智能汽车虚拟化技术(下)

前言:
上篇内容主要介绍了虚拟化技术本身的基本概念,以及车载虚拟化技术的一些特点。而本篇的内容则主要围绕一些虚拟化的技术路线以及行业内的部分应用来展开,同时也带来我们的虚拟机管理器产品(Photon Hypervisor)的介绍。
Hypervisor 与虚拟机协作技术路线
(1)全虚拟化
最初的虚拟化是通过软件模拟具有完整硬件系统功能的、运行在一个隔离环境中的计算机系统,即通过软件虚拟硬件设备提供给GuestOS使用,优点是GuestOS不感知外部真实硬件环境、不用改动。
由于GuestOS中每次访问全虚拟化硬件都要陷入到Hypervisor中,直接导致该方式虚拟的硬件性能较差,一般只用来模拟如串口等比较简单的硬件。对硬件的模拟可以在Hypervisor中直接模拟,也可以将请求传递到其他VM中进行模拟,如在某一VM中通过QEMU进行模拟。
(2)硬件辅助虚拟化
Intel最早提出硬件辅助虚拟化技术,由硬件直接提供共享功能,支持多GuestOS的访问,减少软件虚拟技术带来的延时和性能损耗。
Intel提出了分别针对处理器&内存、IO、网络的Intel VT-x、Intel VT-d和Intel VT-c技术等。随着ARM算力提升,从移动端向边缘、甚至云算力中心发展,ARM也在不断增强其硬件辅助虚拟化技术,比如stage2页表转换、虚拟异常等。
(3)半虚拟化
在硬件辅助虚拟化技术不完善、不强大的发展阶段,或者对于某些复杂外设的共享复用,为避免全虚拟化的性能问题,可以采用GuestOS与Hypervisor协作的半虚拟化技术。
这种技术一般应用于IO设备虚拟化,采用前后端的方式来实现IO设备虚拟化,在GuestOS中实现前端驱动,在Hypervisor或HostOS中实现后端驱动,前后端一般按照VirtIO标准来实现,后端驱动作为硬件的实际访问方。
GuestOS中前端驱动通过Virt Queue等通信机制与后端驱动进行通信,前端驱动将Guest OS的请求传递给后端驱动,后端驱动将请求发送给硬件驱动,处理完后将结果再传回给前端驱动。半虚拟化相对全虚拟化实现的硬件性能较好,且可实现相对比较复杂的硬件,比如 : 块设备,网卡,显示设备等。
Hypervisor支持将硬件资源直接分配给其上虚拟机中GuestOS使用,无需通过Hypervisor进行地址和指令翻译。例如 : 串口资源、USB资源等接口比较丰富的资源可以通过Pass-through直接分配给某虚拟机使用。
设备控制器一般都是以MMIO方式来访问的,所以只需要将控制器地址区域映射到VM就可实现设备控制器的分配,同时还需要分配一个设备硬件中断对应的虚拟中断到该VM,直接透传的方式就是VM独占访问该硬件,所以在性能上是最好的。
而针对车载虚拟化场景,硬件辅助虚拟化和半虚拟化都有涉及。
因为目前用的ARM64架构的硬件是支持硬件辅助虚拟化的,但整体方案上基本上都是用半虚拟化的方案。
车载虚拟化产品
车载虚拟化Hypervisor产品目前国内外有多家厂商在做,比如国外的QNX Hypervisor, Opensynergy, ACRN Hypervisor, Mentor Hypervisor等,国内的RAITE Hypervisor, Alios Hypervisor以及国科础石的Photon Hypervisor等。
而面向汽车量产,业内主流的方案基本上是QNX Hypervisor产品。
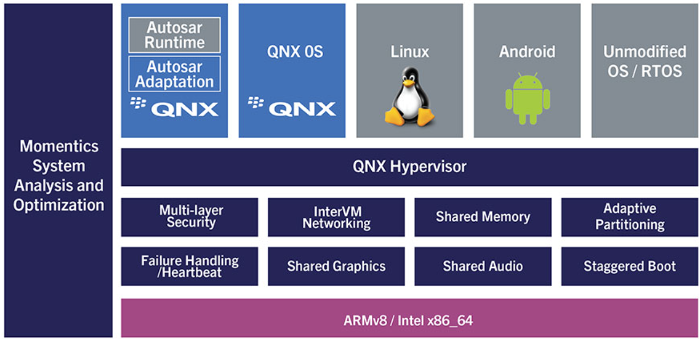
QNX Hypervisor属于微内核架构,同时也适配多个平台(高通、瑞萨、恩智浦、瑞芯微等),目前在国内市场我们看到采用“QNX Hypervisor+高通8155”的组合方案相对比较多。
目前成熟的方案运行在座舱域的比较多,而在舱驾融合的趋势下,底层通过Hypervisor进行隔离,将自动辅助驾驶、智能座舱和高性能计算网关运行在一个SOC硬件上将是未来的重要方向。
虚拟机管理器(Photon Hypervisor)
础光虚拟机管理器是国科础石推出的Hypervisor产品,是基于I型Hypervisor宏内核架构,可支持同时运行Linux、Android和RTOS等多个虚拟机操作系统,实现CPU、内存、外设等硬件资源在操作系统间的有效隔离,满足功能安全和信息安全的要求。
虚拟机管理器主要由如下三个部分构成:
- 虚拟化功能
- CPU虚拟化:运行在ARMv8不同EL等级
- 内存虚拟化:基于内存两阶段映射VTTBR
- 中断虚拟化:基于GICv2/GICv3虚拟化扩展功能
- 设备虚拟化:在hypervisor层实现驱动和后端 / 代理方式
- 基础内核
- 内核动态内存管理
- 基于优先级可抢占实时调度
- 中断支持GICv2/GICv3
- 支持驱动框架,支持clk,emmc等驱动
- BSP
- 支持dts硬件资源配置
- 板卡相关驱动,如串口
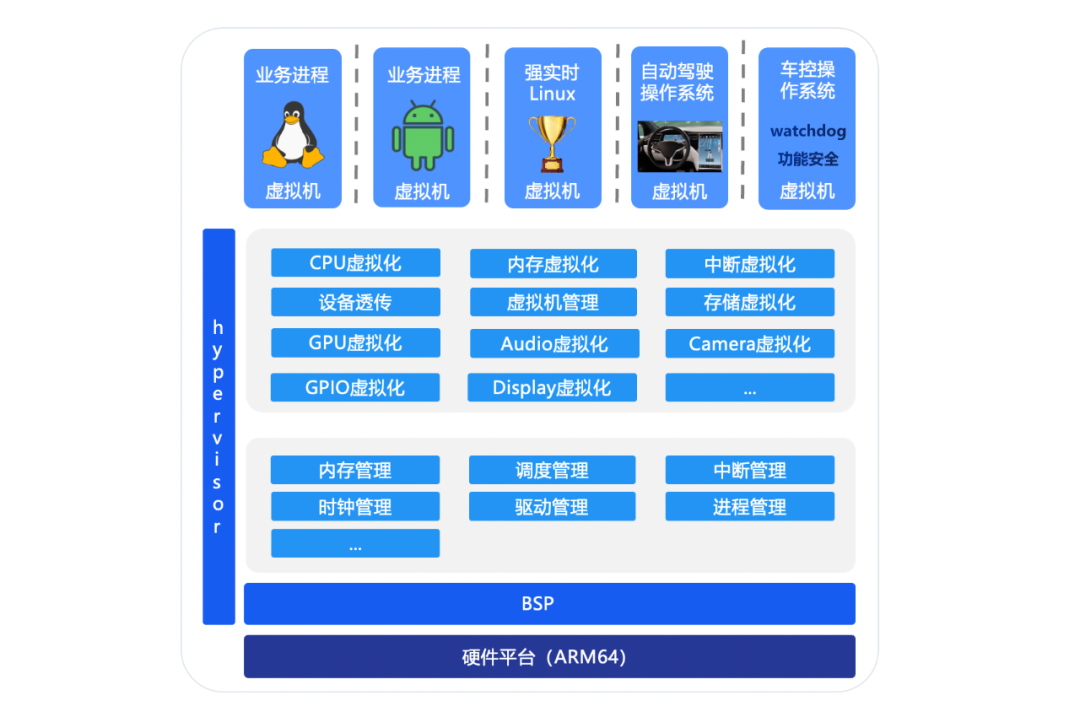
虚拟机管理器(Photon Hypervisor)部分核心功能
- CPU虚拟化
CPU虚拟化就是可以通过多个虚拟机共享物理CPU资源,对虚拟机中的敏感指令进行截获并模拟执行。
础光虚拟机管理器的CPU虚拟化原理是基于ARMV8的异常等级,Hypervisor通常是运行在EL2等级,GuestOS的内核是运行在EL1等级,GuestOS的用户态运行在EL0等级,实际上CPU虚拟化主要是解决不同的态之间切换的问题。
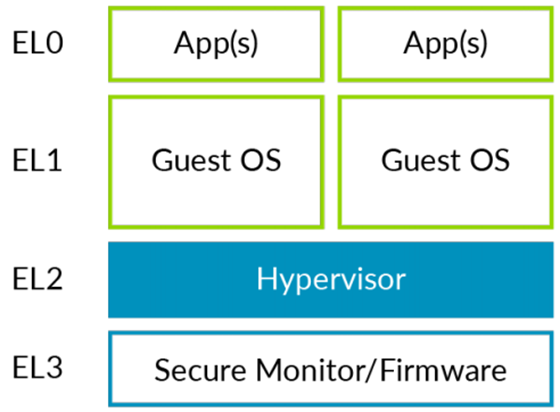
实际上操作系统只有异常(含中断)发生或异常(含中断)处理返回时,才能进行EL切换。
当异常发生:
有两种选择,停留在当前的EL,或者跳转到更高的EL,EL不能降级。
EL0 => EL1: SVC (system call)
EL1 => EL2: HVC (hypervisor call)
EL2 => EL3: SMC (secure monitor call)
当异常返回:
有两种选择,停留在当前EL,或者跳到更低的EL。
可以通过ERET(异常返回, 使用当前的SPSR_ELx和ELR_ELx)跳到更低的EL。在ELR_ELx中保存了返回的地址,SPSR_ELx中的M[3:0]中保存了异常返回的异常层级。
下图可能就会更直观一点。
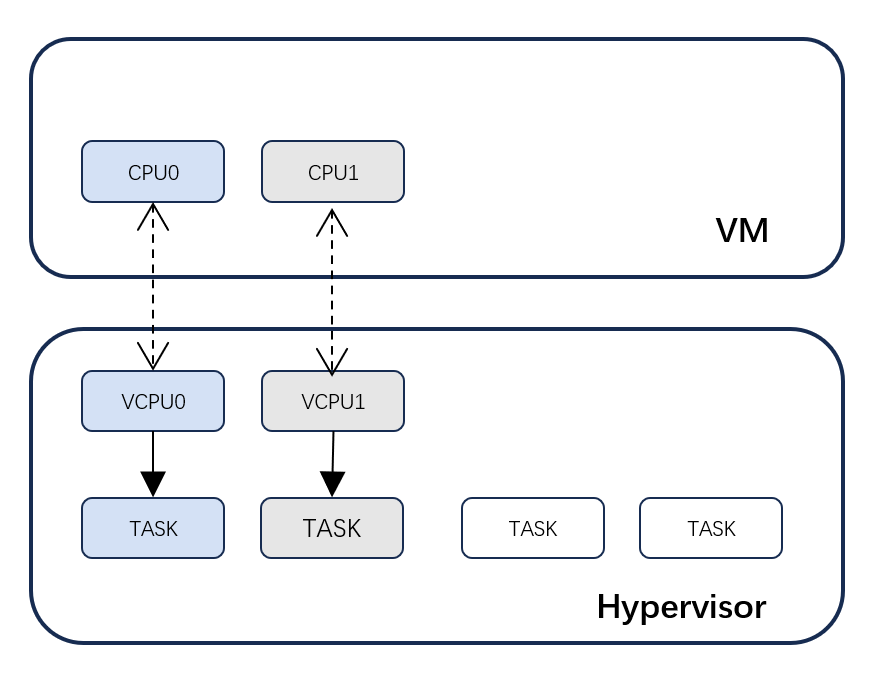
一个虚拟机实际上是由多个VCPU来组成的,那么从Hypervisor这个角度来讲的话,实际上每个VCPU是对应到一个task任务上来的。
Hypervisor本身是一个实时操作系统,包含进程管理、进程调度等功能。task实际上分为两种:
- 一种就是普通task,比如在Hypervisor上会有一些工作队列的task,这种task主要是为Hypervisor自身服务的,我们可以称之普通task,它的特点是和VCPU不做关联,
- 还有一种 task 会跟VCPU做关联,也就是说一个VCPU会对应到一个task,最终在Hypervisor这层的调度都是以task为单位进行的。
下图可以简单解释task 之间切换的过程。
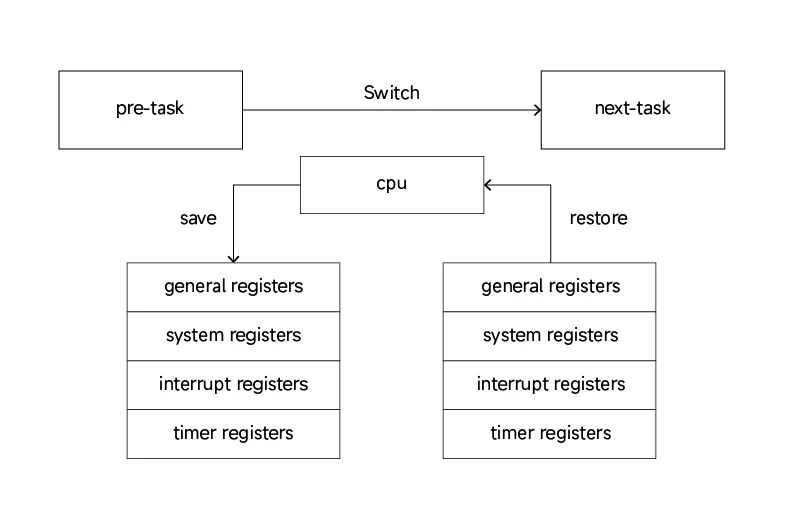
普通的task切换是从pre-task到next-task,在这里面会去做一些寄存器的保存以及寄存器的恢复。
如果涉及到VCPU的切换的话,除了需要保存和恢复task相关的寄存器,还需要额外保存和恢复与VCPU相关的vgic、虚拟时钟等寄存器。这里面也包括几种情况:
- vcpu --> task 保存vcpu上下文
- task --> vcpu 恢复vcpu上下文
- vcpu --> vcpu 保存&恢复vcpu上下文
- task --> task 不涉及vcpu上下文
- 内存虚拟化
础光虚拟机管理器内存虚拟化是基于ARMv8内存虚拟化的两阶段映射。虚拟机通过TTBRn_EL1完成Stage 1的地址转换,将虚拟机使用的VA转换成intermediate physical address(IPA,中间物理地址)。然后再通过VTTBR_EL2完成Stage 2的地址转换,将IPA转换成PA。Hypervisor内核运行在EL2,其使用的内存通过TTBR0_EL2完成地址映射。从而完成最终物理地址的映射。
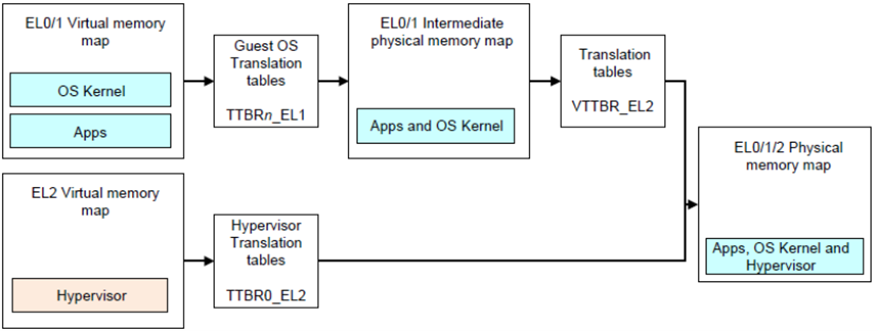
下图更加直观,最左边是虚拟机视角,它里面除了内核,还有一些外设的映射,这里面看到的是虚拟机的虚拟地址。然后通过第一级映射(stage 1)转化成虚拟机的物理地址,然后再通过第二级映射(stage 2)最终转化成在HostOS上的物理地址,也就是硬件能看到的地址。
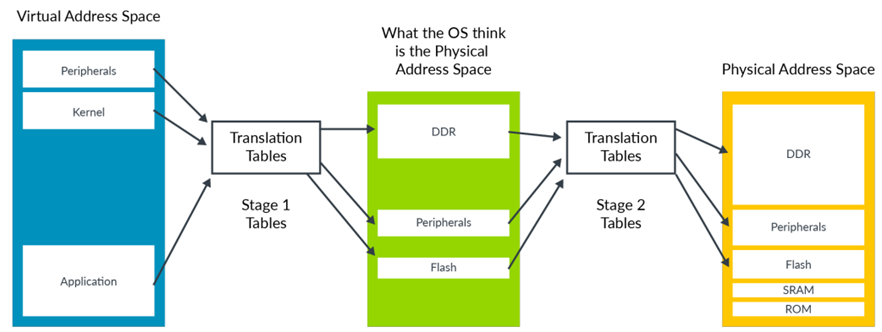
具体虚拟机IPA不同类型地址的映射方式可参照下图:
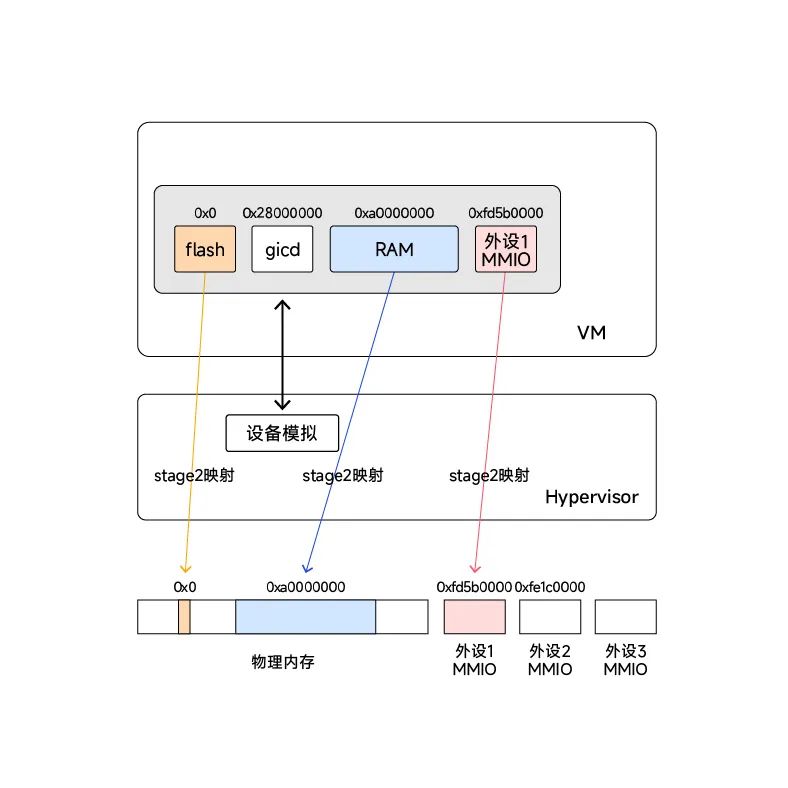
不同种类的虚拟机IPA地址会以不同的映射方式最终对应到硬件上。比如:
- Flash:虚拟flash,用于存放虚拟机相关镜像文件,内存由Hypervisor动态申请,非1:1映射
- gicd:中断虚拟化的模拟设备,不需要映射到真实内存,在Hypervisor中做读写模拟
- RAM:虚拟机RAM内存,在stage 2映射时做1:1映射
- 外设MMIO:外设MMIO内存,在stage 2映射时做1:1映射
- 中断虚拟化
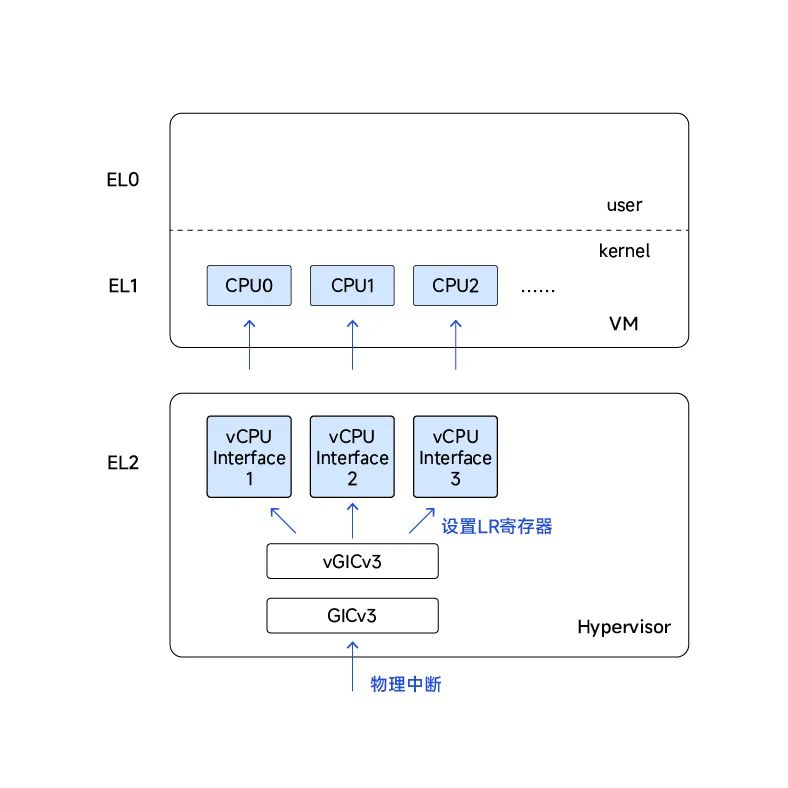
础光虚拟机管理器的中断虚拟化最底层基于GICv2/GICv3的虚拟化扩展的特性来做的。我们以GICv3为例,它有redistributor模块,我们可以理解每一个都会对应物理的CPU,为了支持虚拟化,除了提供physical CPU interface之外,也有virtual CPU interface。我们做中断虚拟化主要就是用了virtual CPU这部分特性。
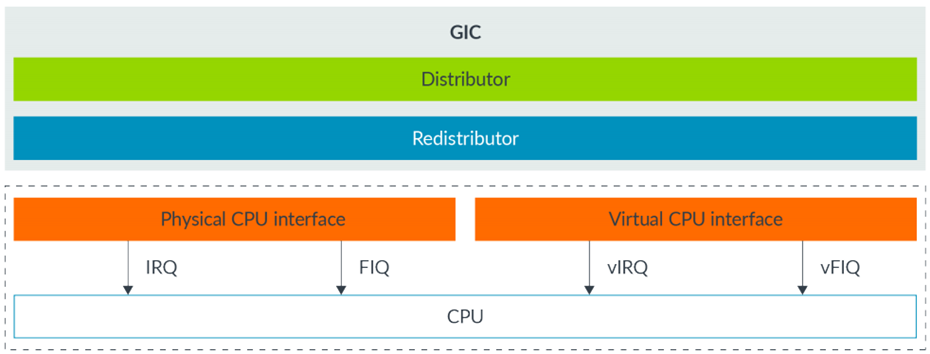
那么如何实现的呢,我们还是以GICv3为例进行说明,整体的过程就是:
1)物理中断从Redistributor发往物理CPU Interface。
2)Hypervisor读取中断信息,决定中断是否发给虚拟CPU Interface。
3)Hypervisor设置LR寄存器,注入虚拟中断。
4)在虚拟机EL1产生中断,虚拟机处理该中断。
- 设备虚拟化
上面的CPU虚拟化、内存虚拟化以及中断虚拟化属于Hypervisor最基本的功能,但其实整个Hypervisor的难点和重点在于设备虚拟化。
怎么理解设备虚拟化?举个例子来说,比如说硬件上除了包含CPU、内存和一些中断功能控制器之外,其实还有很多外设,比如USB,音频,摄像头等等设备,我们怎么样吧这些外设给虚拟机用,这里面就需要用到设备虚拟化的功能。
目前可以采用设备透传和设备共享两种方案,他们的区别在于:
- 设备透传——设备被某个虚拟机独享
- 设备共享——设备可以在多个虚拟机间共享
举个例子,比如在多个虚拟机的场景下,硬件只有一个网卡,当虚拟机需要对外通讯的时候,通过设备透传的方案,那么只能把网卡给一个虚拟机使用,而设备共享的话则是可以多个虚拟机共享使用。
在我们的产品中,主要还是采用设备共享的方式实现设备虚拟化。
关于设备共享,目前业内主要是两种方案,即host后端方式和代理后端方式。
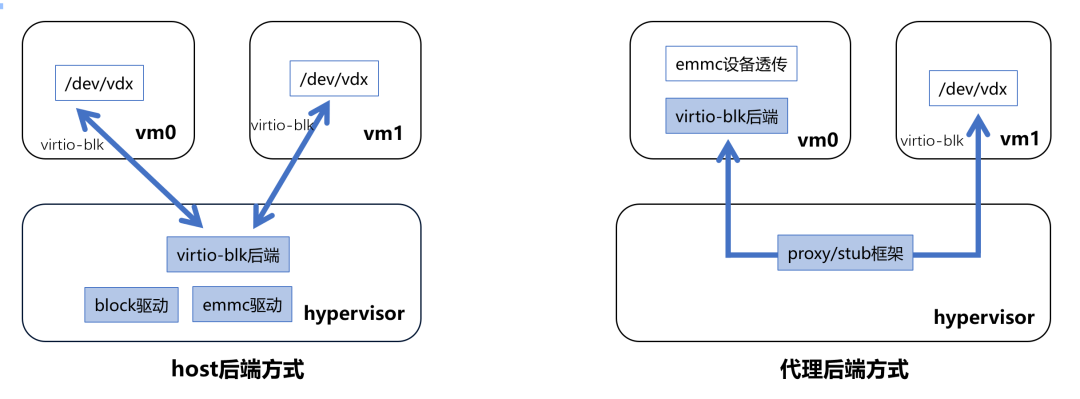
两种方式的区别在于一种是把后端做到Hypervisor这层,另外一种方式就是把后端做到其中的一个GuestOS里面去。两种方式各有利弊,首先host后端方式的好处是虚拟机重启相互不会影响,也不需要修改虚拟机的内核,但需要与芯片/驱动厂商深度合作,一方面通用性和适配的工作量很大,同时也需要在Hypervisor增加很多模块使其相对复杂,带来不稳定性。
而代理后端方式则相反,可以充分利用Linux的成熟生态,另外把后端做到GuestOS以后Hypervisor只实现代理框架,更轻量化,通用性强;但虚拟机VM0如果重启会影响其他虚拟机,同时也需要修改虚拟机(后端)的内核。
我们的Hypervisor产品则可以根据不同的硬件适配情况选择更优的方式实现设备虚拟化。
当然,设备虚拟化这里还有更多更具体的核心功能,同时也有除上述虚拟化功能之外的其他功能点,但篇幅有限,暂不做过多介绍了。
随着产品开发的不断深入,目前我们的虚拟机管理器产品已完成多家主流芯片厂商的适配,并在功能安全认证方面不断努力,接下来也会持续位大家带来同步产品的进展情况,请大家持续关注。
如果有想更多了解虚拟机管理器(Photon Hypervisor)产品的小伙伴,可以后台留言,我们将与您进一步交流。