统一元数据:数据血缘
原创
背景介绍
数据血缘(Data Lineage):是数据治理中元数据管理领域下的一个子范畴,是数据的溯源过程,获得数据产生链路,发现数据的关联关系,目的是解决"数据的哲学三问":我是谁,我从哪里来,我到哪里去。
常见的数据血缘主要包括两大类:
- SQL血缘:基于SQL解析AST语法树,获取SQL的表、字段血缘;
- 业务血缘:常为基于任务调度DAG生成的数据流向关系;
业界方案
业界实现方案,开源项目数据血缘对比
项目 | 血缘能力 |
|---|---|
Apache Atlas | 基于Hive引擎实现,仅支持Hive血缘,支持类型限制(Query、CreateTable/View) |
LinkedIn DataHub | 支持调度任务血缘,SQL血缘支持弱,不支持字段血缘 |
Lyft Amundsen | 仅支持调度任务血缘 |
以Apache Atlas的Hive血缘生产为例。Hive Hook生成的血缘信息会发送到消息中间件,基于Hive原生的HookContext中获取血缘信息,支持血缘解析的Hive SQL类型:
- CREATETABLE_AS_SELECT:基于Select创建Hive表;
- CREATE_MATERIALIZED_VIEW:物化视图创建
- CREATEVIEW:创建视图;
- ALTERVIEW_AS:变更视图表;
- LOAD/EXPORT/IMPORT:数据加载、导入、导出;
- QUERY:复杂查询语句;
基于LineageREST类提供实体对象血缘关系查询REST API接口,基于接口AtlasLineageService#getAtlasLineageInfo 实现元数据查看操作。 更多详情可参考《业界元数据管理:方案设计概览》
SQLFlow是商业化产品,用于多方言的SQL血缘解析,支持表血缘、字段血缘:
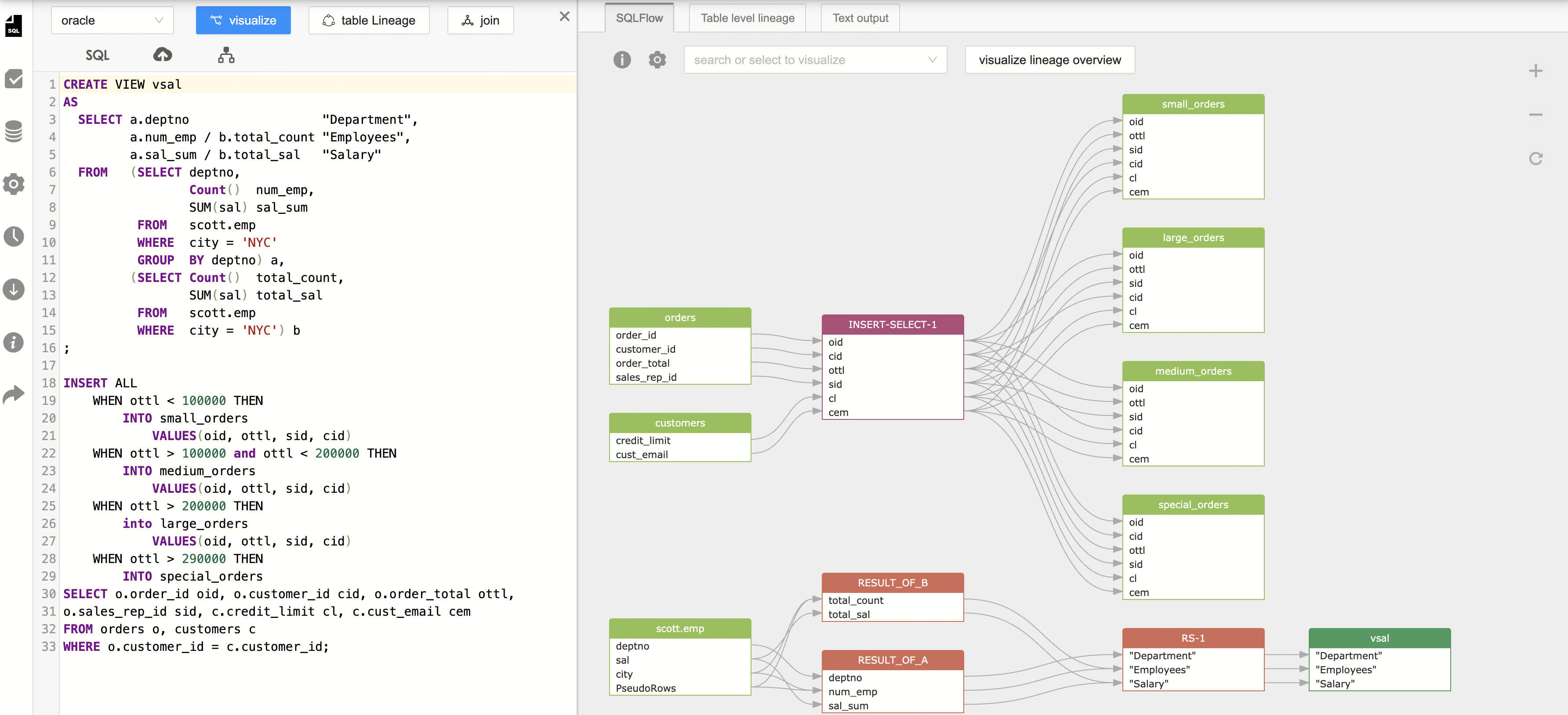
SQL血缘
比较常见的任务血缘解析方式有:1.基于调度系统的任务串联;2. 基于埋点的tracking url记录。由于其实现方式与具体的业务强相关,无通用设计模式,所以暂不赘述。 以下将主要针对SQL血缘解析进行详述。
SQL血缘解析的实现核心:基于AST抽象语法树,识别表、字段的血缘关系。因此血缘解析需至少具备如下能力:
- SQL解析:将SQL语句转换为AST抽象语法树
- 血缘识别:遍历AST语法树,识别对应的表、字段信息,通过AST树结构绑定血缘上下游关系
- 血缘存储:血缘信息一般由顶点(表/字段)和边(上下游关系)组成,维护图结构的血缘信息
在公有云上,面对多样性需求,界定SQL血缘解析的目标是:多SQL方言的数据血缘支持,包括表血缘、字段血缘。 为实现该目标,拆解实现方案如下。
SQL解析
由于不同SQL方言的解析不同,直接基于SQL原生引擎的语法解析、语义解析实现,会存在强绑定引擎问题。
- 语法解析:若在该阶段处理,各方言需对应的不同血缘语义解析Visitor,工作量线性增长
- 语义解析:若在该阶段处理,强依赖元数据,语义解析后得出的血缘对象不完备,并且只有单层血缘
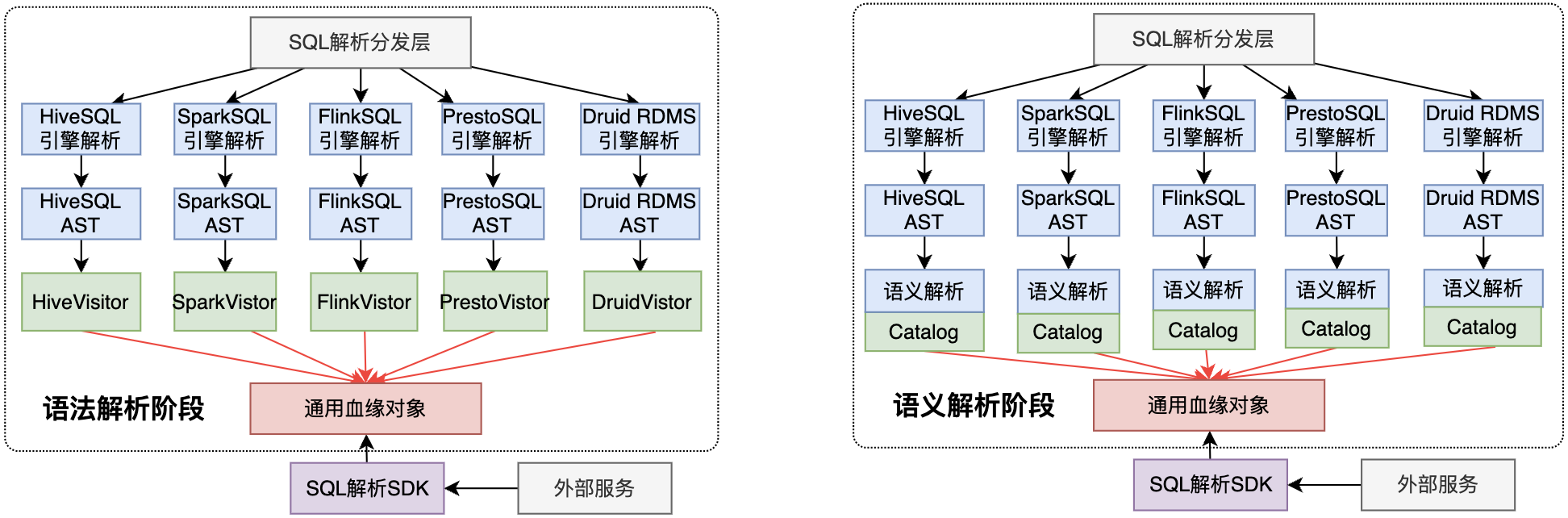
根据以上,基于各引擎SQL解析能力执行,对于多SQL方言的血缘解析是不可行。因此最终选择基于特定的SQL解析组件实现,不同解析组件的方案对比如下:
选项 | 编译框架 | 性能 | 通用性 | 方言支持 | 工作量 |
|---|---|---|---|---|---|
Calcite | JavaCC | 优 | 优+ | 中+ | 高+ |
JSqlParser | JavaCC | 优 | 中- | 优- | 高 |
Marble | JavaCC | 优 | 中+ | 差+ | 高- |
Hqlsql | ANTLR | 中 | 中 | 中+ | 中+ |
SparkSQL | ANTLR | 中 | 中- | 差+ | 高- |
PrestoSQL | ANTLR | 中 | 中- | 差+ | 高- |
Druid | 无框架 | 优+ | 中+ | 优 | 中 |
Alibaba Druid是阿里云计算平台DataWorks团队出品,为监控而生的数据库连接池。Druid SQL是一个内置的SQL层,虽然不具备完整的SQL优化功能,但具备良好的SQL多方言支持,支持多方言转为AST抽象语法树。因此,借助Druid SQL层,可以较便捷的实现血缘解析框架。
Druid SQL 可分三个模块:Parser、AST、Visitor
- Parser:将SQL转换为AST抽象语法树,parser有包括两个部分,Parser和Lexer,其中Lexer实现词法分析,Parser实现语法分析。
- AST:抽象语法树,基于树结构表示SQL语句含义
- Visitor:遍历AST的手段,是处理AST的最方便模式,可以自定义Visitor,如用于解析血缘的LineageVisitor,遍历AST后得到字段和表血缘关系。
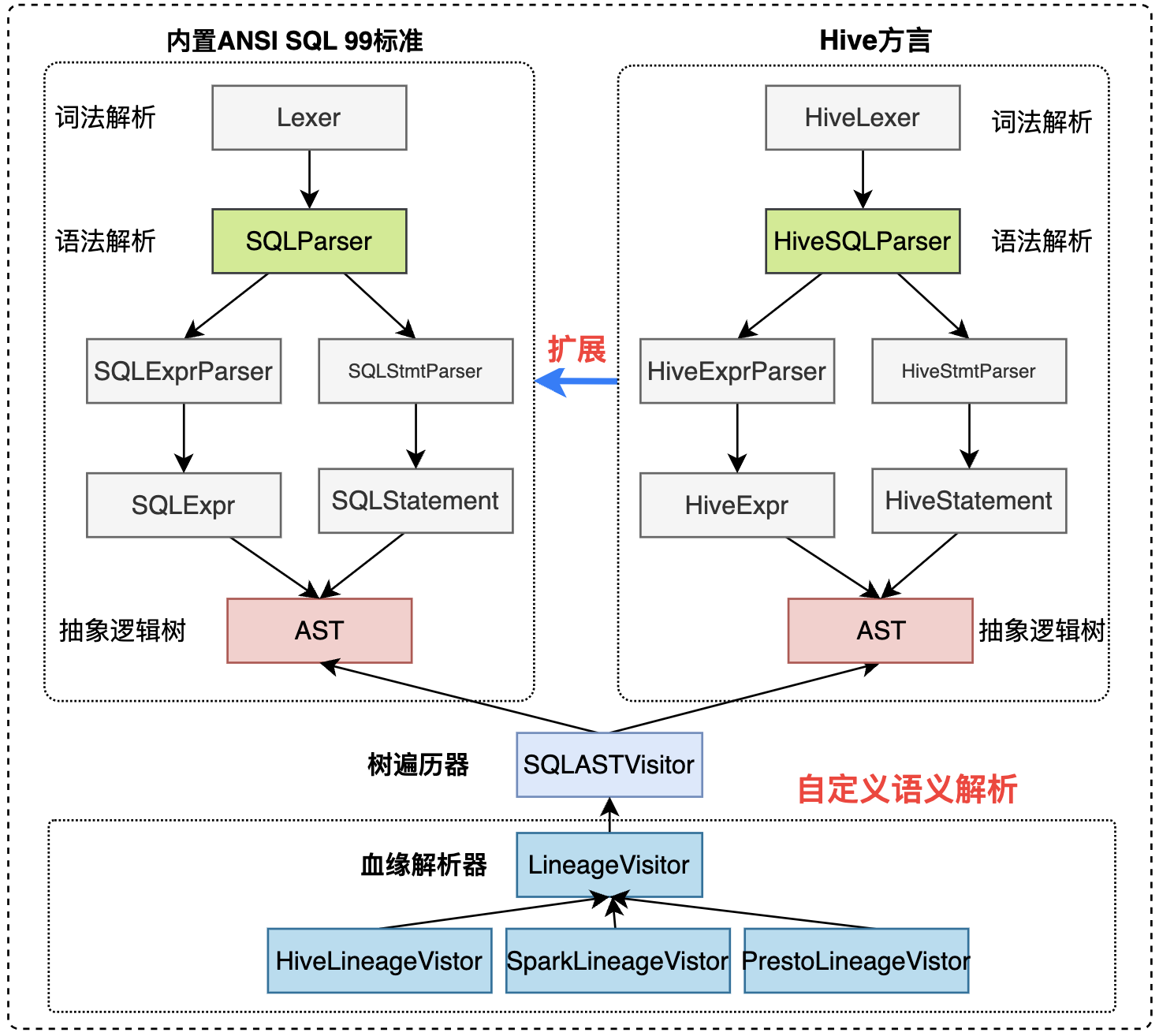
Calcite也可支持数据血缘解析,由于Calcite主要针对统一的SQL方言,对原生多方言支持较弱,因此会有很多工作量在于扩展原生的SQL方言,该实现可参考 Linkedin Coral 处理。Calcite JavaCC SQL解析依赖 FMPP配置文件、FreeMarker模板文件,官方建议在配置模板扩展,尽量避免改动Parser.jj文件。
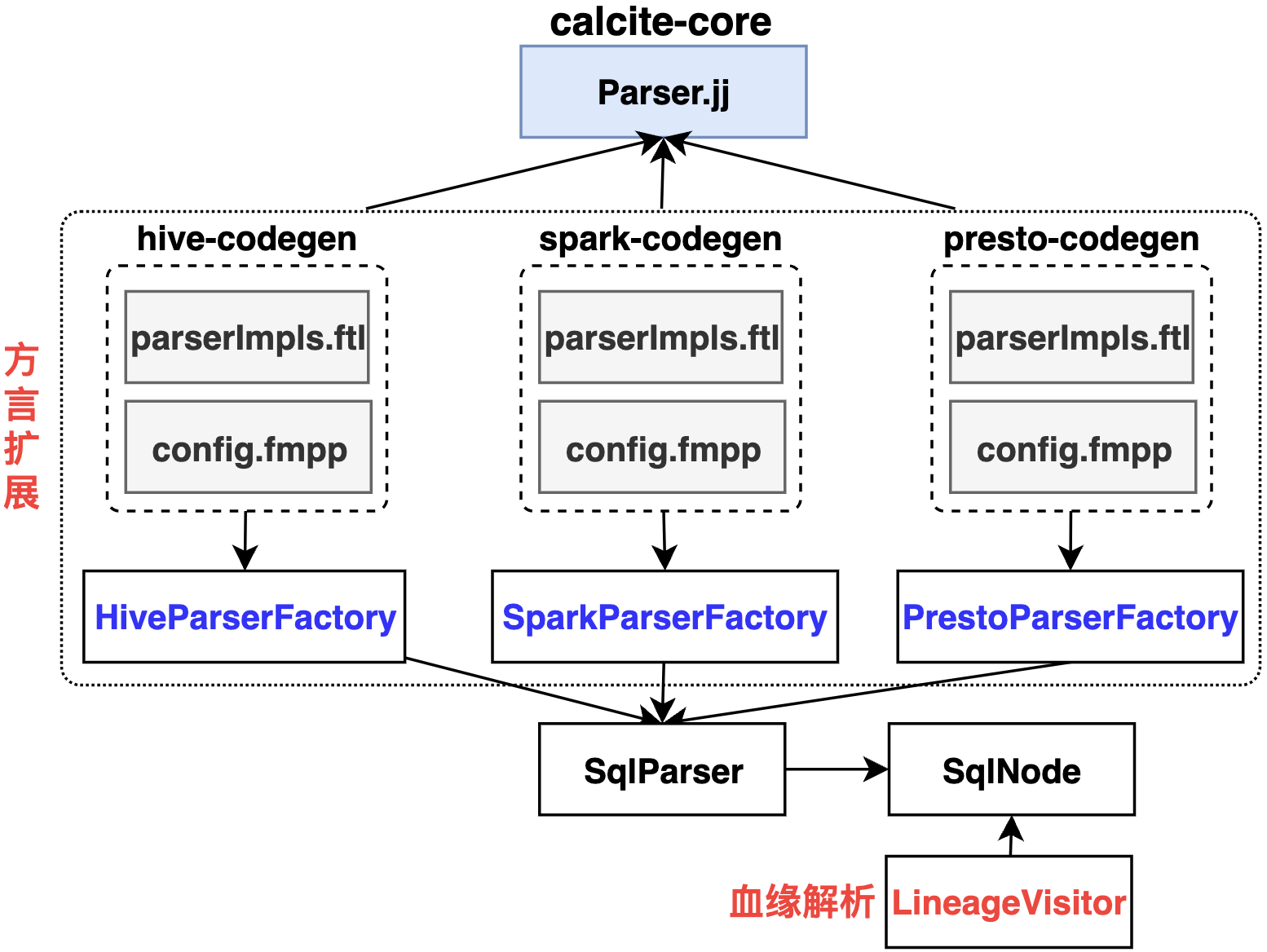
备注:如果业务场景只有单一SQL方言的血缘解析,更推荐基于Calcite处理。Calcite更多详情可参考专栏《Calcite剖析》
血缘识别
血缘识别基于Visitor模式遍历AST树结构,获取表血缘、字段血缘信息。血缘关系图包括:
- 表血缘:表信息作为顶点,表之间的关系作为边,如create table B as select * from A,则source为A表,target为B表;
- 字段血缘:字段作为顶点,字段之间的关系作为边,字段之间的关系是继承自表关系的,如source为A表id字段,target为B表id字段;
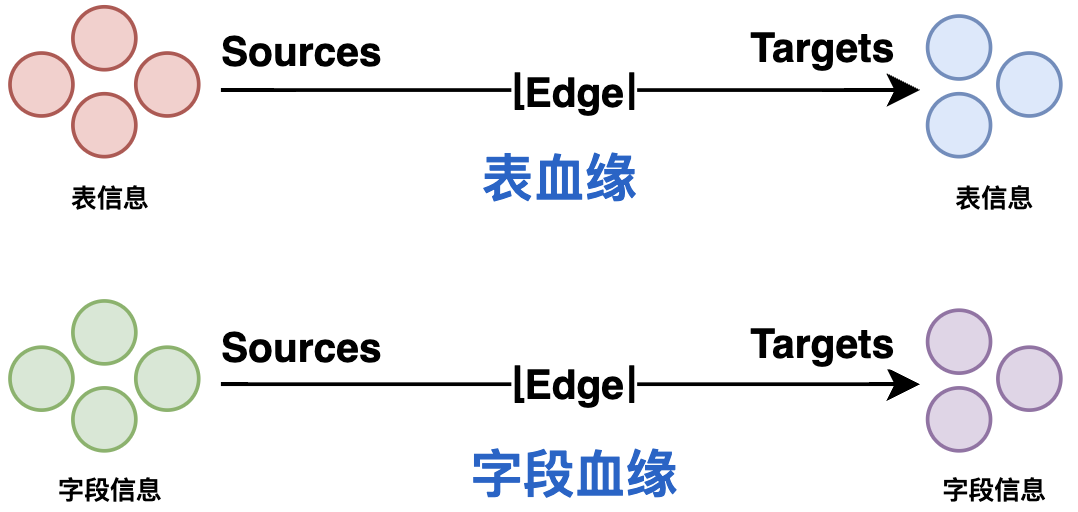
血缘识别Visitor模式可基于自底向上递归遍历血缘关系,根据表节点、字段节点维护血缘信息。
示例(CREATE AS SELECT 语句):create table table_02 as select id,name from table_01,获取语法解析的AST如下:
- ROOT:为AST的根节点信息,SQL解析的起点;
- SQL关键字(绿色框):如CREATE、TABLE、EXTERNAL等;
- SQL表达式(紫色框):每个SQL表达式都维护父节点信息;
- SQL解析器(黄色框):解析指定SQL语句类型,根据不同SQLParser解析器,可生成不同AST子树;
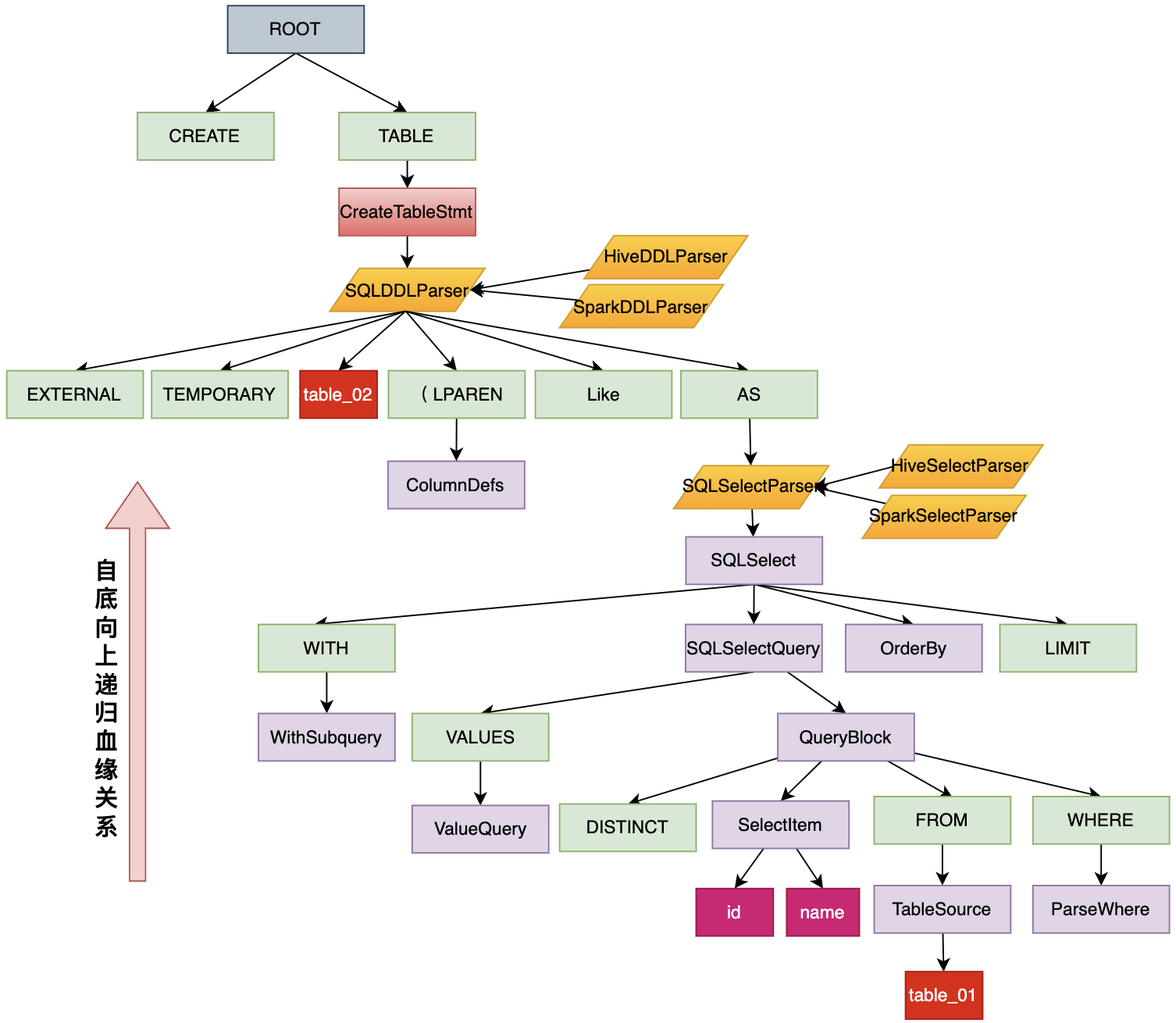
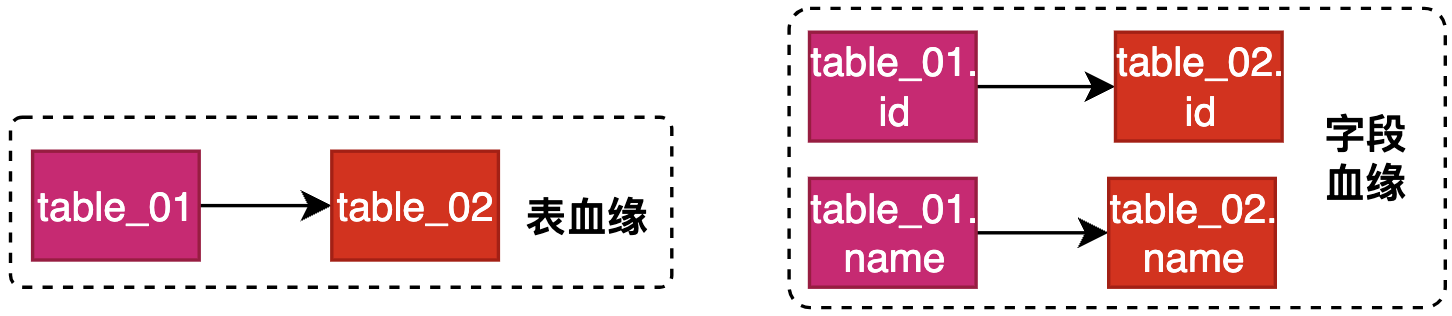
通过对AST语法树的遍历,可得到如下
- 表血缘:table_01 → table_02
- 字段血缘:table_01.id → table_02.id;table_01.name → table_02.name;
血缘存储
血缘数据主要维护顶点和边之间的关系,对应的数据支持保存在关系数据库中。但如果关系层级超过3层,查询时会出现性能瓶颈,可选择基于图数据库存储。
图数据库是一个使用图结构进行语义查询的数据库,它使用节点、边和属性来表示和存储数据。该系统的关键概念是图,它直接将存储中的数据项,与数据节点和节点间表示关系的边的集合相关联。
按照图数据库语言类型可划分如下类型:
- Gremlin: Janus Graph、InfiniteGraph、Cosmos DB、DataStax Enterprise(5.0+) 、Amazon Neptune
- Cypher: Neo4j、RedisGraph、AgensGraph
- nGQL: Nebula Graph
应用架构
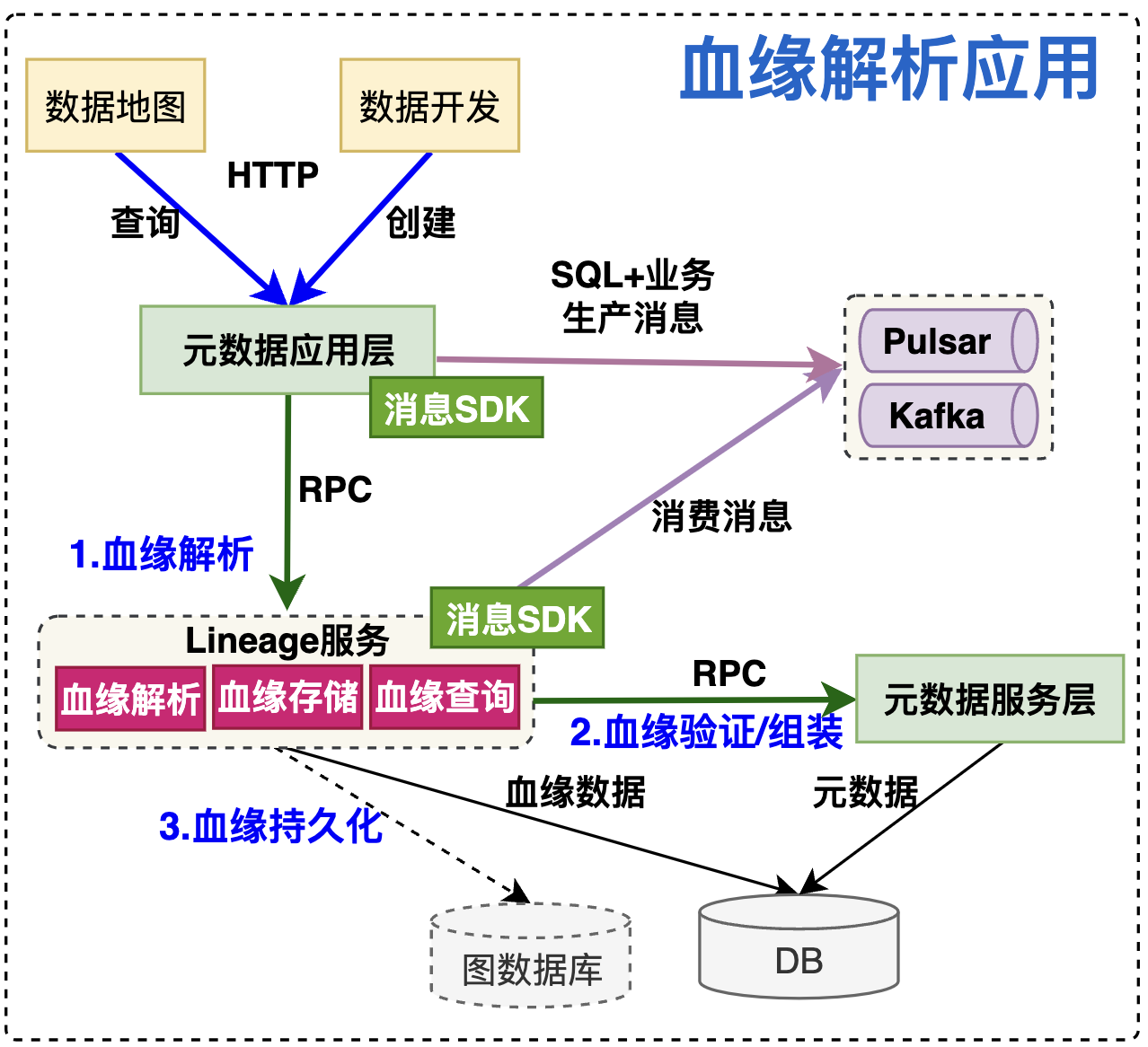
由于数据血缘的时效性不高,且数据量级通常较大,一般会选择消息中间件进行解耦处理。血缘解析应用流程如下:
- 生产数据:上层数据地图、数据开发等功能在SQL和任务过程中,主动push给元数据应用层,元数据应用层基于固定消息格式将对应的数据生产到消息中间件;
- 消费数据:血缘服务定时从消息中间件消费数据进行处理;除此之外,也支持应用层直接RPC接口调用血缘服务进行解析;
- 解析数据:血缘服务基于工具类解析血缘,基于元数据服务层验证血缘有效性并组织,最终将持久化血缘信息。
血缘服务可分为三个模块:血缘解析、血缘存储、血缘查询。
总结
数据血缘是数据治理的重要应用之一,通过血缘信息可清晰识别出表之间的依赖关系,追踪数据的来源和流向过程。数据血缘对于数据质量管理、合规性以及数据安全都有重要的作用。在复杂的数据环境中,维护准确的数据血缘信息是一个挑战性问题。本文首先简介了数据血缘的背景、业界方案;其次,针对SQL血缘的实现原理进行详细说明,主要包括三个流程: SQL解析、血缘识别、血缘存储;最后,整体概述了数据血缘的应用架构。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。