NVIDIA Chat With RTX还没更新么?原来改头换面啦!
NVIDIA Chat With RTX还没更新么?原来改头换面啦!

51长假第二天,突然发现许久不更新的NVIDIA Chat With RTX聊天机器人,迎来的重大更新!
这次真的是改头换面,因为名字已经从Chat With RTX变成了ChatRTX,更加简洁,页面也更新了,彷佛之前的名字从来没出现过一样。
什么是ChatRTX
可能新朋友还不知道ChatRTX是什么。
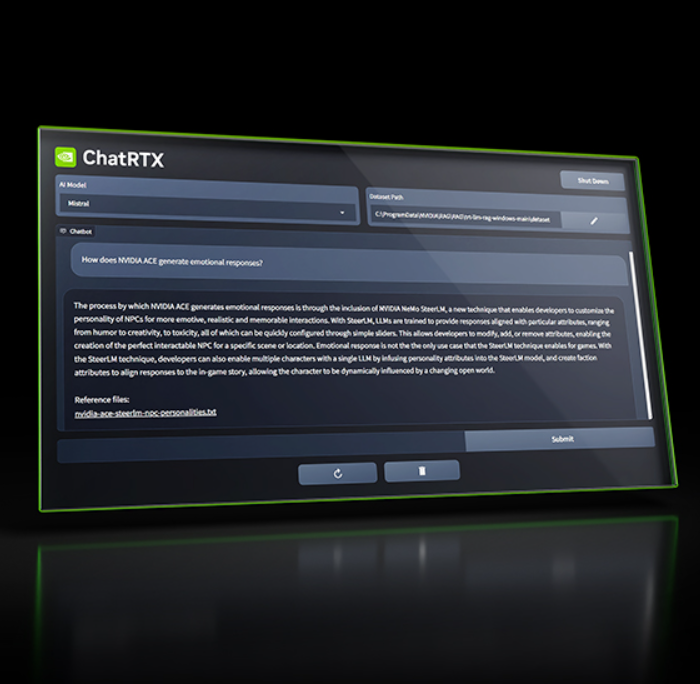
ChatRTX是NVIDIA推出的一款基于GPT(Generative Pre-trained Transformer)的聊天机器人示范程序,它结合了检索增强生成(Retrieval-Augmented Generation,RAG)技术与TensorRT-LLM软件,并通过RTX加速,为用户提供快速且准确的回答。
ChatRTX可以连接到用户自己的文件、笔记、图片或其他数据,并根据用户的需求提供相关信息和解答。该程序支持多种文件格式,如.txt、.pdf、.doc/.docx、.xml等,方便用户查询和检索各种类型的数据。
这次更新,使得ChatRTX具备语音查询能力,用户可以通过语音指令与机器人进行交互。新版本的ChatRTX还增加了对jpeg、gif及png等图片格式的支持,以及通过CLIP神经网络进行图像识别,进一步丰富了用户的数据查询方式。

ChatRTX支持多种开源大型语言模型,除了先前Mistral、Llama 2模型之外,这次加入了Google Gemma模型,这是Google DeepMind和其他Google团队共同开发的一系列轻量级、先进的开放模型。Gemma与Ready-to-use Colab和Kaggle笔记本以及与Hugging Face、MaxText、NVIDIA NeMo和TensorRT-LLM等流行工具的集成,使得入门变得非常容易。
ChatRTX还支持ChatGLM3模型,这个模型是由智谱AI和清华大学KEG实验室联合发布的新一代对话预训练模型。
ChatRTX的硬件条件
- ChatRTX 目前专为具有至少 8GB GPU 内存的 RTX 3xxx 和 RTX 4xxx 系列 GPU 构建(目前不支持 vGPU 配置)
- 至少 100 GB 可用硬盘空间
- Windows 10/11
- 最新的 NVIDIA GPU 驱动程序
安装Tips
安装过程中的注意事项:
- 安装程序将下载各种软件库、AI 模型权重和引擎文件。下载的总大小约为 11 GB,具体取决于所选的型号。下载和安装应该需要 10 到 30 分钟,具体取决于您的互联网连接和服务器上的负载。(全程挂梯子)
- 请确保在安装过程中禁用系统的睡眠功能
- 如果安装失败并显示错误消息。重新运行安装程序,它将从停止的位置恢复并继续安装过程
- 如果在安装某些组件后安装失败。请在下次安装尝试时选择“进行全新安装”。
- 即使安装程序包含大多数必需的大文件,它仍然必须从公共服务器下载一些文件。如果这些服务器关闭,则安装程序可能会失败或暂时停止
- 如果您选择将应用程序安装在默认安装位置以外的其他文件夹中,请确保文件夹路径或文件夹名称中没有空格。这是一个已知问题,将在将来的版本中修复
- 如果多次尝试后安装仍然失败,请在尝试安装之前删除以下文件夹:C:\Users\<username>\AppData\Local\NVIDIA\RAG
安装步骤
- 双击setup.exe文件以启动安装程序。安装程序将通过验证您的系统是否具有兼容的 GPU 来检查系统兼容性。
- 您可以选择默认安装文件夹,也可以通过单击“浏览”按钮并选择自定义文件夹位置来选择其他文件夹。
- 安装完成后,将创建一个桌面图标并启动应用程序。

- 将打开一个浏览器窗口选项卡,显示 ChatRTXUser 界面,如下图所示。同时,还将显示显示错误日志的 Windows 命令提示符。

与您的数据聊天
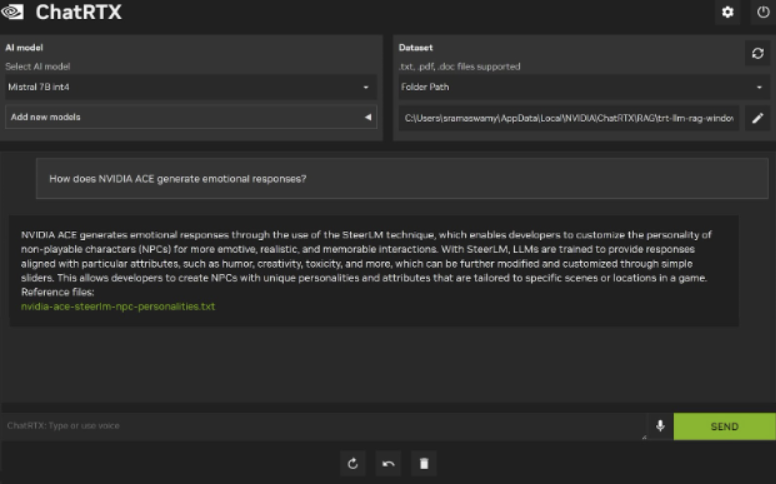
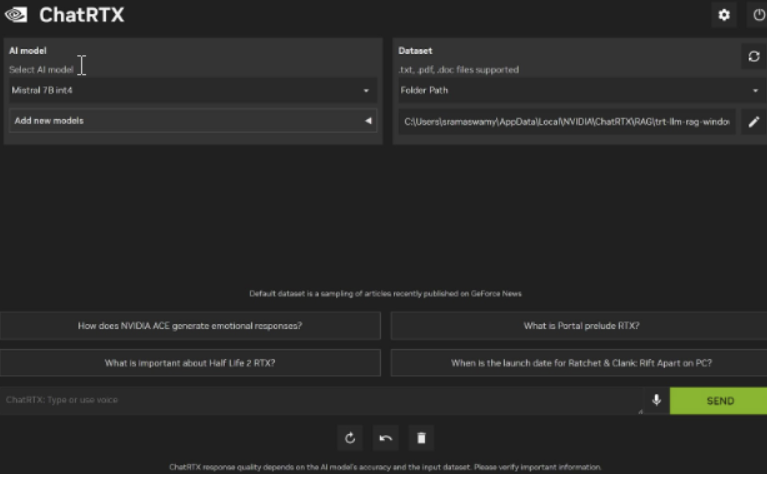
- 该应用程序将默认为 Mistral(特别是 Mistral 7B int4)模型和包含 GeForce 新闻文章集合的默认数据集文件夹。您可以就此新闻文章集进行聊天和提问,或将应用程序指向您自己的数据文件夹。
- 该应用程序目前适用于.txt、.pdf 和 .doc 文件格式。
- 您可以通过单击标有“选择 AI 模型”的选择框来选择您已安装的其他 TensorRT-LLM 兼容模型(例如 Llama 2 7B int4)
- 您可以通过单击“添加新模型”选项并从可用列表中选择一个模型将 AI 模型添加到应用程序。这会将 AI 模型下载到您的本地系统
- 您可以通过单击显示当前数据文件夹路径的行旁边的笔图标并导航到所需文件夹来指向所选数据集。默认数据集(首次启动时加载的数据集)是最近在 GeForce 新闻上发布的文章样本。此数据集的示例问题也以 UI 上的按钮形式提供。
- 选择新的数据文件夹时,应用程序必须使用所选文件夹中包含的文档重新创建数据集矢量嵌入。执行此操作所需的时间将因文件夹中文件的大小和数量而异。
- 应用程序重新创建矢量嵌入后,您可以与此新数据集聊天。
- 如果将新文件添加到所选文件夹,则必须重新生成文件夹的矢量嵌入。添加文件后,通过单击位于“数据集”单元格右侧的“刷新”图标重新生成嵌入
- 注意:回答的准确性和相关性取决于所提问题的具体性、所使用的人工智能模型的准确性以及数据集的准确性。
在没有数据集的情况下与ChatRTX聊天
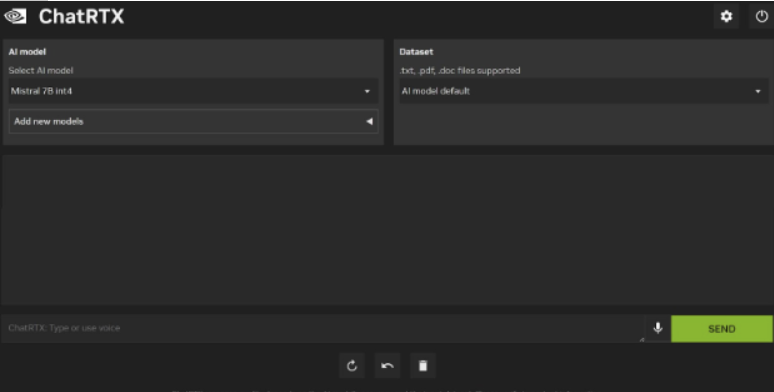
该应用程序使用一种称为检索增强生成 (RAG) 的技术来查找您指向的本地文件,并在向 LLM 提交您的问题时使用该信息提供上下文。禁用 RAG 将导致 LLM 完全基于最初训练的数据生成响应。为了查看 LLM 在没有 RAG 的情况下如何响应,您可以通过从右侧下拉菜单中选择“AI 模型默认值”来禁用 RAG(见下图)
使用CLIP视觉和语言模型
除了预安装的 Mistral LLM 模型外,您还可以从“添加新模型”选项下载并安装 CLIP 视觉和语言模型。安装模型后,您可以将应用程序指向您的 jpeg 图像文件夹并与您的图像聊天。这些图片不必标记。您可以提出诸如“向我展示有猫的图像”、“向我展示在户外拍摄的照片”、“向我展示有花朵的图像”等问题。对问题的回答的准确性取决于 CLIP 模型训练和准确性。
使用语音输入问题
此版本的 ChatRTX 还集成了进行音频到文本翻译的 Whisper 模型。要使用此功能,请确保系统上的麦克风已启用,然后单击“麦克风”图标并提出您的问题。问完问题后,单击“停止”图标停止录制。该应用程序将识别您的问题并将其输出到聊天窗口中。然后,您可以单击“发送”将文本呈现给 LLM 以获得响应。Whisper 模型支持多种语言,例如法语、西班牙语、普通话等。
查询结果
指引 ChatRTX 加载到向量库中的数据被分解成块(您可以将其视为文档中的段落),根据其相关性选择这些块来制定对查询的响应。这种存储数据的方法使 ChatRTX 适用于请求在整个数据集中几个块中涵盖的信息的查询,但不适合涉及一次对整个数据集进行推理的查询。例如,要求提供几份文件中涵盖的一些事实可能比要求提供一份或一组文件的摘
要产生更好的结果。
与大多数 AI 用例一样,响应质量往往会随着数据的增加而提高。将 ChatRTX 指向有关特定主题的更多内容往往会产生更好的响应。
已知bug
当前版本中存在以下已知问题
- 该应用程序目前适用于Microsoft Edge和Google Chrome浏览器。由于一个错误,该应用程序不适用于 FireFox 浏览器。这将在将来的版本中修复。
- 应用程序不记住上下文。这意味着后续问题不会根据先前问题的上下文得到回答。例如,如果你之前问过“RTX 4080 Super的价格是多少?”,然后问“它的硬件规格是什么?”,应用程序不会知道你在问RTX 4080 Super。
- 响应中的源文件归属并不总是正确的。这将在以后的版本中得到改进。
- 观察到一些应用程序卡在无法使用状态的情况下,无法通过重新启动来解决。这通常可以通过删除preferences.json文件来解决(默认情况下位于 C:\Users\<user>\AppData\Local\NVIDIA\ChatWithRTX\RAG\trt-llm-rag-windows-main\config\preferences.json)
- 在极少数情况下,重新安装失败,请尝试删除安装目录(默认位于 C:\Users\<user>\AppData\Local\NVIDIA\ChatWithRTX)
- 如果您选择将应用程序安装在默认安装位置以外的其他文件夹中,请确保文件夹路径或文件夹名称中没有空格