超对齐!OpenAI | 提出了大型语言模型(LLM)新的研究方向:Superalignment
超对齐!OpenAI | 提出了大型语言模型(LLM)新的研究方向:Superalignment

更多干货,第一时间送达
引言
今天OpenAI又发布了一项新研究,并提出了超对齐(superalignment)研究方向,旨在利用深度学习的的泛化特性来控制具有弱监督能力的强模型。
研究背景
随着目前人工智能大模型的发展,如何控制未来超人的人工智能系统将会成为一个核心问题,为此人类需要一个能够监督人工智能的系统。
为此,OpenAI的研究人员研究了一个简单的假设:小模型能监督大模型吗?通过实验结果,他们发现可以使用 GPT-2 级别的模型引导出 GPT-4 的大部分功能,其性能表现可以接近GPT-3.5。这就开辟了一个新的研究方向,即可通过较小模型来应对超人类模型的控制,并且目前通过实验也取得了一定的实际进展。
超对齐问题
超级人工智能(比人类还要聪明的人工智能)有望在未来十年内具有突破性进展。然而,我们仍然不知道如何可靠地引导和控制超人类的人工智能系统。解决了这个问题,我们才能确保未来超人类的人工智能系统更好的服务人类。
今年早些时候,OpenAI成立了超级对齐团队来解决超级智能对齐的问题。今天,我们发布了该团队的第一篇论文,其中介绍了根据经验调整超人模型的新研究方向。
当前的对齐方法,例如来自人类反馈的强化学习(RLHF),依赖于人类监督。然而,未来的人工智能系统将能够执行极其复杂和创造性的行为,这将使人类难以可靠地监督它们。例如,超人模型可能能够编写数百万行新颖且具有潜在危险的计算机代码,即使对于专家来说也很难理解。
相对于超人的人工智能模型,人类将是“弱监督者”,作为“弱监督者”如何才能有效的控制超强的人工智能模型呢?这是 AGI 一致性的核心挑战。
研究设置
如下图所示,在传统机器学习 (ML) 中,人类可以监督比自己弱的人工智能系统(左)。为了协调超级智能,人类需要监督比他们更聪明的人工智能系统(中)。为了能够在该挑战上取得突破性的进展,OpenAI提出了一个可以实证研究的假设,可以使用较小(能力较差)的模型来监督较大(能力更强)的模型吗?

在此过程中,我们并不期望一个强大的预训练模型比提供训练信号的弱监督者表现得更好,因为对于强模型来说,它可能只是学会模仿弱监督者所犯的所有错误。我们所希望的是强大的预训练模型具有出色的原始能力,它们无需从头开始训练,只需要引导出它的潜在知识。
那么关键的问题是:强模型是否会根据弱监督者的潜在意图进行泛化——即使在弱监督者只能提供不完整或有缺陷的训练标签的困难问题上,也能利用其全部能力来解决任务?
实验结果
我们可以通过很多方法来提高强模型的泛华能力。最简单的一个方法就是引导模型更加自信,并且在必要的时候可以引导其反对弱监督模型的观点。当在 NLP 任务上使用此方法用 GPT-2 级模型监督 GPT-4 时,所得模型的性能通常介于 GPT-3 和 GPT-3.5 之间, 即可以通过较弱的监督来恢复 GPT-4 的大部分功能。如下图所示:
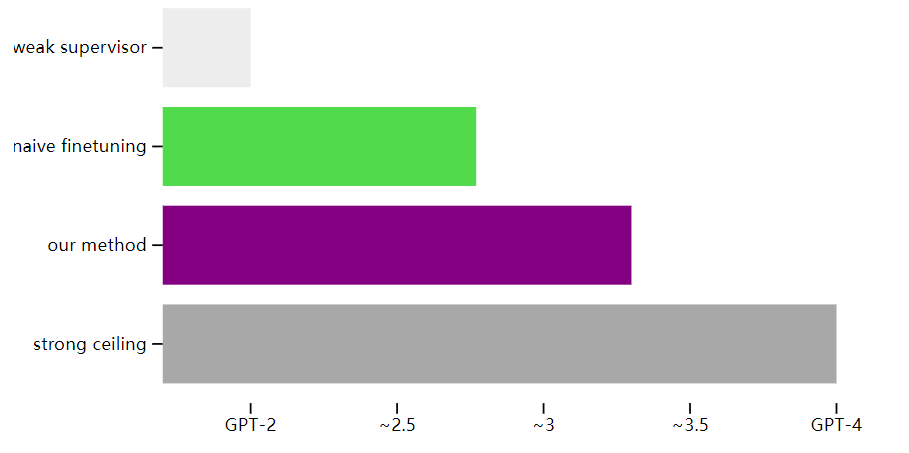
这种方法具有一定的局限性。例如,它不适用于ChatGPT。然而,在此过程中也发现了其它的方法,例如从小型到中型再到大型模型的最佳停止和引导。
总的来说,结果表明,(1)人类监督——例如来自人类反馈的强化学习(RLHF)——如果不进行进一步的工作,可能很难扩展到超人类模型,但是(2)大幅提高从弱到强的泛化能力是可行的。
研究机会
当前的实证设置与最终对齐超级智能模型的问题之间仍存在一些重要差异。举例而言,未来的模型可能更容易模仿人类的低级错误,而不是当前的强模型模仿目前弱模型的错误,这可能使未来的泛化变得更加困难。
尽管存在这些不同之处,OpenAI的实验框架捕捉到了对齐未来超级智能模型所面临的一些关键困难,这使得在这个问题上取得实证进展。未来的研究有许多有前途的方向,包括修复我们实验设置中的不一致性、开发更具可扩展性的方法,并深化我们对何时以及如何实现从弱到强泛化的科学理解。
这对于机器学习研究社区来说是一个令人兴奋的机会,未来可以在对齐方面取得新的进展。为了启动该领域的更多研究OpenAI开放了源码:https://github.com/openai/weak-to-strong,并启动了1000 万美元的资助计划,为研究生、学者和其他研究人员广泛开展超人类人工智能对齐工作。