Elasticsearch FSCrawler 一个bug及解决方案
Elasticsearch FSCrawler 一个bug及解决方案

1、FSCrawler Bug 发现过程及描述
书接上一回,在使用 Elasticsearch FSCrawler 实现文档知识库检索的时候。
发现基于本地磁盘文件轮询导入 Elasticsearch 都没有问题。
但是,借助其 REST API 接口上传文件的时候,发现其字段 filesize 字段没有值。
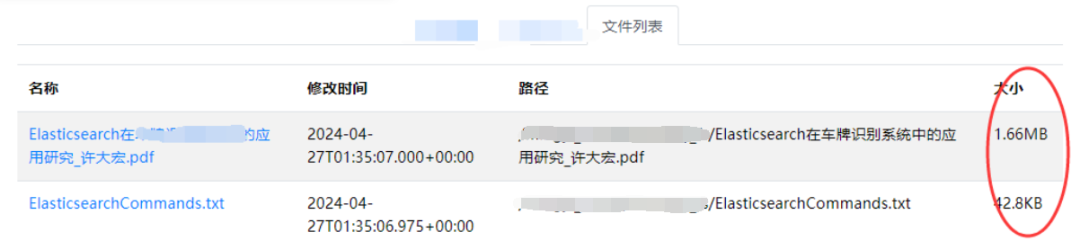
但,实际业务场景中,需要展示这个字段。
这样导致的结果是,页面无法显示,而后发现是因为字段缺失所致。
2、FSCrawler Bug 排查思路
2.1 核查 Mapping 看是否字段缺失
GET fs_job_2024/_mappingMapping 部分映射如下:
"filename": {
"type": "text",
"store": true,
"fields": {
"keyword": {
"type": "keyword"
}
},
"analyzer": "ik_smart"
},
"filesize": {
"type": "long"
},
"indexed_chars": {
"type": "long"
},我们想要的字段 filesize 是存在的。
初步判定 Mapping 没有问题。
2.2 查看历史文档看 filesize 值是否合理
POST fs_job_2024/_search
{
"_source": [
"file.filesize"
],
"query": {
"bool": {
"must": [
{
"exists": {
"field": "file.filesize"
}
}
]
}
}
}执行后看召回结果:
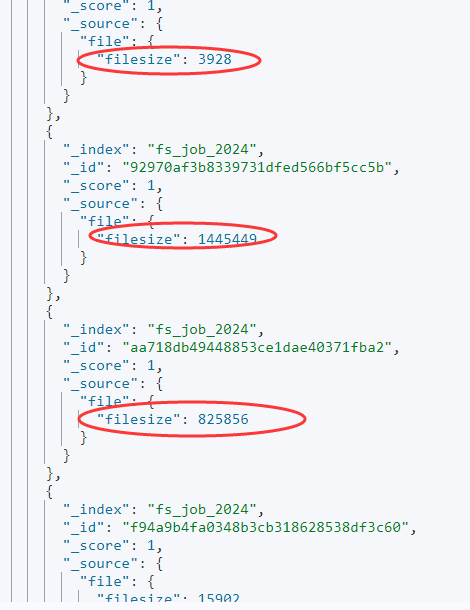
也就是说,已有通过轮询写入 Elasticsearch 集群的文档数据都没有问题。
2.3 python 代码写入文档就会没有 filesize 字段
多次测试发现,只要借助 python Http 请求写入的字段就没有 filesize 字段。
然后,再继续核查官方文档,这方面给出了 CURL 的示例。
https://fscrawler.readthedocs.io/en/latest/admin/fs/rest.html
echo "This is my text" > test.txt
curl -F "file=@test.txt" "http://127.0.0.1:8080/fscrawler/_document"
结果参照执行后,也发现提交的文档没有 filesize 字段。这样之后,我就 Elasticsearch 论坛提交了问题。
https://discuss.elastic.co/t/fscrawler-rest-service-has-no-filesize-field/358630/2
作者响应很及时,并认定这是一个 bug。
反馈如下:
https://github.com/dadoonet/fscrawler/pull/1868
3、FSCrawler Bug 解决方案
期间和作者有过几轮沟通和验证后,最终得出解决方案。
echo "This is my text" > test.txt
curl -F "file=@test.txt" \
-F "tags={\"file\":{\"filesize\":$(ls -l test.txt | awk '{print $5}')}}" \
"http://127.0.0.1:8080/fscrawler/_document"就是写入的时候加上“Additional tags”。这个命令通常用于向支持文件接收的服务发送文件,并同时提供一些元数据(在这里是文件的大小)。
也就是说需要咱们自己提交一下文件的大小。
如下是我 python 代码最终解决方案:
# 获取文件大小
file.seek( 0, os.SEEK_END )
file_size = file.tell()
file.seek( 0 ) # 重置文件指针
# 打印文件大小,用于调试
print( "File size:", file_size )
# 构建文件上传部分
files = {'file': (
file.filename, file, 'application/vnd.openxmlformats-officedocument.wordprocessingml.document')}
# 构建 tags 部分,包含文件大小等信息
tags = {'file': {'filesize': file_size}}
# 发送文件和表单数据到指定地址
response = requests.post(
FS_WEB_ADDRESS,
files=files,
data={'tags': json.dumps( tags )}, # 使用 json.dumps 将字典转换为 JSON 字符串
timeout=10
)这样所有新文档的提交都有 filesize 值了。
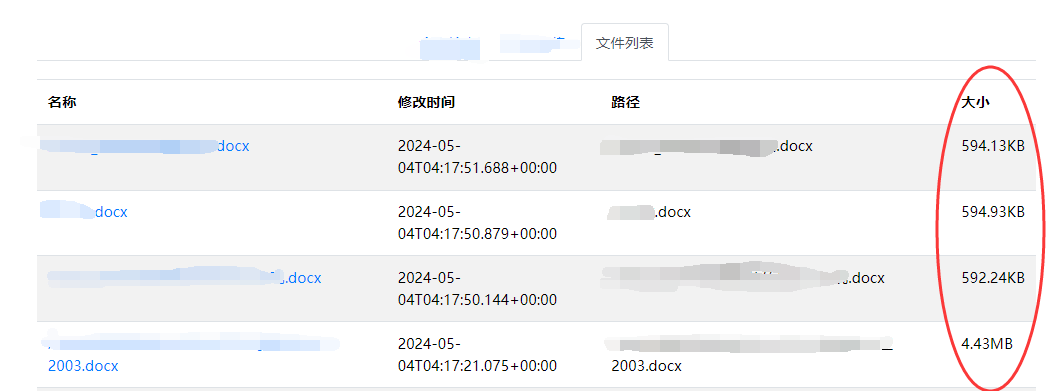
4、小结
本文详细描述发现 FSCrawler bug 的全过程。欢迎留言就 FSCrawler 相关技术问题进行交流。
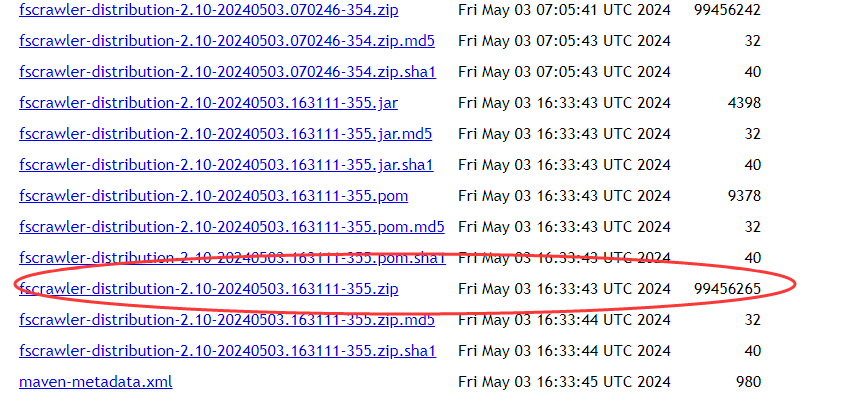
PS:要用如下截图最新版本的包来验证才可以修复bug。
本文分享自 铭毅天下Elasticsearch 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体分享计划 ,欢迎热爱写作的你一起参与!