0922-7.1.9-使用Spark和Hive访问Ozone
0922-7.1.9-使用Spark和Hive访问Ozone

Fayson
发布于 2024-05-09 14:22:24
发布于 2024-05-09 14:22:24
1 使用Spark访问Ozone
1.下载数据并上传到Ozone的bucket中
hdfs dfs -mkdir -p ofs://ozone1/data/vehicles
wget -qO - https://www.fueleconomy.gov/feg/epadata/vehicles.csv | hdfs dfs -copyFromLocal - ofs://ozone1/data/vehicles/vehicles.csv 
2.使用Spark拆分数据并保存到Hive外表中。
spark-shell --conf "spark.debug.maxToStringFields=90" --conf spark.yarn.access.hadoopFileSystems="ofs://ozone1/" << EOF
val df = spark.read.format("csv").option("header", "true").load("ofs://ozone1/data/vehicles/vehicles.csv")
df.createOrReplaceTempView("tempvehicle")
spark.sql("create table vehicles stored as parquet location 'ofs://ozone1/data/vehicles/vehicles' as select * from tempvehicle");
EOF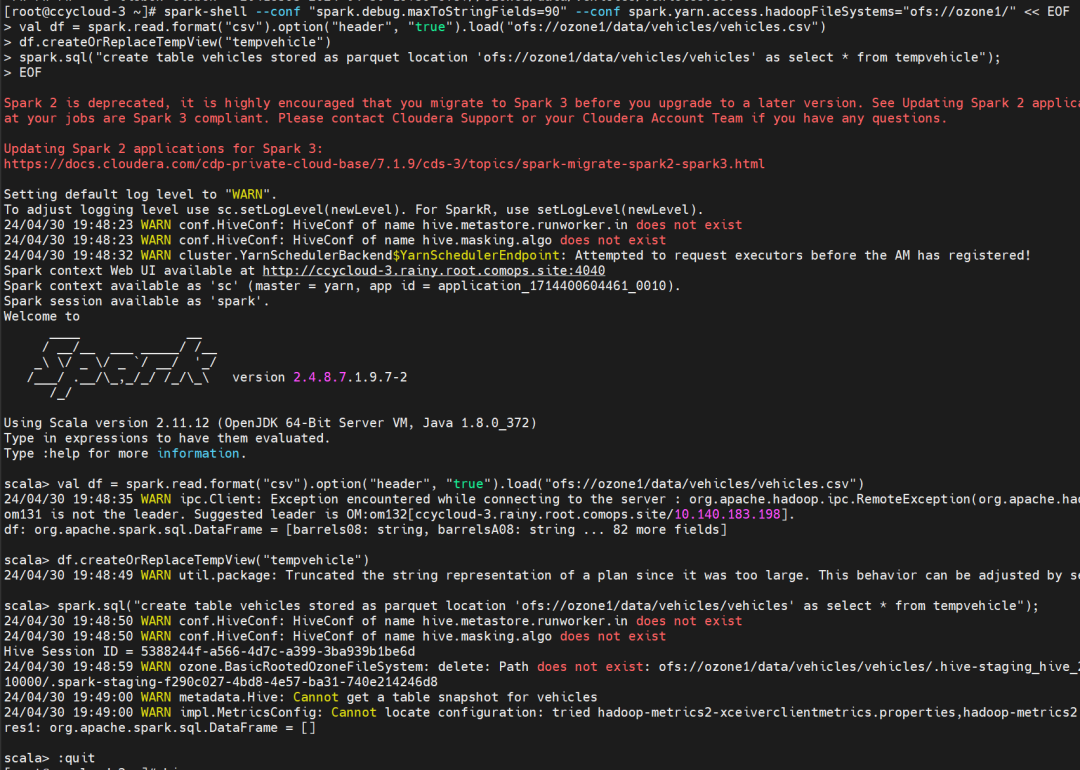
3.运行以下Spark SQL代码:
spark-shell --conf "spark.sql.debug.maxToStringFields=90" --conf spark.yarn.access.hadoopFileSystems="ofs://ozone1/" << EOF
var df=spark.sql("select count(*) from vehicles")
df.show()
EOF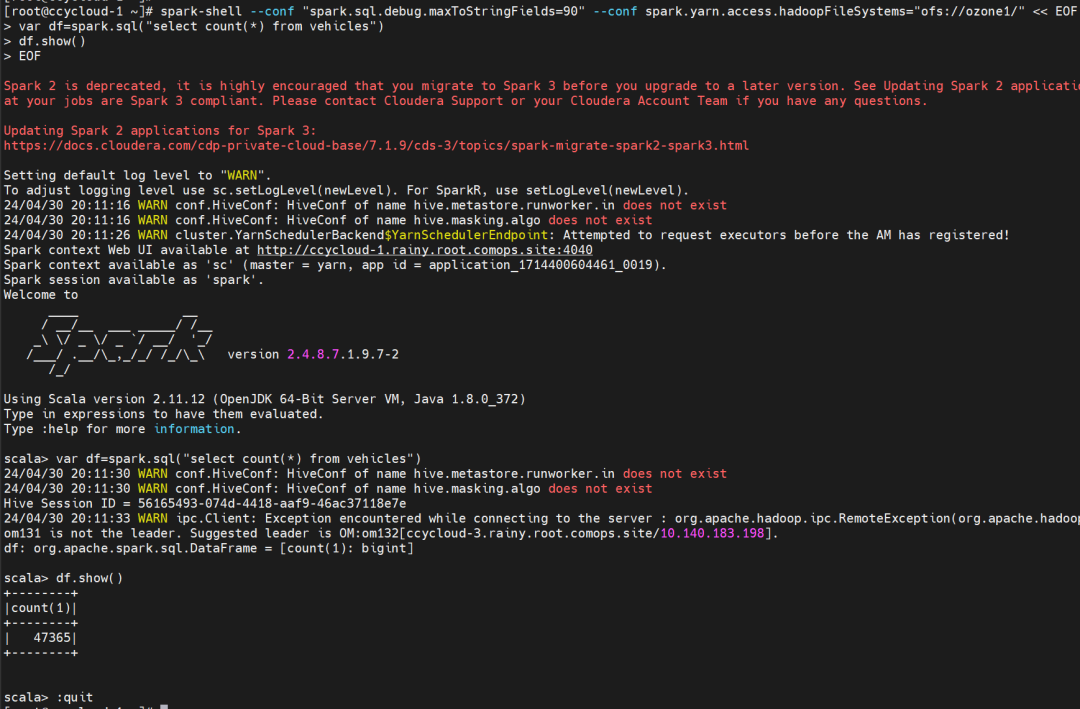
4.运行以下Spark SQL代码:
spark-shell --conf "spark.sql.debug.maxToStringFields=90" --conf spark.yarn.access.hadoopFileSystems="ofs://ozone1/" << EOF
var df=spark.sql("select make, count(*) from vehicles group by make order by 2 desc limit 10")
df.show()
EOF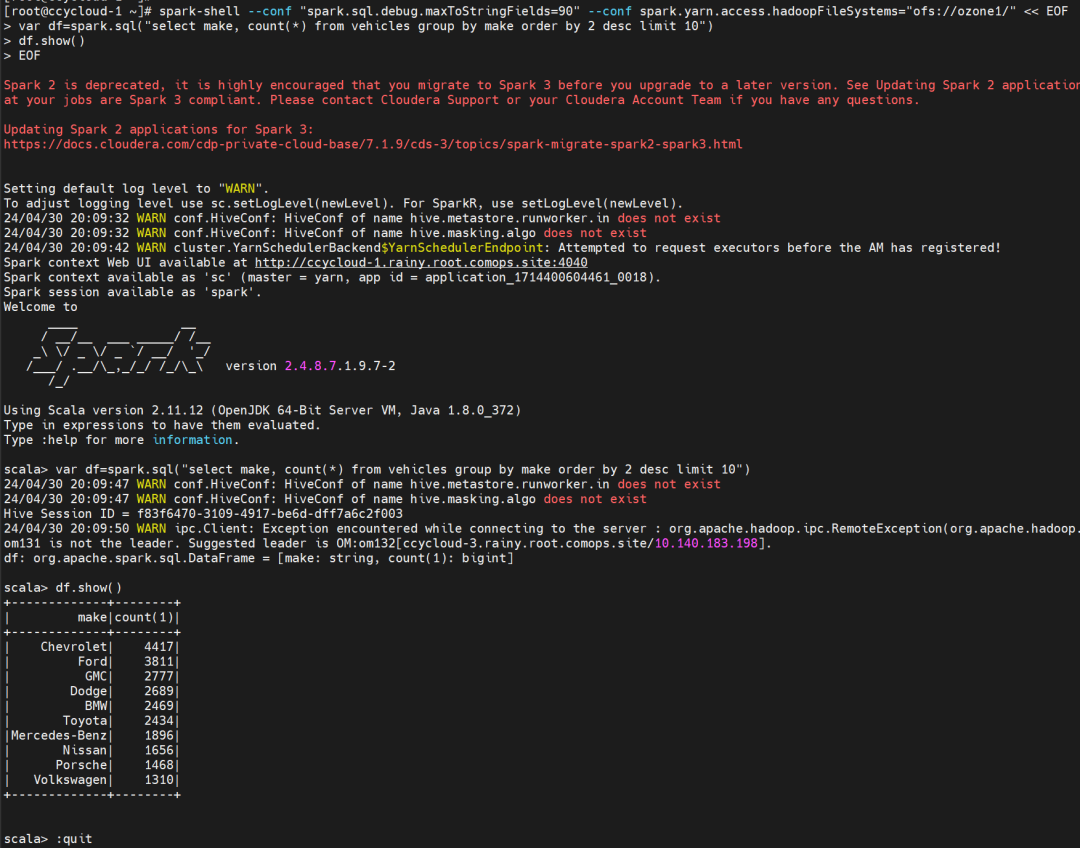
5.运行以下Spark SQL代码:
spark-shell --conf "spark.sql.debug.maxToStringFields=90" --conf spark.yarn.access.hadoopFileSystems="ofs://ozone1/" << EOF
var df=spark.sql("select make,model, count(*) from vehicles group by make,model order by 3 desc limit 10")
df.show()
EOF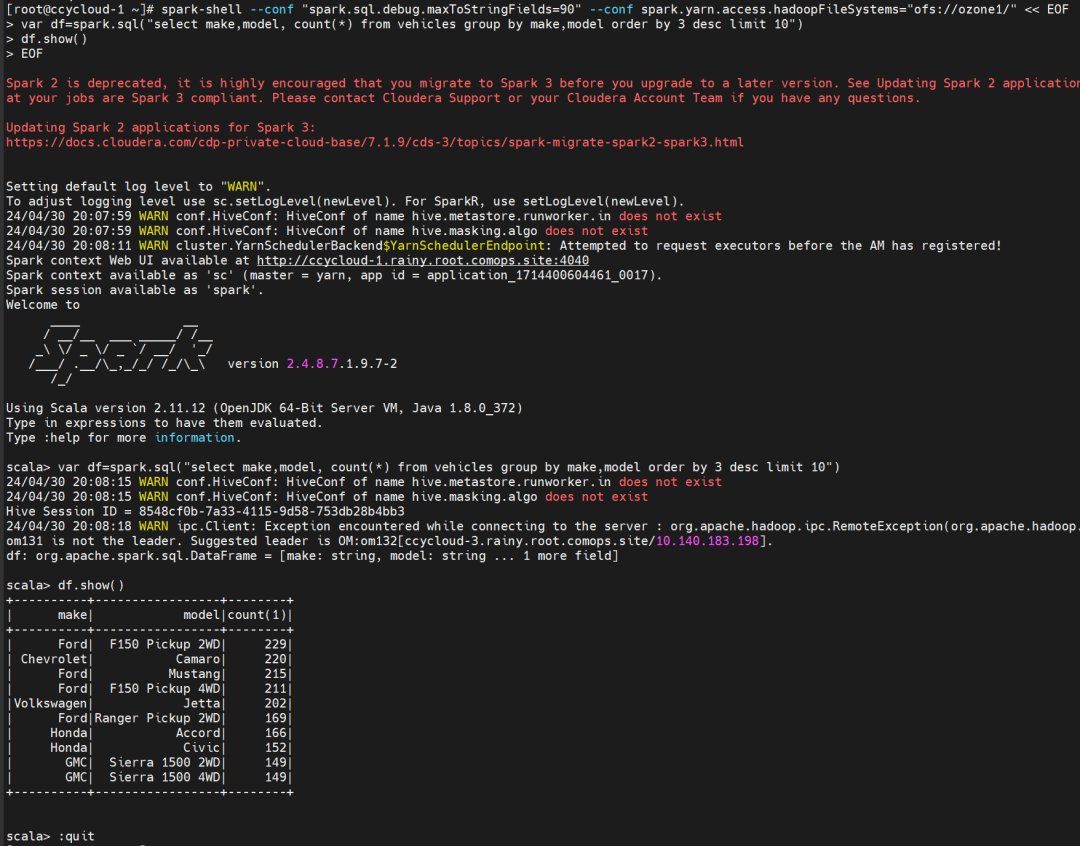
6.运行以下Spark SQL代码:
spark-shell --conf "spark.sql.debug.maxToStringFields=90" --conf spark.yarn.access.hadoopFileSystems="ofs://ozone1/" << EOF
var df=spark.sql("select make,model, max(cast(combe as float)) from vehicles group by make,model order by 3 desc, 1,2 limit 10")
df.show()
EOF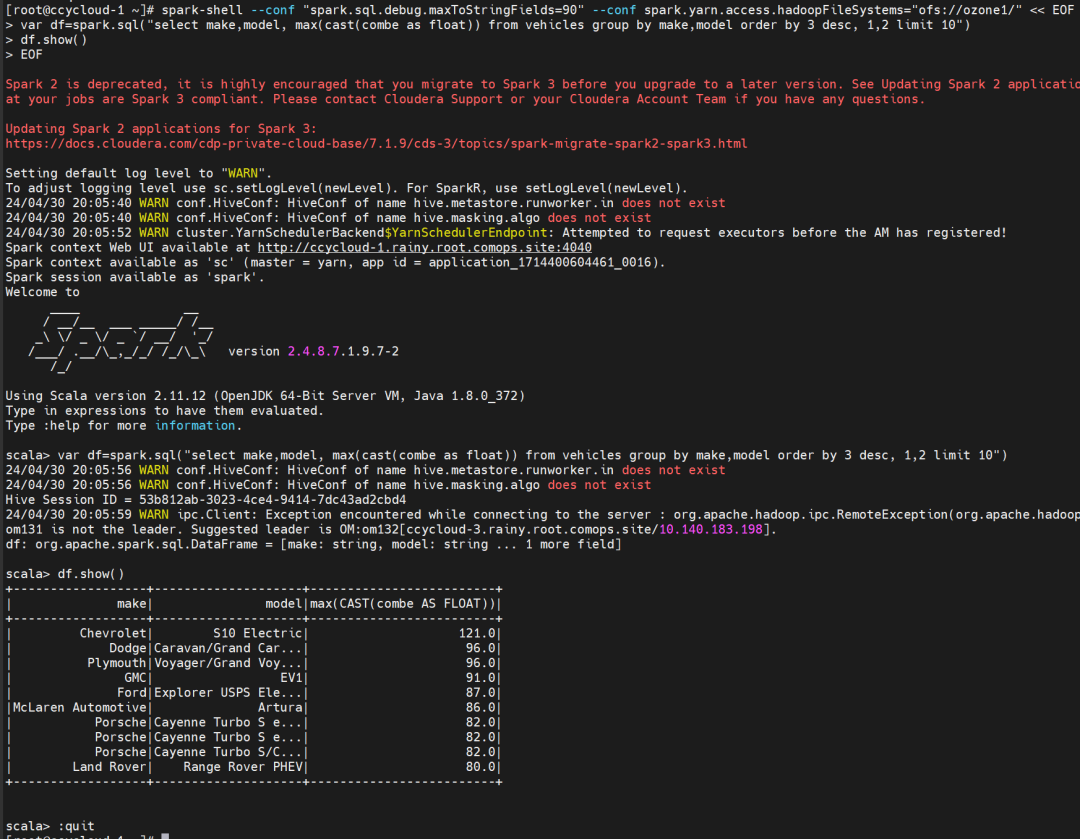
2 使用Hive访问Ozone
1.在Hive中建表
CREATE EXTERNAL TABLE `hive_vehicles`(
`barrels08` string,`barrelsa08` string,`charge120` string,`charge240` string,`city08` string,`city08u` string,`citya08` string,`citya08u` string,`citycd` string,`citye` string,`cityuf` string,`co2` string,`co2a` string,`co2tailpipeagpm` string,`co2tailpipegpm` string,`comb08` string,`comb08u` string,`comba08` string,`comba08u` string,`combe` string,`combinedcd` string,`combineduf` string,`cylinders` string,`displ` string,`drive` string,`engid` string,`eng_dscr` string,`fescore` string,`fuelcost08` string,`fuelcosta08` string,`fueltype` string,`fueltype1` string,`ghgscore` string,`ghgscorea` string,`highway08` string,`highway08u` string,`highwaya08` string,`highwaya08u` string,`highwaycd` string,`highwaye` string,`highwayuf` string,`hlv` string,`hpv` string,`id` string,`lv2` string,`lv4` string,`make` string,`model` string,`mpgdata` string,`phevblended` string,`pv2` string,`pv4` string,`range` string,`rangecity` string,`rangecitya` string,`rangehwy` string,`rangehwya` string,`trany` string,`ucity` string,`ucitya` string,`uhighway` string,`uhighwaya` string,`vclass` string,`year` string,`yousavespend` string,`guzzler` string,`trans_dscr` string,`tcharger` string,`scharger` string,`atvtype` string,`fueltype2` string,`rangea` string,`evmotor` string,`mfrcode` string,`c240dscr` string,`charge240b` string,`c240bdscr` string,`createdon` string,`modifiedon` string,`startstop` string,`phevcity` string,`phevhwy` string,`phevcomb` string)
row format delimited
fields terminated by ','
location 'ofs://ozone1/hive/warehouse/distcp/vehicles';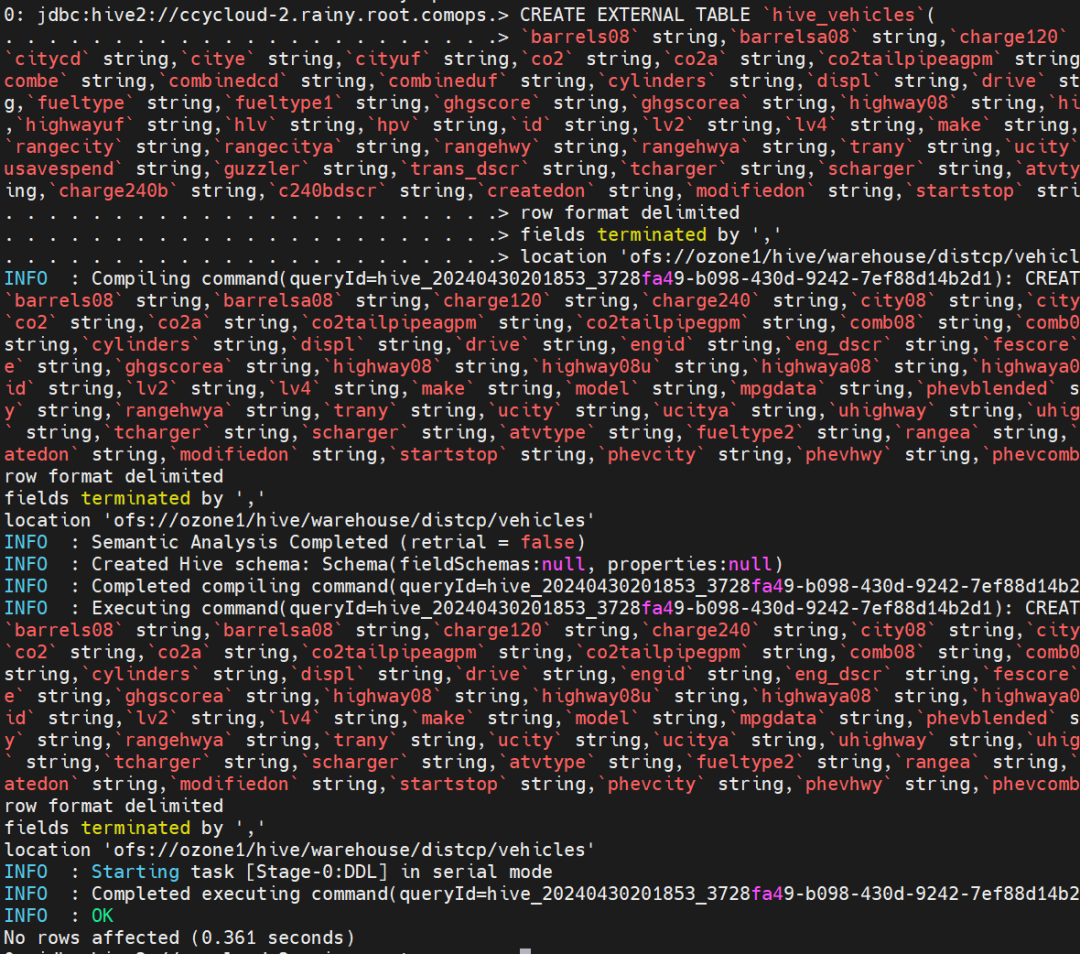
2.在Hive中执行以下SQL
alter table hive_vehicles set tblproperties('skip.header.line.count'='1');
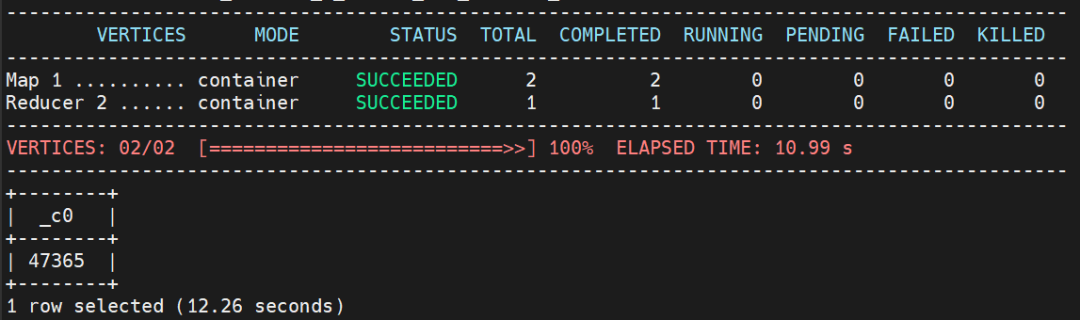
select count(*) from hive_vehicles;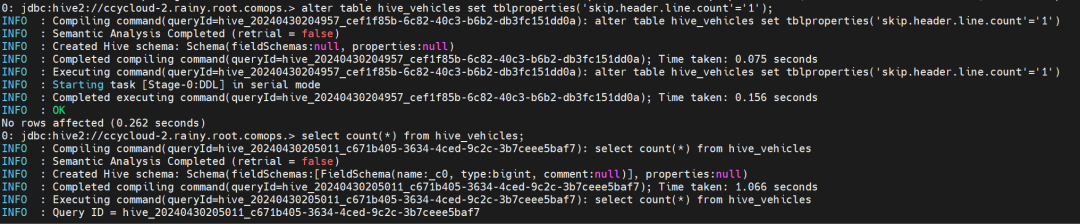
3.在Hive中执行以下SQL
select make, count(*) from hive_vehicles group by make order by 2 desc limit 10;
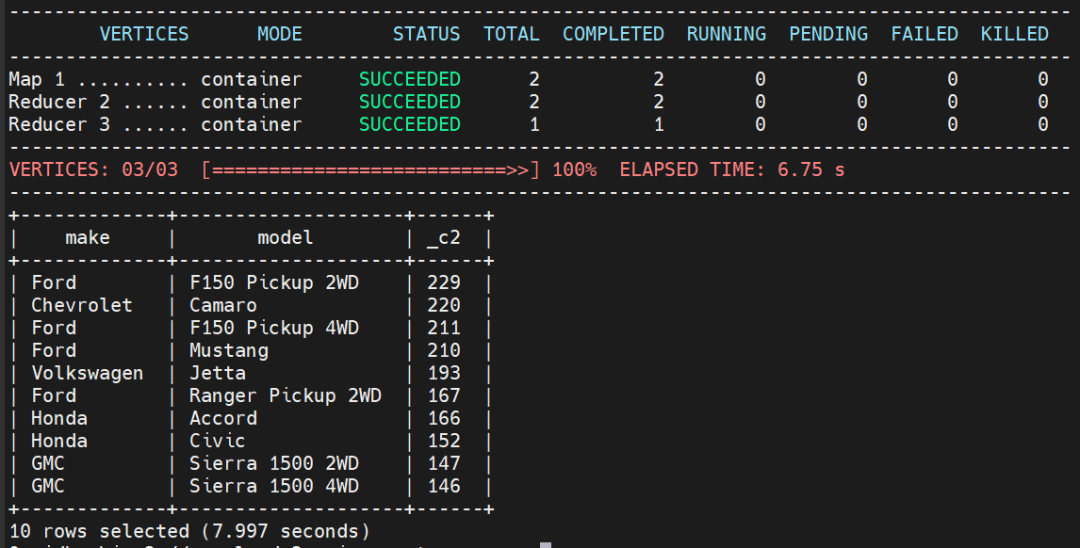
select make,model, count(*) from hive_vehicles group by make,model order by 3 desc limit 10;
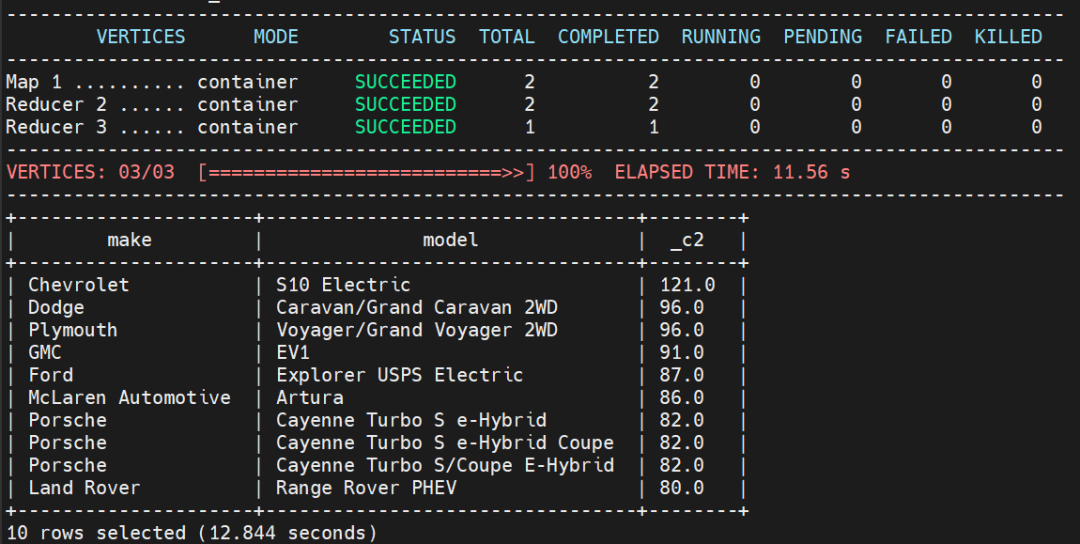
select make,model, max(cast(combe as float)) from hive_vehicles group by make,model order by 3 desc, 1,2 limit 10;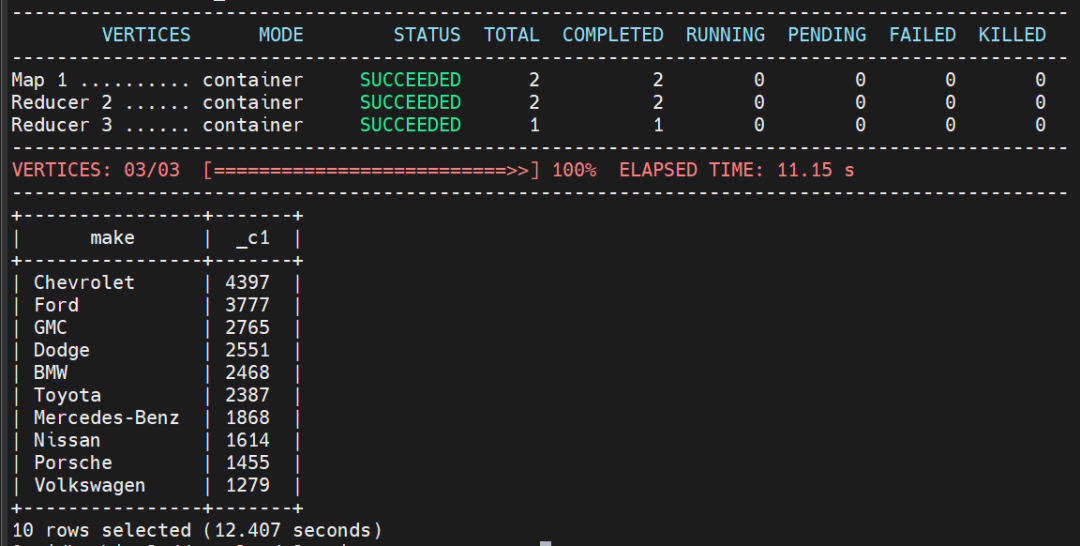
4.在Ozone下创建warehouse
CREATE DATABASE ozone_wh
LOCATION 'ofs://ozone1/hive/warehouse/external'
MANAGEDLOCATION 'ofs://ozone1/hive/warehouse/managed';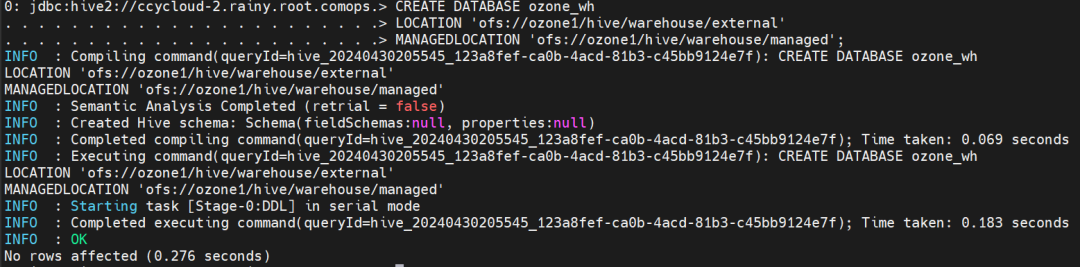
5.创建内表,并插入数据
create table ozone_wh.test_managed (name string, value string);
show create table ozone_wh.test_managed;
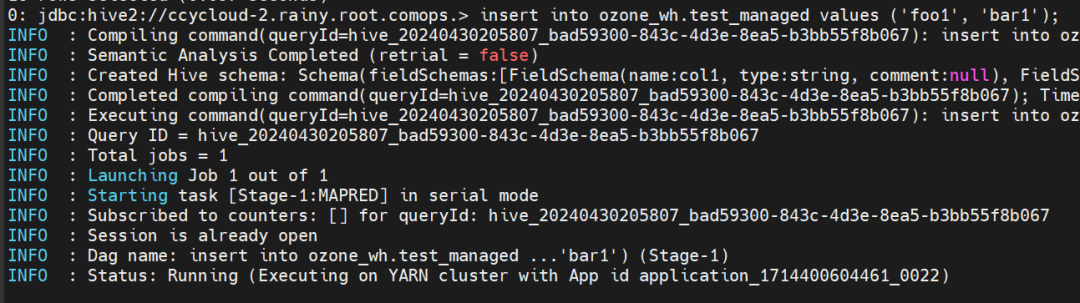
insert into ozone_wh.test_managed values ('foo1', 'bar1');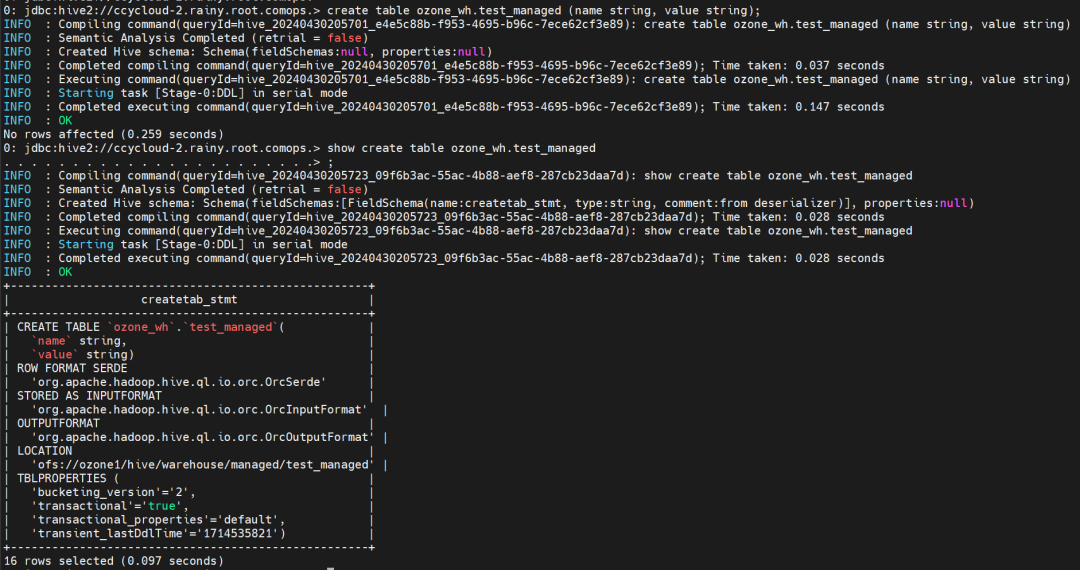
6.创建外表并插入数据:
create external table ozone_wh.test_external (name string, value string);
show create table ozone_wh.test_external;
insert into ozone_wh.test_external values ('foo1', 'bar1');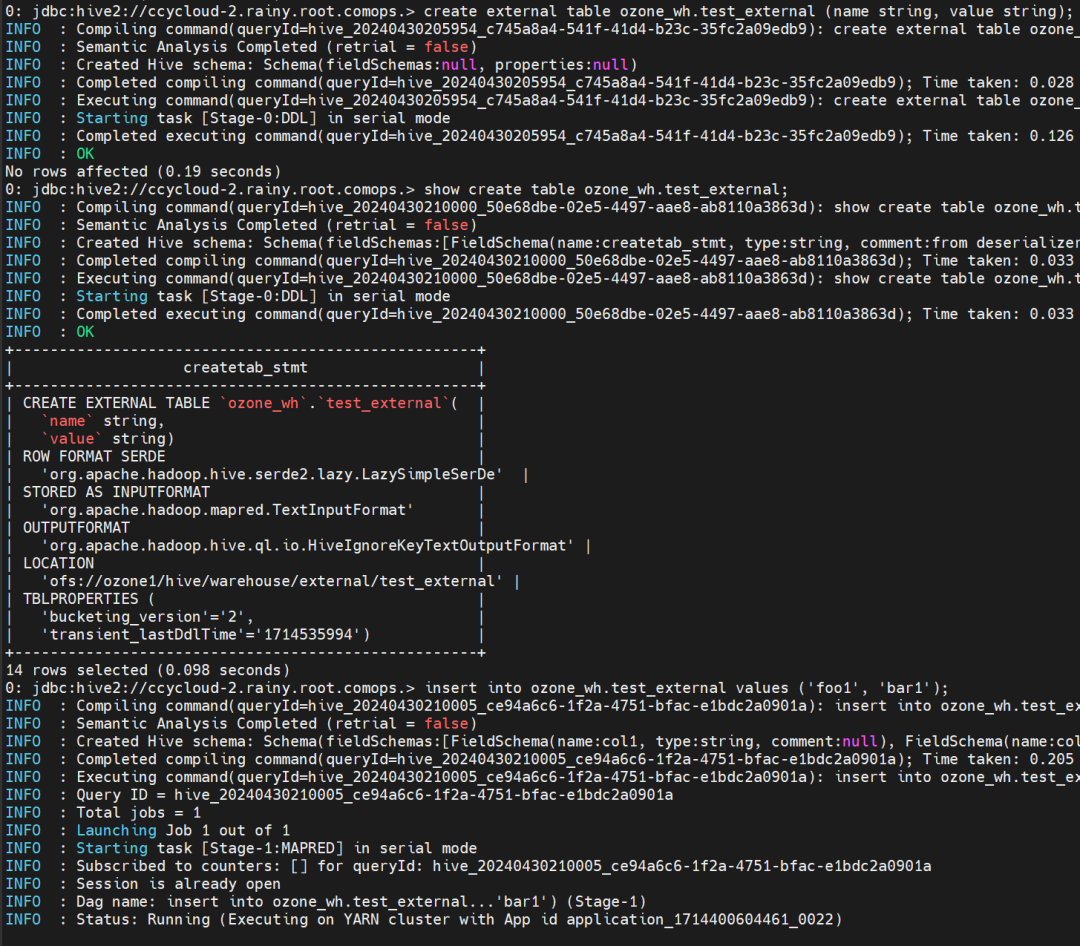
7.查看一下内外两个表在Ozone下的文件:
ozone fs -ls -R ofs://ozone1/hive/warehouse/managed
ozone fs -ls -R ofs://ozone1/hive/warehouse/external
本文参与 腾讯云自媒体分享计划,分享自微信公众号。
原始发表:2024-05-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录