【爬虫软件】快手评论区采集:自动采集10000多条,含二级评论、展开评论!
原创【爬虫软件】快手评论区采集:自动采集10000多条,含二级评论、展开评论!
原创
马哥python说
发布于 2024-03-21 12:41:53
发布于 2024-03-21 12:41:53
一、背景说明
1.1 效果演示
您好!我是@马哥python说,一名10年程序猿。
我用python开发了一个爬虫采集软件,可自动抓取快手评论数据,并且含二级评论!
为什么有了源码还开发界面软件呢?方便不懂编程代码的小白用户使用,无需安装python、无需懂代码,双击打开即用!
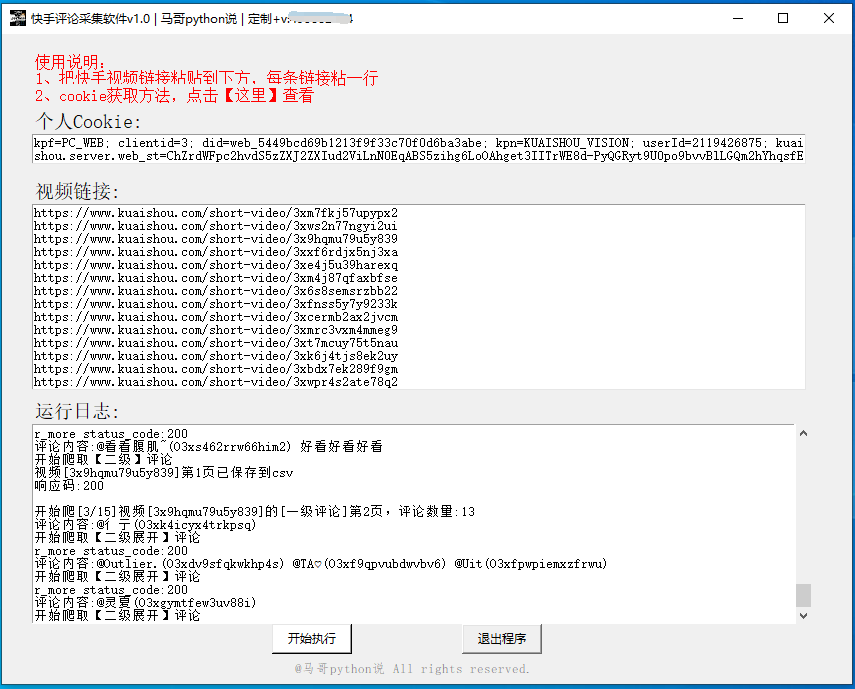
软件运行界面
爬取结果截图:
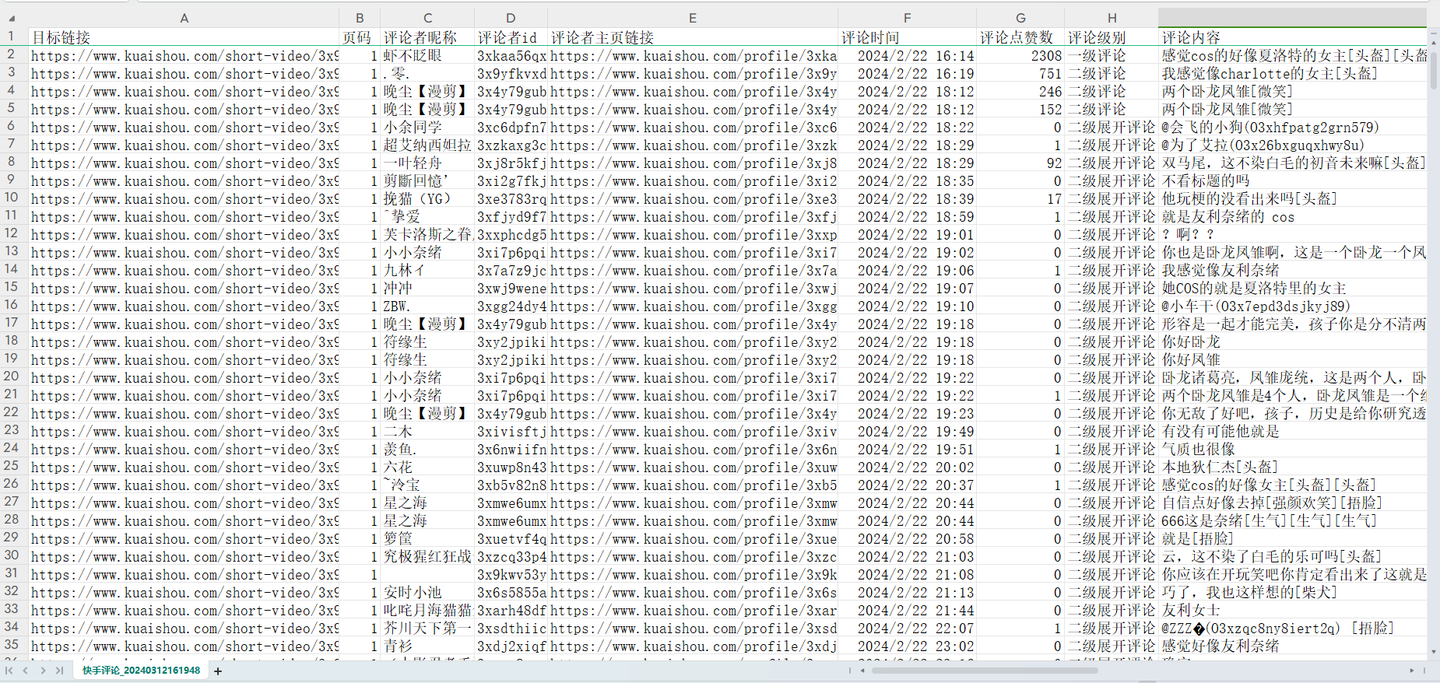
结果1
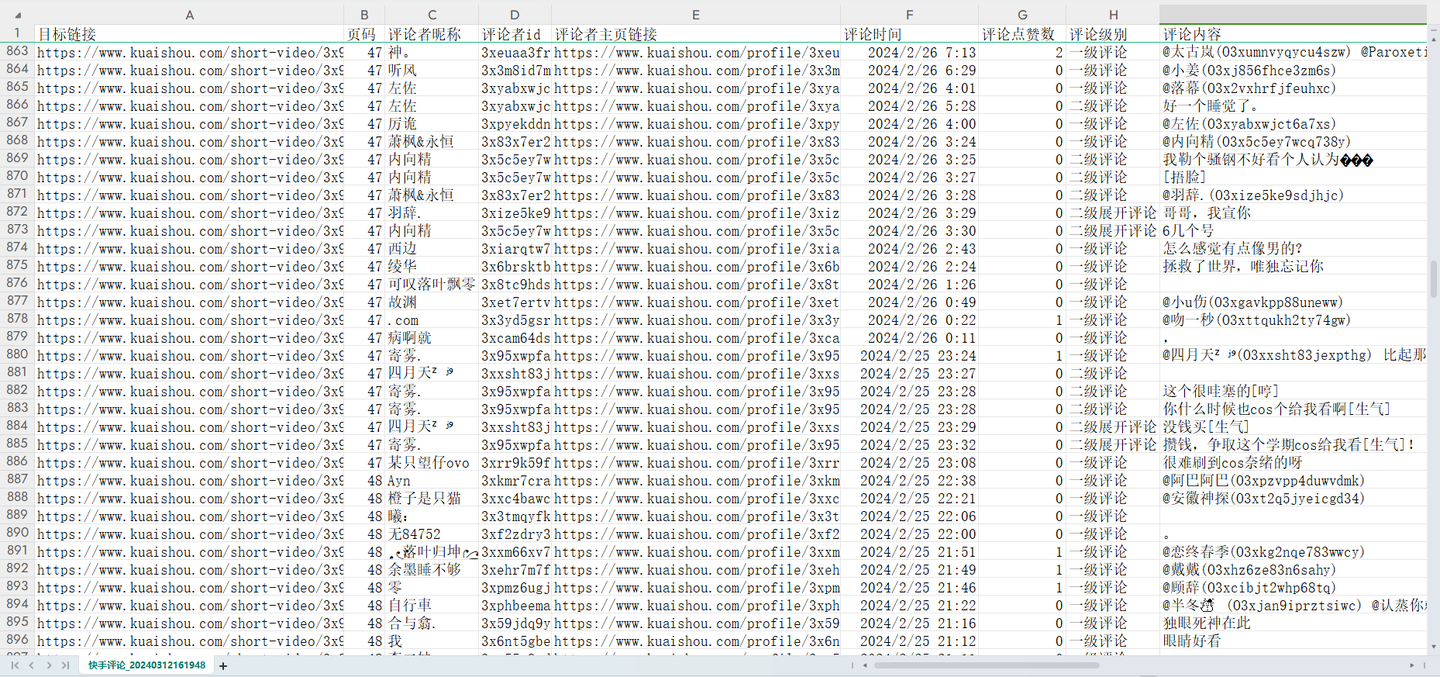
结果2
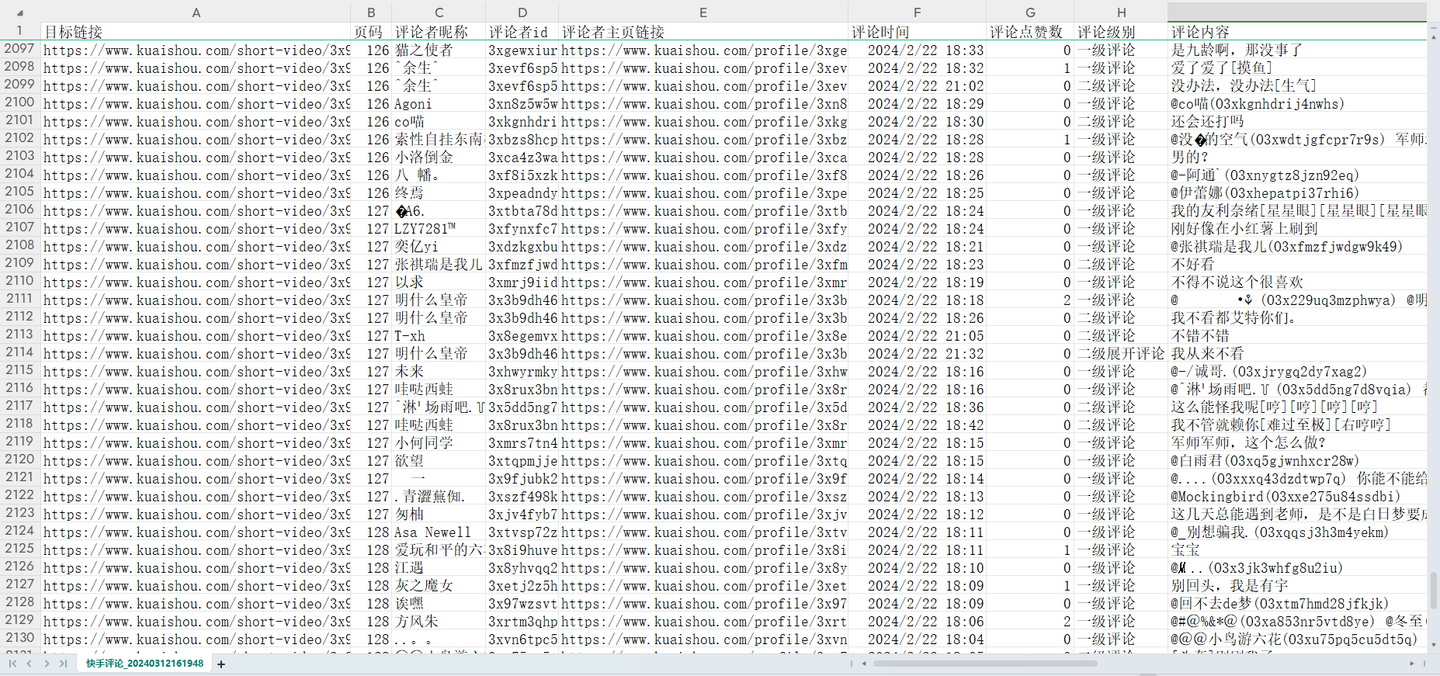
结果3
以上。
1.2 演示视频
软件运行演示视频:
【软件演示】快手评论采集工具,可爬取上万条,含二级评论、展开评论!
1.3 软件说明
几点重要说明!!
1. Windows用户可直接双击打开使用,无需Python运行环境,非常方便!
2. 需要填入cookie和爬取目标视频链接。
3. 支持同时爬多个视频的评论。
4. 可爬取9个关键字段,含:目标链接,页码,评论者昵称,评论者id,评论者主页链接,评论时间,评论点赞数,评论级别,评论内容。
5. 评论中包含二级评论及二级展开评论。
6. 爬取结果自动导出到csv文件。二、代码讲解
2.1 爬虫采集模块
首先,定义接口地址作为请求地址:
# 请求地址
url = 'https://www.kuaishou.com/graphql'定义一个请求头,用于伪造浏览器:
# 请求头
h1 = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Type': 'application/json',
'Cookie': self.cookie_val,
'Host': 'www.kuaishou.com',
'Origin': 'https://www.kuaishou.com',
'Referer': 'https://www.kuaishou.com',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
'sec-ch-ua': '"Google Chrome";v="119", "Chromium";v="119", "Not?A_Brand";v="24"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"macOS"',
}其中,cookie是个关键参数,需要填写到软件界面里。
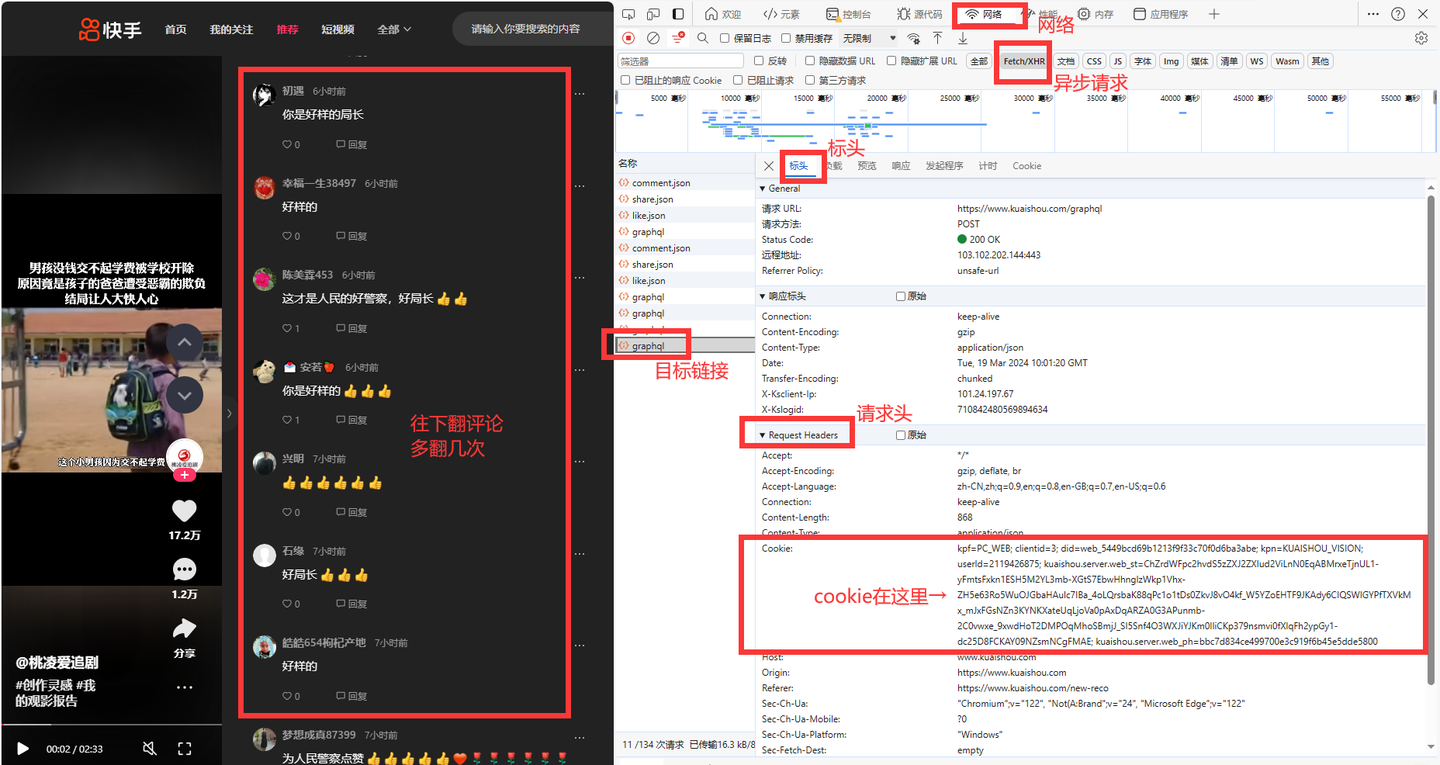
开发者中获取cookie的方法
加上请求参数,告诉程序你的爬取条件是什么:
# 请求参数
params = {"operationName": "commentListQuery",
"variables": {
"photoId": video_id,
"pcursor": pcursor,
},
"query": "query commentListQuery($photoId: String, $pcursor: String) {\n visionCommentList(photoId: $photoId, pcursor: $pcursor) {\n commentCount\n pcursor\n rootComments {\n commentId\n authorId\n authorName\n content\n headurl\n timestamp\n likedCount\n realLikedCount\n liked\n status\n authorLiked\n subCommentCount\n subCommentsPcursor\n subComments {\n commentId\n authorId\n authorName\n content\n headurl\n timestamp\n likedCount\n realLikedCount\n liked\n status\n authorLiked\n replyToUserName\n replyTo\n __typename\n }\n __typename\n }\n __typename\n }\n}\n"}下面就是发送请求和接收数据:
# 发送请求
r = requests.post(url, json=params, headers=h1)
# 接收json数据
json_data = r.json()定义一些空列表,用于存放解析后字段数据:
content_list = [] # 评论内容
create_time_list = [] # 评论时间
like_count_list = [] # 评论点赞数
author_name_list = [] # 评论者昵称
author_id_list = [] # 评论者id
author_link_list = [] # 评论者链接
comment_level_list = [] # 评论级别循环解析字段数据,以"评论内容"为例:
# 循环解析
for data in json_data['data']['visionCommentList']['rootComments']:
# 评论内容
content = data['content']
self.tk_show('评论内容:' + content)
content_list.append(content)其他字段同理,不再赘述。
最后,是把数据保存到csv文件:
# 保存数据到DF
df = pd.DataFrame(
{
'目标链接': 'https://www.kuaishou.com/short-video/' + video_id,
'页码': page,
'评论者昵称': author_name_list,
'评论者id': author_id_list,
'评论者主页链接': author_link_list,
'评论时间': create_time_list,
'评论点赞数': like_count_list,
'评论级别': comment_level_list,
'评论内容': content_list,
}
)
# 保存到csv
if os.path.exists(self.result_file): # 如果文件存在,不再设置表头
header = False
else: # 否则,设置csv文件表头
header = True
df.to_csv(self.result_file, mode='a+', index=False, header=header, encoding='utf_8_sig')
self.tk_show('视频[{}]第{}页已保存到csv'.format(video_id, page))完整代码中,还含有:游标控制翻页、判断循环结束条件、时间戳转换、二级评论及二级展开评论的采集等关键实现逻辑,详见文末。
2.2 软件界面模块
软件界面采用tkinter开发。
主窗口部分:
# 创建主窗口
root = tk.Tk()
root.title('快手评论采集软件v1.0 | 马哥python说')
# 设置窗口大小
root.minsize(width=850, height=650)填写cookie控件:
# 【填入Cookie】
tk.Label(root, justify='left', font=('微软', 14), text='个人Cookie:').place(x=30, y=75)
entry_ck = tk.Text(root, bg='#ffffff', width=110, height=2, )
entry_ck.place(x=30, y=100, anchor='nw') # 摆放位置填写视频链接控件:
# 【视频链接】
tk.Label(root, justify='left', font=('微软', 14), text='视频链接:').place(x=30, y=185)
video_ids = tk.StringVar()
video_ids.set('')
entry_nt = tk.Text(root, bg='#ffffff', width=110, height=12, )
entry_nt.place(x=30, y=210, anchor='nw') # 摆放位置底部软件版权说明:
# 版权信息
copyright = tk.Label(root, text='@马哥python说 All rights reserved.', font=('仿宋', 10), fg='grey')
copyright.place(x=290, y=625)以上。
2.3 日志模块
好的日志功能,方便软件运行出问题后快速定位原因,修复bug。
核心代码:
def get_logger(self):
self.logger = logging.getLogger(__name__)
# 日志格式
formatter = '[%(asctime)s-%(filename)s][%(funcName)s-%(lineno)d]--%(message)s'
# 日志级别
self.logger.setLevel(logging.DEBUG)
# 控制台日志
sh = logging.StreamHandler()
log_formatter = logging.Formatter(formatter, datefmt='%Y-%m-%d %H:%M:%S')
# info日志文件名
info_file_name = time.strftime("%Y-%m-%d") + '.log'
case_dir = r'./logs/'
info_handler = TimedRotatingFileHandler(filename=case_dir + info_file_name,
when='MIDNIGHT',
interval=1,
backupCount=7,
encoding='utf-8')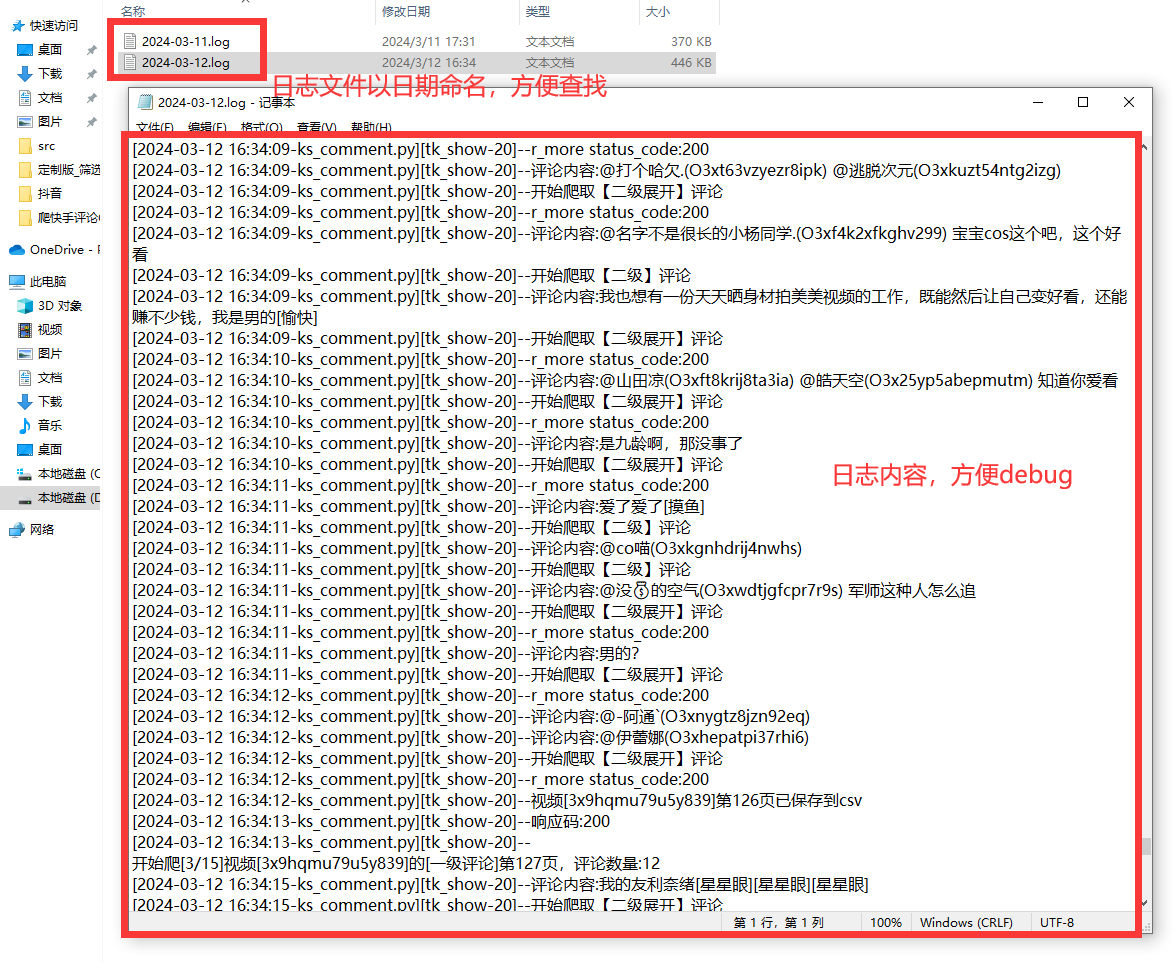
日志文件
___
我是@马哥python说,一名10年程序猿,持续分享python干货中!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
作者已关闭评论
推荐阅读
目录