3D内容创作新篇章:DREAMGAUSSIAN技术解读,已开源
3D内容创作新篇章:DREAMGAUSSIAN技术解读,已开源

DREAMGAUSSIAN: GENERATIVE GAUSSIAN SPLATTING FOR EFFICIENT 3D CONTENT CREATION
1. 论文信息

2. 引言

本文从自动三维数字内容创建的研究背景入手,探讨了这一领域在数字游戏、广告、电影以及元宇宙等多个领域的应用前景。特别强调了图像到3D和文本到3D这两种核心技术如何通过减少专业艺术家的手动劳动需求,以及赋予非专业用户参与3D资产创建的能力,带来显著优势。文章借鉴了2D内容生成领域的最新突破,讨论了3D内容创建领域的快速发展,将现有的研究分为两大类:仅推理的3D原生方法和基于优化的2D提升方法。
3D原生方法能够在几秒钟内生成3D一致的资产,但需要在大规模3D数据集上进行广泛训练,这不仅需要大量的人力,而且在多样性和真实性方面仍然存在限制。另一方面,通过提出Score Distillation Sampling (SDS) 来克服3D数据限制的Dreamfusion启发了最近的2D提升方法的发展,这些方法采用了Neural Radiance Fields (NeRF) 来模拟丰富的3D信息,以应对SDS监督下的不一致性和模糊性问题。尽管这些方法在生成质量上有所提高,但由于NeRF渲染的成本高昂,它们以几小时的优化时间著称,限制了它们在实际应用中的规模部署。
针对上述问题,本文提出了一种新的框架——DreamGaussian,通过在优化流程中重新设计选择,大幅提高了3D内容生成的效率。作者的方法可以在仅用2分钟内从单视图图像生成具有明确网格和纹理映射的逼真3D资产。与以往采用NeRF表示法难以有效剪枝空白空间的方法相比,作者的生成高斯分割显著简化了优化景观,并展示了与生成设置的优化进程高度一致的高斯分割的渐进密化,极大地提高了生成效率。
由于SDS监督的模糊性和空间密化,直接从3D高斯生成的结果往往会显得模糊。为了解决这一问题,作者提出了一个高效的从3D高斯提取网格的算法,并提出了一个生成UV空间细化阶段来增强纹理细节。与先前的纹理细化方法相比,作者的细化阶段在保持高效率的同时实现了更好的保真度。
总结本文的贡献如下:作者提出了一种通过将高斯分割适应生成设置,显著减少基于优化的2D提升方法生成时间的新框架;设计了一种高效的从3D高斯提取网格的算法和UV空间纹理细化阶段,进一步提高了生成质量;通过在图像到3D和文本到3D任务上的广泛实验,证明了作者的方法有效地平衡了优化时间和生成保真度,为3D内容生成的实际部署打开了新的可能性。
3. 方法
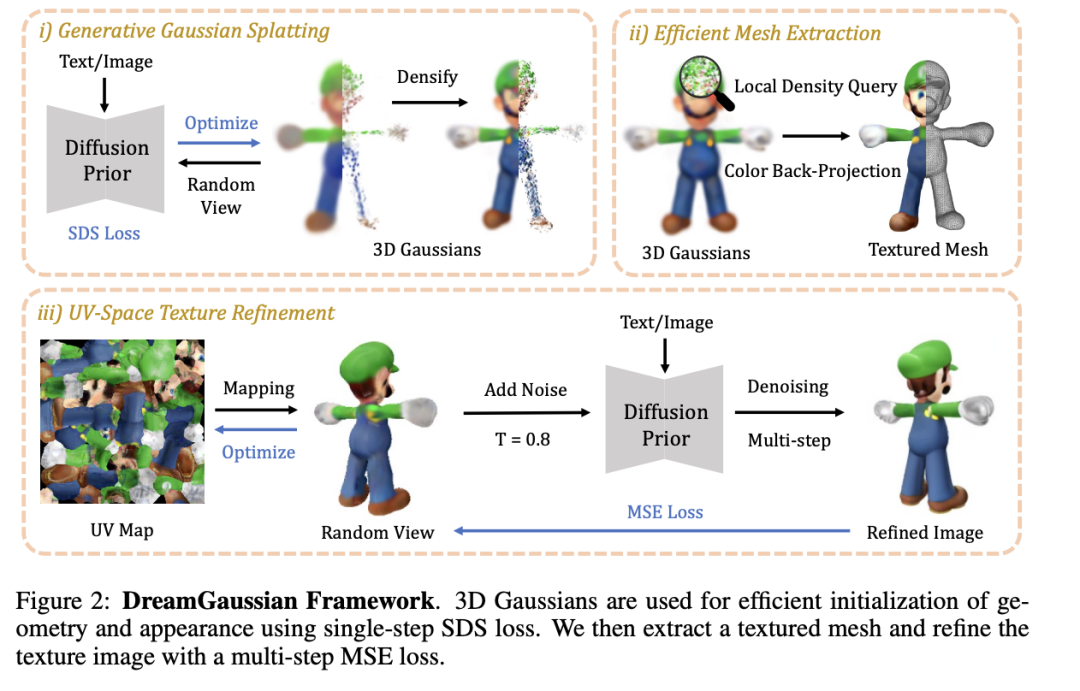
3.1 Generative Gaussian Splatting
作者介绍了将高斯分割技术用于3D信息的表达方式。该技术通过一组3D高斯模型来代表3D信息,已在重建设置中证明了其有效性,与NeRF模型相比,在相似的建模时间下提供了高速的推理速度和高质量的重建效果。然而,其在生成方式中的应用尚未被探索。作者认为3D高斯模型可以高效地用于3D生成任务。
具体来说,每个高斯的位置可以用中心
、缩放因子
和旋转四元数
来描述。作者还为体积渲染存储了一个不透明度值
和一个颜色特征
。由于作者只想模拟简单的漫反射颜色,因此禁用了球面谐波。所有上述可优化的参数由
表示,其中
是第
个高斯的参数。为了渲染一组3D高斯,作者需要将它们投影到图像平面上作为2D高斯。然后,对每个像素按照从前到后的深度顺序执行体积渲染,以评估最终的颜色和不透明度。在这项工作中,作者使用了来自文献的高度优化的渲染器实现来优化
。
作者使用在球内随机采样的位置初始化3D高斯,缩放设置为单位比例,不包含旋转。在优化过程中,这些3D高斯会周期性地密集化。与重建流程不同,作者从较少的高斯开始,但更频繁地密集化它们,以与生成进度对齐。作者遵循之前工作的推荐做法,并使用SDS来优化3D高斯。在每一步,作者随机采样一个围绕物体中心轨道的相机姿态
,并渲染当前视图的RGB图像
和透明度
。类似于Dreamtime,作者线性减少时间步长
,这用于对添加到渲染RGB图像的随机噪声
进行加权。然后,使用不同的2D扩散先验
来指导SDS去噪步骤,这一步骤被反向传播到3D高斯。
对于图像到3D任务,给定输入图像
和前景遮罩
。使用Zero-1-to-3 XL作为2D扩散先验。SDS损失可以表示为:
其中,
是由2D扩散先验
预测的噪声,
是从参考相机
到当前相机姿态的相对变化。此外,作者优化参考视图图像
和透明度
以与输入对齐:
其中,
和
是在训练期间线性增加的权重。最终损失是上述三个损失的加权和。
对于文本到3D任务,输入是单个文本提示。遵循先前的工作,使用Stable-diffusion进行文本到3D任务。SDS损失可以表示为:
其中,
是输入文本描述的CLIPemebdding。
讨论:作者观察到,即使在较长的SDS训练迭代后,生成的高斯通常看起来模糊且缺乏细节。这可以通过SDS损失的模糊性来解释。由于每个优化步骤可能提供不一致的3D指导,算法难以正确密集化正在重建的区域或剪除过度重建的区域,如同在重建场景中那样。这一观察促使作者设计了后续的网格提取和纹理细化设计。
3.2 Efficient Mesh Extraction
作者探讨了如何将生成的3D高斯模型转换为多边形网格,并进一步细化纹理。到目前为止,从3D高斯模型提取多边形网格仍是一个未探索的问题。由于空间密度由大量的3D高斯模型描述,采用暴力方法查询密集的3D密度网格可能既缓慢又低效。此外,如何在3D中提取外观也不清楚,因为颜色混合只在投影的2D高斯模型中定义。作者提出了一种基于块状局部密度查询和背投影颜色的高效算法,用于提取纹理网格。
为了提取网格几何形状,需要一个密集的密度网格来应用Marching Cubes算法。高斯分割算法的一个重要特性是,在优化过程中会分割或剪枝过大的高斯模型。作者利用这一特性执行块状密度查询。首先,作者将3D空间
划分为
个块,然后剔除中心位于每个局部块外的高斯模型。这有效地减少了每个块中查询的高斯模型总数。然后,作者在每个块内查询一个
的密集网格,最终得到一个
的密集网格。对于网格位置
的每个查询,作者累加每个剩余3D高斯模型的加权不透明度:
其中,
是从缩放
和旋转
构建的协方差矩阵。然后使用一个经验阈值通过Marching Cubes算法提取网格表面。对提取的网格应用Decimation和Remeshing进行后处理,使其平滑。
颜色背投影。由于作者已经获得了网格几何形状,作者可以将渲染的RGB图像反向投影到网格表面,并将其作为纹理烘焙。作者首先展开网格的UV坐标并初始化一个空的纹理图像。然后,作者均匀选择8个方位角和3个仰角,加上顶部和底部视图来渲染相应的RGB图像。这些RGB图像中的每个像素可以根据UV坐标反向投影到纹理图像上。根据Richardson等人的做法,作者排除了具有小的相机空间z方向法线的像素,以避免在网格边界处不稳定的投影。这种反向投影的纹理图像作为下一个网格纹理微调阶段的初始化。
3.3 UV-space Texture Refinement
在UV-space Texture Refinement小节中,作者介绍了第二阶段的纹理图像细化过程。由于SDS优化的模糊性,从3D高斯提取的网格通常具有模糊的纹理。因此,作者提出了一个细化纹理图像的后续阶段。然而,直接使用SDS损失对UV空间进行微调通常会导致出现伪影,这一点在先前的工作中也有观察到。这是由于在可微渲染中使用的mipmap纹理采样技术。在像SDS这样模糊的指导下,传播到每个mipmap级别的梯度会导致过饱和的颜色块。因此,作者寻求更明确的指导来微调模糊纹理。
作者从SDEdit的图像到图像合成和重建设置中汲取灵感。由于作者已经有了一个初始化纹理,作者可以从任意相机视图
渲染一个模糊图像
。然后,作者用随机噪声扰乱图像,并应用多步去噪过程
使用2D扩散先验来获得一个细化的图像:
其中,
是在时间步
的随机噪声,
分别对应于图像到3D的
和文本到3D的
。起始时间步
被谨慎选择,以限制噪声强度,使得细化图像可以增强细节而不破坏原始内容。然后使用这个细化的图像通过像素级MSE损失来优化纹理:
对于图像到3D任务,作者仍然应用方程中的参考视图RGBA损失。作者发现,大约50步就可以在大多数情况下获得良好的细节,而更多的迭代可以进一步增强纹理的细节。
4. 实验
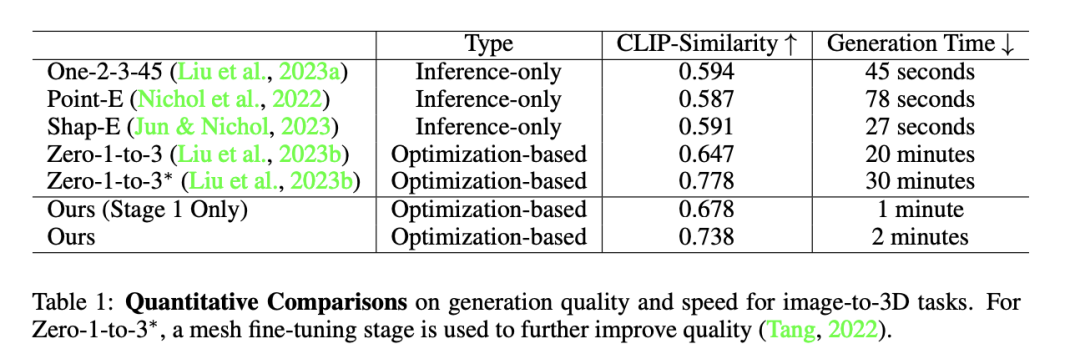
这个实验数据表提供了对于图像到3D任务在生成质量和速度上的定量比较。主要比较了几种不同方法的CLIP相似度和生成时间,其中CLIP相似度越高表示生成的3D图像与目标图像的相似度越高,生成时间则是完成任务所需的时间。从这个表格中,作者可以得出以下分析:One-2-3-45、Point-E、和Shap-E均属于仅推理类方法,这类方法不需要优化过程,因此生成时间较短。在这三种方法中,Shap-E的CLIP相似度最高(0.591),同时也拥有最快的生成时间(27秒)。Zero-1-to-3和**Zero-1-to-3
**属于基于优化的方法。其中,Zero-1-to-3
通过使用网格微调阶段进一步提高质量,因此其CLIP相似度显著高于未使用网格微调阶段的Zero-1-to-3(0.778 vs 0.647),但相应的,生成时间也从20分钟增加到30分钟。作者的方法在仅有第一阶段时(优化基础),CLIP相似度为0.678,生成时间为1分钟,已经超过了仅推理方法的性能,并且在与基于优化的其他方法比较时,生成速度显著更快。当包括了作者方法的完整流程(两个阶段)时,CLIP相似度进一步提升到0.738,同时生成时间仅为2分钟。这显示了作者方法在保证较高相似度的同时,显著降低了生成所需时间。
作者的方法在图像到3D任务上,相比于现有的仅推理方法和基于优化的方法,在生成质量(CLIP相似度)和生成速度(时间)上取得了很好的平衡。特别是,相比于其他优化基础的方法,作者的方法大幅缩短了生成时间,同时还保持了较高的生成质量,展示了其在实际应用场景中的潜力和优势。
5. 讨论
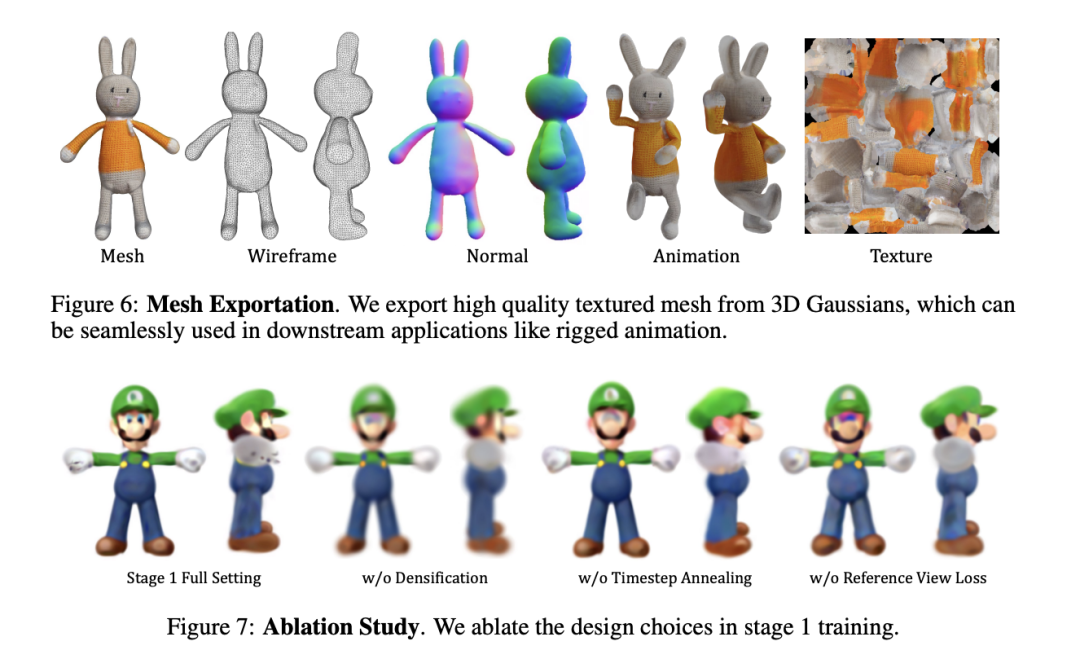
本文提出的方法通过将高斯分割技术引入3D内容生成领域,并进一步通过UV空间纹理细化阶段提高纹理质量,成功地解决了现有技术中的一些关键挑战。这种创新的方法论具有多个显著优点,同时也面临一些潜在的局限性。
通过使用3D高斯模型和高效的网格提取算法,该方法能够快速生成3D内容,显著减少了传统3D内容创建所需的时间和计算资源。与依赖繁重的NeRF渲染的方法相比,这种高斯分割方法简化了优化景观,使得从简单的参数化形式中生成复杂的3D模型变得更加高效和实用。这对于需要快速迭代和生成大量3D内容的应用场景(如游戏开发和虚拟现实)来说是一个巨大的优势。UV-space纹理细化阶段有效地提高了从模糊高斯模型生成的网格的纹理质量,通过引入像素级MSE损失和利用2D扩散先验的多步去噪过程,它能够细化初始粗糙纹理,增强细节,提供更逼真的视觉效果。这一步骤体现了将深度学习方法与传统图形技术相结合的强大潜力,为提高自动生成的3D模型的真实感开辟了新的途径。
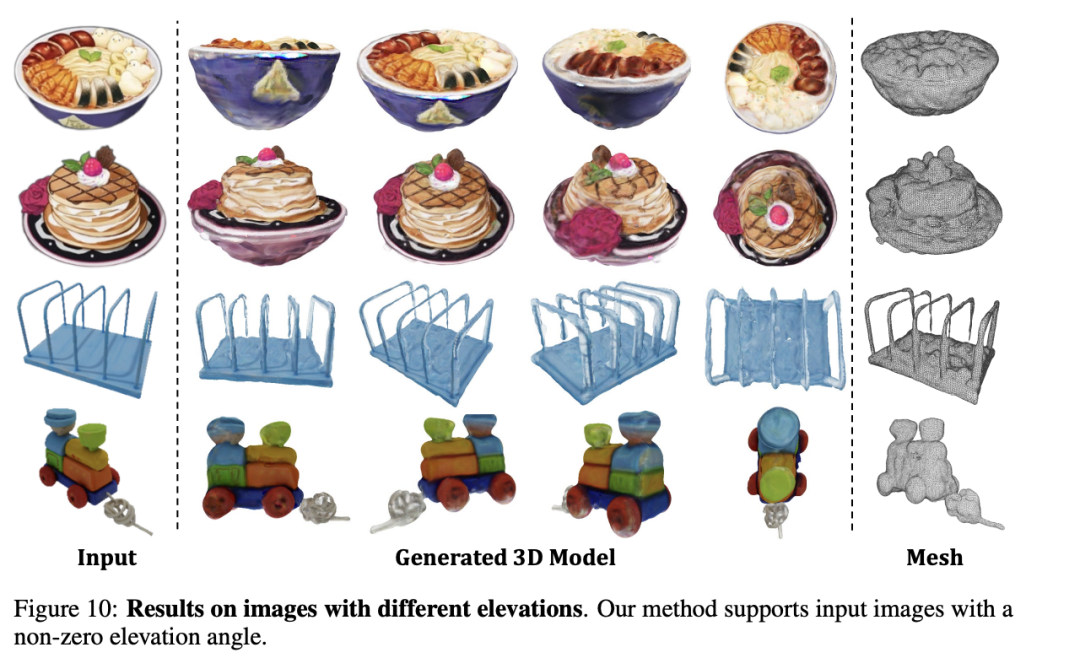
然而,尽管本文方法在多个方面表现出色,但也存在一些缺点。首先,尽管高斯分割方法提高了生成效率,但它在处理极其复杂或高度详细的3D场景时可能不如基于NeRF的方法精确。这是因为高斯模型的简化表示可能难以捕捉到微小的几何细节或复杂的纹理变化,特别是在模型需要极高精度时。尽管UV-space纹理细化阶段可以提高纹理质量,但这一步骤的成功在很大程度上依赖于初始纹理的质量和所选去噪过程的效果。如果初始纹理过于模糊或去噪算法未能正确识别和增强关键细节,最终结果可能不会达到预期的质量水平。
本文提出的方法通过结合高斯分割和UV-space纹理细化,为3D内容生成领域带来了显著的效率和质量提升,展示了深度学习在传统3D建模领域的应用潜力。尽管存在一些局限性,但这些挑战也为未来的研究提供了新的方向,例如进一步优化高斯模型以捕获更细致的细节,或改进纹理细化技术以提高其对不同类型纹理的适应性和效果。
6. 结论
在本文中,作者成功地介绍并实现了一种创新的3D内容生成框架,称为DreamGaussian,该框架结合了高斯分割技术和UV-space纹理细化阶段,以提高自动生成的3D模型的效率和质量。通过高效的网格提取算法,作者能够从3D高斯模型中快速生成粗糙网格,并利用后续的纹理细化步骤显著提高了纹理的清晰度和细节,最终实现了逼真的3D资产生成。本文的方法展示了如何有效地缩短3D内容创建的时间,并减少了对专业3D建模技能的依赖,从而使非专业用户也能参与到3D资产的创作中来。此外,通过将深度学习技术应用于3D建模和纹理生成过程,作者不仅提高了生成质量,而且为3D内容的实时生成和应用开辟了新的可能性,这对于游戏开发、虚拟现实和其他数字娱乐领域来说是一个巨大的进步。
尽管本文的方法在多个方面取得了突破,但在处理极其复杂场景和捕捉微小细节方面仍有提升空间。未来的研究可以探索更高级的高斯模型优化技术和纹理细化方法,以进一步增强生成3D模型的真实感和细节丰富度。DreamGaussian框架代表了3D内容生成领域的一个重要进展,通过提供一种快速、高效且用户友好的生成方法,它为数字内容创作开辟了新的道路。未来,作者期待看到这一方法如何被进一步发展和应用于更广泛的场景和应用中,为创造更加丰富和多样的虚拟世界提供强大的支持。