关于OLAP和OLTP你想知道的一切

关于OLAP和OLTP你想知道的一切
OLAP是英文Online Analytical Processing的缩写,中文称为联机分析处理。它是一种基于多维数据模型的分析处理技术,用于从不同的角度进行数据挖掘和分析,以帮助用户快速发现数据之间的相关性和趋势。
OLAP技术通常涉及到预计算、缓存和查询优化等方面的技术,可用于构建在线分析系统(OLAP系统)。该系统将大量的数据按照多个维度进行组织和展示,并提供灵活的查询和聚合功能,以用于支持决策制定、业务分析和报告生成等应用场景。
与传统的关系数据库管理系统(RDBMS)相比,OLAP系统具有更高的查询速度和更丰富的分析功能。它可以在秒级别内查询数千万、甚至数亿条记录,并支持多维度聚合、钻取、切片和切块等功能。因此,OLAP技术在商业智能(BI)和大数据分析领域得到了广泛的应用。
那什么又是OLTP呢?
OLTP是联机事务处理(Online Transaction Processing)的英文缩写,它是一种用于管理业务交易的数据库技术。OLTP系统通常支持高并发的数据插入、更新、删除和查询操作,以保证业务的实时性和准确性。
与OLAP不同,OLTP系统的主要目标是对业务数据进行快速的增删改查操作。因此,OLTP系统需要具有高度的可用性、事务性和数据完整性等特性,以满足业务处理的要求。此外,OLTP系统还需要具有良好的性能和扩展性,以应对高并发访问和大规模数据存储的需求。
OLTP系统通常使用关系型数据库管理系统(RDBMS)实现,例如MySQL、Oracle、Microsoft SQL Server等。这些数据库提供了严格的事务控制和ACID特性,以确保业务数据的一致性和可靠性。同时,它们还提供了丰富的查询和索引功能,以支持各种复杂的业务查询和报表生成。
下面是OLAP和OLTP在不同方面的对比:
特性 | OLAP | OLTP |
|---|---|---|
主要使用场景 | 数据分析、决策支持 | 业务交易处理 |
涉及数据量 | 大规模数据(TB或PB级别) | 中等规模数据(GB或TB级别) |
事务和数据完整性 | 不涉及事务,侧重于数据的一致性和准确性 | 需要严格的事务控制和ACID特性,以保证数据的一致性和可靠性 |
功能使用需求 | 多维度查询、聚合、切片、钻取等 | 插入、更新、删除、查询等基本业务操作 |
并发要求 | 读写比较平均,相对较低的并发请求 | 高并发的数据插入、更新、删除和查询操作 |
技术实现方案 | 基于多维度数据模型的处理引擎(如Kylin、Palo等) | 关系型数据库管理系统(RDBMS)(如MySQL、Oracle等) |
可用性要求 | 强调冷热数据分离、容错性等,但非高可用性 | 强调高可用性、故障恢复、备份和灾备等 |
数据模型/规约 | 多维度数据模型,支持OLAP Cube等 | 关系型数据模型,支持SQL查询等 |
技术典范 | Hadoop、Spark、Hive等大数据技术栈 | MySQL、Oracle、Microsoft SQL Server等传统数据库技术栈 |
OLAP准则
- 多维性:OLAP模型必须提供多维概念视图,支持用户在多个维度上对数据进行切片、切块、钻取等操作。
- 透明性准则:OLAP系统需要提供透明的数据访问方式,用户可以方便地访问和分析数据,无需了解底层数据存储结构。
- 存取能力准则:OLAP系统需要支持高效的数据存取能力,包括对大量数据的查询、汇总和分组等操作。
- 稳定的报表能力:OLAP系统要具备稳定且高效的报表生成能力,支持各种形式的数据可视化和分析展示。
- 客户/服务器体系结构:OLAP系统需要采用客户/服务器体系结构,以提高系统的可靠性、可扩展性和性能。
- 维的等同性准则:OLAP系统应该支持维的等同性,即允许用户在不同维度上进行比较和分析。
- 动态的稀疏矩阵处理准则:OLAP系统需要支持动态的稀疏矩阵处理,以便更加灵活地处理不规则的数据。
- 多用户支持能力准则:OLAP系统要具有良好的多用户支持能力,可以同时处理多个用户的查询请求。
- 非受限的跨维操作:OLAP系统需要支持非受限的跨维操作,允许用户在不同维度上自由切换和分析数据。
- 直观的数据操纵:OLAP系统要支持直观的数据操纵,例如通过拖拽、下拉菜单等方式对数据进行操作。
- 灵活的报表生成:OLAP系统需要支持灵活的报表生成,允许用户根据需求自定义报表格式和样式。
- 不受限的维与聚集层次:OLAP系统需要支持不受限的维与聚集层次,允许用户在不同层次上进行数据分析和比较。
- 可扩展性:OLAP系统需要具备良好的可扩展性,可以根据业务需求灵活地扩展系统容量和性能,例如通过增加节点、分区等方式来实现水平扩展。
- 易用性:OLAP系统要尽可能简单易用,用户可以通过自然语言查询、可视化分析等方式轻松地进行分析,减少学习和使用成本。
- 安全性:OLAP系统需要具备高度的安全性,可以通过身份认证、访问控制等方式来保护数据的机密性和完整性,防止数据被未经授权的用户窃取或篡改。
OLAP场景的关键特征
数据读写特征
- 大多数是读请求
- 网站分析、BI工具等OLAP应用场景通常需要快速响应查询请求,因此大多数操作都是读取数据而不是写入数据。
- 数据总是以相当大的批(> 1000 rows)进行写入
- OLAP系统需要支持高效的数据加载,常常使用ETL工具将数据批量导入数据库中。
- 不修改已添加的数据
- OLAP系统的数据不经常修改,主要用于历史数据和长期分析,因此不像OLTP系统那样需要频繁地更新记录。
查询特征
- 每次查询都从数据库中读取大量的行,但是同时又仅需要少量的列
- OLAP系统需要支持对大量数据的复杂查询和分析,因此通常会读取大量的记录,但只返回用户需要的几个列。
- 宽表,即每个表包含着大量的列
- OLAP系统需要支持多维数据分析,通常采用宽表(Wide Table)结构存储数据,每个表包含大量的列。
- 较少的查询(通常每台服务器每秒数百个查询或更少)
- OLAP系统通常只处理少量的查询请求,但每个查询需要读取大量的数据进行分析。
- 对于简单查询,允许延迟大约50毫秒
- 对于一些简单的查询请求,用户可以接受一定的延迟时间,但是对于复杂的查询请求,用户需要快速得到结果。
- 列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
- OLAP系统存储的数据通常比较整齐,列中的数据类型都相同,且相对较小。
- 每一个查询除了一个大表外都很小
- OLAP系统中的查询通常涉及多个表,但只有一个表包含大量的数据,其余表的数据相对较小。
- 查询结果明显小于源数据,换句话说,数据被过滤或聚合后能够被盛放在单台服务器的内存中
- OLAP系统的目标是提供快速响应的查询结果,因此查询结果通常需要进行聚合和过滤操作,得到一个较小的数据集,以减少数据传输和处理的开销。
性能特征
- 处理单个查询时需要高吞吐量(每个服务器每秒高达数十亿行)
- OLAP系统需要支持高性能的数据处理,能够处理海量数据,提高查询效率和响应速度。
- 事务不是必须的
- OLAP系统中对数据的修改操作比较少,因此事务处理并不是必要的。
- 对数据一致性要求低
- OLAP系统中的数据通常用于历史数据和长期分析,一定程度上可以容忍数据的不一致。因此对于数据一致性的要求相对较低。
OLAP与OLTP的区别特征
- OLAP系统强调数据分析,而不是数据库内存效率
- OLAP系统的目标是支持复杂的数据分析和决策支持,因此注重查询和分析能力,而不是内存效率。
- OLAP系统强调SQL执行时长和磁盘I/O,而不是内存各种指标的命令率和绑定变量
- OLAP系统需要处理大量数据,因此注重SQL执行性能和磁盘I/O效率,以提高查询效率和响应速度。
- OLAP系统强调分区,以提高查询效率和可扩展性。
- OLAP系统通常会将数据按照特定的规则进行分区,以提高查询效率和可扩展性,并支持更快速的数据加载和备份。
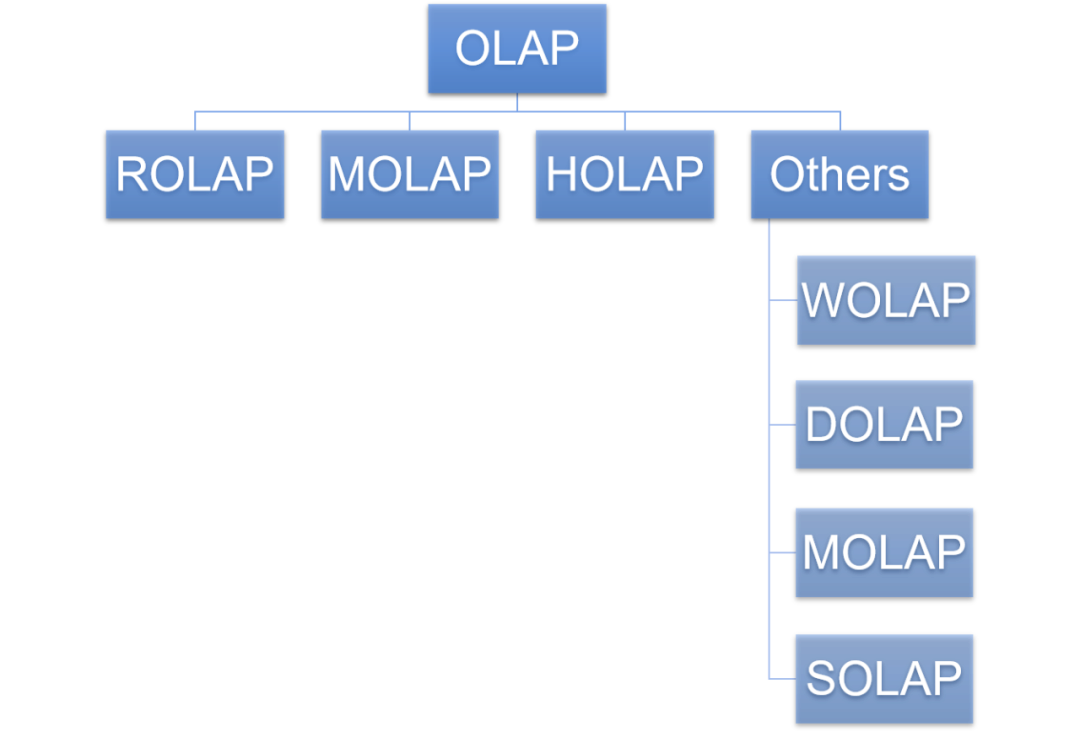
OLAP分类
类型 | 描述 | 优点 | 缺点 |
|---|---|---|---|
ROLAP(关系型OLAP) | 基于关系型数据库实现OLAP的技术。 | 灵活性高,可以处理大量数据、各种不同类型的查询操作;易于管理和维护;适合实时查询和分析。 | 性能相比MOLAP较弱;难以支持复杂的多维关系;需要专门的存储设备和软件环境来保证其高性能。 |
MOLAP(多维OLAP) | 基于多维存储模型实现OLAP的技术。 | 性能高,可以快速处理复杂的多维查询和分析操作;提供丰富的数据可视化功能,方便用户观察和理解数据;支持离线分析和数据挖掘。 | 数据量大时占用空间较大;对数据修改操作有一定限制;不适合并发访问和实时查询。 |
HOLAP(混合OLAP) | 结合ROLAP和MOLAP的特点,使用两种技术共同构建一个OLAP系统。 | 兼具ROLAP和MOLAP的优点,灵活性和性能都较高;支持复杂的多维查询和分析操作,同时也可以处理实时查询。 | 需要较高的技术水平来实现和维护;在处理大量数据时,性能可能会受到影响。 |
Others(其他OLAP) | 包括HOLAP以外的其他不同类型的OLAP技术,如WOLAP、SOLAP等。 | 扩展性好,可以适应各种不同的数据存储和查询需求;提供特定的功能和工具,支持各种不同的数据分析操作。 | 可能需要额外的硬件和软件环境来保证其高性能;在处理大量数据时,性能可能会受到影响;需要针对不同类型的OLAP技术进行专门的培训和学习。 |
OLAP系统通常可以分为三类:
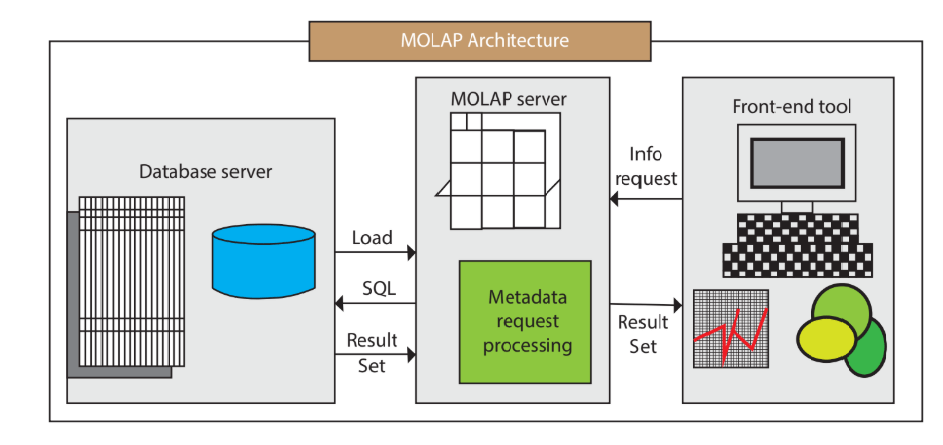
- 基于多维数组的OLAP(MOLAP):这种OLAP系统使用多维数组来存储和查询数据,具有快速响应、高性能等特点。但是,MOLAP系统面临着存储空间限制和缓存效率等问题,尤其在面对大规模数据时,可能会出现性能瓶颈。
多维OLAP(Multi-dimensional OLAP,MOLAP)是一种以多维数组或称为多维数据立方体(multidimensional cube)为基础的OLAP系统,它以多个维度来表示和存储数据,并提供了快速的多维数据分析和查询功能。
在多维OLAP系统中,数据通常是按照事实表和维度表的方式组织和存储的。事实表包含了各种业务数据以及与之相关的度量(measures),如销售额、库存量等;而维度表则包含了各种描述性的属性信息,如时间、地理位置、产品类别等。通过将事实表和维度表联接起来,就形成了一个多维数据立方体,可以方便地进行各种数据分析和查询操作。
多维OLAP系统的优点在于它具有快速响应、高性能、易于使用等特点,能够支持各种复杂的多维数据分析和查询操作,例如:对不同维度的数据进行切片和钻取、同时对多个维度进行分析、按照时间趋势进行分析等。此外,多维OLAP系统还具有灵活性和可扩展性,支持动态添加新的维度和度量等。
因为我这篇文章会把涉及到的比较流行的OLAP的框架都总结进来,所以会把下面要做分类的框架与这个放到前面的总结进行清晰划分。
- MOLAP是基于多维存储模型实现OLAP的技术,典型代表包括Druid和Kylin。
- 在MOLAP中,会根据用户定义的数据维度、度量在数据写入时生成预聚合数据,以加速查询操作,适用于查询场景相对固定,并且对查询性能要求非常高的场景。
- MOLAP的优点在于它通过预处理可以避免查询过程中出现大量的即时计算,从而提升查询性能;同时还支持多维分析和数据挖掘等高级分析操作。
- MOLAP的缺点在于需要预先定义维度,限制了后期数据查询的灵活性;增加新的指标需要重新增加预处理流程,存储成本也较高;不支持明细数据查询,仅适用于聚合型查询。
- MOLAP支持一些聚合函数,如sum、avg、count等,在预处理环节进行计算,并在查询时调用。这些函数只能用于查询预聚合数据,不能查询原始明细数据。
- 基于关系型数据库的OLAP(ROLAP):这种OLAP系统使用关系型数据库技术来存储和查询数据,相比MOLAP系统更具有灵活性和可扩展性。但是,ROLAP系统在处理复杂查询时可能会出现性能问题。
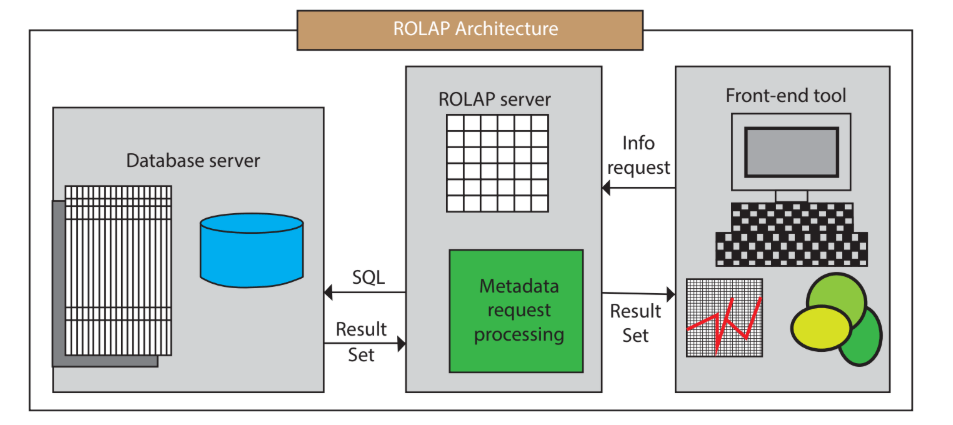
- ROLAP(关系型OLAP)的典型代表包括Presto、Impala、GreenPlum、Clickhouse、Elasticsearch、Hive、Spark SQL、Flink SQL。
- ROLAP不使用预聚合技术,在查询请求到来时即时计算,没有预先聚合好的数据可供优化查询速度。
- ROLAP不需要进行数据预处理,因此查询灵活,可扩展性好。它使用MPP架构,可以高效处理大量数据。
- ROLAP的劣势在于当数据量较大或query较为复杂时,查询性能无法像MOLAP那样稳定;所有计算都是即时触发,因此会耗费更多的计算资源,带来潜在的重复计算。
- ROLAP适用于对查询模式不固定、查询灵活性要求高的场景,如数据分析师常用的数据分析类产品。
- 混合型OLAP(HOLAP):这种OLAP系统结合了MOLAP和ROLAP两种技术的优点,既可以支持快速的多维数据分析和查询,又可以利用关系型数据库的强大查询和计算功能。但是,HOLAP系统需要处理多种不同类型的数据集,可能会导致性能问题或者一致性问题。
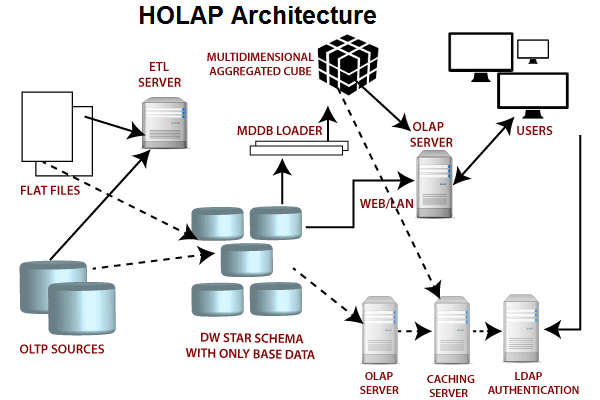
- 混合OLAP结合了MOLAP和ROLAP的优势,提供了所有聚合级别的快速访问。
- 在混合OLAP中,聚合信息存储在OLAP服务器上,而详细记录保留在关系数据库中。因此,不会保留详细记录的重复副本,平衡了磁盘空间需求。
- 混合OLAP的劣势在于它需要同时支持MOLAP和ROLAP,因此本身的体系结构也非常复杂。
- Others(其他OLAP),不在主流分类里,作为参考吧增长点知识
- Others(其他OLAP)包括HOLAP以外的其他不同类型的OLAP技术,如WOLAP、DOLAP、MOLAP和SOLAP等。
- 启用Web的OLAP(WOLAP)适用于基于Web的数据仓库应用程序,允许用户在浏览器中访问和分析数据。
- 桌面OLAP(DOLAP)是运行在个人计算机或工作站上的OLAP系统,通常处理小型数据集。
- 移动OLAP(MOLAP)是专门为移动设备设计的OLAP系统。
- 空间OLAP(SOLAP)是处理空间数据的OLAP系统,支持地图和GIS应用等。
OLAP 架构
概念说明
- Serde:序列化反序列化,serialize/deSerialize
- MPP:大规模并行处理技术 (Massively Parallel Processor)
细节说明
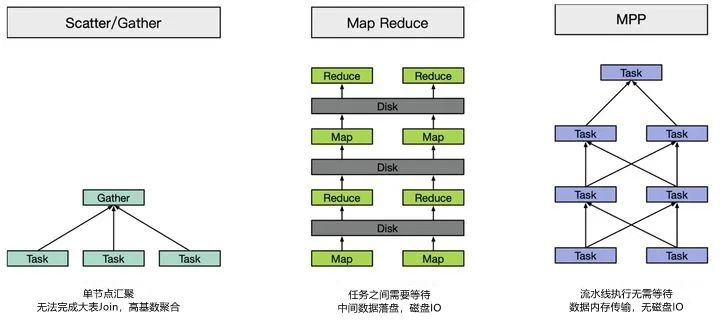
- OLAP架构根据查询类型可以分为即席查询和固化查询。即席查询通过手写 SQL 完成一些临时的数据分析需求,这类 SQL 形式多变、逻辑复杂,对查询时间没有严格要求。而固化查询指的是一些已经固化下来的取数、看数需求,通过数据产品的形式提供给用户,从而提高数据分析和运营的效率。这类 SQL 的模式是固定的,对响应时间有较高的要求。
- 主流的 OLAP 引擎可以根据架构实现方式分为 MPP 架构系统(如Presto、Impala、SparkSQL、Drill等)、搜索引擎架构的系统(如Elasticsearch、Solr等)和预计算系统(如Druid、Kylin等)。MPP 架构系统主要采用分布式查询引擎,而不是使用 Hive+MapReduce 架构,从而提高查询效率;搜索引擎架构的系统则在入库时将数据转换为倒排索引,采用 Scatter-Gather 计算模型,在搜索类查询上能做到亚秒级响应。但是对于扫描聚合为主的查询,随着处理数据量的增加,响应时间也会退化到分钟级;预计算系统则在入库时对数据进行预聚合,进一步牺牲灵活性换取性能,以实现对超大数据集的秒级响应。
- 在选择 OLAP 框架时需要考虑三个方面:数据存储和构建、安装搭建、开发成本。这三个方面涉及到的具体内容包括数据集成、数据模型设计、ETL 工具的选择、服务器规模和授权费用等。此外,还需要考虑系统的扩展性、稳定性、安全性和易用性等因素。
- OLAP 的优势基于数据仓库面向主题、集成的、保留历史及不可变更的数据存储,以及多维模型多视角多层次的数据组织形式。如果脱离了这两点,OLAP 将不复存在,也就没有优势可言。这种存储方式可以快速地响应用户的查询请求,提高数据分析和运营的效率。此外,OLAP 引擎还支持多维分析、数据切片和切块、缓存和压缩等特性,从而提高系统的查询性能和吞吐量。
OLAP引擎的常见操作
OLAP引擎中常见操作的内容:
操作 | 描述 |
|---|---|
上卷/Roll Up | 选定某些维度,根据这些维度来聚合事实。例如:SELECT dim_a, aggs_func(fact_b) FROM fact_table GROUP BY dim_a |
下钻/Drill Down | 选定某些维度,将这些维度拆解出小的维度(如年拆解为月,省份拆解为城市),之后聚合事实 |
切片(Slicing、Dicing) | 选定某些维度,并根据特定值过滤这些维度的值,将原来的大Cube切成小cube。例如:dim_a IN (‘CN’, ‘USA’) |
旋转/Pivot/Rotate | 维度位置的互换 |
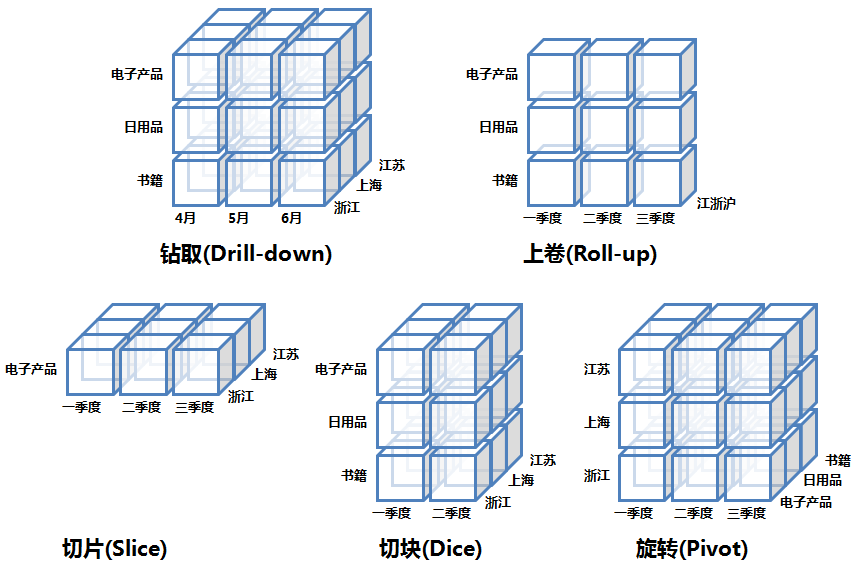
开源OLAP引擎对比
Impala、Presto、ClickHouse、Doris、Druid、TiDB这6个开源OLAP引擎的对比总结:
引擎 | 开源情况 | 优点 | 缺点 | 易用性 | 自身存储 |
|---|---|---|---|---|---|
Impala | Apache项目 | 支持Hive元数据,可以兼容 Hive SQL 使用 MPP 架构,响应速度快 | 不支持 Array 类型 部分 Hadoop 生态系统内缺少集成 | 较易上手,但配置较为复杂 | 依赖于 HDFS 或 Kudu 存储 |
Presto | Facebook开源 | 支持多种数据源和格式,可拓展性强 | 处理海量数据时,性能下降明显 | 查询语言支持 ANSI SQL | 依赖于外部存储(如 HDFS、S3 等) |
ClickHouse | Yandex开源 | 为列式存储设计,查询速度快,压缩率高,扩展性好 | 仅支持 SQL92 标准的语法,不支持 JSON、XML等非结构化数据 | 容易上手,学习资料丰富 | 列式存储系统 |
Doris | Apache项目 | 采用基于列的存储结构,处理千亿行数据,查询速度快,易于扩展 支持多写,易于扩展,提供 RESTFUL API, 技术支持较好 | 对于复杂结构的查询不友好,缺少开发文档 | 支持 MySQL 协议,易于上手 | 基于 HDFS 存储 |
Druid | Apache项目 | 支持超快速的聚合查询和实时数据摄取,可拓展性强 易于安装、配置和使用,社区活跃度高 | 对时间序列数据表现优异,对非时间序列数据支持不足 | 无需外部存储,自身存储能力强 | 自身存储 |
TiDB | PingCAP开源 | 优秀的分布式事务处理能力,支持 SQL 和 NoSQL 数据模型 | 对大数据集查询性能稍逊,单机版性能不理想 | 支持 MySQL协议,易于上手 | 分布式 NewSQL 数据库 |
希望这份总结能够对您有所帮助。需要注意的是,以上信息可能随着引擎版本的更新而发生变化,请以官方文档或最新资料为准。
先来点开胃小菜,先把即将进一步深入分析的OLAP框架进行下简单总结,先在头脑里留下的印象。
简介
- Impala:
Impala是Cloudera开发并开源的,是一种SQL on Hadoop解决方案。与Hive类似,但抛弃了MapReduce,使用MPP数据库技术提高查询速度。Impala可以直接查询存储在HDFS和HBase中的数据,并且支持与现有存储无缝对接。需要单独安装,公司内PAAS主推。提供JDBC接口和SQL执行引擎,易于与现有系统集成。
- Presto:
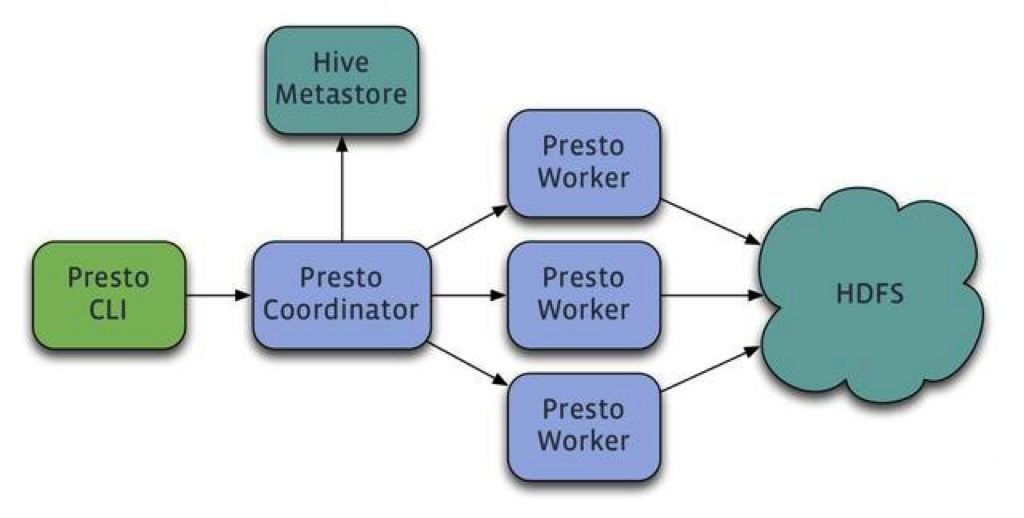
Presto是Facebook开源的大数据查询引擎,旨在解决Hive查询速度慢的问题。使用Java编写,所有数据均在内存中处理。原生集成了Hive、HBase和关系型数据库。提供JDBC接口和SQL执行引擎,易于与现有系统集成。
- Druid:
Druid采用预计算的方式来解决基于时序的数据进行聚合查询的问题。数据可以实时摄入,并立即可查,同时数据几乎不可变。通常基于时序的事实事件进入Druid,外部系统就可以对该事实进行查询。需要预计算,将数据存储在Druid的Segment文件中,占用一定存储资源。对SQL支持不友好,需要使用Druid自己的方言书写。无需外部存储,自身存储能力强。
- Kylin:
Kylin是一种OLAP数据引擎,通过预计算的方式将用户设定的多维度数据立方体(cube)缓存起来,达到快速查询的目的。应用场景是针对复杂SQL join后的数据缓存。需要预计算,将数据构建成cube存储到HBase中。提供JDBC接口和REST服务,易于与现有系统集成。
- Redis:
Redis可以将要分析的数据同步到Redis并在其中快速查询。可以在分析前将本月数据同步到Redis。
对比
并发能力对比:
- 简单查询:
- Impala:表现出色,在并发查询方面优秀,可以支持数千个客户端同时进行操作。
- Presto:性能较好,可以支持高达数百个客户端。
- Druid:支持高并发,并行查询,可以通过增加节点来扩展集群的并发能力,适合处理多个数据流。
- Kylin:由于采用了Cubing层的预计算机制,在查询时可以快速检索缓存中的cube,因此同样具有很强的并发支持。
- Redis:具有极高的并发能力,可以轻松处理高达10万级别的QPS。
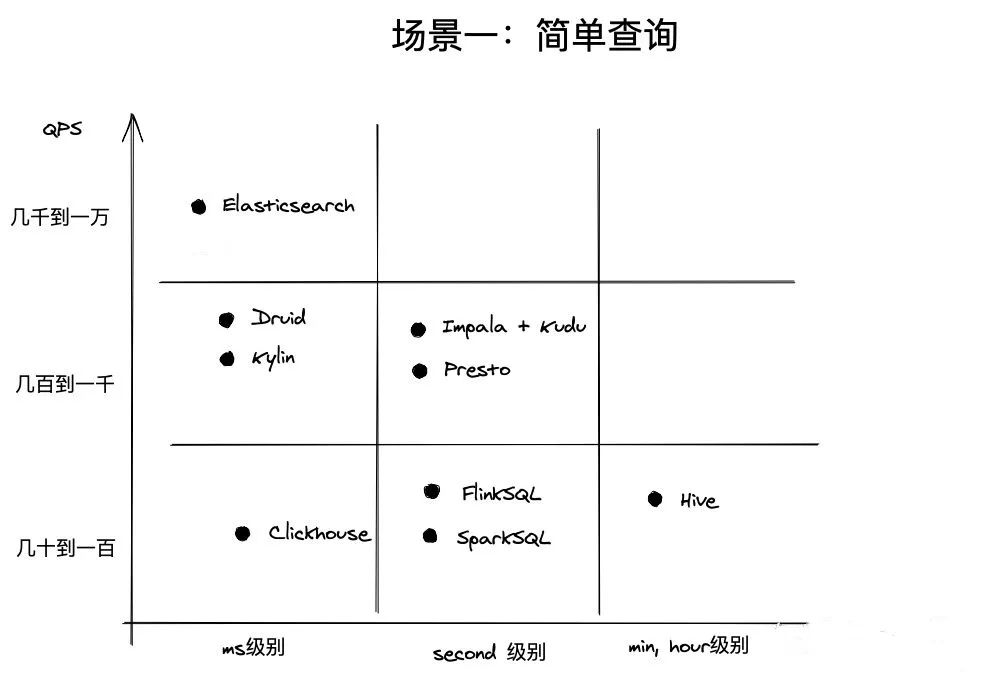
简单查询
- 复杂查询:
- Impala:在复杂查询场景下可能会受到较大的延迟影响,但仍然可以支持相当数量的并发查询。
- Presto:在简单和复杂查询场景下都表现良好,但复杂查询情况下延迟略高于Impala。
- Druid:对于时间序列数据的聚合查询,延迟非常低。但如果需要处理非时序数据,则延迟会明显变高。
- Kylin:仍然具有很强的并发支持,由于采用了Cubing层的预计算机制,在复杂查询场景下仍然能够高效处理。
- Redis:不擅长处理复杂查询,适合处理简单的查询场景。
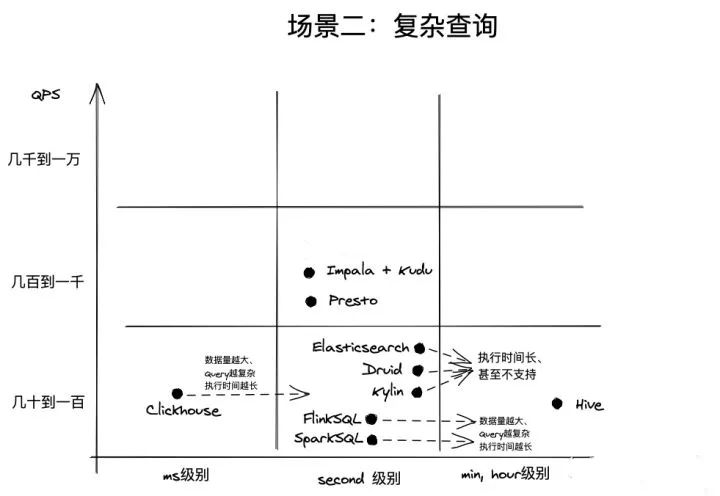
复杂查询
并发能力对比:
- Impala:在并发查询方面表现优异,可支持数千个客户端同时进行操作。
- Presto:对于大量并发查询,性能不如Impala,但仍然可以支持高达数百个客户端。
- Druid:支持高并发,并行查询,可以通过增加节点来扩展集群的并发能力,适合处理多个数据流。
- Kylin:由于采用了Cubing层的预计算机制,在查询时可以快速检索缓存中的cube,因此同样具有很强的并发支持。
- Redis:具有极高的并发能力,可以轻松处理高达10万级别的QPS。
查询延迟对比:
- Impala:在简单查询场景下,延迟表现优秀。但在复杂查询场景下,Impala可能会受到较大的延迟影响。
- Presto:在简单和复杂查询场景下都表现良好,但查询延迟通常略高于Impala。
- Druid:对于时间序列数据的聚合查询,延迟非常低。但如果需要处理非时序数据,则延迟会明显变高。
- Kylin:由于采用了Cubing层的预计算机制,在查询时可以快速检索缓存中的cube,因此具有非常低的延迟。
- Redis:因为数据全部在内存中处理,所以Redis的查询延迟很低。
执行模型对比:
- Impala:使用MPP架构,支持并行查询,适合处理大量小规模的数据。
- Presto:支持分布式查询和并发查询,可以处理较复杂的查询。但由于使用单节点上的Java虚拟机执行查询操作,所以性能可能会受到影响。
- Druid:采用列式存储结构,支持高效的聚合查询。但由于不支持复杂SQL查询,因此不适合处理其他类型的查询。
- Kylin:使用Cube进行预计算和缓存,在查询时可以快速检索缓存中的Cube,处理复杂的OLAP查询非常出色。
- Redis:由于数据全部在内存中处理,支持高效的键值操作,适合处理简单的查询场景。
Hive
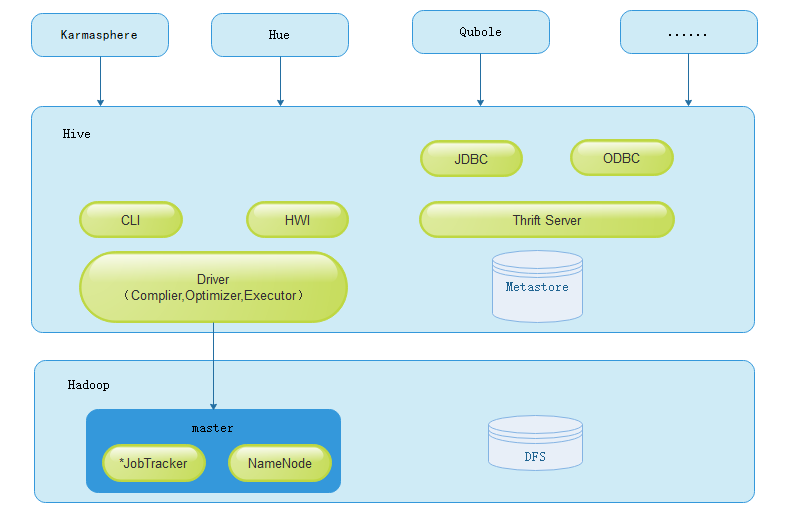
Hive是一个分布式SQL on Hadoop方案,可在底层MapReduce计算模型上执行分布式计算。它擅长处理长时间运行的离线批处理,数据量越大,其优势越明显。因此,Hive在数据量大且数据驱动需求强烈的互联网大厂中很受欢迎。
然而,在过去两年中,随着Clickhouse逐渐流行,某些总数据量不超过百PB级别的互联网数据仓库需求已经有多家公司改用Clickhouse的方案。相比Hadoop/Hive,Clickhouse拥有以下优势:
- 单个查询执行速度更快。
- 不依赖Hadoop。
- 架构和运维更简单。
因此,对于需要查询速度更快、结构更简单的较小规模大数据仓库的公司,Clickhouse可能是更好的选择。
Spark SQL、Flink SQL
在大部分场景下,Hive的计算速度过慢。即使对于企业内部产品、运营、数据分析师的ad-hoc查询,也会经常抱怨Hive执行太慢。更不用说对外在线服务的高QPS、低查询延迟的需求了。这些痛点推动了MPP内存迭代和DAG计算模型的诞生和发展,例如Spark SQL、Flink SQL、Presto等技术,目前在企业中非常流行。
相比Hive,Spark SQL和Flink SQL的执行速度更快,编程API丰富,同时支持流式计算与批处理,并且具有流批统一的趋势,从而使得大数据应用变得更加简单。因此,在需要高性能、低延迟的场景下,Spark SQL和Flink SQL可能是更好的选择。
Presto
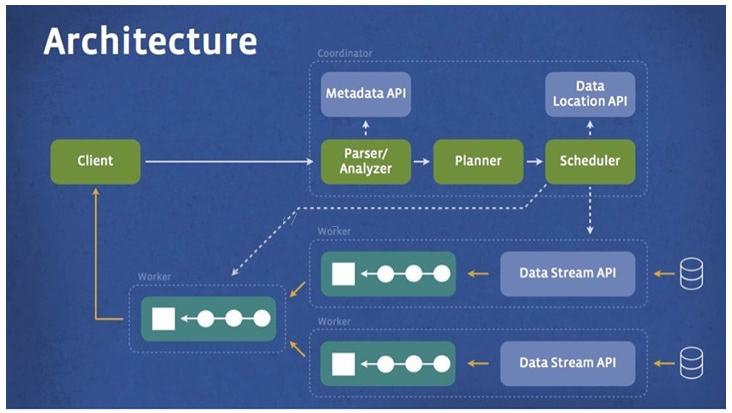
对于MPP架构的数据库,例如Presto、Apache Drill和Apache Impala和Greenplum等,它们都具有以下特点:
- 分布式计算:这些数据库采用分布式计算技术,在多个节点上并行处理数据。每个节点只负责自己的部分数据,并提供局部计算结果。
- SQL支持:这些数据库支持SQL查询语言,可以方便地进行数据查询和分析。同时,它们也支持列式存储和向量化计算等优化技术,以提高查询性能。
- 横向扩展:这些数据库支持横向扩展,可以通过添加更多节点来扩展存储和计算能力。这使得它们能够处理大规模数据集和高并发访问的需求。
- 实时查询:这些数据库支持实时查询和交互式数据分析,可以在毫秒级别内返回查询结果。这使得它们适合处理实时业务场景,如实时日志分析和流式数据处理等领域。
总之,MPP架构的数据库具有分布式计算、SQL支持、横向扩展和实时查询等特点。这些特点使得它们非常适合处理海量数据和高并发访问的应用场景,如实时日志分析、电商推荐、搜索和人工智能等领域。
Elasticsearch、Druid、Kylin和MPP架构的数据库都是目前流行的大数据处理和分析解决方案。它们之间存在以下不同之处:
- 架构模式:Elasticsearch和MPP架构的数据库采用分布式计算和存储模式,将数据分散存储在多个节点上,并利用集群计算能力进行高效地数据处理和分析。而Druid和Kylin则更加关注于OLAP领域,采用列式存储和多维聚合查询等技术来提高查询性能。
- 适用场景:Elasticsearch主要用于全文检索和实时日志分析等领域,MPP架构的数据库则更适用于企业级数据仓库、在线交易处理和实时数据分析等场景。Druid和Kylin则适用于基于多维度数据分析的应用场景。
- 数据处理能力与查询性能:Elasticsearch和MPP架构的数据库支持实时数据处理和交互式查询,可以在毫秒级别内返回查询结果。而Druid和Kylin则具有更好的多维聚合查询性能和数据分析能力。
- 技术门槛和复杂度:Elasticsearch和MPP架构的数据库的部署和维护相对更加复杂,需要一定的技术知识和经验。而Druid和Kylin则趋于易于使用和上手。
除了架构模式、适用场景、数据处理能力和技术门槛等因素,还需要考虑ad-doc和QPS等性能指标。
- ad-doc:在大数据处理和分析领域中,ad-doc(average document count per request)通常表示每个请求所涉及的平均文档数。较低的ad-doc值通常意味着更快的查询响应速度和更高的并发请求处理能力。在这方面,Elasticsearch和MPP架构的数据库都表现出较好的性能,而Druid和Kylin可能存在一些局限。
- QPS:QPS(Query Per Second)代表每秒钟可以处理的查询请求数量,也是衡量系统性能的重要指标之一。较高的QPS值通常意味着更快的查询响应速度和更高的并发请求处理能力。在这方面,MPP架构的数据库通常表现出比其他解决方案更高的性能,而Elasticsearch和Druid等则相对较弱。
- 单机QPS:在单机部署的情况下,Elasticsearch可以处理每秒数千个查询请求,MPP架构的数据库可以处理每秒数万个查询请求,而Druid和Kylin可以处理每秒数百个到数千个查询请求。
- 集群部署:在集群部署的情况下,这些解决方案的QPS能力会有所不同。对于Elasticsearch和MPP架构的数据库,它们支持水平扩展和负载均衡等技术,可以通过添加更多节点来提高整个系统的查询吞吐量和并发请求处理能力。而对于Druid和Kylin等解决方案来说,它们也支持分布式部署,但它们的扩展性相对较弱,需要更多的手动配置和调优工作。
- 处理请求QPS的能力:在处理查询请求时,不同解决方案的QPS能力也存在一定差异。例如,在处理简单的聚合查询时,Druid和Kylin的查询性能通常比Elasticsearch和MPP架构的数据库更好;在处理实时日志分析等场景时,Elasticsearch和MPP架构的数据库则可能表现得更优秀。
关于Elasticsearch、Druid、Kylin和MPP架构的数据库在延迟和数据源特征方面进行总结。
1. 延迟
1.1 Elasticsearch
Elasticsearch是一个开源的搜索和分析引擎,主要用于全文检索和实时日志分析等领域。它支持实时数据处理和交互式查询,可以在毫秒级别内返回查询结果。Elasticsearch的查询响应时间通常在几百毫秒内,对于实时日志分析等场景可达到毫秒级别的查询响应速度。Elasticsearch可以支持海量数据的实时搜索,并且具有良好的水平扩展性和负载均衡能力。同时,Elasticsearch还可以与各种数据源进行整合,例如MySQL、Oracle、MongoDB等。
使用案例:
- 在电商网站中,用户输入搜索关键词后,Elasticsearch可以快速从庞大的商品库中返回与关键词相关的搜索结果,提升了搜索体验。
- 在日志分析场景中,Elasticsearch可以帮助企业快速查找和分析海量的日志数据,发现问题并解决。
1.2 Druid
Druid是一个面向OLAP分析的开源数据存储和查询系统,采用了列式存储和多维聚合查询等技术。在处理简单的聚合查询时,Druid的查询响应时间通常在几十毫秒到几百毫秒之间。Druid主要适用于基于事件的数据源和时间序列数据源,可以在高吞吐量的实时数据流中进行在线数据分析和处理。同时,Druid也支持以批处理方式加载静态数据,如从Hadoop集群中读取日志。
使用案例:
- 在移动游戏行业中,Druid可以用于实时监控用户行为,例如注册、登录、付费等行为,并对其进行实时分析,以提升用户体验和产品质量。
- 在智能家居领域中,Druid可以用于管理设备状态和行为数据,并根据用户的操作历史和生活习惯进行预测和推荐。
1.3 Kylin
Kylin是一个开源的分布式OLAP引擎,可以将大规模数据保存到Hadoop中,并支持多维度聚合查询和快速过滤。在处理复杂的多维聚合查询时,Kylin的查询响应时间通常在几秒钟到几十秒之间。Kylin需要较长的预计算和构建时间,同时也对数据源的要求比较严格。Kylin适用于面向行的数据源,主要作用是实现OLAP分析。
使用案例:
- 在金融业中,Kylin可以用于处理大量的交易数据,并进行多维度分析和报告生成,以帮助管理层做出更优秀的商业决策。
- 在电信业中,Kylin可以用于处理用户通话记录、短信和流量等数据,以监控网络质量和业务运营情况。
1.4 MPP架构的数据库
MPP架构的数据库是一种高性能的分布式数据库系统,具有良好的水平扩展和负载均衡能力。MPP架构的数据库适用于大规模数据仓库和企业级应用。它能够处理各种类型的数据源,包括结构化、半结构化和非结构化数据。同时,MPP架构的数据库也支持与多个数据源进行互操作,如Hadoop、NoSQL、RDBMS等。
使用案例:
- 在金融机构中,MPP架构的数据库可以用于处理交易数据和客户信息,以进行风险管理和业务分析。
- 在零售业中,MPP架构的数据库可以用于处理顾客购买记录和库存信息,以提高供应链效率和客户满意度。
2. 数据源特征
在选择大数据处理和分析解决方案时,还需要考虑数据源的特征。以下是这四种解决方案适用的不同数据源类型:
2.1 Elasticsearch
Elasticsearch适用于文本、日志、指标和其他结构化或半结构化数据。它支持实时索引,可以快速存储、搜索和分析大量文档数据。同时,Elasticsearch也可以与各种数据源进行整合,例如MySQL、Oracle、MongoDB等。
使用案例:
- 在社交媒体平台中,Elasticsearch可以用于管理用户生成的内容数据,例如照片、视频和帖子等。
- 在电商网站中,Elasticsearch可以用于管理商品信息和订单数据,以便更好地理解客户需求。
2.2 Druid
Druid适用于基于事件的数据源和时间序列数据源。它支持多维聚合查询和快速过滤,可以在高吞吐量的实时数据流中进行在线数据分析和处理。同时,Druid也支持以批处理方式加载静态数据,如从Hadoop集群中读取日志。
使用案例:
- 在游戏行业中,Druid可以用于监控玩家活动并实时将其传送到数据仓库中,以供分析和报告。
- 在物联网领域中,Druid可以用于监控设备状态并进行实时分析,并通过阈值警报通知相关人员。
2.3 Kylin
Kylin适用于面向行的数据源,其主要作用是实现OLAP分析。它需要预计算和缓存处理大量的聚合数据,并通过ETL工具将数据从各种数据源(如Hive、HBase、MySQL、PostgreSQL等)加载到Kylin中。
使用案例:
- 在电信行业中,Kylin可以用于处理通话记录、短信和流量等数据,并进行多维度分析和报告生成,以帮助运营商制定更好的业务策略。
- 在医疗保健领域中,Kylin可以用于处理患者数据和药品信息,并进行多维度分析和报告。
2.4 MPP架构的数据库
MPP架构的数据库适用于大规模数据仓库和企业级应用。它能够处理各种类型的数据源,包括结构化、半结构化和非结构化数据。同时,MPP架构的数据库也支持与多个数据源进行互操作,如Hadoop、NoSQL、RDBMS等。
使用案例:
- 在金融机构中,MPP架构的数据库可以用于处理交易数据和客户信息,并进行风险管理和业务分析。
- 在电信业中,MPP架构的数据库可以用于处理通话记录和流量数据,并进行网络监控和维护。
Clickhouse
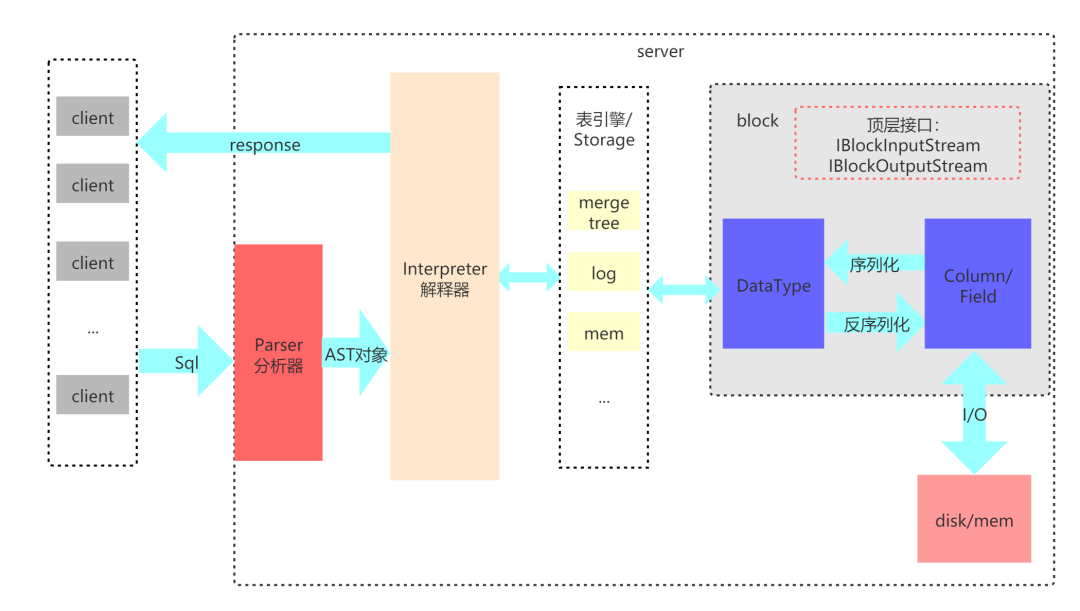
ClickHouse是近年来备受关注的开源列式数据库,主要用于数据分析(OLAP)领域。目前国内社区火热,各个大厂纷纷跟进大规模使用。
ClickHouse从OLAP场景需求出发,定制开发了一套全新的高效列式存储引擎,并且实现了数据有序存储、主键索引、稀疏索引、数据Sharding、数据Partitioning、TTL、主备复制等丰富功能。以上功能共同为ClickHouse极速的分析性能奠定了基础。
ClickHouse部署架构简单,易用,不依赖Hadoop体系(HDFS+YARN)。它比较擅长的地方是对一个大数据量的单表进行聚合查询。Clickhouse用C++实现,底层实现具备向量化执行(Vectorized Execution)、减枝等优化能力,具备强劲的查询性能。目前在互联网企业均有广泛使用,比较适合内部BI报表型应用,可以提供低延迟(ms级别)的响应速度,也就是说单个查询非常快。
但是Clickhouse也有它的局限性,在OLAP技术选型的时候,应该避免把它作为多表关联查询(JOIN)的引擎,也应该避免把它用在期望支撑高并发数据查询的场景,OLAP分析场景中,一般认为QPS达到1000+就算高并发,而不是像电商、抢红包等业务场景中,10W以上才算高并发,毕竟数据分析场景,数据海量,计算复杂,QPS能够达到1000已经非常不容易。例如Clickhouse,如果如数据量是TB级别,聚合计算稍复杂一点,单集群QPS一般达到100已经很困难了,所以它更适合企业内部BI报表应用,而不适合如数十万的广告主报表或者数百万的淘宝店主相关报表应用。Clickhouse的执行模型决定了它会尽全力来执行一个Query,而不是同时执行很多Query。
ElasticSearch
我博客里写了很多有关Elasticsearch的文章,因为它是脱胎于lucene,Lucene众所周知是个搜索引擎框架。依托于Lucene的倒排序索引结构,加之支持文本分词,所以搜索领域可以说是独占鳌头。而且性能也很高,基本上三个节点的集群,支撑个1000+的qps轻轻松松。你以为它的强大就只适用于搜索场景了?其实并不是,它提供着强大的聚合(aggregation)功能,虽然是json结构的,但是与传统的sql是可以互相转化的。
举例:
Elasticsearch Aggregation 语句:
{
"aggs": {
"orders_per_month": {
"date_histogram": {
"field": "order_date",
"interval": "month"
},
"aggs": {
"total_sales": {
"sum": {
"field": "order_total"
}
},
"average_sales": {
"avg": {
"field": "order_total"
}
}
}
}
}
}以上聚合查询语句的含义是,按月份(interval: month)分组计算订单总数(total_sales)和平均销售额(average_sales),并在每个月份中显示。
SQL 查询语句:
使用Impala的SQL查询语言将上述Aggregation语句转换为SQL查询语句,大致如下所示:
SELECT
DATE_TRUNC('month', order_date) AS month,
SUM(order_total) AS total_sales,
AVG(order_total) AS average_sales
FROM
my_table
GROUP BY
month;以上SQL查询语句的含义是,按月份(DATE_TRUNC函数)分组(GROUP BY子句)计算订单总数(SUM函数)和平均销售额(AVG函数),并显示每个月份的结果。
Elasticsearch作为OLAP引擎可以带来以下几项优势
- 高效的数据查询和分析:Elasticsearch的文档存储模型和倒排索引技术,使得它非常适合存储和查询非结构化或半结构化数据。同时,Elasticsearch提供了丰富的聚合功能,可以方便地进行数据分析和统计。这使得Elasticsearch能够在处理大规模和复杂数据集时保持高效性能。
- 水平扩展和高可用性:Elasticsearch是一个分布式系统,支持水平扩展,可以将数据分散在多个节点上存储和处理。同时,Elasticsearch还提供了副本机制,以确保数据的高可用性。这使得Elasticsearch可以轻松应对海量数据和高并发访问的需求。
- 灵活的数据建模和处理:Elasticsearch是一个面向文档的数据库,允许用户自由定义文档结构,并且支持动态添加和删除字段。这使得Elasticsearch能够适应不同的数据建模和处理需求,例如实时日志分析、电商推荐、搜索等多种场景。
Elasticsearch的查询执行引擎基于Scatter-Gather MapReduce模型,下面是它们之间的关系说明:
- Scatter:Elasticsearch使用Shard(分片)作为数据处理的最小单元。在Scatter阶段,查询请求将被分发到多个Shard上执行。每个Shard只负责处理自己的部分数据,并返回一部分结果。
- Gather:在Gather阶段,相同类型的Shard返回的结果会被合并成一个结果集。这些结果可以被再次分发到更多的Shard上进行进一步计算和筛选。
- MapReduce:在MapReduce阶段,对结果集进行过滤、聚合和计算等操作。其中,Map阶段对结果进行转换和扩展,Reduce阶段对结果进行合并和归约。
Elasticsearch可以理解成为最简单的Scatter-Gather MapReduce模型,Elasticsearch能够高效地处理大量的数据查询请求。具体而言,该模型具有以下优点:
- 分布式处理:Scatter-Gather MapReduce模型使用分布式计算技术,在多个节点上分散存储和处理数据。这使得Elasticsearch能够轻松应对大规模数据集和高并发访问的场景。
- 高效率查询:Scatter-Gather MapReduce模型将查询请求分解成多个子任务,在多个节点上并行执行,从而提升了查询效率。
- 灵活的计算模型:Scatter-Gather MapReduce模型采用MapReduce计算模型,支持多种数据处理操作,例如聚合、过滤和归约等。
这样的结构特点,也决定了它适用的业务范围,由于节点上数据交换是基于内存,而不会像MapReduce那次每次shuffle都要先落盘。而Lucene的倒排序的数据结构实际是一种行列混存模式,并且在做查询的时候又能通过FPS和跳表等来加快数据的查询,所以在数据量不大的时候,性能还是很高的。但是如果只是单机部署,那么这种基于提高QPS理念的设计就会导致执行特别慢,这也是部署时候应该注意的。
Elasticsearch作为OLAP引擎存在以下一些劣势:
- 不适合高写入负载:Elasticsearch的主要设计目标是快速查询和分析数据,而非高并发写入。当大量数据需要被频繁更新或者删除时,Elasticsearch的性能可能会受到影响。
- 缺少严格的事务支持:Elasticsearch不支持传统RDBMS中的严格事务,因此在处理事务型操作时可能会出现一些问题。例如,如果同时进行多个更新请求,则可能会产生竞争条件或者冲突。
- 复杂性与技术门槛较高:Elasticsearch具有许多高级功能,需要用户具备一定的技术水平才能充分利用这些功能。此外,Elasticsearch的部署和维护也需要相应的技术知识和经验。
- 单机存储容量受限:Elasticsearch的单机存储容量受限于硬件资源和节点数,当数据集增长到一定规模时,可能需要扩展集群来满足存储需求。
举个例子:将Elasticsearch作为电商网站的商品搜索引擎,实现在线交易处理(Online Transaction Processing)。
在这个例子中,Java应用程序可以使用Elasticsearch进行以下操作:
- 数据写入与更新:当用户浏览商品时,Java应用程序可以将商品信息写入Elasticsearch索引中。当用户购买商品时,Java应用程序可以更新商品的库存和销售额等信息。
- 实时搜索与过滤:当用户进行商品搜索时,Java应用程序可以使用Elasticsearch的全文检索功能,实时查询并返回匹配的商品列表。同时,Java应用程序也可以使用Elasticsearch的聚合查询功能,在搜索结果中添加价格、品牌、规格等筛选条件。
- 性能优化与扩展:Java应用程序可以利用Elasticsearch的分布式架构,将大规模数据集分散存储和计算,从而提高性能和可扩展性。例如,将不同类型的商品存储在不同的索引中,并使用Shard来分摊负载。
具体而言,Java应用程序可以使用Elasticsearch提供的Java API,通过HTTP协议与Elasticsearch集群通信,实现上述操作。这段Java代码会演示如何使用Elasticsearch的Java API向索引中添加文档:
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
IndexRequest request = new IndexRequest("my_index");
request.id("1");
String jsonString = "{" +
"\"name\":\"John\"," +
"\"age\":30," +
"\"city\":\"New York\"" +
"}";
request.source(jsonString, XContentType.JSON);
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
System.out.println(response.getResult());RestHighLevelClient连接到Elasticsearch集群,创建一个名为"my_index"的索引,并将一条包含姓名、年龄和城市信息的文档添加到该索引中。
Impala
Impala:
- 底层实现:Impala使用了一种基于内存的列式存储引擎,它与Hadoop的MapReduce框架不同。在Impala中,数据以列的形式存储在磁盘上,并且可以在查询之前进行压缩和编码。这使得Impala能够快速扫描大量的数据,并且具有非常高的性能和低延迟。
- 支持语言:Impala支持标准SQL语法,包括SELECT、FROM、WHERE、GROUP BY、HAVING和ORDER BY等关键字。此外,Impala还支持UDF(用户自定义函数)和UDAF(用户自定义聚合函数),这些函数可以用C++或Java等语言编写。
- 广度角度:Impala可以直接查询HDFS和Apache HBase中的数据,并且可以与Hadoop生态系统中的其他组件无缝集成,例如Apache Hive、Apache Spark和Apache Kafka等。Impala支持多种文件格式,包括Parquet、Avro、SequenceFile和TextFile等。同时,Impala还支持多种查询类型,例如基本查询、连接查询、分组聚合查询和窗口函数查询等。
另外,再从数据兼容类型的角度,Impala也具有一些优势:
- HBase:HBase是一个开源的分布式NoSQL数据库,它可以在Hadoop集群上运行。Impala支持直接查询HBase中的数据,并将其视为关系型表。
- Hive:Hive是一个基于Hadoop的数据仓库,它提供了类似SQL的查询语言和简单数据摘要功能。Impala可以与Hive集成,以便查询Hive表。
- JDBC/JAR:Impala提供了JDBC和ODBC连接器,使得用户可以使用标准的SQL客户端工具(例如Apache Zeppelin、Tableau等)连接Impala。此外,Impala还提供了一组Java API,使得用户可以将其嵌入到自己的Java应用程序中。
- Parquet/Avro:Parquet和Avro都是Hadoop生态系统中常见的列式存储格式。Impala支持这些格式,并且能够优化查询,以便在读取和写入时获得更好的性能。
总之,Impala是一个可以直接查询HDFS和HBase中的数据,与Hive无缝集成的分布式SQL查询引擎,同时还提供了JDBC和ODBC连接器,支持Parquet和Avro等文件格式。通过这些功能,Impala提供了非常广泛和灵活的数据访问能力,可以与Hadoop生态系统中的其他组件(例如Apache Zeppelin、Tableau等)无缝集成。同时,Impala基于内存的列式存储引擎和优化查询算法,使得它能够快速、高效地处理大规模数据,并且具有极低的延迟。
c++和java中的使用案例
- C++:Impala提供了一组C++ API,可以让开发人员在本地应用程序中轻松地连接、查询和处理Impala数据。例如,下面的代码片段演示如何通过C++ API连接Impala集群,并执行SQL查询:
#include <impala/client.h>
using namespace impala;
int main() {
// 创建Impala客户端连接
boost::shared_ptr<ImpalaClient> client(new ImpalaClient("localhost", 21050));
// 执行SQL查询
TExecResult result;
client->Exec("SELECT * FROM my_table", &result);
// 处理查询结果
if (result.__isset.data) {
for (int i = 0; i < result.data.size(); ++i) {
// 处理每行记录
}
}
}- Java:Impala也提供了一组Java API,可以让开发人员在Java应用程序中使用Impala。例如,下面的代码片段演示如何使用Java API连接Impala集群,并执行SQL查询:
import java.sql.*;
public class ImpalaDemo {
public static void main(String[] args) throws SQLException {
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null;
try {
// 连接Impala
Class.forName("org.apache.hive.jdbc.HiveDriver");
connection = DriverManager.getConnection("jdbc:hive2://localhost:21050/default", "", "");
statement = connection.createStatement();
// 执行SQL查询
String sql = "SELECT * FROM my_table";
resultSet = statement.executeQuery(sql);
// 处理查询结果
while (resultSet.next()) {
// 处理每行记录
}
} finally {
// 关闭连接
resultSet.close();
statement.close();
connection.close();
}
}
}Kylin
要说Kylink就不得不提一个概念,就是MOLAP系统。
MOLAP
MOLAP(多维在线分析处理)是一种基于多维数据存储和查询的数据仓库技术。它将数据按照不同的维度组织,并使用聚合计算以提高查询性能。MOLAP通常具有以下特点:
- 复杂查询:MOLAP可以支持复杂的查询操作,例如多维度分析、数据透视和切片等。
- 高性能:MOLAP使用预先计算聚合值和指标,因此查询性能非常高,并且对于大规模数据集也非常适用。
- 可视化:MOLAP可以通过各种图表和可视化工具来展示查询结果,使得用户可以更加直观地理解数据。
MOLAP Cube
MOLAP Cube是MOLAP中最重要的概念之一,它是多维数据的物理表示,由多个维度和指标构成。MOLAP Cube具有以下特点:
- 多维度:MOLAP Cube可以包含多个维度,例如时间、地理位置、产品线和客户群体等。
- 指标度量:MOLAP Cube中的每个单元格都包含一个或多个指标度量,例如销售额、利润和库存等。
- 预计算:MOLAP Cube使用预计算技术来加速查询操作,可以在查询之前预先计算聚合值和指标。
MOLAP Cube通常包含以下组成部分:
- 维度:指数据的分类方式,例如时间维度、地理位置维度等。
- 度量:指需要被度量的数据,例如销售额、利润等。
- 层次结构:指数据的层级结构,例如时间维度中的年、季度、月等层次结构。
- 聚合规则:指如何进行聚合计算,例如可采用求和、平均数、最大/最小值等方式进行聚合。
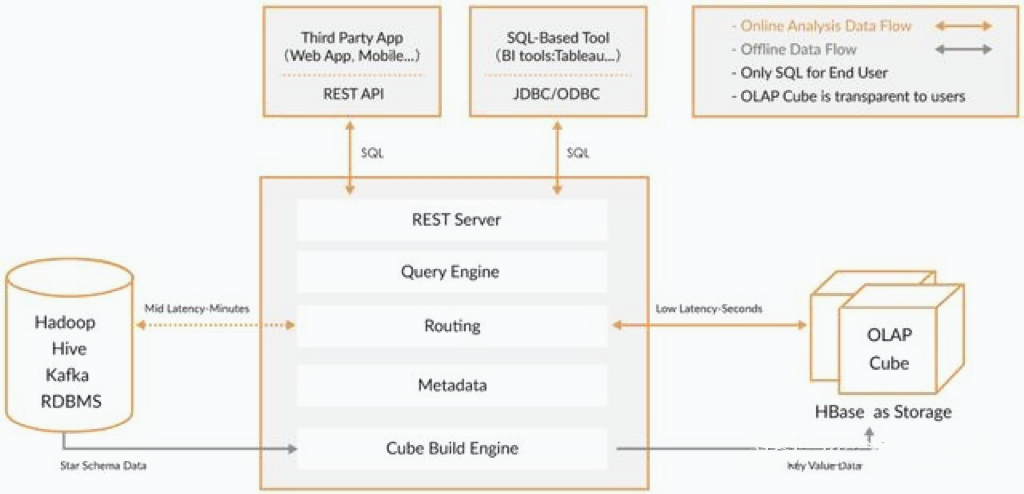
适合Kylin的场景包括:
- 数据体量: 用户数据存在于Hadoop HDFS中,利用Hive将HDFS文件数据以关系数据方式存取,数据量巨大,在500G以上,每天有数G甚至数十G的数据增量导入
- 维度相关: 有10个以内较为固定的分析维度
简单来说,Kylin中数据立方的思想就是以空间换时间,通过定义一系列的纬度,对每个纬度的组合进行预先计算并存储。有N个纬度,就会有2的N次种组合。所以最好控制好纬度的数量,因为存储量会随着纬度的增加爆炸式的增长,产生灾难性后果。
Druid
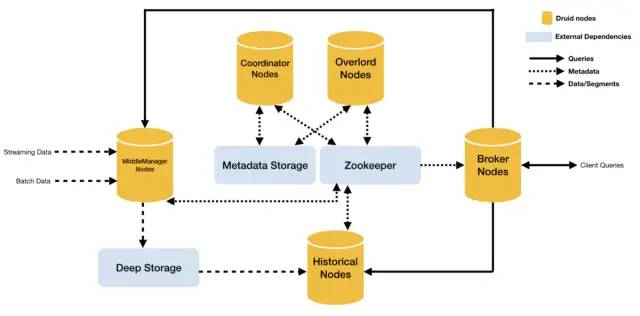
Druid是一款快速、灵活的开源数据存储、查询和分析引擎,支持实时和批处理,并可扩展到PB级别的数据量。
特点
- 实时和批处理:Druid支持实时和批处理,可以将实时事件流和离线历史数据存储在同一个系统中。
- 高性能:Druid是为了高性能而设计的,可以在秒内查询数千万行数据。
- 特别适合时间序列:它可以把数据按照时间序列分批存储,十分适合用于对按时间进行统计分析的场景。
- 可扩展:Druid是可扩展的,可轻松地扩展到PB级别的数据量。
- 灵活:Druid的设计非常灵活,可以根据需要进行自定义配置,也可以与其他工具集成。
- 多维度分析:Druid可用于多维度分析,支持快速切换、分组和过滤多个分析维度。
- 易于使用:Druid提供了易于使用的Web UI和API,使得用户可以方便地进行数据查询和管理。
- 不适合多表连查:天然属性决定,Druid不支持多表连接
- 不太适合粗筛阶段使用:这种情况下,一般都与类似于Spark这类的计算框架结合着来使用 Druid是一个用于快速、实时和批量查询的分布式列存储数据库,可以用于多维度分析、实时监控和数据探索等场景。而Spark是一个用于快速计算的通用集群计算引擎,可以处理大规模的数据处理需求,例如机器学习、图形处理和流式计算等。
- 数据ETL:Druid可以用于实时或离线的数据准备和清洗,而Spark可以用于数据转换和数据预处理。可以使用Druid将原始数据加载到Druid中,然后使用Spark进行数据转换和数据预处理,最后再将数据导入Druid以供查询和分析。
- 数据查询和分析:Druid是一个用于多维度分析和实时监控的列存储数据库,可以快速查询PB级别的数据,并提供直观的Web UI和API。而Spark可以执行复杂的转换和分析操作,例如机器学习和图形处理等。可以使用Druid作为主要的数据查询和分析引擎,而Spark则可以做为补充来执行更复杂的数据处理操作。
- 流式计算:Druid可以用于实时监控和流式计算,例如实时事件流和日志处理。与此同时,Spark具有强大的流式处理功能,并且可以与Kafka等流数据存储集成。因此,Druid和Spark可以一起使用以构建大规模的流式处理应用程序。
- 不太适处理透视维度复杂多变的查询场景:由于Druid的数据模型是面向列的,并且使用了列式存储引擎,因此在透视维度复杂多变的查询场景中可能会受到一些限制,原因如下:
- 数据冗余:Druid的数据模型是面向列的,因此需要将所有数据都冗余成不同的列,以便于查询和聚合操作。对于透视维度复杂多变的查询场景,这种冗余可能会导致数据集过于庞大,造成存储和查询效率等问题。
- 索引管理:Druid使用了一种基于Bitmap的索引方式来加速查询,但是对于透视维度复杂多变的查询场景,可能需要创建大量的Bitmap索引,从而导致系统负担增加,并降低系统的性能。
- 维度推导:Druid的数据模型需要事先定义好所有的维度,而对于透视维度复杂多变的查询场景,这些维度可能会非常多,且难以预先定义。这就需要在查询时进行维度推导,增加了查询复杂度和开销。
- 数据更新:Druid的列存储引擎适用于静态数据和快速查询等场景,但是对于频繁更新和变化的数据集,可能需要重新加载整个数据集,从而导致查询的延迟和性能下降。
- 擅长查询的类型单一:一些常见的sql(group by等)在druid中运行速度一般
- 插入更新速度慢:Druid支持低延时的数据插入、更新,但是比hbase、传统数据库要慢很多
- 命中后的性能问题:这是查询规律,当然druid更不能免俗,Druid在查询条件命中大量数据情况下可能会有性能问题,而且排序、聚合等能力普遍不太好,灵活性和扩展性不够,比如缺乏Join、子查询等
使用情况
Druid广泛用于以下领域:
- 实时监控:Druid可以用于实时监控和分析系统和应用程序的性能指标、日志和事件流数据。
- 广告技术:Druid可用于广告技术,包括广告投放和分析、营销自动化和实时竞价等。
- 物联网:Druid可以用于处理物联网设备的传感器数据,例如温度、湿度和气压等。
- 游戏:Druid可用于实时监控游戏性能指标、用户行为和支付数据等。
- 电子商务:Druid可以用于电子商务领域,例如实时推荐、购物车分析和订单跟踪等。
实时监控可以说是Druid的拿手好戏了,所以在Spring开发中,你会发现有很多公司把它直接集成到一些业务内做埋点,完成对数据的监控,如果想在Spring中使用Druid来做监控,该怎么做呢?
Java Spring Framework集成Druid进行数据访问层(DAO)监控的示例代码:
- 在pom.xml中添加druid-spring-boot-starter和mysql-connector-java依赖
<dependencies>
<!-- druid spring boot starter -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>${druid.version}</version>
</dependency>
<!-- mysql connector java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
</dependencies>- 在application.properties文件中配置Druid数据源
spring.datasource.url=jdbc:mysql://localhost:3306/test
spring.datasource.username=root
spring.datasource.password=root
# Druid configuration
spring.datasource.druid.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.druid.initial-size=5
spring.datasource.druid.min-idle=5
spring.datasource.druid.max-active=20
spring.datasource.druid.max-wait=60000
spring.datasource.druid.time-between-eviction-runs-millis=60000
spring.datasource.druid.min-evictable-idle-time-millis=300000
spring.datasource.druid.validation-query=SELECT 1 FROM DUAL
spring.datasource.druid.test-while-idle=true
spring.datasource.druid.test-on-borrow=false
spring.datasource.druid.test-on-return=false
spring.datasource.druid.filters=stat,wall
spring.datasource.druid.connection-properties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000- 创建User实体类
public class User {
private Long id;
private String username;
private String password;
// getters and setters
}- 创建UserMapper接口和实现类
@Mapper
public interface UserMapper {
@Select("SELECT id, username, password FROM user WHERE id=#{id}")
User selectById(Long id);
}
@Repository
public class UserMapperImpl implements UserMapper {
@Autowired
private JdbcTemplate jdbcTemplate;
public User selectById(Long id) {
return jdbcTemplate.queryForObject("SELECT id, username, password FROM user WHERE id=?", new Object[]{id}, new BeanPropertyRowMapper<>(User.class));
}
}- 在Controller中调用UserMapper的selectById方法并返回结果
@RestController
public class UserController {
@Autowired
private UserMapper userMapper;
@GetMapping("/users/{id}")
public User getUserById(@PathVariable Long id) {
return userMapper.selectById(id);
}
}通过以上步骤,就可以在Java Spring Framework中集成Druid进行数据访问层(DAO)监控了。