《移动性能实战》 笔记
原创
写入放大效应解释
随机读写的定义是什么
就是随机产生偏移量然后写入,区别于顺序读写需要考虑当前写到哪儿了然后再末尾进行写入。一句话就是随机产生偏移量进行写入
内存相关知识介绍
1.内存页是内存空间的最小申请单位,闪存中的内存块是一个个内存页拼接起来的。
2.已擦除就是这个内存页上是空白的,反过来没有擦除的就是已经用了的内存页。
3.内存块里面的已擦除的内存页就是指该内存页没有使用没有内容,没有擦除的内存页分为两种状态:一种是存储着有效数据的内存页 另一种是失效的内存页(没用了但是还占着空间之后会清除的和gc一样,这个无效的内存页之后会在写入内存块的时候内存块不足进行清理,后面讲)
失效的内存页指的是什么?指的是新数据覆盖了旧数据,旧数据不需要了,因此保存旧数据的内存页就叫做失效的内存页
4.什么时候进行失效内存页的清除呢?当需要在这个内存块中写入数据时但是又发现现在的内存块空间不够,里面又正好有个失效的内存页(如果都是有用的就不做处理将新写入的数据放到新的内存快中)
那么就会对这个内存块整理(保证所有的页都是有效或者空闲的)先复制有用的内存页放到新的内存块中,再把原来的内存块删除掉(可以看到明显多了两步操作,正常情况直接写就行但是会出现大量的失效内存页所以当这种情况发生时就会进行整理)
写入流程梳理
第一次写入时因为所有内存页都没有写入(也叫擦除状态),所以可以直接写入内存块中空闲的内存页中。
第二次及后续修改时,会将修改内容写入到新的空闲内存页,同时将地址指向新的内存页,然后将旧地址的内存页标记为无效。
当新加的内容在内存块中已经放不下时,会进行一次整理:把当前内存块中有用的内存页放到新的内存块中同时把新加的内容也放进去,然后把之前的内存块删除掉
写入放大的原理
这是正常的,因为写入就是不断的往内存块中堆数据,这里面就有很多无用的内存页(即对一个变量的反复修改会导致大量的无用内存页因为只是再堆新的内存页前面的数据内存页都是无用的),因此当这个内存块中堆不下新的内存页时就需要一次cy整理了。
写入放大效应发生的步骤
从闪存中读取整个内存块(内存块的整个读取512kb),将其中有效内存页提取并追加新写的内容内存页(新内存页的缓存写入),接着删除原来的内存块(删除512kb原来的旧的内存块里面有无用页做一次大整理),再然后吧提取出来的内存页和新加的内存页写入到新的内存块中
可以看到读取512kb是为了提取有效页,删除512kb是进行一了次整理不需要了,写入512kb是为了将提取出来的和新家的内存页放到新的内存块中。
区分进城和场景收集详细的io信息
整体目标
因为将fork函数添加到了unix的环境变量中因此调用fork函数时会执行我们的逻辑,因此当app执行io操作时通过脚本进行捕获对应的操作并加载我们jar中的类进行统计i9信息并通过binde启动我们自己的远程服务去做信息统计
大致方向
通过hook fork函数+hook IO的函数进行数据上报
具体步骤
- 第一步 首先在unix系统中有一个preload 环境变量,该环境变量下的动态链接库会优先加载,影响的是运行时 通过动态链接库调用的函数(比如将我们动态库中的fork函数放入环境变量中,这样当调用fork时就会调用我们的方法) 目的:当系统启动时就会先加载这个链接库里面的函数,由于我们加入了fork函数,因此之后调用fork函数的时候可以走到我们的fork逻辑中。
- 第二部就是添加新的jar包到java的classpath环境变量中,这样所有的应用程序都不需要像以前那样通过dexclassloader去加载程序外部的类,而是直接可以用(相当于添加到了最上层的classloader中的class路径中) 目的:不需要使用dexclassloader加载去使用系统和app中不存在的类Hook Native函数的做法修改GOT表原理引用外部函数的时候 ,在编译时会在GOT表中添加一个代理。当真正需要这个函数的时候,got表会链接真实的地址调用(GOT表内存放的是外部函数的地址)
Hook点
因此我们只要将got表中存放的链接地址替换为我们的函数地址即可
缺点
只能hook外部函数,对于内部函数来说需要下面那种方式才可以:inlineHook
inlinehook
原理
对于so的内部函数来说调用函数就相当于在符号表中找到对应函数的地址,然后跳转到对应的函数执行。
Hook点
可以hook so的内部函数(通过找到符号表替换函数的前两行指令为跳转到自己的函数中执行然后再挑战到原函数执行)
缺点
不能hook静态函数因为 静态函数没有符号表(也就不能找到函数的指令去替换前两个指令为跳转到我们的函数执行)
数据库IO 相关
数据库的连接缓存
数据库打开比较耗时应该放在子线程做,并且每次打开都比较耗时所以应该看情况不应该频繁打开数据库(频繁的打开关闭会造成更严重的耗时)。源码中打开数据库后会保持链接的缓存除非调用close,所以close应该看情况决定是否使用完就调用还是需要等待最后一次读取数据库在调用close关闭链接
数据库的AUTO INCREMENT带来的消耗
sql的默认行号规则
SQLite表的每行都有一个行号,行号用64位带有符号的整型数据表示。SQLite支持使用默认的列名ROWID、ROWID和OID来访问行号。
如果表里某一列指定为INTEGER PRIMARY KEY类型,那么这一列和ROWID是等价的。也就是说,如果你指定某一列为主键,访问该列其实就是访问行号。
添加新数据也就是新行时,行号复用算法会寻找库中没有使用的或者已经删除的行进行复用
如果使用的行数超出了指定的最大行数限制或者即使已经复用了已经删除的行但是也无法存放新内容时 就会报出 sql_full行号满了的错误
AUTO INCREMENT定义
这个关键词只会出现在主键后面,用来强制让行号进行递增(不复用已经删除的行号),因此AUTO INCREMENT的作用是保证主键是严格单调递增的.
AUTO INCREMENT实现原理
内部会创建一个新的数据库去维护该表使用的最大行号,因此对于增删改都需要额外去更新这个表里的内容造成多余的IO
想来也合理:因为要保证使用的行号是严格递增的,因此需要有个地方保存当前使用的行号是多少,每次都在这个上面进行+1
对于普通操作来说 删除的行号会进行复用而不是新建一行去存储但是对于这种强制的 删除了或者哪怕添加失败也不会复用那一行,而是不断追加新的行.
因此在主键加上AUTOINCREMENT后,可以保证主键是严格递增的,但是并不能保证每次都加1,因为在插入失败后,失败的行号不会被复用,这就造成主键会有间隔
AUTO INCREMENT数据对比
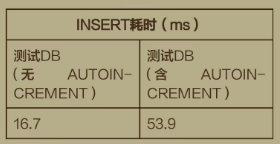
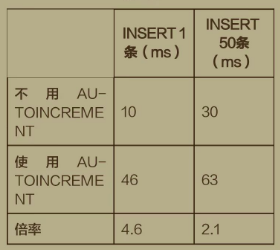
AUTO INCREMENT总结
AUTOINCREMENT可以保证主键的严格递增,但使用AUTOINCREMENT会增加INSERT耗时1倍以上,所以使用AUTOINCREMENT时不可以任性,用在该用的地方效果才佳。比如,客户端需要拿该主键和服务器校对数据,需要保证主键唯一性。
最后以SQLite官网的一句话作为结尾:
这个AUTOINCR
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。