0923-7.1.9-使用S3 Gateway访问Ozone
0923-7.1.9-使用S3 Gateway访问Ozone

Fayson
发布于 2024-05-09 14:22:54
发布于 2024-05-09 14:22:54
S3 Gateway允许访问/s3v卷下的bucket。
1.要访问不在 /s3v 卷下的已有bucket,我们可以在/s3v卷中创建symlink
ozone sh bucket link /vol1/obs-bucket /s3v/obs-bucket-link
ozone sh bucket info /s3v/obs-bucket-link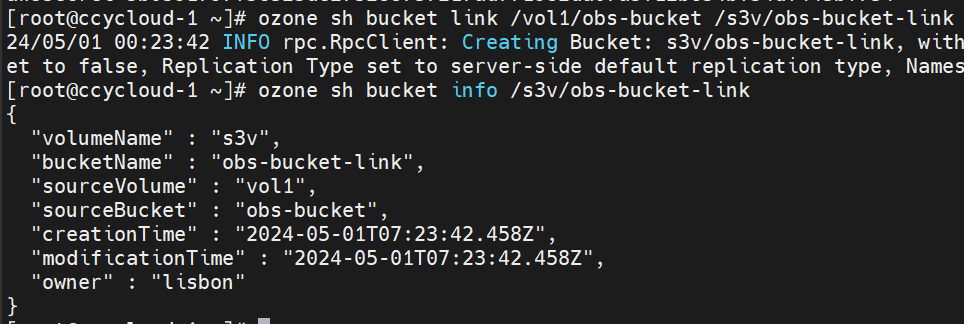
2.如果通过 S3 访问之前创建的 LEGACY 存储桶,则需要禁用ozone.om.enable.filesystem.paths(默认为 True)。这个配置为true则是允许LEGACY 存储桶与Hadoop 文件系统语义兼容,为false则是允许LEGACY 存储桶与S3语义兼容。
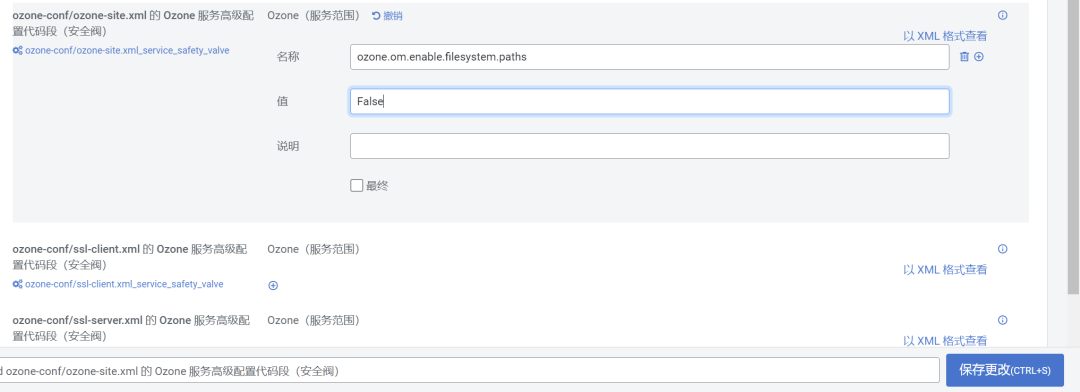
保存更改后重启Ozone服务。
3.可以通过 S3 读取 FSO 存储桶中的数据,也可以将key/文件写入 FSO 存储桶。 但是由于与 S3 语义不兼容,中间目录的创建可能会失败。
4.从Ozone获取S3 credential
kinit Lisbon
ozone s3 getsecret --om-service-id=ozone1
export awsAccessKey=lisbon@LISBON.COM
export awsSecret=5b0591797f5c325de273288737217ad771982da07a5f12b654bf54df443bf734
5.选择一台安装了S3 Gateway的主机,获取S3的endpoint
export s3_endpoint='http://ccycloud-2.rainy.root.comops.site:9878'6.通过S3使用hadoop CLI访问Ozone
## Create a directory in a bucket
hadoop fs -Dfs.s3a.bucket.probe=0 -Dfs.s3a.change.detection.version.required=false -Dfs.s3a.change.detection.mode=none -Dfs.s3a.access.key=$awsAccessKey -Dfs.s3a.secret.key=$awsSecret -Dfs.s3a.endpoint=$s3_endpoint -Dfs.s3a.path.style.access=true -Dfs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem -mkdir -p s3a://obs-bucket-link/dir1/dir2
## Add key to a the prev directory
echo "Random text for word count" > key1
hadoop fs -Dfs.s3a.bucket.probe=0 -Dfs.s3a.change.detection.version.required=false -Dfs.s3a.change.detection.mode=none -Dfs.s3a.access.key=$awsAccessKey -Dfs.s3a.secret.key=$awsSecret -Dfs.s3a.endpoint=$s3_endpoint -Dfs.s3a.path.style.access=true -Dfs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem -put key1 s3a://obs-bucket-link/dir1/dir2/key1
## List files/dirs in a bucket
hadoop fs -Dfs.s3a.bucket.probe=0 -Dfs.s3a.change.detection.version.required=false -Dfs.s3a.change.detection.mode=none -Dfs.s3a.access.key=$awsAccessKey -Dfs.s3a.secret.key=$awsSecret -Dfs.s3a.endpoint=$s3_endpoint -Dfs.s3a.path.style.access=true -Dfs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem -ls -R s3a://obs-bucket-link/
ozone sh key list /s3v/obs-bucket-link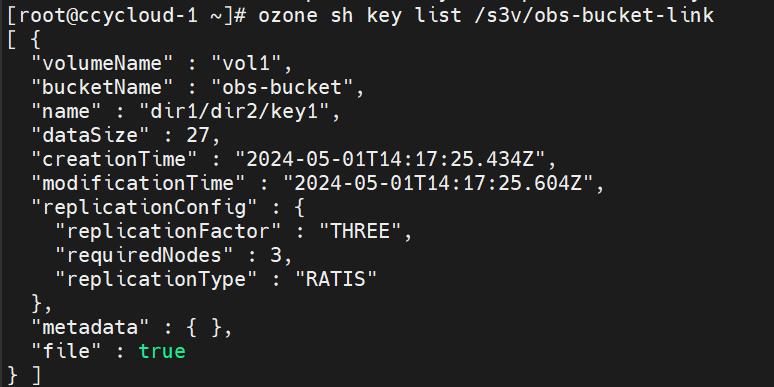
1 使用Spark通过S3访问Ozone
1.为Spark创建S3的property文件
vi ozone-s3.properties
spark.hadoop.fs.s3a.impl = org.apache.hadoop.fs.s3a.S3AFileSystem
spark.hadoop.fs.s3a.endpoint = http://ccycloud-2.rainy.root.comops.site:9878
spark.hadoop.fs.s3a.bucket.probe = 0
spark.hadoop.fs.s3a.change.detection.version.required = false
spark.hadoop.fs.s3a.change.detection.mode = none
spark.hadoop.fs.s3a.path.style.access = true2.使用S3 properties文件启动spark-shell
spark-shell --properties-file ozone-s3.properties --conf spark.hadoop.fs.s3a.access.key=$awsAccessKey --conf spark.hadoop.fs.s3a.secret.key=$awsSecret
3.计算输入文件中的单词数
var lines = sc.textFile("s3a://obs-bucket-link/dir1/dir2/key1")
var words = lines.flatMap(_.split(" "))
var wordsKv = words.map((_, 1))
var wordCounts = wordsKv.reduceByKey(_ + _ )
4.将单词数写入Ozone
wordCounts.saveAsTextFile("s3a://obs-bucket-link/output")
:quit
5.读取输出
hadoop fs -Dfs.s3a.bucket.probe=0 -Dfs.s3a.change.detection.version.required=false -Dfs.s3a.change.detection.mode=none -Dfs.s3a.access.key=$awsAccessKey -Dfs.s3a.secret.key=$awsSecret -Dfs.s3a.endpoint=$s3_endpoint -Dfs.s3a.path.style.access=true -Dfs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem -cat s3a://obs-bucket-link/output/*
2 使用Hive通过S3访问Ozone
1.在ozone-site.xml中增加S3配置,Ozone > Configuration > Ozone Service Advanced Configuration Snippet (Safety Valve) for ozone-conf/ozone-site.xml > View as XML
<property>
<name>fs.s3a.access.key</name>
<value>lisbon@LISBON.COM</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value>5b0591797f5c325de273288737217ad771982da07a5f12b654bf54df443bf734</value>
</property>
<property>
<name>fs.s3a.endpoint</name>
<value>http://ccycloud-2.rainy.root.comops.site:9878</value>
</property>
<property>
<name>fs.s3a.bucket.probe</name>
<value>0</value>
</property>
<property>
<name>fs.s3a.change.detection.version.required</name>
<value>false</value>
</property>
<property>
<name>fs.s3a.path.style.access</name>
<value>true</value>
</property>
<property>
<name>fs.s3a.change.detection.mode</name>
<value>none</value>
</property>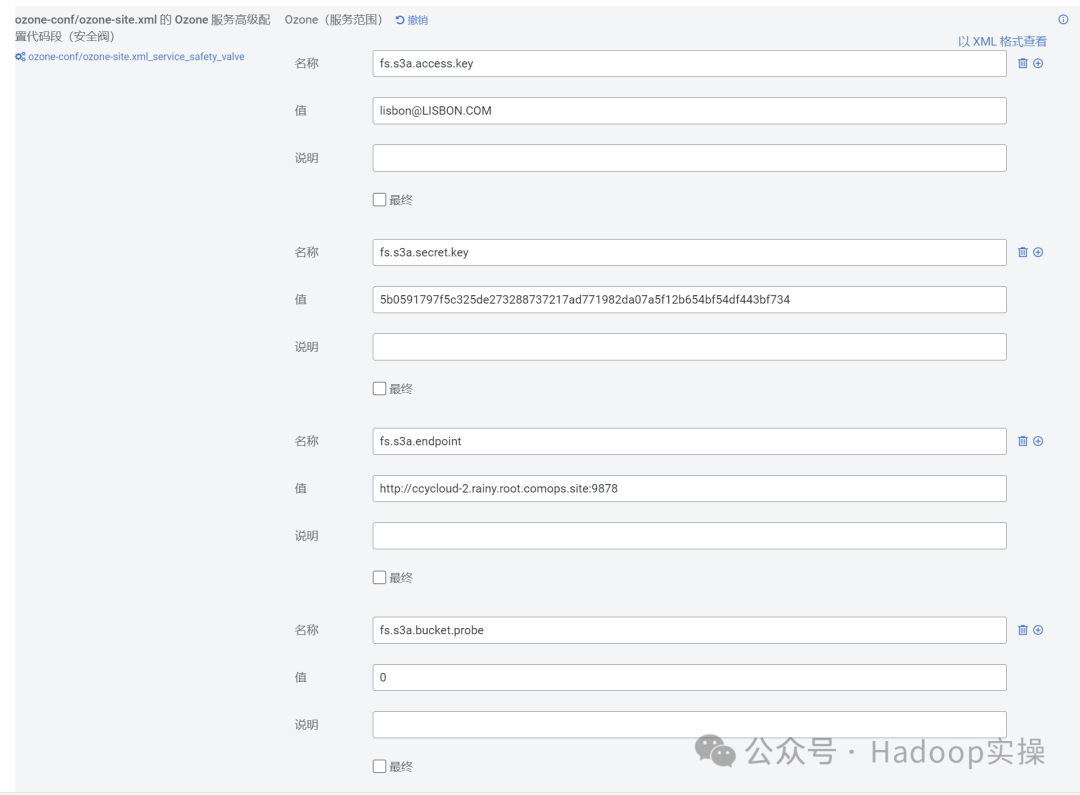

2.保存更改,按照向导重启集群并部署客户端配置。
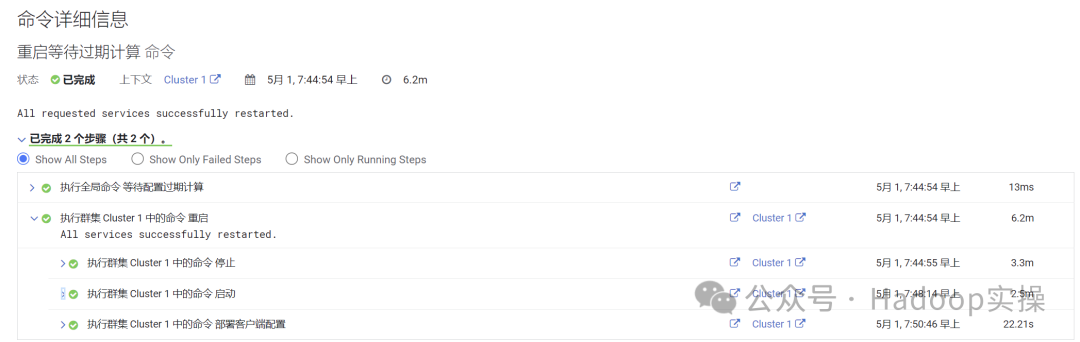
3.将之前的车辆数据拷贝到obs的bucket
hadoop distcp -m 2 -skipcrccheck hdfs:///tmp/vehicles.csv s3a://obs-bucket-link/warehouse/distcp/vehicles/vehicles.csv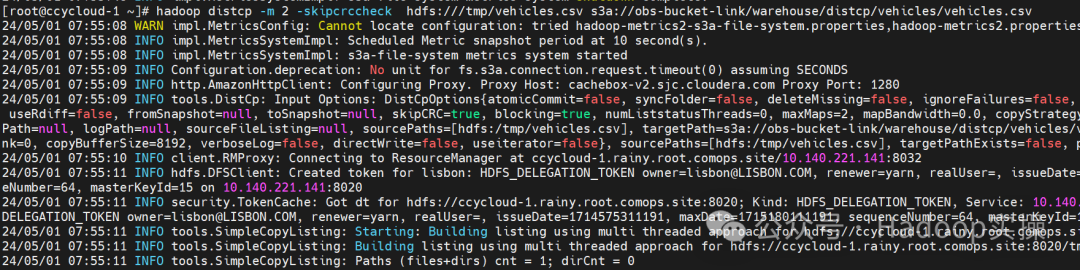
4.在Hive中创建表
CREATE EXTERNAL TABLE `hive_s3_vehicles`(
`barrels08` string,`barrelsa08` string,`charge120` string,`charge240` string,`city08` string,`city08u` string,`citya08` string,`citya08u` string,`citycd` string,`citye` string,`cityuf` string,`co2` string,`co2a` string,`co2tailpipeagpm` string,`co2tailpipegpm` string,`comb08` string,`comb08u` string,`comba08` string,`comba08u` string,`combe` string,`combinedcd` string,`combineduf` string,`cylinders` string,`displ` string,`drive` string,`engid` string,`eng_dscr` string,`fescore` string,`fuelcost08` string,`fuelcosta08` string,`fueltype` string,`fueltype1` string,`ghgscore` string,`ghgscorea` string,`highway08` string,`highway08u` string,`highwaya08` string,`highwaya08u` string,`highwaycd` string,`highwaye` string,`highwayuf` string,`hlv` string,`hpv` string,`id` string,`lv2` string,`lv4` string,`make` string,`model` string,`mpgdata` string,`phevblended` string,`pv2` string,`pv4` string,`range` string,`rangecity` string,`rangecitya` string,`rangehwy` string,`rangehwya` string,`trany` string,`ucity` string,`ucitya` string,`uhighway` string,`uhighwaya` string,`vclass` string,`year` string,`yousavespend` string,`guzzler` string,`trans_dscr` string,`tcharger` string,`scharger` string,`atvtype` string,`fueltype2` string,`rangea` string,`evmotor` string,`mfrcode` string,`c240dscr` string,`charge240b` string,`c240bdscr` string,`createdon` string,`modifiedon` string,`startstop` string,`phevcity` string,`phevhwy` string,`phevcomb` string)
row format delimited
fields terminated by ','
location 's3a://obs-bucket-link/warehouse/distcp/vehicles';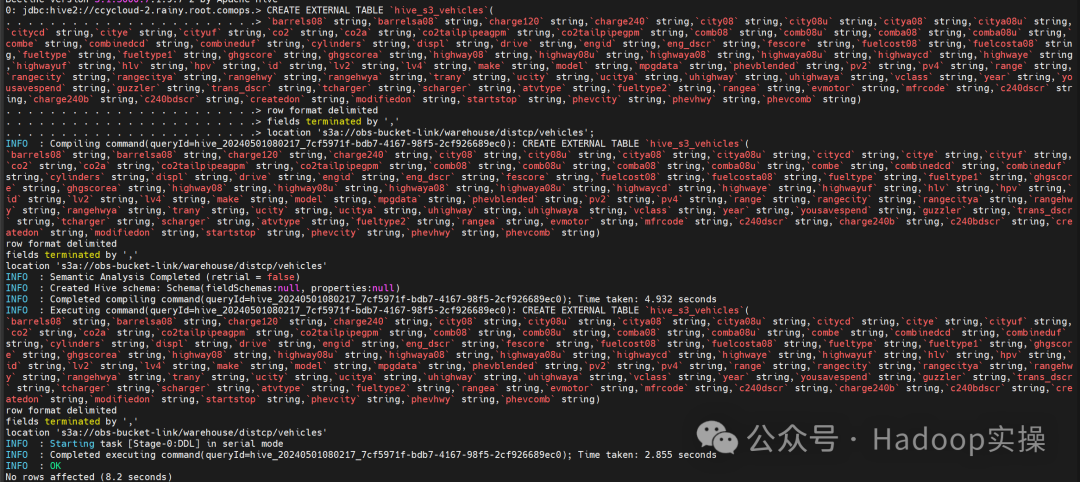
5.运行以下SQL
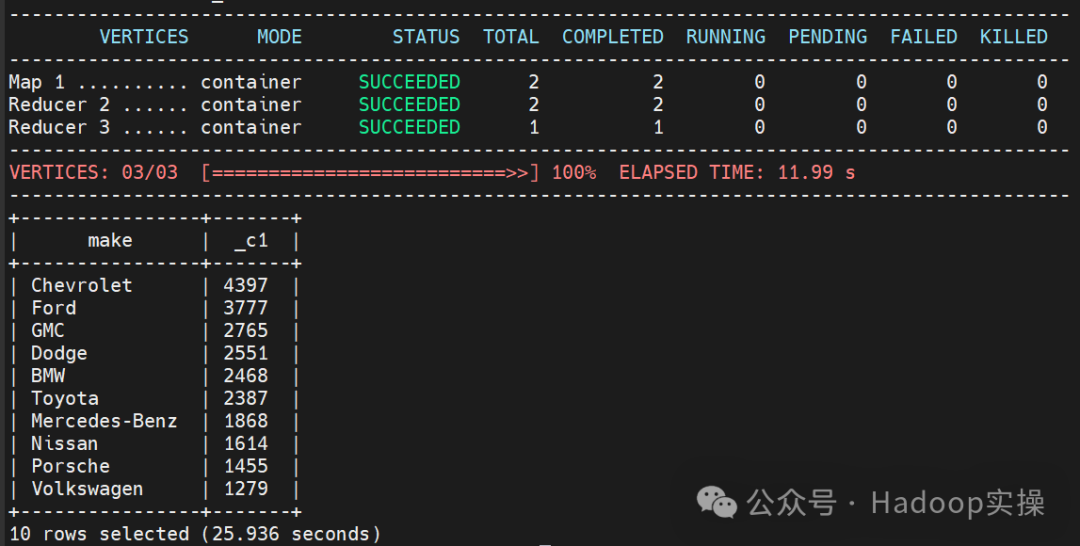
select * from `hive_s3_vehicles` limit 1;
select make, count(*) from hive_s3_vehicles group by make order by 2 desc limit 10;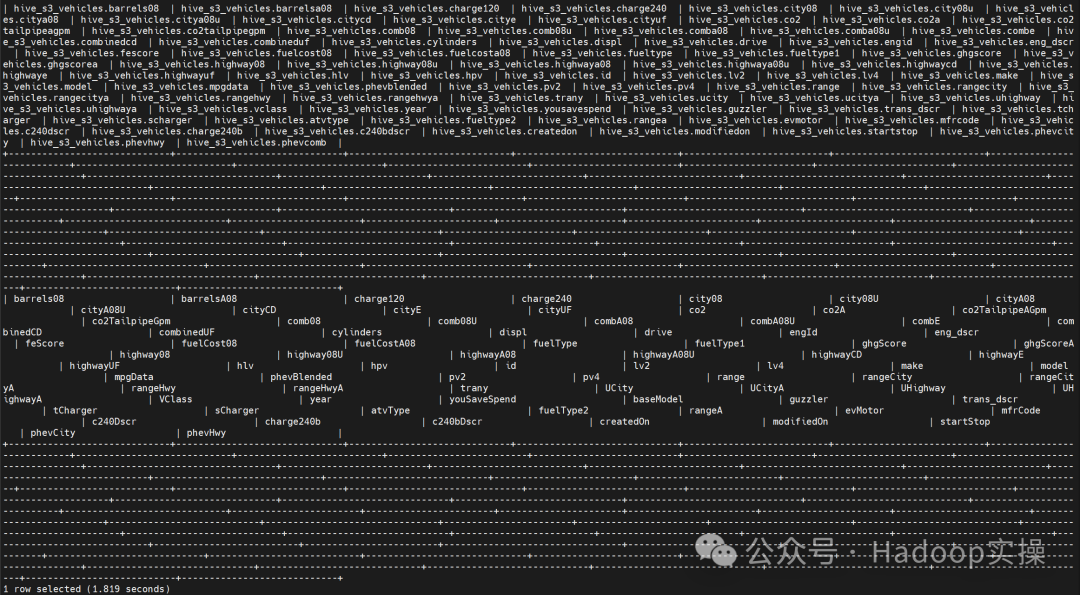
本文参与 腾讯云自媒体分享计划,分享自微信公众号。
原始发表:2024-05-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
相关产品与服务
对象存储
对象存储(Cloud Object Storage,COS)是由腾讯云推出的无目录层次结构、无数据格式限制,可容纳海量数据且支持 HTTP/HTTPS 协议访问的分布式存储服务。腾讯云 COS 的存储桶空间无容量上限,无需分区管理,适用于 CDN 数据分发、数据万象处理或大数据计算与分析的数据湖等多种场景。