为什么会出现cpu使用率偶数核比奇数核高
原创
偶有云上用户反馈云主机cpu使用率偶数核比奇数核高的现象,比如cpu0高,cpu1低,cpu2高,cpu3低依次循环,这里的原因是开启超线程后一个物理core包含两个超线程,比如vcpu0/vcpu1是一个物理core的两个超线程,vcpu2/vcpu3也是一个物理core的两个超线程,抛开cpu wake_affine因素,linux内核在调度选核时如果有空闲的物理core会优先选择两个超线程都是空闲的物理core来运行进程以实现core间负载均衡,如果没有空闲的物理core也会选择最空闲的调度组。以此问题为引本文尝试分析下linux内核的调度选核策略,文中涉及的实验软硬件环境基于tencentos 5.4内核和Intel x86服务器。
在讲具体的问题之前我们先了解下调度域、调度组与物理拓扑结构之间的关系
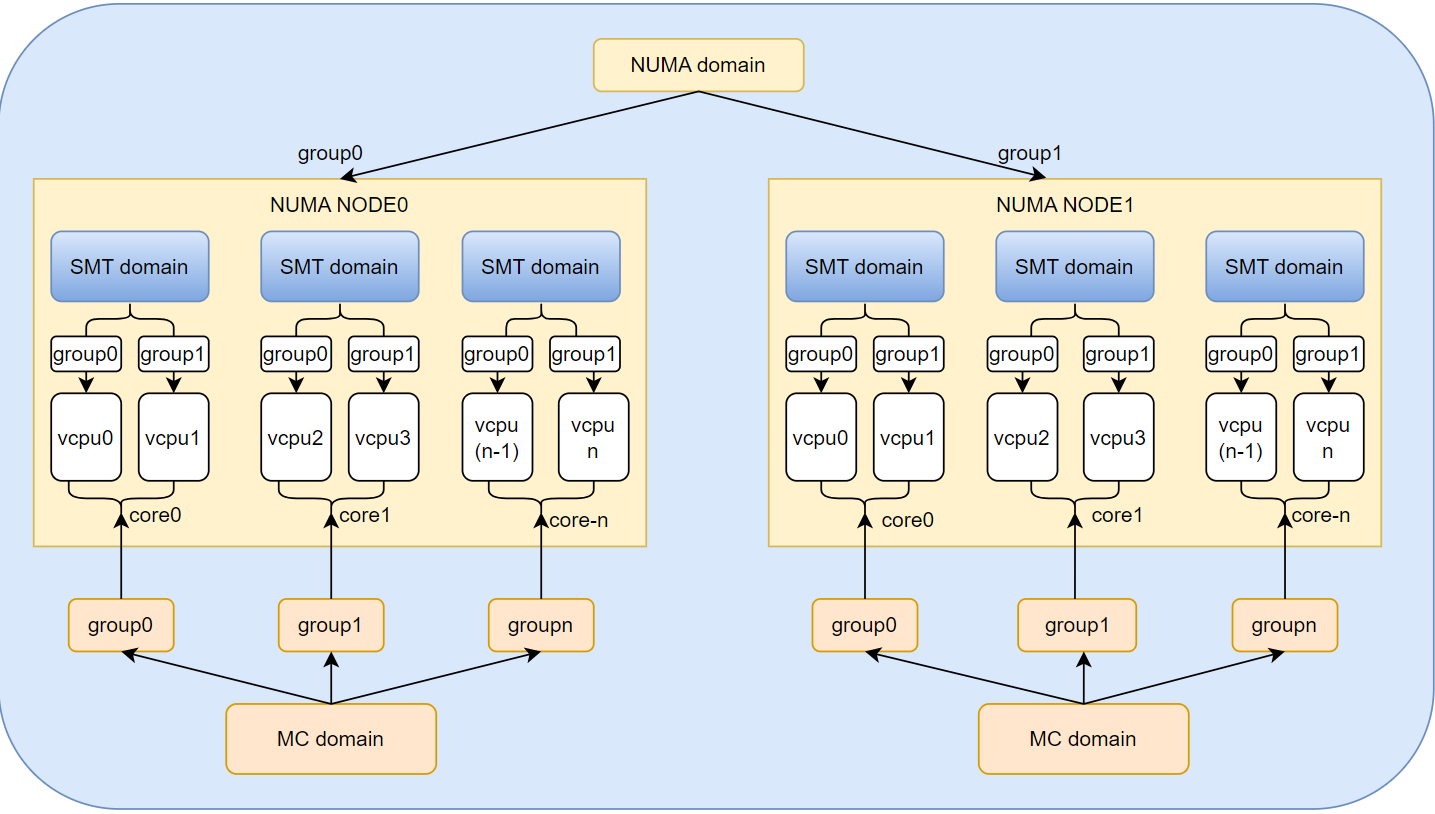
如果机器只有一个NUMA node且未开启超线程,那么系统看到的只有一个MC domain。
如上图1所示这里以双socket和开启超线程的intel cpu为例,主机包含两个socket,每个socket为一个NUMA NODE,每个NUMA包含多个物理core,每个物理core包含两个超线程,一个超线程对应一个vcpu。
内核会根据物理拓扑结构建立对应层次的调度域,调度域schedule domain分为三个层次,从低到高依次为SMT domain,MC domain和NUMA domain,SMT即为simultaneous multi-threading,一个物理core的所有超线程在一个SMT domain中,如上图所示一个SMT domain包含一个物理core的两个超线程。MC为 multi-core,同一个NUMA node的所有物理核中的超线程都在一个MC调度域内。NUMA domain包含SoC的所有超线程,如上图1所示包含两个NUMA NODE的所有超线程。
第一层sd (SMT domain):
如上图1所示每个core包含两个2个超线程构成了 SMT 域, 物理core的一对超线程共享了 L1 与 L2。
第二层sd (MC domain):
如上图1所示NUMA NODE0中core0 与 core1以及core(n),他们位于同一个 SOCKET属于同一个 MC 域,共享 LLC。
第三层sd (NUMA domain):
如上图1所示的 NUMA NODE0和 NUMA NODE1,属于一个NUMA domain,每个NUMA NODE会有自己的LLC。
内核会根据物理拓扑结构建立对应层次的调度域sched_domain,然后在每层调度域上再建立相应的调度组sched_group。
以一个124个vcpu双NUMA且开启超线程的主机为例来介绍说明内核sched_domain和sched_group关系
主机两个Socket,每个Scoket有31个物理core共62个超线程vcpu,
vcpu0-vcpu61位于Socket0,vcpu62-vcpu123位于Socket1:
# lscpu | grep -E "CPU(s)|NUMA node|Socket|Thread|Core"
Thread(s) per core: 2
Core(s) per socket: 31
Socket(s): 2
NUMA node(s): 2
NUMA node0 CPU(s): 0-61
NUMA node1 CPU(s): 62-123内核会根据物理拓扑结构建立对应层次的调度域sched_domain,每个vcpu都有定义独立的sched_domain和sched_group来表示per cpu的schedule domain和schedule group,每层的调度域会通过sched_domain.parent 和sched_domain.child 关联起来。
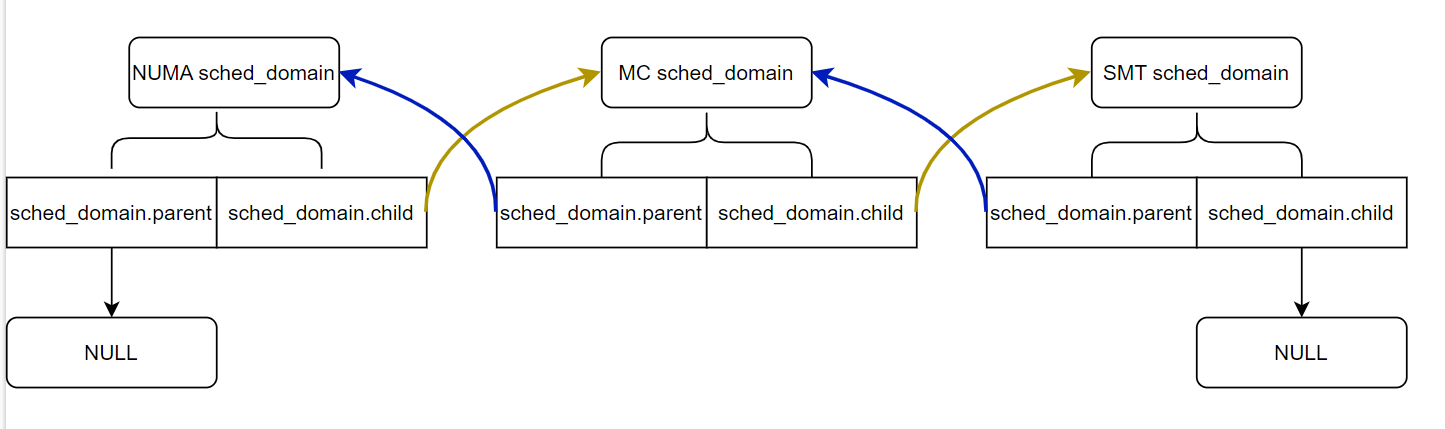
per vcpu有一个独立的runq,每个rq.sd指向独立的sched_domain 地址,因此通过per cpu的rq.sd使用率live crash可以查看每个vcpu对应的sched_domain地址来获取其关联的SMT,MC以及NUMA调度域信息:
系统proc接口可以查看每个调度域的名字:
[root@VM-1-4-tencentos ~]# cat /proc/sys/kernel/sched_domain/cpu0/domain0/name
SMT
[root@VM-1-4-tencentos ~]# cat /proc/sys/kernel/sched_domain/cpu0/domain1/name
MC
[root@VM-1-4-tencentos ~]# cat /proc/sys/kernel/sched_domain/cpu0/domain2/name
NUMA
以vcpu0的runq为例:
crash> runq | head -1
CPU 0 RUNQUEUE: ffff88b492229980
crash> rq.sd ffff88b492229980
sd = 0xffff88b48aa23e00 //sched_domain
vcpu0关联的SMT调度域sched_domain,smt domain包含一对超线程的两个vcpu
crash> struct sched_domain.name,parent,child,span,span_weight 0xffff88b48aa23e00
name = 0xffffffff8253e5db <kallsyms_token_index+59507> "SMT" //SMT domain名
parent = 0xffff88b48a4dbe00 //指向SMT domain的上一级调度域MC调度域
child = 0x0
span = 0xffff88b48aa23f20 //vcpu0所在SMT调度域关联的cpumask,表示该smt调度域包含哪些超线程号
span_weight = 2//该调度域下包含的cpu数量
crash> cpumask 0xffff88b48aa23f20 -x
struct cpumask {
bits = {0x3, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x90004000, 0x0, 0x1, 0xffffc9000d20c000, 0x420804000000002, 0x0, 0x0, 0x3700000000, 0x4, 0xfffb706a, 0xffff88ea8be9c000, 0x3700000037, 0x7800000000, 0x7800000078, 0x0, 0xffffffff82260540, 0x100000, 0x400000, 0x100000, 0x1, 0x0, 0x0, 0xffff88b48aa240b0, 0xffff88b48aa240b0, 0x0, 0xd4da92e6, 0x26554, 0xffffffffff3b4a54, 0x1fe63, 0x1, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffff88b492fe9a00, 0x0, 0x0, 0x0, 0x0, 0xd4da9000, 0x1a, 0x1a, 0x2a400006be6, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffff88b48aa24280, 0xffff88b48aa24280, 0x0, 0x0, 0x64, 0x0, 0x0, 0xffff88b492fe9bc0, 0x0, 0xffffffff83149580, 0xffff88b48aa242d0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0}
}
crash> eval -b 0x3 //vcpu0的SMT调度域包含vcpu0和vcpu1一对超线程
bits set: 1 0
crash>
vcpu0关联的MC调度域sched_domain:
crash> struct sched_domain.name,parent,child,span,span_weight 0xffff88b48a4dbe00
name = 0xffffffff82534eb3 <kallsyms_token_index+20811> "MC"
parent = 0xffff88b48a4f3e00 //指向MC domain的上一级调度域NUMA调度域
child = 0xffff88b48aa23e00 //指向MC domain的下一级调度域SMT调度域
span = 0xffff88b48a4dbf20 //vcpu0所在MC调度域关联的cpumask,表示该MC调度域包含哪些超线程号
span_weight = 62
crash>
vcpu0的MC调度域包含NUMA NODE0上vcpu0~vcpu61所有vcpu:
crash> cpumask 0xffff88b48a4dbf20 -x
struct cpumask {
bits = {0x3fffffffffffffff, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffff88b48a4f2800, 0xffff88b48a48c400, 0xffff88b48a424440, 0x3e, 0x7c, 0x7500000020, 0x100000001, 0x10000122f, 0x1023a4805, 0x7c, 0x1853, 0x1023a4c05, 0x101, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffffffff82534eb3, 0xffff88ea8afaf858, 0x0, 0xffff88b48a90c350, 0x3e, 0x3fffffffffffffff, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffff88b48a4f2600, 0xffff88b48a48c600, 0xffff88b48a424540, 0x3e, 0x7c, 0x7500000020, 0x100000001, 0x10000122f, 0x1023a4874, 0x7c, 0x2050, 0x1023a4a3a, 0x9b, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffffffff82534eb3, 0xffff88ea8afaf858, 0x0, 0xffff88b48a90c350, 0x3e}
}
crash> eval -b 0x3fffffffffffffff
bits set: 61 60 59 58 57 56 55 54 53 52 51 50 49 48 47 46 45 44 43 42 41 40
39 38 37 36 35 34 33 32 31 30 29 28 27 26 25 24 23 22 21 20 19 18
17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
crash>
crash>
crash> struct sched_domain.name,parent,child,span,span_weight 0xffff88b48a4f3e00
name = 0xffffffff8254d687 <kallsyms_token_index+121119> "NUMA"
parent = 0x0
child = 0xffff88b48a4dbe00 //指向NUMA domain的下一级调度域MC调度域
span = 0xffff88b48a4f3f20 //vcpu0所在NUMA调度域关联的cpumask,表示该NUMA调度域包含哪些超线程号
span_weight = 124
crash>
vcpu0的NUMA调度域包含两个NUMA NODE上vcpu0~vcpu123所有vcpu,
cpumask为unsigned long类型,数组bits[0]对应的0-63号vcpu,bits[1]对应的vcpu号为(64+x)对应64~123
crash> cpumask 0xffff88b48a4f3f20 -x
struct cpumask {
bits = {0xffffffffffffffff, 0xfffffffffffffff, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffff88b48a4dcc00, 0xffff88b48a42d3c0, 0x7c, 0xf8, 0x7d00000020, 0x2, 0x40000642f, 0x1023edcd3, 0xf8, 0x38ca, 0x1023ee143, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffffffff8254d687, 0xffff88ea8afaf918, 0x0, 0x0, 0x7c, 0xffffffffffffffff, 0xfffffffffffffff, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffff88b48a4dce00, 0xffff88b48a42d440, 0x7c, 0xf8, 0x7d00000020, 0x2, 0x40000642f, 0x1023edc9a, 0xf8, 0x59a1, 0x1023ee082, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffffffff8254d687, 0xffff88ea8afaf918, 0x0, 0x0, 0x7c}
}
crash> eval -b 0xffffffffffffffff
bits set: 63 62 61 60 59 58 57 56 55 54 53 52 51 50 49 48 47 46 45 44 43 42
41 40 39 38 37 36 35 34 33 32 31 30 29 28 27 26 25 24 23 22 21 20
19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
crash>
因为vcpu1跟vcpu0是一个物理core的两个超线程,因此两个vcpu的
SMT调度域sched_domain.span对应的cpumask包含的cpu号上相同的,这里都包含vcpu0和vcpu1.
crash> runq | grep "CPU 1 RUNQUEUE"
CPU 1 RUNQUEUE: ffff88b492269980
crash> rq.sd ffff88b492269980
sd = 0xffff88b48aa23c00
crash> struct sched_domain.name,parent,child,span 0xffff88b48aa23c00
name = 0xffffffff8253e5db <kallsyms_token_index+59507> "SMT"
parent = 0xffff88b48a4dbc00
child = 0x0
span = 0xffff88b48aa23d20
crash>
crash> cpumask 0xffff88b48aa23d20 -x
struct cpumask {
bits = {0x3, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffff88b48a4dbe00, 0x0, 0xffff88b48ab5d040, 0x2, 0x4, 0x6e00000020, 0x0, 0x12af, 0x10238aa74, 0x4, 0x472, 0x10238ab48, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffffffff8253e5db, 0xffff88ea8afaf818, 0x0, 0xffff88b48a90cff0, 0x2, 0x3, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x90004000, 0x0, 0x1, 0xffffc9000d20c000, 0x420804000000002, 0x0, 0x0, 0x3700000000, 0x4, 0xfffb706a, 0xffff88ea8be9c000, 0x3700000037, 0x7800000000, 0x7800000078, 0x0, 0xffffffff82260540, 0x100000, 0x400000, 0x100000, 0x1, 0x0, 0x0, 0xffff88b48aa240b0, 0xffff88b48aa240b0, 0x0, 0xd4da92e6, 0x26554, 0xffffffffff3b4a54, 0x1fe63, 0x1, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0}
}
crash> eval -b 0x3
bits set: 1 0
crash> SMT域是最底层的调度域,smt domain包含一对超线程.smt domain 里有两个 sched_group,而每个 sched_group 则只会有一个vcpu,所以 smt 域的负载均衡就是执行超线程间的进程迁移,perf cpu SMT domain下的两个sched_group相互关联,其中sched_group.cpumask记录对应vcpu掩码位,比如vcpu3的smt domain下的schedule_group.cpumask的bit3为1.
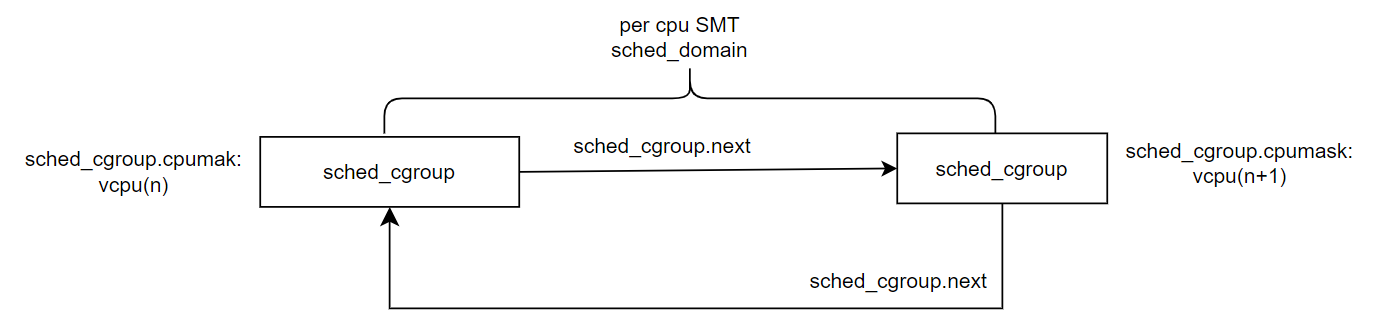
以vcpu0和vcpu1这一对超线程为例,介绍SMT domain 两个sched_group的关系
crash> runq |grep -wE "CPU 0|CPU 1"
CPU 0 RUNQUEUE: ffff88b492229980
CPU 1 RUNQUEUE: ffff88b492269980
vcpu0 对应sched_group信息:
crash> rq.sd ffff88b492229980
sd = 0xffff88b48aa23e00
crash> struct sched_domain.name,groups 0xffff88b48aa23e00
name = 0xffffffff8253e5db <kallsyms_token_index+59507> "SMT"//调度域名
groups = 0xffff88b48ab5d040//smt调度域对应的sched_group
crash> struct sched_group.cpumask,next 0xffff88b48ab5d040
cpumask = 0xffff88b48ab5d070 //sched_group包含哪些vcpu号
next = 0xffff88b48ab5df80 //指向同一个物理core的另外一个超线程sched_group,
//这里指向vcpu1的sched_group
cpumask的bit0为1对应vcpu0
crash> cpumask 0xffff88b48ab5d070 -x
struct cpumask {
bits = {0x1, 0x0, 0xffff88b48ab5d100, 0x100000002, 0xffff88b48a423000, 0x0, 0x0, 0x0, 0x80000000, 0x0, 0x2, 0x400, 0x400, 0x400, 0x102adc1da, 0x1e00000000, 0x40000000, 0x0, 0xffff88b48ab5d080, 0x100000002, 0xffff88b48ab5d0c0, 0x0, 0x0, 0x0, 0x40000000, 0x0, 0x2, 0x400, 0x400, 0x400, 0x102adc1db, 0x1d00000000, 0x20000000, 0x0, 0xffff88b48ab5d200, 0x100000002, 0xffff88b48ab5d140, 0x0, 0x0, 0x0, 0x20000000, 0x0, 0x2, 0x400, 0x400, 0x400, 0x102adc1a8, 0x1c00000000, 0x10000000, 0x0, 0xffff88b48ab5d180, 0x100000002, 0xffff88b48ab5d1c0, 0x0, 0x0, 0x0, 0x10000000, 0x0, 0x2, 0x400, 0x400, 0x400, 0x102adc1d9, 0x1b00000000, 0x8000000, 0x0, 0xffff88b48ab5d300, 0x100000002, 0xffff88b48ab5d240, 0x0, 0x0, 0x0, 0x8000000, 0x0, 0x2, 0x400, 0x400, 0x400, 0x102adc1d7, 0x1a00000000, 0x4000000, 0x0, 0xffff88b48ab5d280, 0x100000002, 0xffff88b48ab5d2c0, 0x0, 0x0, 0x0, 0x4000000, 0x0, 0x2, 0x400, 0x400, 0x400, 0x102adc1b3, 0x1900000000, 0x2000000, 0x0, 0xffff88b48ab5d400, 0x100000002, 0xffff88b48ab5d340, 0x0, 0x0, 0x0, 0x2000000, 0x0, 0x2, 0x400, 0x400, 0x400, 0x102adc1aa, 0x1800000000, 0x1000000, 0x0, 0xffff88b48ab5d380, 0x100000002, 0xffff88b48ab5d3c0, 0x0, 0x0, 0x0, 0x1000000, 0x0, 0x2, 0x400, 0x400, 0x400, 0x102adc1db, 0x1700000000}
}
crash> eval -b 0x1
bits set: 0
crash>
vcpu1 对应sched_group信息:
crash> rq.sd ffff88b492269980
sd = 0xffff88b48aa23c00
crash> struct sched_domain.name,groups 0xffff88b48aa23c00
name = 0xffffffff8253e5db <kallsyms_token_index+59507> "SMT"
groups = 0xffff88b48ab5df80//smt调度域对应的sched_group
crash> struct sched_group.cpumask,next,group_weight 0xffff88b48ab5df80
cpumask = 0xffff88b48ab5dfb0 //sched_group包含哪些vcpu号
next = 0xffff88b48ab5d040 //指向同一个物理core的另外一个超线程sched_group,
//这里指向vcpu0的sched_group
group_weight = 1 //该调度组下只有一个vcpu
cpumask的bit1为1对应vcpu1
crash> cpumask 0xffff88b48ab5dfb0 -x
struct cpumask {
bits = {0x2, 0x0, 0x2, 0x400, 0x400, 0x400, 0x102ae674e, 0x0, 0x1, 0x0, 0x1, 0x4f, 0xffff88ea8be74a30, 0x0, 0x0, 0xffff88b48ab5e028, 0xffff88b48ab5e028, 0x0, 0x0, 0xffff88b48ab5e048, 0xffff88b48ab5e048, 0x0, 0x1, 0x4f, 0xffff88ea8be74a40, 0x0, 0x0, 0xffff88b48ab5e088, 0xffff88b48ab5e088, 0x0, 0x0, 0xffff88b48ab5e0a8, 0xffff88b48ab5e0a8, 0x0, 0xffff88b48ab5ec00, 0xffff88b48ab5e0c0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffff88b492ce9bc0, 0xffff88b47ecf2000, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffff88ea8b02c840, 0x0, 0x0, 0xffff88b48ab5e148, 0xffff88b48ab5e148, 0x0, 0x0, 0xffff88b48ab5e168, 0xffff88b48ab5e168, 0x0, 0x1, 0x50, 0xffff88ea8be74a70, 0x0, 0x0, 0xffff88b48ab5e1a8, 0xffff88b48ab5e1a8, 0x0, 0x0, 0xffff88b48ab5e1c8, 0xffff88b48ab5e1c8, 0x0, 0x1, 0x50, 0xffff88ea8be74a80, 0x0, 0x0, 0xffff88b48ab5e208, 0xffff88b48ab5e208, 0x0, 0x0, 0xffff88b48ab5e228, 0xffff88b48ab5e228, 0x0, 0x1, 0x50, 0xffff88ea8be74a90, 0x0, 0x0, 0xffff88b48ab5e268, 0xffff88b48ab5e268, 0x0, 0x0, 0xffff88b48ab5e288, 0xffff88b48ab5e288, 0x0, 0xffff88b48ab5ede0, 0xffff88b48ab5e2a0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffff88b492de9bc0, 0xffff88b47ecf0000, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffff88ea8b02ca80, 0x0, 0x0, 0xffff88b48ab5e328, 0xffff88b48ab5e328, 0x0, 0x0, 0xffff88b48ab5e348, 0xffff88b48ab5e348, 0x0, 0x1, 0x51, 0xffff88ea8be74ac0, 0x0, 0x0, 0xffff88b48ab5e388, 0xffff88b48ab5e388, 0x0, 0x0, 0xffff88b48ab5e3a8}
}
crash> eval -b 0x2
bits set: 1
crash> MC schedule domain则是由单个NUMA NODE上 所有的 CPU 组成,而其中每个 schedule group则为下级smt domain 的所有CPU构成,也就是MC schedule domain的每个schedule group包含一对超线程的两个vcpu。
如下图所示一个物理核的两个超线程指向同一个schedule group, sched_group.cpumask记录一个物理核两个vcpu的掩码位,vcpu0/vcpu1为一个物理core的一对超线程,vpu0-vcpu61为这里实验环境一个NUMA NODE0上的所有62个vcpu。
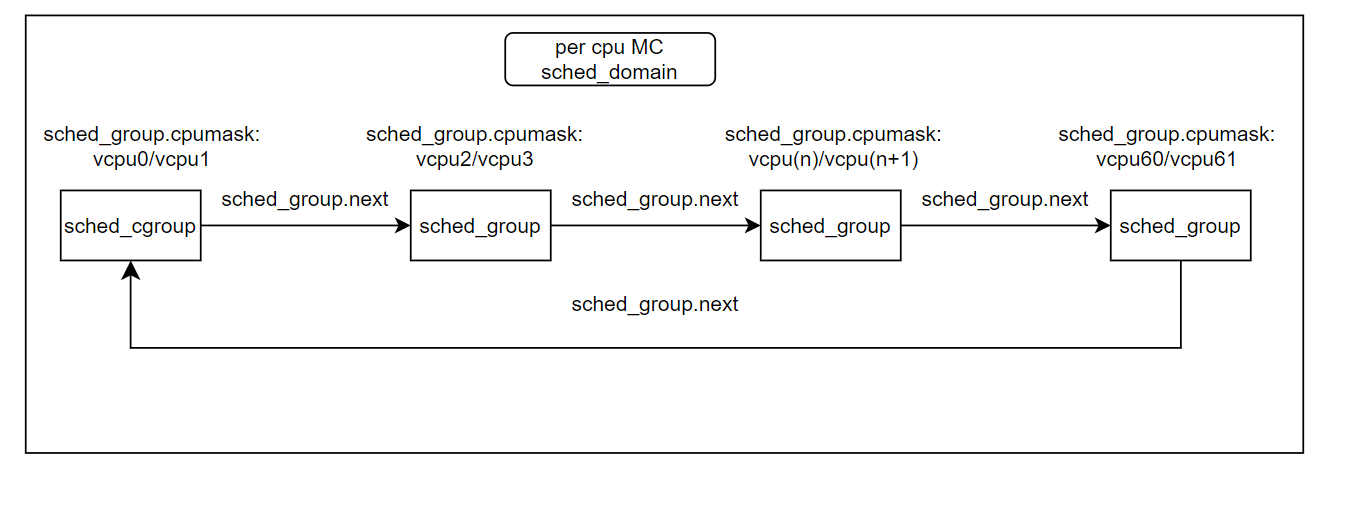
如下信息可以看到vcpu0和vcpu1这一对超线程各自的MC sched_domain.groups是同一个地址,
说明一对超线程用的是一个schedule group
crash> runq |grep -wE "CPU 0|CPU 1"
CPU 0 RUNQUEUE: ffff88b492229980
CPU 1 RUNQUEUE: ffff88b492269980
crash>
crash>
crash> rq.sd ffff88b492229980
sd = 0xffff88b48aa23e00
crash> struct sched_domain.name,parent 0xffff88b48aa23e00
name = 0xffffffff8253e5db <kallsyms_token_index+59507> "SMT"
parent = 0xffff88b48a4dbe00
crash> struct sched_domain.name,groups 0xffff88b48a4dbe00
name = 0xffffffff82534eb3 <kallsyms_token_index+20811> "MC"
groups = 0xffff88b48a423fc0
crash> struct sched_group.cpumask,next,group_weight 0xffff88b48a423fc0
cpumask = 0xffff88b48a423ff0
next = 0xffff88b48a424040 //指向同MC schedule domain的下一个schedule group,
//这里vcpu0和vcpu1的schedule_group.next都是
//指向vcpu2和vcpu3的sched_group
group_weight = 2 //该调度组下有两个vcpu
crash> cpumask 0xffff88b48a423ff0 -x
struct cpumask {
bits = {0x3, 0x0, 0xffff88b48a424100, 0xffff88ea8a9745c0, 0xffffffff82273f10, 0xffff88ea89c7b250, 0x1, 0x100000000, 0x0, 0x0, 0xffff88b48a424140, 0x20000003e, 0xffff88b48a424080, 0x0, 0x0, 0x0, 0xc, 0x0, 0x3e, 0x800, 0x400, 0x400, 0x102c0fbe2, 0x200000000, 0xc, 0x0, 0xffff88b48a4241c0, 0xffff88b48a423f40, 0xffff88b48a424000, 0xffffffff82cc79a0, 0xffff88ea8b950460, 0x1700000001, 0x0, 0x0, 0xffff88b48a424200, 0xffff88b48a424000, 0xffffffff82559fd4, 0xffff88ea89c7b240, 0x1, 0x300000000, 0x0, 0x0, 0xffff88b48a424240, 0x20000003e, 0xffff88b48a424180, 0x0, 0x0, 0x0, 0x30, 0x0, 0x3e, 0x800, 0x400, 0x400, 0x102c0fc3f, 0x400000000, 0x30, 0x0, 0xffff88b48a4242c0, 0xffff88b48a4240c0, 0xffff88b48a424100, 0xffffffff82cc79a0, 0xffff88ea8b92e540, 0xf00000001, 0x0, 0x0, 0xffff88b48a424300, 0xffff88b48a424100, 0xffffffff82263ee0, 0xffff88ea89c7b230, 0x1, 0x500000000, 0x0, 0x0, 0xffff88b48a424340, 0x20000003e, 0xffff88b48a424280, 0x0, 0x0, 0x0, 0xc0, 0x0, 0x3e, 0x800, 0x400, 0x400, 0x102c0fbf4, 0x600000000, 0xc0, 0x0, 0xffff88b48a4243c0, 0xffff88b48a4241c0, 0xffff88b48a424200, 0xffffffff82cc79a0, 0xffff88b491a01260, 0xd00000001, 0x0, 0x0, 0xffff88b48a424400, 0xffff88b48a424200, 0xffffffff82263a13, 0xffff88ea89c7b220, 0x1, 0x700000000, 0x0, 0x0, 0xffff88b48a424440, 0x20000003e, 0xffff88b48a424380, 0x0, 0x0, 0x0, 0x300, 0x0, 0x3e, 0x800, 0x400, 0x400, 0x102c0fc0d, 0x800000000, 0x300, 0x0, 0xffff88b48a4244c0, 0xffff88b48a4242c0, 0xffff88b48a424300, 0xffffffff82cc79a0, 0xffff88b4919e5500, 0x500000001}
}
crash> eval -b 0x3
bits set: 1 0
crash>
crash> runq |grep -wE "CPU 1"
CPU 1 RUNQUEUE: ffff88b492269980
crash>
crash> rq.sd ffff88b492269980
sd = 0xffff88b48aa23c00
crash> struct sched_domain.name,parent 0xffff88b48aa23c00
name = 0xffffffff8253e5db <kallsyms_token_index+59507> "SMT"
parent = 0xffff88b48a4dbc00
crash> struct sched_domain.name,groups 0xffff88b48a4dbc00
name = 0xffffffff82534eb3 <kallsyms_token_index+20811> "MC"
groups = 0xffff88b48a423fc0
crash> struct sched_group.cpumask,next 0xffff88b48a423fc0
cpumask = 0xffff88b48a423ff0
next = 0xffff88b48a424040 //指向同MC schedule domain的下一个schedule group,
//这里vcpu0和vcpu1的schedule_group.next都是
//指向vcpu2和vcpu3的sched_group
vcpu0和vcpu1的schedule_group.next指向关联vcpu2和vcpu3的sched_group,
对应的sched_group.cpumask可以看到包含vcpu2和vcpu3
crash> struct sched_group.cpumask,next 0xffff88b48a424040
cpumask = 0xffff88b48a424070
next = 0xffff88b48a424140
crash> cpumask 0xffff88b48a424070 -x
struct cpumask {
bits = {0xc, 0x0, 0x3e, 0x800, 0x400, 0x400, 0x102d44942, 0x200000000, 0xc, 0x0, 0xffff88b48a4241c0, 0xffff88b48a423f40, 0xffff88b48a424000, 0xffffffff82cc79a0, 0xffff88ea8b950460, 0x1700000001, 0x0, 0x0, 0xffff88b48a424200, 0xffff88b48a424000, 0xffffffff82559fd4, 0xffff88ea89c7b240, 0x1, 0x300000000, 0x0, 0x0, 0xffff88b48a424240, 0x20000003e, 0xffff88b48a424180, 0x0, 0x0, 0x0, 0x30, 0x0, 0x3e, 0x800, 0x400, 0x400, 0x102d448bc, 0x400000000, 0x30, 0x0, 0xffff88b48a4242c0, 0xffff88b48a4240c0, 0xffff88b48a424100, 0xffffffff82cc79a0, 0xffff88ea8b92e540, 0xf00000001, 0x0, 0x0, 0xffff88b48a424300, 0xffff88b48a424100, 0xffffffff82263ee0, 0xffff88ea89c7b230, 0x1, 0x500000000, 0x0, 0x0, 0xffff88b48a424340, 0x20000003e, 0xffff88b48a424280, 0x0, 0x0, 0x0, 0xc0, 0x0, 0x3e, 0x800, 0x400, 0x400, 0x102d44926, 0x600000000, 0xc0, 0x0, 0xffff88b48a4243c0, 0xffff88b48a4241c0, 0xffff88b48a424200, 0xffffffff82cc79a0, 0xffff88b491a01260, 0xd00000001, 0x0, 0x0, 0xffff88b48a424400, 0xffff88b48a424200, 0xffffffff82263a13, 0xffff88ea89c7b220, 0x1, 0x700000000, 0x0, 0x0, 0xffff88b48a424440, 0x20000003e, 0xffff88b48a424380, 0x0, 0x0, 0x0, 0x300, 0x0, 0x3e, 0x800, 0x400, 0x400, 0x102d4493e, 0x800000000, 0x300, 0x0, 0xffff88b48a4244c0, 0xffff88b48a4242c0, 0xffff88b48a424300, 0xffffffff82cc79a0, 0xffff88b4919e5500, 0x500000001, 0x0, 0x0, 0xffff88b48a424500, 0xffff88b48a424300, 0xffffffff82262d38, 0xffff88ea89c7b210, 0x1, 0x900000000, 0x0, 0x0, 0xffff88b48a424540, 0x20000003e, 0xffff88b48a424480, 0x0, 0x0, 0x0}
}
crash> eval -b 0xc
bits set: 3 2
crash>
因为我们的环境vcpu0~vcpu61在同一个NUMA NODE0上,所以vcpu61的schedule group是NUMA NODE0对应的MC domain
的最后一个schedule group,其对应的sched_group.next指向的是同一个MC domain包含vcpu0和vcpu1的sched_group
crash> runq |grep -wE "CPU 61"
CPU 61 RUNQUEUE: ffff88b493169980
crash> rq.sd ffff88b493169980
sd = 0xffff88b48a4da800
crash> struct sched_domain.name,parent 0xffff88b48a4da800
name = 0xffffffff8253e5db <kallsyms_token_index+59507> "SMT"
parent = 0xffff88b48a4e2400
crash> struct sched_domain.name,groups 0xffff88b48a4e2400
name = 0xffffffff82534eb3 <kallsyms_token_index+20811> "MC"
groups = 0xffff88b48a425d40
crash> struct sched_group.cpumask,next,group_weight 0xffff88b48a425d40
cpumask = 0xffff88b48a425d70
next = 0xffff88b48a423fc0 //这里指向包含vcpu0和vcpu1这一对超线程的schedule group
group_weight = 2 //该调度组下有两个vcpu
crash> cpumask 0xffff88b48a425d70 -x
struct cpumask {
bits = {0x3000000000000000, 0x0, 0x3e, 0x800, 0x400, 0x400, 0x102d66063, 0x3c00000000, 0x3000000000000000, 0x0, 0xffff88b48a425e00, 0x400035, 0x1, 0x0, 0xffffffff812a5350, 0xffffffff812a58b0, 0xffff88b4891dcc00, 0x0, 0xffff88b48a425f40, 0x400034, 0x1, 0x0, 0xffffffff812a5350, 0xffffffff812a58b0, 0xffff88b4891dcb80, 0x0, 0xffff88b48a427f80, 0x40002f, 0x1, 0x0, 0xffffffff812a5350, 0xffffffff812a58b0, 0xffff88b4891dc900, 0x0, 0xffff88b48a425e40, 0x400030, 0x1, 0x0, 0xffffffff812a5350, 0xffffffff812a58b0, 0xffff88b4891dc980, 0x0, 0xffff88b48a425e80, 0x400031, 0x1, 0x0, 0xffffffff812a5350, 0xffffffff812a58b0, 0xffff88b4891dca00, 0x0, 0xffff88b48a425ec0, 0x400032, 0x1, 0x0, 0xffffffff812a5350, 0xffffffff812a58b0, 0xffff88b4891dca80, 0x0, 0xffff88b48a425f00, 0x400033, 0x1, 0x0, 0xffffffff812a5350, 0xffffffff812a58b0, 0xffff88b4891dcb00, 0x0, 0xffffffff81ad6030, 0xffffffff81b25a50, 0x0, 0x1, 0x0, 0x0, 0x3fffffffffffffff, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffffffff81ab89e0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffffffff81a90080, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffffffff81a8f950, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffffffff81a90210, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffffffff81a64ec0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffffffff81a66470, 0x0, 0x0, 0x0, 0x0}
}
crash> eval -b 0x3000000000000000
bits set: 61 60
crash> NUMA 域则是由系统里的所有CPU构成,如上图1双NUMA NODE的Soc的NUMA domain包含两个schedule group,每个schedule group包含单个NUMA NODE的所有cpu,如下图所示vcpu0-vcpu61对应实验环境NUMA NODE0上所有的vcpu, 这里vcpu62-vcpu123对应实验环境NUMA NODE1的所有62个vcpu.
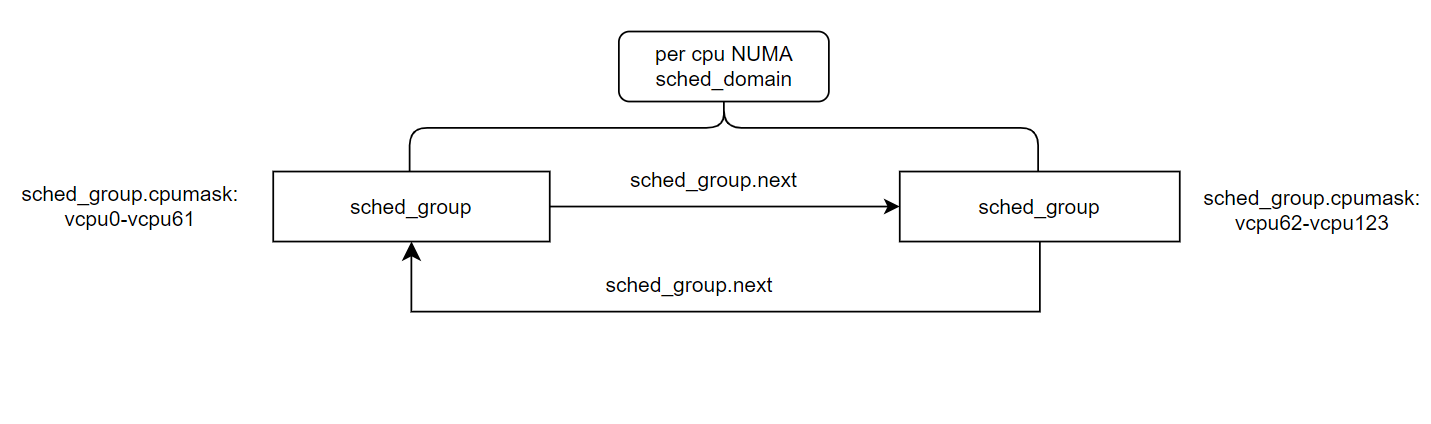
crash> runq |grep -wE "CPU 0"
CPU 0 RUNQUEUE: ffff88b492229980
crash> rq.sd ffff88b492229980
sd = 0xffff88b48aa23e00
crash> struct sched_domain.name,parent 0xffff88b48aa23e00
name = 0xffffffff8253e5db <kallsyms_token_index+59507> "SMT"
parent = 0xffff88b48a4dbe00
crash> struct sched_domain.name,parent 0xffff88b48a4dbe00
name = 0xffffffff82534eb3 <kallsyms_token_index+20811> "MC"
parent = 0xffff88b48a4f3e00
crash> struct sched_domain.name,groups 0xffff88b48a4f3e00
name = 0xffffffff8254d687 <kallsyms_token_index+121119> "NUMA"
groups = 0xffff88b48a42cfc0
crash> struct sched_group.cpumask,next,group_weight 0xffff88b48a42cfc0
cpumask = 0xffff88b48a42cff0
next = 0xffff88b48a42cf80 //这里指向的sched_cgroup的cpumask包含的是NUMA NODE的所有vcpu
//这里指向的sched_cgroup的next指回这里的sched_group地址0xffff88b48a42cfc0
group_weight = 62 // 该调度组下有62个vcpu
sched_group的cpumask包含的是NUMA NODE0的vcpu0~vcpu61:
crash> cpumask 0xffff88b48a42cff0 -x
struct cpumask {
bits = {0x3fffffffffffffff, 0x0, 0xffff88b48a42cb40, 0x3e00000001, 0xffff88ea8a976f80, 0x0, 0x0, 0x0, 0xc000000000000000, 0xfffffffffffffff, 0xffff88b48a42d080, 0x3e00000001, 0xffff88b48a42af80, 0x0, 0x0, 0x0, 0x3fffffffffffffff, 0x0, 0xffff88b48a42d040, 0x3e00000001, 0xffff88ea8a976f80, 0x0, 0x0, 0x0, 0xc000000000000000, 0xfffffffffffffff, 0xffff88b48a42d100, 0x3e00000001, 0xffff88b48a42af80, 0x0, 0x0, 0x0, 0x3fffffffffffffff, 0x0, 0xffff88b48a42d0c0, 0x3e00000001, 0xffff88ea8a976f80, 0x0, 0x0, 0x0, 0xc000000000000000, 0xfffffffffffffff, 0xffff88b48a42d180, 0x3e00000001, 0xffff88b48a42af80, 0x0, 0x0, 0x0, 0x3fffffffffffffff, 0x0, 0xffff88b48a42d140, 0x3e00000001, 0xffff88ea8a976f80, 0x0, 0x0, 0x0, 0xc000000000000000, 0xfffffffffffffff, 0xffff88b48a42d200, 0x3e00000001, 0xffff88b48a42af80, 0x0, 0x0, 0x0, 0x3fffffffffffffff, 0x0, 0xffff88b48a42d1c0, 0x3e00000001, 0xffff88ea8a976f80, 0x0, 0x0, 0x0, 0xc000000000000000, 0xfffffffffffffff, 0xffff88b48a42d280, 0x3e00000001, 0xffff88b48a42af80, 0x0, 0x0, 0x0, 0x3fffffffffffffff, 0x0, 0xffff88b48a42d240, 0x3e00000001, 0xffff88ea8a976f80, 0x0, 0x0, 0x0, 0xc000000000000000, 0xfffffffffffffff, 0xffff88b48a42d300, 0x3e00000001, 0xffff88b48a42af80, 0x0, 0x0, 0x0, 0x3fffffffffffffff, 0x0, 0xffff88b48a42d2c0, 0x3e00000001, 0xffff88ea8a976f80, 0x0, 0x0, 0x0, 0xc000000000000000, 0xfffffffffffffff, 0xffff88b48a42d380, 0x3e00000001, 0xffff88b48a42af80, 0x0, 0x0, 0x0, 0x3fffffffffffffff, 0x0, 0xffff88b48a42d340, 0x3e00000001, 0xffff88ea8a976f80, 0x0, 0x0, 0x0, 0xc000000000000000, 0xfffffffffffffff, 0xffff88b48a42d400, 0x3e00000001, 0xffff88b48a42af80, 0x0, 0x0, 0x0}
}
crash> eval -b 0x3fffffffffffffff
bits set: 61 60 59 58 57 56 55 54 53 52 51 50 49 48 47 46 45 44 43 42 41 40
39 38 37 36 35 34 33 32 31 30 29 28 27 26 25 24 23 22 21 20 19 18
17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
crash>
crash> struct sched_group.cpumask,next 0xffff88b48a42cf80
cpumask = 0xffff88b48a42cfb0
next = 0xffff88b48a42cfc0
crash>
cpumask 包含的是NUMA NODE1的vcpu62~vcpu123
crash> cpumask 0xffff88b48a42cfb0 -x
struct cpumask {
bits = {0xc000000000000000, 0xfffffffffffffff, 0xffff88b48a42cf80, 0x3e00000001, 0xffff88b48a42af80, 0x0, 0x0, 0x0, 0x3fffffffffffffff, 0x0, 0xffff88b48a42cb40, 0x3e00000001, 0xffff88ea8a976f80, 0x0, 0x0, 0x0, 0xc000000000000000, 0xfffffffffffffff, 0xffff88b48a42d080, 0x3e00000001, 0xffff88b48a42af80, 0x0, 0x0, 0x0, 0x3fffffffffffffff, 0x0, 0xffff88b48a42d040, 0x3e00000001, 0xffff88ea8a976f80, 0x0, 0x0, 0x0, 0xc000000000000000, 0xfffffffffffffff, 0xffff88b48a42d100, 0x3e00000001, 0xffff88b48a42af80, 0x0, 0x0, 0x0, 0x3fffffffffffffff, 0x0, 0xffff88b48a42d0c0, 0x3e00000001, 0xffff88ea8a976f80, 0x0, 0x0, 0x0, 0xc000000000000000, 0xfffffffffffffff, 0xffff88b48a42d180, 0x3e00000001, 0xffff88b48a42af80, 0x0, 0x0, 0x0, 0x3fffffffffffffff, 0x0, 0xffff88b48a42d140, 0x3e00000001, 0xffff88ea8a976f80, 0x0, 0x0, 0x0, 0xc000000000000000, 0xfffffffffffffff, 0xffff88b48a42d200, 0x3e00000001, 0xffff88b48a42af80, 0x0, 0x0, 0x0, 0x3fffffffffffffff, 0x0, 0xffff88b48a42d1c0, 0x3e00000001, 0xffff88ea8a976f80, 0x0, 0x0, 0x0, 0xc000000000000000, 0xfffffffffffffff, 0xffff88b48a42d280, 0x3e00000001, 0xffff88b48a42af80, 0x0, 0x0, 0x0, 0x3fffffffffffffff, 0x0, 0xffff88b48a42d240, 0x3e00000001, 0xffff88ea8a976f80, 0x0, 0x0, 0x0, 0xc000000000000000, 0xfffffffffffffff, 0xffff88b48a42d300, 0x3e00000001, 0xffff88b48a42af80, 0x0, 0x0, 0x0, 0x3fffffffffffffff, 0x0, 0xffff88b48a42d2c0, 0x3e00000001, 0xffff88ea8a976f80, 0x0, 0x0, 0x0, 0xc000000000000000, 0xfffffffffffffff, 0xffff88b48a42d380, 0x3e00000001, 0xffff88b48a42af80, 0x0, 0x0, 0x0, 0x3fffffffffffffff, 0x0, 0xffff88b48a42d340, 0x3e00000001, 0xffff88ea8a976f80, 0x0, 0x0, 0x0}
}
crash>
//其他核比如vcpu123 对应的per cpu NUMA sched_domain下schedule group情况相同
crash> runq |grep -wE "CPU 123"
CPU 123 RUNQUEUE: ffff88ea93169980
crash> runq |grep -wE "CPU 123"
CPU 123 RUNQUEUE: ffff88ea93169980
crash> rq.sd ffff88ea93169980
sd = 0xffff88ea8a9ab400
crash> struct sched_domain.name,parent 0xffff88ea8a9ab400
name = 0xffffffff8253e5db <kallsyms_token_index+59507> "SMT"
parent = 0xffff88ea8a9b3000
crash> struct sched_domain.name,parent 0xffff88ea8a9b3000
name = 0xffffffff82534eb3 <kallsyms_token_index+20811> "MC"
parent = 0xffff88ea8a9ca400
crash> struct sched_domain.name,groups 0xffff88ea8a9ca400
name = 0xffffffff8254d687 <kallsyms_token_index+121119> "NUMA"
groups = 0xffff88ea8a97a240
crash> struct sched_group.cpumask,next 0xffff88ea8a97a240
cpumask = 0xffff88ea8a97a270
next = 0xffff88ea8a97a280
crash> cpumask 0xffff88ea8a97a270 -x
struct cpumask {
bits = {0xc000000000000000, 0xfffffffffffffff, 0xffff88ea8a97a240, 0x3e00000001, 0xffff88b48a42af80, 0x0, 0x0, 0x0, 0x3fffffffffffffff, 0x0, 0xffffffff81a47920, 0x0, 0x0, 0x1, 0x0, 0x0, 0x0, 0x0, 0xffffffff81a47c20, 0xffffffff81a47780, 0x0, 0x1, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffffc9000ddfd000, 0x201000, 0x2, 0xffff88ea8a9d1000, 0x200, 0x0, 0xffffffff82ed91b0, 0x0, 0xffffc9000c481000, 0x2000, 0x2, 0xffff88ea8a97b168, 0x1, 0x0, 0xffffffff8119b62c, 0x0, 0xffffffffa0000000, 0x2000, 0x102, 0xffff88ea8a97b180, 0x1, 0x0, 0xffffffff8119c56e, 0xffff88ea8a97a400, 0xffff88ea8a97a400, 0x0, 0x0, 0xffff88ea8a97a420, 0xffff88ea8a97a420, 0x0, 0x0, 0xffffffff81a71140, 0xffffffff81a70b30, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffffffff81a6dc90, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffffffff81a724e0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffffffff81a6cb70, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffffffff81a6a5b0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffffffff81a6a5b0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffffffff81a6a5b0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffffffff81a6dfd0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0xffffffff81a6e2e0, 0x0, 0x0, 0x0, 0x0, 0x0}
}
crash> eval -b 0xc000000000000000
bits set: 63 62
crash> eval -b 0xfffffffffffffff
bits set: 59 58 57 56 55 54 53 52 51 50 49 48 47 46 45 44 43 42 41 40 39 38
37 36 35 34 33 32 31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
crash>
crash> struct sched_group.cpumask,next 0xffff88ea8a97a280
cpumask = 0xffff88ea8a97a2b0
next = 0xffff88ea8a97a240
crash> eval -b 0xffff88ea8a97a2b0
bits set: 63 62 61 60 59 58 57 56 55 54 53 52 51 50 49 48 47 43 39 38 37 35
33 31 27 25 23 20 18 17 16 15 13 9 7 5 4
crash> 介绍了调度域,调度组相关的知识,接下来看看cfs调度器是如何为进程选择cpu(runqueue),如下图6所示不同的调用路径最终调用的选核函数是select_task_rq_fair.
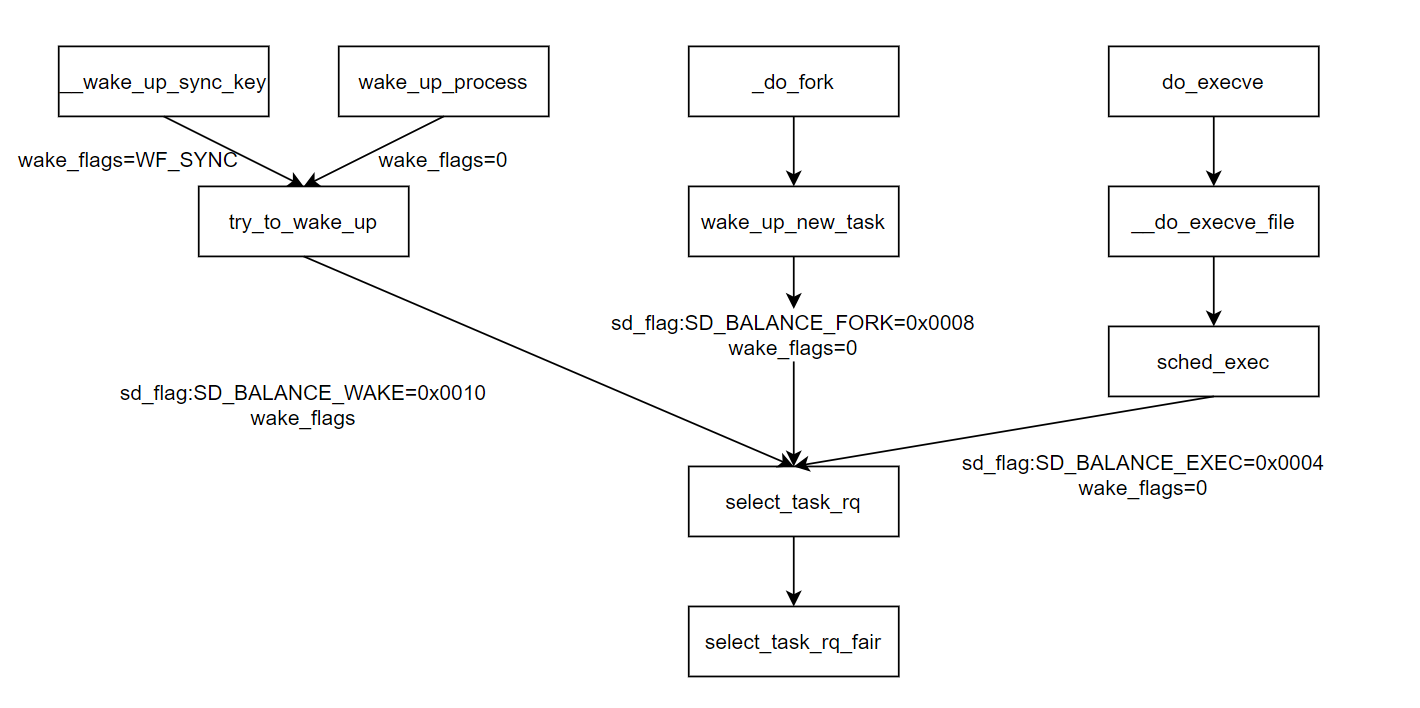
select_task_rq_fair涉及到几个比较重要的函数record_wakee,wake_affine,find_idlest_cpu和select_idle_sibling.
为了方便描述,这里将执行唤醒的进程称为waker进程,被唤醒的进程称为wakee进程。
如上图6所示只有wakeup时函数传入的sd_flag标志位才会是SD_BALANCE_WAKE,这时才会做wake affine选核,
会先调用record_wakee统计waker进程的wakee_flips.wakee_flips表示当前进程作为waker唤醒其他进程的次数,
当前进程前后两次调用record_wakee时如果超过了1秒,那么wakee_flips衰减为原来的1/2. 前后两次唤醒的不是
同一个进程时wakee_flips加1所以wakee_flips越大说明被该进程唤醒的wakee不止一个,并且越大说明唤醒不同
进程的频率越高。
static void record_wakee(struct task_struct *p)
{
/*
* Only decay a single time; tasks that have less then 1 wakeup per
* jiffy will not have built up many flips.
*/
if (time_after(jiffies, current->wakee_flip_decay_ts + HZ)) {
current->wakee_flips >>= 1;
current->wakee_flip_decay_ts = jiffies;
}
if (current->last_wakee != p) {
current->last_wakee = p;
current->wakee_flips++;
}
}
tencentos未使能sched_energy_enabled,这里先忽略跳过find_energy_efficient_cpu。
接着通过 wake_cap 和 wake_wide 以及waker所在vcpu是不是在wakee的cpumask内来确定
这次对进程的唤醒是不是 want_affine 的.
want_affine = !wake_wide(p) && !wake_cap(p, cpu, prev_cpu) &&
cpumask_test_cpu(cpu, p->cpus_ptr);
factor = this_cpu_read(sd_llc_size)表示了在当前NUMA NODE上能够共享llc cache的CPU数目,
在这里的实验环境一个NUMA NODE是62个vcpu。
crash> p sd_llc_size | head -4
PER-CPU DATA TYPE:
int sd_llc_size;
PER-CPU ADDRESSES:
[0]: ffff88b492216444
crash> rd ffff88b492216444
ffff88b492216444: 8a4dbe000000003e >.....M.
crash> eval -b 0x3e
decimal: 62
共享llc chache的CPU越多factor就越大,那么wake_affine返回0的概率更大, 因为有更多的共享LL3的CPU那么可以
选择want_affine的概率就更大.slave<=factor即waker和wakee两者中较小值wakee_flips(为什么不是较大值?)小于
等于factor或者两个waker wakee_flips的比值小于factor(master <= slave * factor即 master/slave < factor)
说明进程唤醒切换不那么频繁,认为共享LLC的cpu数可以装得下这些被唤醒的进程,则选择wake_affine更优。这里理解
进程高wakee_flips说明有比较多的进程依赖于这个进程去唤醒,如果还继续wake_affine而不允许选择另外一个
LLC的cpu上运行会导致更高的调度延迟。 如果 slave 任务少于共享一个 LLC 的CPU数(按:一般来说是一个 Socket 下的所有核共享一个LLC)
static int wake_wide(struct task_struct *p)
{
unsigned int master = current->wakee_flips;
unsigned int slave = p->wakee_flips;
int factor = this_cpu_read(sd_llc_size);
if (master < slave)
swap(master, slave);
if (slave <= factor || master <= slave * factor)
return 0;
return 1;
}
默认未使能sched_asym_cpucapacity,wake_cap总返回0
static int wake_cap(struct task_struct *p, int cpu, int prev_cpu)
{
long min_cap, max_cap;
if (!static_branch_unlikely(&sched_asym_cpucapacity))
return 0;
.....
}
获取到want_affine值后,接着从waker 进程当前所在CPU的最下层调度域开始向上遍历,也即从SMT->MC>NUMA方向遍历,
默认sched_domain.flags配置下want_affine为1时wake_affine从waker进程当前所在的cpu this_cpu和wakee进程上
一次running时所在cpu prev_cpu中初选一个合适的cpu,接着如果是走到快速路径select_idle_sibling继续从
wake_affine返回的new_cpu所在的LLC内的所有cpu中选择最空闲的cpu,如果是走到慢速路径find_idlest_cpu则
会在整机所有cpu中找最空闲的schedule group进而找到最空闲的cpu。
1. 如果最下一层调度域(这里实验环境是SMT domain)没有配置SD_LOAD_BALANCE则直接跳出for_each_domain循环,
如果同时传入的sd_flags是SD_BALANCE_WAKE则会走到快速路径select_idle_sibling。
2. 如果是want_affine且调度域sched_domain.flags开启了SD_LOAD_BALANCE和SD_WAKE_AFFINE(两者默认打开)
且待被唤醒的wakee进程先前所在的cpu在当前遍历的调度域cpumask内,并且当前waker进程运行的cpu跟wakee进
程先前运行的cpu不是一个cpu,则通过wake_affine从wakee进程上一次运行所在的prev_cpu和waker CPU中预选
一个合适的new CPU并设置sd = NULL。接着走到快速路径select_idle_sibling中再次优选一个cpu,
同时设置current->recent_used_cpu为当前waker进程运行的CPU
3.如果是want_affine但所有层次调度域sched_domain.flags都没有配置SD_WAKE_AFFINE,并且
sched_domain.flags配置了传入的sd_flag,则sd = tmp,那么会走到慢速路径find_idlest_cpu
4.如果不是want_affine, 且sched_domain.flags配置了SD_LOAD_BALANCE和sd_flag,
则最终因for_each_domain遍历到最上面一层调度域(实验环境是NUMA domain)后退出循环,
此时sd指向了sched_domain.flags配置了SD_LOAD_BALANCE和sd_flag的最上面一层调度域
的sched_domain,接着会走到慢速路径通过find_idlest_cpu选择一个合适的cpu
static int
select_task_rq_fair(struct task_struct *p, int prev_cpu, int sd_flag, int wake_flags)
{
struct sched_domain *tmp, *sd = NULL;
int cpu = smp_processor_id();
int new_cpu = prev_cpu;
int want_affine = 0;
int sync = (wake_flags & WF_SYNC) && !(current->flags & PF_EXITING);
if (sd_flag & SD_BALANCE_WAKE) {
record_wakee(p);
if (sched_energy_enabled()) {
new_cpu = find_energy_efficient_cpu(p, prev_cpu);
if (new_cpu >= 0)
return new_cpu;
new_cpu = prev_cpu;
}
want_affine = !wake_wide(p) && !wake_cap(p, cpu, prev_cpu) &&
cpumask_test_cpu(cpu, p->cpus_ptr);
}
rcu_read_lock();
for_each_domain(cpu, tmp) {
//调度域flags默认都开启了SD_LOAD_BALANCE,通过/proc/sys/kernel/sched_domain/cpuX/domainX/flags
//可查看per cpu调度域的struct sched_domain.flags值
if (!(tmp->flags & SD_LOAD_BALANCE))
break;
/*
* If both 'cpu' and 'prev_cpu' are part of this domain,
* cpu is a valid SD_WAKE_AFFINE target.
*/
if (want_affine && (tmp->flags & SD_WAKE_AFFINE) &&
cpumask_test_cpu(prev_cpu, sched_domain_span(tmp))) {
if (cpu != prev_cpu)
new_cpu = wake_affine(tmp, p, cpu, prev_cpu, sync);
sd = NULL; /* Prefer wake_affine over balance flags */
break;
}
if (tmp->flags & sd_flag)
sd = tmp;
else if (!want_affine)
break;
}
if (unlikely(sd)) {
/* Slow path */
new_cpu = find_idlest_cpu(sd, p, cpu, prev_cpu, sd_flag);
} else if (sd_flag & SD_BALANCE_WAKE) { /* XXX always ? */
/* Fast path */
new_cpu = select_idle_sibling(p, prev_cpu, new_cpu);
if (want_affine)
current->recent_used_cpu = cpu;
}
rcu_read_unlock();
return new_cpu;
}
wake_affine是从waker 进程当前所在的cpu this_cpu和待被唤醒的wakee进程上一次所在的cpu选一个
合适的cpu,如果this_cpu和prev_cpu是共享llc且都是空闲的那么会优选prev_cpu,若如果两者都不是空闲
的最终通过wake_affine_weight选择两者较低负载的返回,如果sd_flag设置了SD_BALANCE_WAKE,那么这
里wake_affine返回的new_cpu并不是最终目的cpu,仅会作为后面select_idle_sibling的一个参数再进一步
从共享LLC的cpu下筛选出共享合适的cpu。若调用select_task_rq_fair时传入的wake_flags带WF_SYNC标识位
说明waker进程在wakee进程被唤醒后将进入阻塞状态,wake_affine会倾向于选择将wakee进程放置到waker当前
所在的CPU this_cpu。
static int wake_affine(struct sched_domain *sd, struct task_struct *p,
int this_cpu, int prev_cpu, int sync)
{
int target = nr_cpumask_bits;
//cat /sys/kernel/debug/sched_features | grep -E 'WA_IDLE|WA_WEIGHT'
//可查看WA_IDLE和WA_WEIGHT都是开启的
if (sched_feat(WA_IDLE))
/*wake_affine_idle中判断this_cpu和prev_cpu是共享llc且都是空闲的那么会优选prev_cpu,
若prev_cpu不是idle,但this_cpu为idel(此时通常this_cpu是swapper在运行,wakup的调用来
自中断上下文),那么选择this_cpu。如果非sync且this_cpu核和prev_cpu都不空闲这里返回nr_cpumask_bits
,继续走wake_affine_weight在this_cpu和prev_cpu选出负载较低的cpu*/
target = wake_affine_idle(this_cpu, prev_cpu, sync);
if (sched_feat(WA_WEIGHT) && target == nr_cpumask_bits)
target = wake_affine_weight(sd, p, this_cpu, prev_cpu, sync);
schedstat_inc(p->se.statistics.nr_wakeups_affine_attempts);
if (target == nr_cpumask_bits)
return prev_cpu;
schedstat_inc(sd->ttwu_move_affine);
schedstat_inc(p->se.statistics.nr_wakeups_affine);
return target;
}
find_idlest_cpu的遍历循序是从上层往下层遍历,即从select_task_rq_fair中for_each_domain里
sd = tmp获取的调度域往下层调度域遍历。如果每一层的调度域sched_domain.flags都配置sd_flag的值
那么sd = tmp后sd指向的就是最上一层的调度域,在实验环境这里就是从NUMA->MC->SMT方向遍历
static inline int find_idlest_cpu(struct sched_domain *sd, struct task_struct *p,
int cpu, int prev_cpu, int sd_flag)
{
int new_cpu = cpu;
if (!cpumask_intersects(sched_domain_span(sd), p->cpus_ptr))
return prev_cpu;
/*
* We need task's util for capacity_spare_without, sync it up to
* prev_cpu's last_update_time.
*/
if (!(sd_flag & SD_BALANCE_FORK))
sync_entity_load_avg(&p->se);
while (sd) {
struct sched_group *group;
struct sched_domain *tmp;
int weight;
if (!(sd->flags & sd_flag)) {
sd = sd->child;
continue;
}
//find_idlest_group判断入参cpu所在的schedule group是最空闲的则返回NULL
//接着继续遍历下一级调度域sd->child的调度组找到最空闲的schedule group
//如果当前sd指向调度域下当前waker进程cpu所在的schedule group不是最空闲,那么
//find_idlest_group返回当前sd指向的调度域下其他最空闲的schedule group
//接着走到find_idlest_group从该返回的group中找到最空闲的cpu
group = find_idlest_group(sd, p, cpu, sd_flag);
if (!group) {
//继续遍历下一层调度域直到遍历完所有调度域后sd为空时while(sd)不成立退出循环
sd = sd->child;
continue;
}
//遍历group找到最空闲的cpu, 上层的调度域的sg已经包含了下层调度域sg的cpu,
//find_idlest_group_cpu里遍历group内所有cpu找到最空闲的,如果load相同则取先遍历到的,
//这里遍历完上一层调度域的group后找到最空闲的cpu,如果还有子调度域还会继续遍历下层调度
//域的schedule group,这里理解这样实现的原因是上一层调度域的group找到的cpu从单cpu来看
//可能是最空闲的,但是从物理core来说就不一定了,例如NUMA调度域的一个schedule group包含
//单个NUMA NODE的所有vcpu,遍历NUMA调度域其中一个schedule group找到最空闲的vcpu,但是
//这个vcpu 所在MC domain的schedule group却不一定是最空闲的,比如vcpu0是NUMA Domain下其中
//一个schedule group里最空闲的,但是vcpu0跟vcpu1组成的MC domain的调度组就不一定比
//vcpu2和vcpu3组成的MC domain的调度组更空闲了,所以需要继续遍历下一层调度域的调度组
new_cpu = find_idlest_group_cpu(group, p, cpu);
if (new_cpu == cpu) {//相等说明是同一个sched_domain地址,sd直接指向sd->child
//继续遍历下一层调度域
/* Now try balancing at a lower domain level of 'cpu': */
sd = sd->child;
continue;
}
/* Now try balancing at a lower domain level of 'new_cpu': */
cpu = new_cpu;
weight = sd->span_weight;
sd = NULL;
//span_weight是每个调度域的cpu数量,上一层调度域的span_weight值总是不小于下一层调度域,
//这里循环的作用是将sd当前指向的调度域的span_weight数与cpu号所在的最下层调度域到最上层调度域的
//span_weight都对比下,因为是从cpu的最下一层调度域开始对比,所以如果weight小于等于tmp->span_weight
//说明先前遍历的sd已经是指向最下一层调度域了,不需要再继续遍历,则这里break退出后while(sd)不成立退出循环
for_each_domain(cpu, tmp) {
if (weight <= tmp->span_weight)
break;
//如果weight > tmp->span_weight说明前面遍历的sd指向的调度域还不是最下一层调度域
//同时如果sched_domain.flags设置了sd_flag那么将sd指向前面find_idlest_group_cpu选中
//返回cpu对应的下一层调度域地址,while(sd)继续遍历下一层的调度域找到更空闲的cpu
if (tmp->flags & sd_flag)
sd = tmp;
}
}
return new_cpu;
}
通过while (group = group->next, group != sd->groups);遍历入参sd指向的调度域的所有schedule group,
比如假如传入的sd指向的是NUMA domain,那么会遍历NUMA domain的两个调度组,每个sched_group.cpumask
包含了对应调度组的CPU号
static struct sched_group *
find_idlest_group(struct sched_domain *sd, struct task_struct *p,
int this_cpu, int sd_flag)
{
do{
...
/* Skip over this group if it has no CPUs allowed */
if (!cpumask_intersects(sched_group_span(group),
p->cpus_ptr))
continue;
local_group = cpumask_test_cpu(this_cpu,
sched_group_span(group));
...
for_each_cpu(i, sched_group_span(group)) {
...
}
} while (group = group->next, group != sd->groups);
...
}
依次优先从共享LLC的target、prev cpu和recent_used_cpu 三个中找个满足条件的cpu,如果没有
再从target所在的MC调度域中从target cpu开始遍历MC调度域找一个完全空闲的物理core,
没有再找一个空闲的vcpu,还没有找到则再从target cpu所在物理core的一对超线程中找一个空闲使用,
最后都没有找到就直接只用target cpu。 这里只会从一个MC调度域内找cpu,不会跨NUMA选核
static int select_idle_sibling(struct task_struct *p, int prev, int target)
{
struct sched_domain *sd;
int i, recent_used_cpu;
//如果前面wake_affine选中的cpu是空闲并且没有被抢占
//或者cpu上只有SCHED_IDLE调度器的进程在运行直接返回wake_affine选中的cpu
if (available_idle_cpu(target) || sched_idle_cpu(target))
return target;
/*
* If the previous CPU is cache affine and idle, don't be stupid:
*/
//如果前面wake_affine选中的cpu跟wakee进程上一次运行的prev cpu共享LLC
//并且prev cpu当前是空闲的则继续使用prev cpu
if (prev != target && cpus_share_cache(prev, target) &&
(available_idle_cpu(prev) || sched_idle_cpu(prev)))
return prev;
/* Check a recently used CPU as a potential idle candidate: */
//recent_used_cpu记录的cpu如果跟前面wake_affine选中的cpu共享LLC并且是空闲
//的且wakee进程绑定的cpumask包含recent_used_cpu则选择recent_used_cpu
recent_used_cpu = p->recent_used_cpu;
if (recent_used_cpu != prev &&
recent_used_cpu != target &&
cpus_share_cache(recent_used_cpu, target) &&
(available_idle_cpu(recent_used_cpu) || sched_idle_cpu(recent_used_cpu)) &&
cpumask_test_cpu(p->recent_used_cpu, p->cpus_ptr)) {
/*
* Replace recent_used_cpu with prev as it is a potential
* candidate for the next wake:
*/
p->recent_used_cpu = prev;
return recent_used_cpu;
}
/*
crash> p sd_llc | tail -1
[123]: ffff88ea93156448
crash> rd ffff88ea93156448
ffff88ea93156448: ffff88ea8a9b3000 .0......
crash> sched_domain.name ffff88ea8a9b3000
name = 0xffffffff82534eb3 <kallsyms_token_index+20811> "MC"
crash>
*/
//sd_llc指向MC调度域
sd = rcu_dereference(per_cpu(sd_llc, target));
if (!sd)
return target;
/*select_idle_core从target开始在target所在MC调度域内遍历找一个空闲的物理core,
物理core下的超线程都是空闲的才会选中该物理core, per cpu指针cpu_sibling_map包含
对应cpu关联的两个cpu号,例如使用live crash查看cpu0的cpu_sibling_map包含cpu0跟cpu1,*/
crash> p cpu_sibling_map | head -4
PER-CPU DATA TYPE:
cpumask_var_t cpu_sibling_map;
PER-CPU ADDRESSES:
[0]: ffff88b492210258
crash> rd ffff88b492210258
ffff88b492210258: ffff88b491d695b0 ........
crash> cpumask ffff88b491d695b0 -x
struct cpumask {
bits = {0x3, 0x0, 0x3fffffffffffffff, 0x0, ....,...}*/
i = select_idle_core(p, sd, target);
if ((unsigned)i < nr_cpumask_bits)
return i;
/*从target开始在target所在MC调度域内遍历找一个空闲的cpu,不要求cpu所在的物理core
两个cpu都是空闲的*/
i = select_idle_cpu(p, sd, target);
if ((unsigned)i < nr_cpumask_bits)
return i;
/*从target的smt调度域内找一个空闲的cpu,也就是从跟target所在物理core的一对超线程中
找到空闲的cpu*/
i = select_idle_smt(p, sd, target);
if ((unsigned)i < nr_cpumask_bits)
return i;
return target;
}经过上面的分析就不难理解为什么会出现cpu使用率偶数核比奇数核高的现象了(当然这并不是说每种场景都是如此,只是说明在内核的选核逻辑上这种情况是存在的),如上图6所示当进程被创建出来时走的_do_fork->wake_up_new_task->select_task_rq调用路径,入参sd_flag为SD_BALANCE_FORK,wake_flags为0.进程被唤醒走try_to_wake_up->select_task_rq调用路径,入参sd_flag为SD_BALANCE_WAKE.
内核默认schedule domain的flags如下所示默认开启了SD_LOAD_BALANCE和SD_BALANCE_FORK等,没有开启SD_BALANCE_WAKE.
#ifdef CONFIG_SMP
#define SD_LOAD_BALANCE 0x0001 /* Do load balancing on this domain. */
#define SD_BALANCE_NEWIDLE 0x0002 /* Balance when about to become idle */
#define SD_BALANCE_EXEC 0x0004 /* Balance on exec */
#define SD_BALANCE_FORK 0x0008 /* Balance on fork, clone */
#define SD_BALANCE_WAKE 0x0010 /* Balance on wakeup */
#define SD_WAKE_AFFINE 0x0020 /* Wake task to waking CPU */
#define SD_ASYM_CPUCAPACITY 0x0040 /* Domain members have different CPU capacities */
#define SD_SHARE_CPUCAPACITY 0x0080 /* Domain members share CPU capacity */
#define SD_SHARE_POWERDOMAIN 0x0100 /* Domain members share power domain */
#define SD_SHARE_PKG_RESOURCES 0x0200 /* Domain members share CPU pkg resources */
#define SD_SERIALIZE 0x0400 /* Only a single load balancing instance */
#define SD_ASYM_PACKING 0x0800 /* Place busy groups earlier in the domain */
#define SD_PREFER_SIBLING 0x1000 /* Prefer to place tasks in a sibling domain */
#define SD_OVERLAP 0x2000 /* sched_domains of this level overlap */
#define SD_NUMA 0x4000 /* cross-node balancing */
crash> struct sched_domain.name,flags,parent 0xffff88b48aa23e00
name = 0xffffffff8253e5db <kallsyms_token_index+59507> "SMT"
flags = 4783
parent = 0xffff88b48a4dbe00
crash> eval -b 4783
bits set: 12 9 7 5 3 2 1 0
crash>
crash> struct sched_domain.name,flags,parent 0xffff88b48a4dbe00
name = 0xffffffff82534eb3 <kallsyms_token_index+20811> "MC"
flags = 4655
parent = 0xffff88b48a4f3e00
crash> eval -b 4655
bits set: 12 9 5 3 2 1 0
crash>
crash> struct sched_domain.name,flags,parent 0xffff88b48a4f3e00
name = 0xffffffff8254d687 <kallsyms_token_index+121119> "NUMA"
flags = 25647
parent = 0x0
crash>
crash> eval -b 25647
bits set: 14 13 10 5 3 2 1 0
crash>
[root@VM-1-4-tencentos ~]# cat /proc/sys/kernel/sched_domain/cpu0/domain0/name
SMT
[root@VM-1-4-tencentos ~]# cat /proc/sys/kernel/sched_domain/cpu0/domain0/flags
4783
[root@VM-1-4-tencentos ~]# cat /proc/sys/kernel/sched_domain/cpu0/domain1/name
MC
[root@VM-1-4-tencentos ~]# cat /proc/sys/kernel/sched_domain/cpu0/domain1/flags
4655
[root@VM-1-4-tencentos ~]# cat /proc/sys/kernel/sched_domain/cpu0/domain2/name
NUMA
[root@VM-1-4-tencentos ~]# cat /proc/sys/kernel/sched_domain/cpu0/domain2/flags
25647
[root@VM-1-4-tencentos ~]#
当新创建进程首次被调度运行时选核走慢路径find_idlest_cpu从最上层调度域到最下层调度域(实验环境是NUMA domain-> MC domain-> SMT domain)一层层遍历找出每层调度域最空闲调度组,再从调度组找出最空闲的cpu。
当进程休眠后被唤醒走try_to_wake_up->select_task_rq调用路径,入参sd_flag为SD_BALANCE_WAKE,sched_domain.flags默认没有使能SD_BALANCE_WAKE, 因此通常情况下会走wake_affine和select_idle_sibling选核,如果wakee进程休眠前running时所在cpu当前是空闲的,那么wakee 进程被唤醒后会优先选中在原来的cpu上运行或者选即将空闲的waker进程所在的cpu,如果wakee进程原先running时所在cpu和waker进程当前所在的cpu都非空闲,select_idle_sibling选cpu时就会从wake_affine选中的new_cpu开始遍历选出物理core的一对超线程都是空闲的物理core的第一个cpu来运行以实现物理core间负载均衡,因此当系统中有物理core是空闲时会先在空闲的物理core上选择一个cpu来运行,因为单个物理core是从低cpu号向高cpu号遍历,所以就会出现cpu使用率偶数核比奇数核高的现象.
如下所示当空载机器用stress-ng起四个进程时会均衡分布在两个NUMA上的各自两个物理core上:
stress-ng --cpu 4 --cpu-load=60

使用stress-ng起少于vcpu数量的一半进程比如stress-ng --cpu 62 --cpu-load=60,可以看到会均衡到所有物理core上

参考:
https://github.com/gatieme/LDD-LinuxDeviceDrivers/blob/master/study/kernel/00-DESCRIPTION/SCHEDULER.md
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。