary(df)) 在第三次循环结束时发生,一旦每个个股都被完全处理完毕。这个列表会自动更新每个个股和每个批次。三次循环完成后,我们使用 pd.DataFrame.from_dict(last_row_list) 从这个字典列表创建 last_row_df 数据帧。将字典列表创建为数据帧并将其合并的过程比直接将其附加到数据帧稍快一些。score 列是所有区域方法的横向总和。然后按 score 按升序对最后一行数据帧进行排序。有保存日期版本的选项。regime 数据帧是通过将维基百科网络数据帧和最后一行数据帧连接而创建的。请注意,Symbol 列被设置为 index。同样,有保存日期版本的选项。
接下来,让我们用几个热图来可视化市场的情况。
热图
维基百科页面展示了 全球行业分类标准(GICS)部门和子行业的结构。我们将按以下方式汇总数据:
- 部门,用于自上而下的视角
- 子行业,用于自下而上的视角
- 最后,部门 和 子行业,以在每个部门内选择赢家和输家。
我们使用 .groupby() 方法并按 score 排序。然后我们使用 Styler 构造函数 .style.background_gradient() 根据数字绘制市场:
groupby_cols = ['score'] + regime_cols
sort_key = ['GICS Sector']
regime_df.groupby(sort_key)[groupby_cols].mean().sort_values(
by= 'score').style.background_gradient(
subset= groupby_cols,cmap= 'RdYlGn').format('{:.1g}') 热力图覆盖了所有区域方法,包括绝对和相对:
- score:股票级别所有方法的横向总和。
- rg:绝对的底部/顶部区域。
- rrg:相对的底部/顶部区域。
- smaC50200:移动平均线交叉 ST/LT 绝对。
- smar50200:移动平均线交叉 ST/LT 相对。
- bohl200:范围突破(200 天)。
- ttH50L200:绝对的对于菜鸟的乌龟 50/200(快速/慢速)。
- ttr50r200:相对的对于菜鸟的乌龟 50/200(快速/慢速)。
让我们看看它是什么样子的:
图 1:行业水平的区域分数热图
部门热图为市场提供了一个鸟瞰图。高度杠杆的部门,如金融、房地产和科技仍然处于金字塔顶部。与此同时,消费品行业等防御性行业落后。在撰写本文时,这个牛市仍然十分活跃。实际上就是这么简单。
然后我们深入到子行业:
sort_key = ['GICS Sub-Industry']
regime_df.groupby(sort_key)[groupby_cols].mean().sort_values(
by= 'score').style.background_gradient(
subset= groupby_cols,cmap= 'RdYlGn').format('{:.1g}') 这给了我们市场的一个像素化图片,较差表现的子行业位于顶部:
图 2:区域分数的子行业水平
标普 500 指数是一个广泛而深入的指数。 市场的这种细粒度图像显示了每个子行业目前的状况。 特别关注绝对/相对二元性。 记住,相对表现领先于绝对表现。 这就是您如何捕捉拐点并相应地建立或退出仓位,并等待其他人群的到来的方式。
这个详细的图像是信息与决策的经典例子。 这个热图将使您了解市场的情况。 但是,它的格式不够高效,不能让您根据信息采取行动。
这将我们带到最终的排序,按部门和子行业。
sort_key = ['GICS Sector','GICS Sub-Industry']
regime_df.groupby(sort_key)[groupby_cols].mean().sort_values(
by= ['GICS Sector','score']).style.background_gradient(
subset= groupby_cols,cmap= 'RdYlGn').format('{:.1g}') 这会生成一个热图,其中子行业按其行业内的升序排序。 与此同时,部门按字母顺序分类。
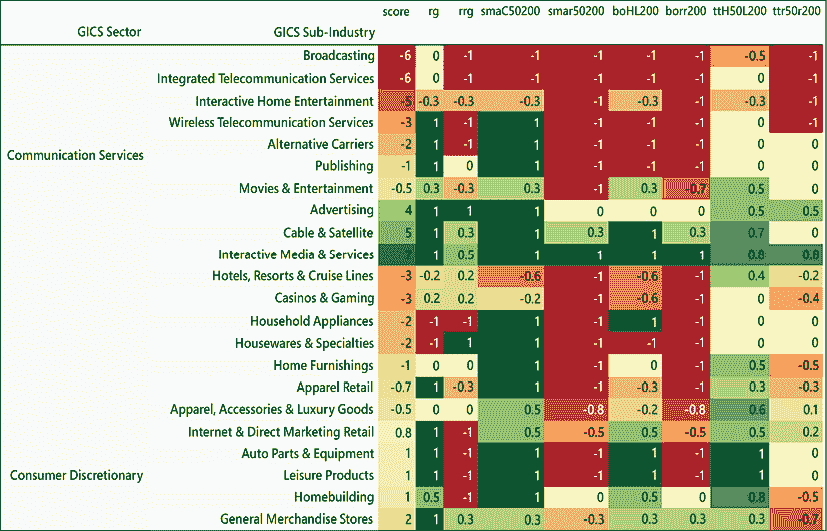
图 3:部门和子行业级别的热图
这个最终的热图提供了可行的信息。 子行业按其部门内的升序排名。 这允许在表现不佳者和表现良好者之间进行套利。 在不同部门和时间内重复这个过程,您将顺利地遵循部门轮换的实质。 这就是长/短 2.0 相对方法的本质。
个体流程
一旦筛选完成,您可能希望查看列表中的一些股票。 因此,笔记本的其余部分是关于在个别股票水平上进行数据可视化的。 输入一个股票代码,例如,ticker = 'FMC':
bm_ticker= '^GSPC'
bm_df = pd.DataFrame()
bm_df[bm_col] = round(yf.download(tickers= bm_ticker,start= start, end = end,interval = "1d",
group_by = 'column',auto_adjust = True, prepost = True,
treads = True, proxy = None)['Close'],dgt)
bm_df[ccy_col] = 1
ticker = 'FMC'
lvl = 2 # Try different levels to see
df = round(yf.download(tickers= ticker,start= start, end = end, interval = "1d", group_by = 'column',auto_adjust = True, prepost = True, treads = True, proxy = None),dgt)
df = swings(df,rel = False)
df = regime(df,lvl = 2,rel = False) # Try different lvl values (1-3) to vary absolute sensitivity
df = swings(df,rel = True) # Try different lvl values (1-3) to vary relative sensitivity
df = regime(df,lvl = 2,rel= True)
_o,_h,_l,_c = lower_upper_OHLC(df,relative = False)
for a in range(2):
df['sma'+str(_c)[:1]+str(st)+str(lt)] = regime_sma(df,_c,st,lt)
df['bo'+str(_h)[:1]+str(_l)[:1]+ str(slow)] = regime_breakout(df,_h,_l,window)
df['tt'+str(_h)[:1]+str(fast)+str(_l)[:1]+ str(slow)] = turtle_trader(df, _h, _l, slow, fast)
_o,_h,_l,_c = lower_upper_OHLC(df,relative = True)
df[['Close','rClose']].plot(figsize=(20,5),style=['k','grey'],
title = str.upper(ticker)+ ' Relative & Absolute') 这将打印出类似以下图表的内容:
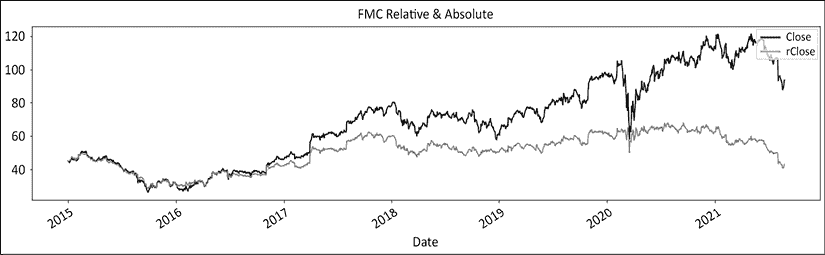
图 4:FMC 收盘价的绝对和相对系列
以下部分将数据绘制成三个图表:
# CHAPTER 5: Regime Definition
plot_abs_cols = ['Close','Hi'+str(lvl), 'clg','flr','rg_ch','rg']
# plot_abs_cols = ['Close','Hi2', 'Lo2','clg','flr','rg_ch','rg']
plot_abs_style = ['k', 'ro', 'go', 'kv', 'k^','b:','b--']
y2_abs = ['rg']
plot_rel_cols = ['rClose','rH'+str(lvl), 'rL'+str(lvl), 'rclg','rflr','rrg_ch','rrg']
# plot_rel_cols = ['rClose','rH2', 'rL2','rclg','rflr','rrg_ch','rrg']
plot_rel_style = ['grey', 'ro', 'go', 'kv', 'k^','m:','m--']
y2_rel = ['rrg']
df[plot_abs_cols].plot(secondary_y= y2_abs,figsize=(20,8),
title = str.upper(ticker)+ ' Absolute',# grid=True,
style=plot_abs_style)
df[plot_rel_cols].plot(secondary_y=y2_rel,figsize=(20,8),
title = str.upper(ticker)+ ' Relative',# grid=True,
style=plot_rel_style)
df[plot_rel_cols + plot_abs_cols].plot(secondary_y=y2_rel + y2_abs, figsize=(20,8), title = str.upper(ticker)+ ' Relative & Absolute', # grid=True,
style=plot_rel_style + plot_abs_style) 这将创建三个图表:绝对、相对和绝对与相对结合。 红/绿色的点是波动。 水平线是制度变革波动。 请注意,以下图表是在绝对和相对系列的 lvl 设置为 2 的情况下生成的。 您可以通过在绝对系列的 df = regime(df,lvl = 2,rel = False) 行和相对系列的 df = regime(df,lvl = 2,rel = True) 行中更改此值来增加或减少任一系列的灵敏度。
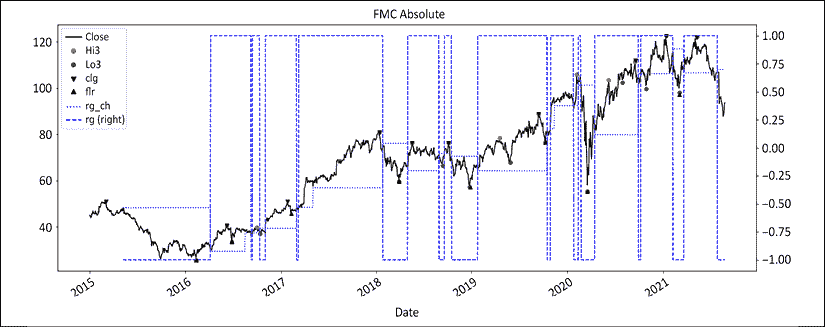
图 5:绝对图表,显示有虚线的底部/顶部制度
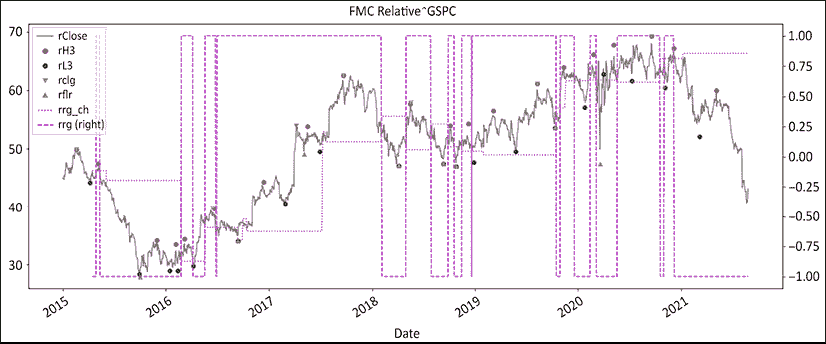
图 6:相对图表,显示有虚线的底部/顶部制度。 红/绿色的点是波动
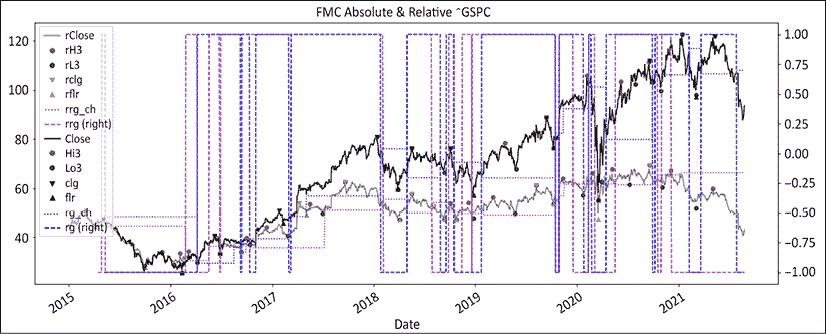
图 7:具有底部/顶部制度的绝对和相对图表
下一段代码块使用 graph_regime_combo() 进行美观的视觉呈现。 首先,这是绝对系列,然后是相对系列:
# CHAPTER 5: Regime Definition
ohlc = ['Open','High','Low','Close']
_o,_h,_l,_c = [ohlc[h] for h in range(len(ohlc))]
# ma_st = ma_mt = ma_lt = lt_lo = lt_hi = st_lo = st_hi = 0
mav = [fast, slow, 200]
ma_st,ma_mt,ma_lt = [df[_c].rolling(mav[t]).mean() for t in range(len(mav))]
bo = [fast, slow]
st_lo,lt_lo = [df[_l].rolling(bo[t]).min() for t in range(len(bo))]
st_hi,lt_hi = [df[_h].rolling(bo[t]).max() for t in range(len(bo))]
rg_combo = ['Close','rg','Lo3','Hi3','Lo3','Hi3','clg','flr','rg_ch']
_c,rg,lo,hi,slo,shi,clg,flr,rg_ch =[rg_combo[r] for r in range(len(rg_combo)) ]
graph_regime_combo(ticker,df,_c,rg,lo,hi,slo,shi,clg,flr,rg_ch,ma_st,ma_mt,ma_lt,lt_lo,lt_hi,st_lo,st_hi)
rohlc = ['rOpen','rHigh','rLow','rClose']
_o,_h,_l,_c = [rohlc[h] for h in range(len(rohlc)) ]
mav = [fast, slow, 200]
ma_st,ma_mt,ma_lt = [df[_c].rolling(mav[t]).mean() for t in range(len(mav))]
bo = [fast, slow]
st_lo,lt_lo = [df[_l].rolling(bo[t]).min() for t in range(len(bo))]
st_hi,lt_hi = [df[_h].rolling(bo[t]).max() for t in range(len(bo))]
rrg_combo = ['rClose','rrg','rL3','rH3','rL3','rH3','rclg','rflr','rrg_ch']
_c,rg,lo,hi,slo,shi,clg,flr,rg_ch =[rrg_combo[r] for r in range(len(rrg_combo)) ]
graph_regime_combo(ticker,df,_c,rg,lo,hi,slo,shi,clg,flr,rg_ch,ma_st,ma_mt,ma_lt,lt_lo,lt_hi,st_lo,st_hi) 这将生成以下两个图表。
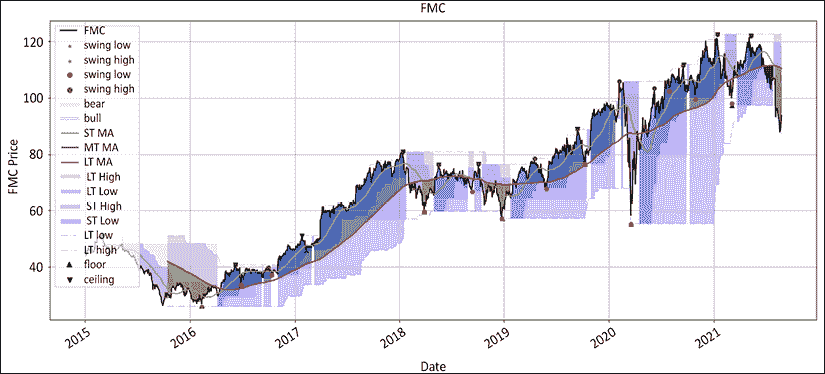
图 8:具有多种制度方法的绝对图表
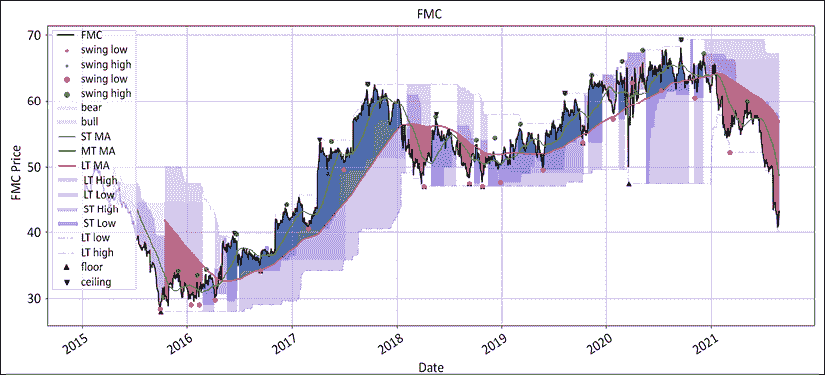
图 9:具有多种制度方法的相对图表
这是本书的结尾,也是你踏上空头交易广阔荒野的征程的开始。你现在拥有一张地图,将帮助你在空头市场的惊涛骇浪中航行。
作为告别的话,我们无情的行业忠实地遵循一条法则:供需关系。在长/空头交易中,长期股票选择者充足,而熟练的空头卖家却严重短缺。
当市场走低时,那些挺身而出的人,才会脱颖而出。