呕心沥血,独到的见解:JUC集合类,独到的见解。
原创呕心沥血,独到的见解:JUC集合类,独到的见解。
原创
注意:普通集合类,太过于基础,这里仅仅是简单回顾,还需要大家有相应基础哈
另外:配合我并发编程专栏中的线程池学习并发队列效果更佳。
并发容器概览
concurrentHashMap:线程安全的HashMap
CopyOnWriteArrayList:线程安全的List
BlockingQueue:
这是一个接口,表示阻塞队列,适用于数据共享的通道
ConcurrentLinkedQueue:
高效的非阻塞并发队列,使用链表实现,可以看作线程安全的LinkedList
//下面的不是很常用
ConcurrentSkipListMap:是一个Map,使用跳表的数据结构进行快速查找,用的并不是很多
重要的是前三个。
集合类的老家伙们
Vector和HashTable
就是直接加上synchronized,并发能力差,性能不好
后来、
HashMap和ArrayList,想变得 线程安全,利用Collecitons.synchronizedList()和Collections.synchronizedMap变的线程安全
然而,这也是包装了一层synchronized,比上面的玩意儿,高明不了哪里去
就有了下面两个高级的家伙
concurrentHashMap和CopyOnwriteArrayList
ConcurrentHashMap!!!
学习基础之:重温Map
Map是一个接口,四个实现:hashMap、HashTable、LinkedHashMap、TreeMap
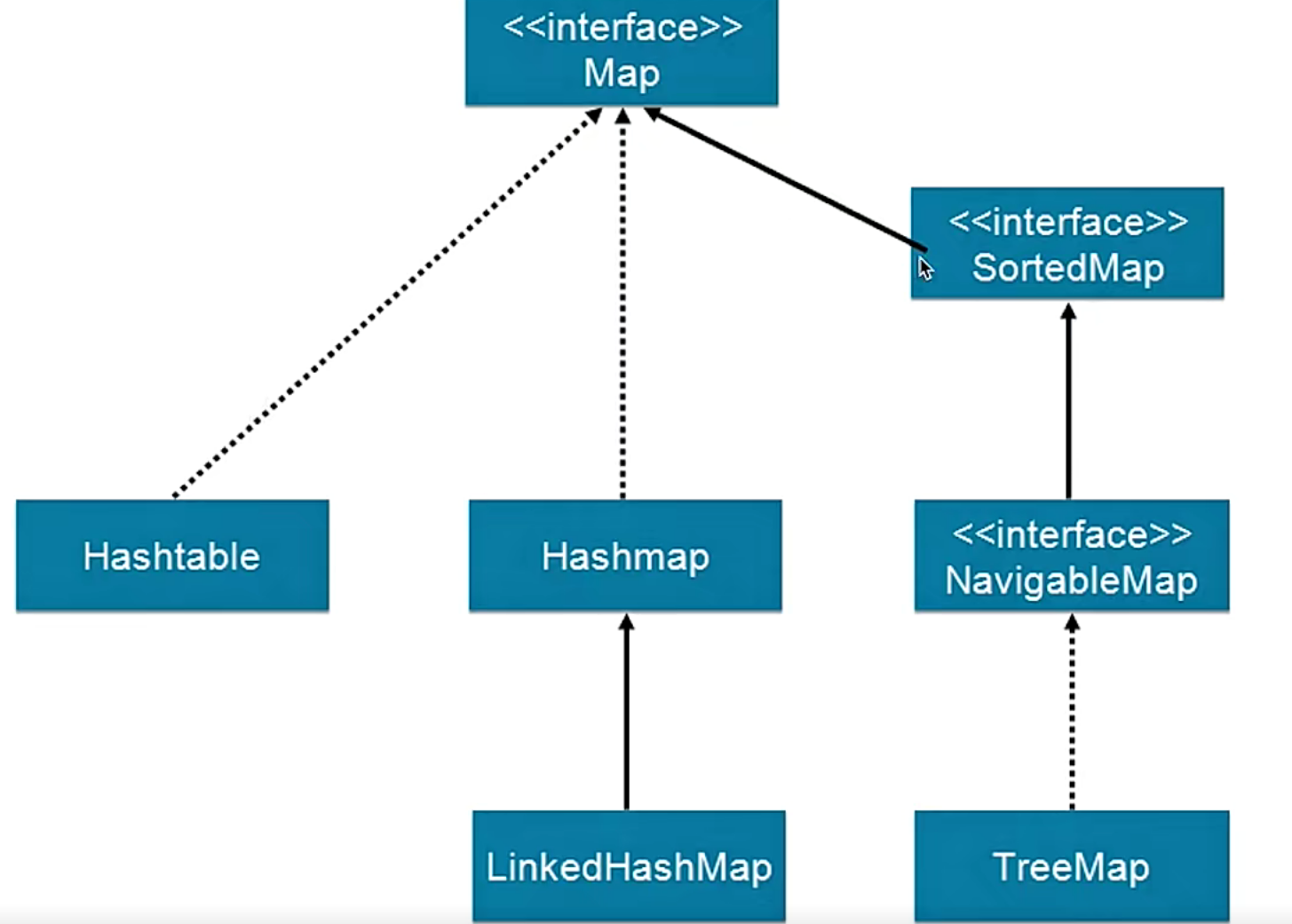
hashMap简介:key不可以为null,value不做限制。线程不安全,
HashTable:线程安全的map,基本被淘汰,只能允许一个线程访问
LinkedHashMap:hashMap子类,保存插入顺序,遍历的顺序和插入的顺序一致
TreeMap:可以排序的map
为什么需要concurrentHashMap,分析HashMap
因为Collecitons.synchronizedMap是给操作加上锁,并发效率低
为什么HashMap线程不安全?
这里抛出3个问题:
1.同时put碰撞导致数据丢失
如果两个key计算的hash值相等,多个线程同时put,就会一个被覆盖丢失
- 同时put扩容导致数据丢失
如果多个线程同时put,同时需要扩容,那么只会有一个保留下来。某个线程数据丢失
- 死循环造成的CPU100%
这个主要发生在jdk7 put方法采用头插法,就会有这个问题
由于没有下载jdk1.7,不运行 演示这个死循环了
原因是:并发扩容的时候,会出现循环扩容的问题
关于hashmap并发的特点,有下面几点:
1非线程安全
2迭代时不允许修改内容
3只读的并发是安全的
4要使用并发场景的话,可以用Collections.synchronizedMap方法修饰
jdk1.7的concurrentHashMap
concurrentHashMap在entry桶的基础上,分为不同的segement
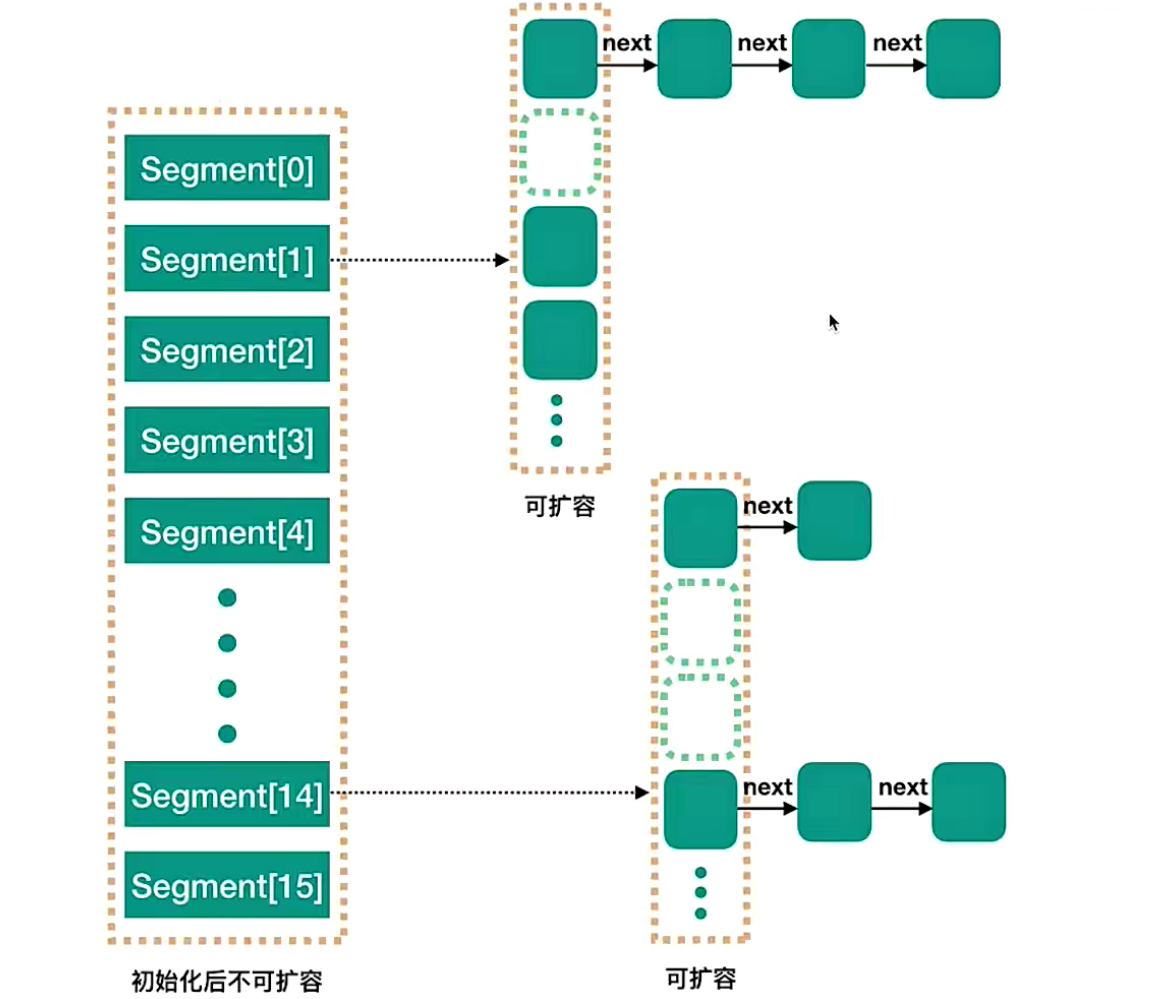
可以理解为:每个segment是hashmap的数组+链表
每个segment独立上ReentrantLock锁(segment继承ReentrantLock),每个segment之间互不影响,提高了并发效率
默认有16个segment,也就是说,最多支持16个线程并发写的能力,
这个16的默认值,可以在初始化concurrnetHash的时候修改
这是1.7的,接下来看1.8
jdk1.8的concurrentHashMap
不再采用segment,而是变为Node。由reentrantLock锁变为了CAS+synchronized
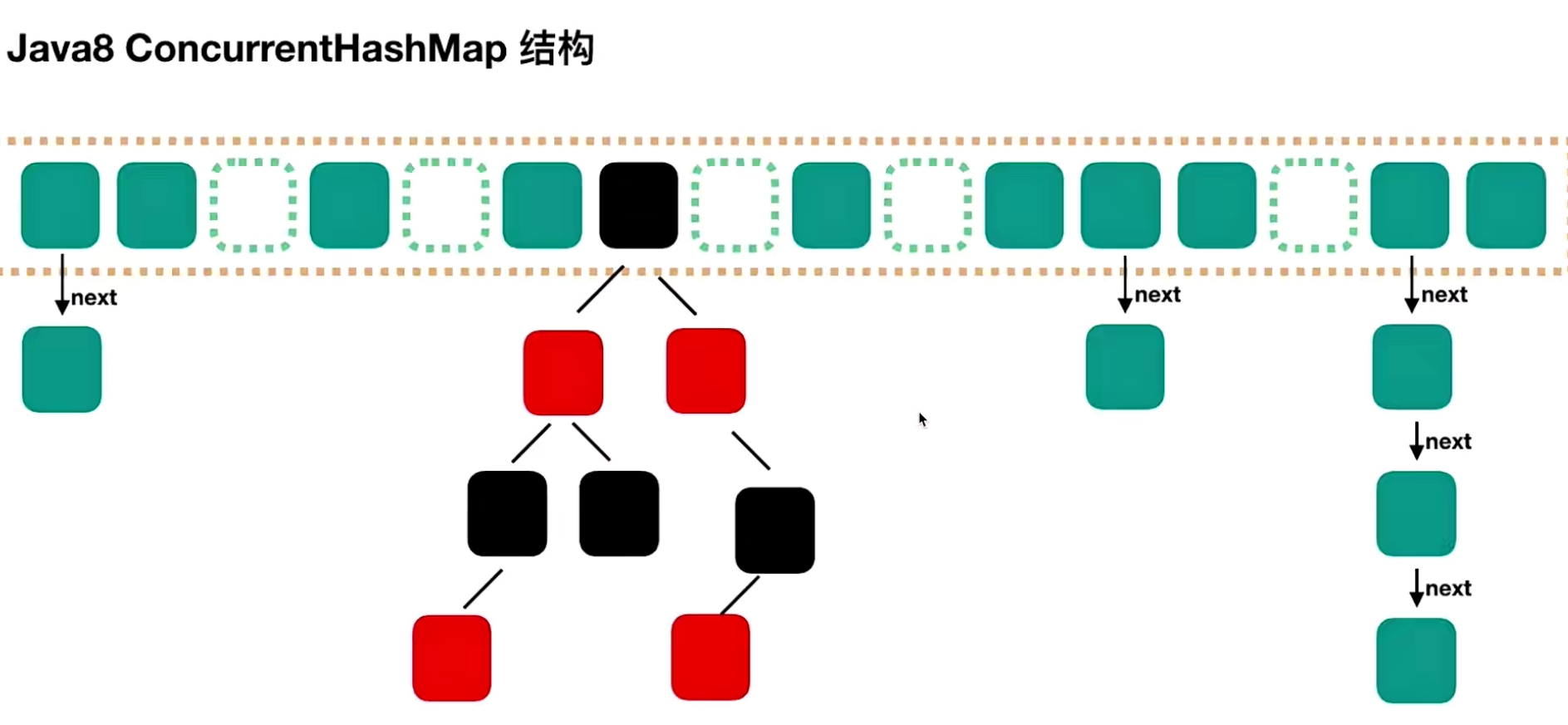
可以看到,和hashmap的结构是非常相似的
好,那么发生了这么大的改变,如何通过node,cas+synchronized实现并发安全的?
我们看一下put和get方法
put核心流程
先判断不为空,key和v都不为空,hashMap则是key可以为空
1key进行重hash,spread
2对当前table无条件循环
3没有初始化table,则初始化
4没有hash冲突,则用cas插入新节点,成功后判断是否需要扩容再结束
5如果是MOVED的状态,则先扩容
6存在hash冲突,通过synchronized加锁,进行链表或者红黑树安全的插入
7插入链表会有红黑树的转换,大于8的时候
8最后再检查是否需要扩容final V putVal(K key, V value, boolean onlyIfAbsent) {
//这里于hashmap不一样,不允许null值
if (key == null || value == null) throw new NullPointerException();
//算出自己的hash值,spread是重hash,减少碰撞
int hash = spread(key.hashCode());
int binCount = 0;
//用for做死循环,这里就是配合cas使用的,cas,和预期值不符合的话,就再一次进入逻辑,直到cas成功
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
//为空则初始化,健壮性就看一眼就先过哈,往后看
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//tabAt,获取table中索引为i的元素,
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//casTabAt(i)利用cas实现无锁插入,实际上属于乐观锁
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
//MOVED为-1的时候,进行扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
//最后一个else,既不为null,也不需要扩容,剩下的就是算出来的位置冲突了
else {
V oldVal = null;
//这时候就需要加synchronized锁来保证并发安全,锁住红黑树或者是链表
synchronized (f) {
if (tabAt(tab, i) == f) {
//链表结构
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
//不是链表结构,则在红黑树里插入
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//扩容
addCount(1L, binCount);
return null;
} 总结一下,让我讲的话,我会先讲一下key部位空,和hashMap有差异,
再讲重hash降低碰撞概率
再是真正的put逻辑,分有冲突和没冲突,没冲突的时候直接进行cas插入,这里配合外层的for无条件循环实现,插入成功之后到addCount扩容
然后就是碰撞的情况,这里需要再链表和红黑树插入,采用synchronized而不是cas了,然后再说一下链表升级到红黑树的过程。
延申
为什么concurrent的key不允许为null?
二义性,存放null的时候,不能确定是存了一个null,还是没存东西,
hashMap的设计是在单线程下的,可以用contains(key)来判断是否是存了一个null
但是concurrentHashMap不行,他是并发使用的,
没办法通过contains判断是否检查准确性,可能因为并发修改导致不可靠。
1.7到1.8,concurrentHashMap。做了什么变化
首先是分段锁的粒度,摒弃了segement数据结构,不再用16个segment做分段锁,从16个并发,到每个node上
并发安全,采用cas+synchronized的方式代替reentrantLock
然后就是红黑树的引入,查询时间复杂度也发生了变化
concurrentHashMap为什么用synchronized而不再用ReetrantLock
jdk1.8中,只有头节点需要进行同步,和AQS有一定的关系
这里别急,我看不懂,等我学完AQS会完善这里哈
内部优化
synchronized则是jvm直接支持的,jvm能够在运行时做出优化措施,自旋自适应、锁消除、锁粗化等待
另外性能方面,synchronized是jvm直接支持,而reenrantLock是独立的类。
为什么:concurrentHashMap不是线程安全的?
这其实是一个误区。本身是线程安全的,只不过是我们错误的使用,因为组合操作
/**
* @Author:Joseph
* 演示:组合操作不能保证线程安全
*/
public class OptionNotSafe implements Runnable{
private static ConcurrentHashMap<String,Integer> scores = new ConcurrentHashMap<>();
public static void main(String[] args) throws InterruptedException {
scores.put("小明",0);
Thread thread1 = new Thread(new OptionNotSafe());
Thread thread2 = new Thread(new OptionNotSafe());
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println(scores);
}
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
Integer socre = scores.get("小明");
int newScore = socre + 1;
scores.put("小明",newScore);
}
}
}这里先get获取旧的值,再加一,再put,组合操作,不是原子性的,concurrentHashMap只保证put和get的原子性,所以,不被这个锅,但是concurrent考虑到了这个场景,用了CAS的一个命令,我们可以通过这个加上while循环完成乐观锁来保障线程安全的get和put,如下:
也可以加synchornized保证,但是这样的话,concurrentHashMap就没有意义了,不如用hashmap呢
看人家给的repalce咋用
for (int i = 0; i < 10; i++) {
while (true){
Integer socre = scores.get("小明");
int newScore = socre + 1;
boolean b = scores.replace("小明", socre, newScore);
while (b){
break;
}
}
}concurrent还保证了原子性的putIfAbsent操作

这个和redis实现分布式锁的时候,java能能保证原子性的很相似
加餐:生产场景的concurrentHashMap并发事故
司机出车之前需要考试过了才行
题目做乱序,用hashMap做乱序,线程不安全,多个线程处理的时候,就出现线程不安全的问题,司机收到的题目是重复的,后面用concurrentHashMap就解决了这个问题。
CopyOnwriteArrayList
1诞生原因
jdk5引入,代替Vector,SynchronizedList
就跟concurrentHashMap代替SynchronizedMap一样
list家族中的并发类
Vector和Synchronized锁的粒度太大,并发效率低,并且迭代时无法编辑
COW容器还包括CopyOnWriteArraySet,代替同步set
2适用场景
读操作尽可能快,而写操作慢一些也可以的场景,不仅保证读多写少,还要保证读快
比如:黑名单,读很多,却很少修改
3读写规则
和读写锁一样,读读共享,其他都是互斥,
读操作可以同时进行,
但是:copyOnWrite,在写入的时候,也可以读取,大幅提高读的能力,
为什么呢?这么厉害,先看看代码的例子,演示一下
注意:arrayList不能迭代的时候修改,报并发修改异常 ,属于fail-fast机制,这个基础的八股就不多讲了哈,这里主要看copyOnwriteList可以并发的修改
这是arrayList报异常的例子
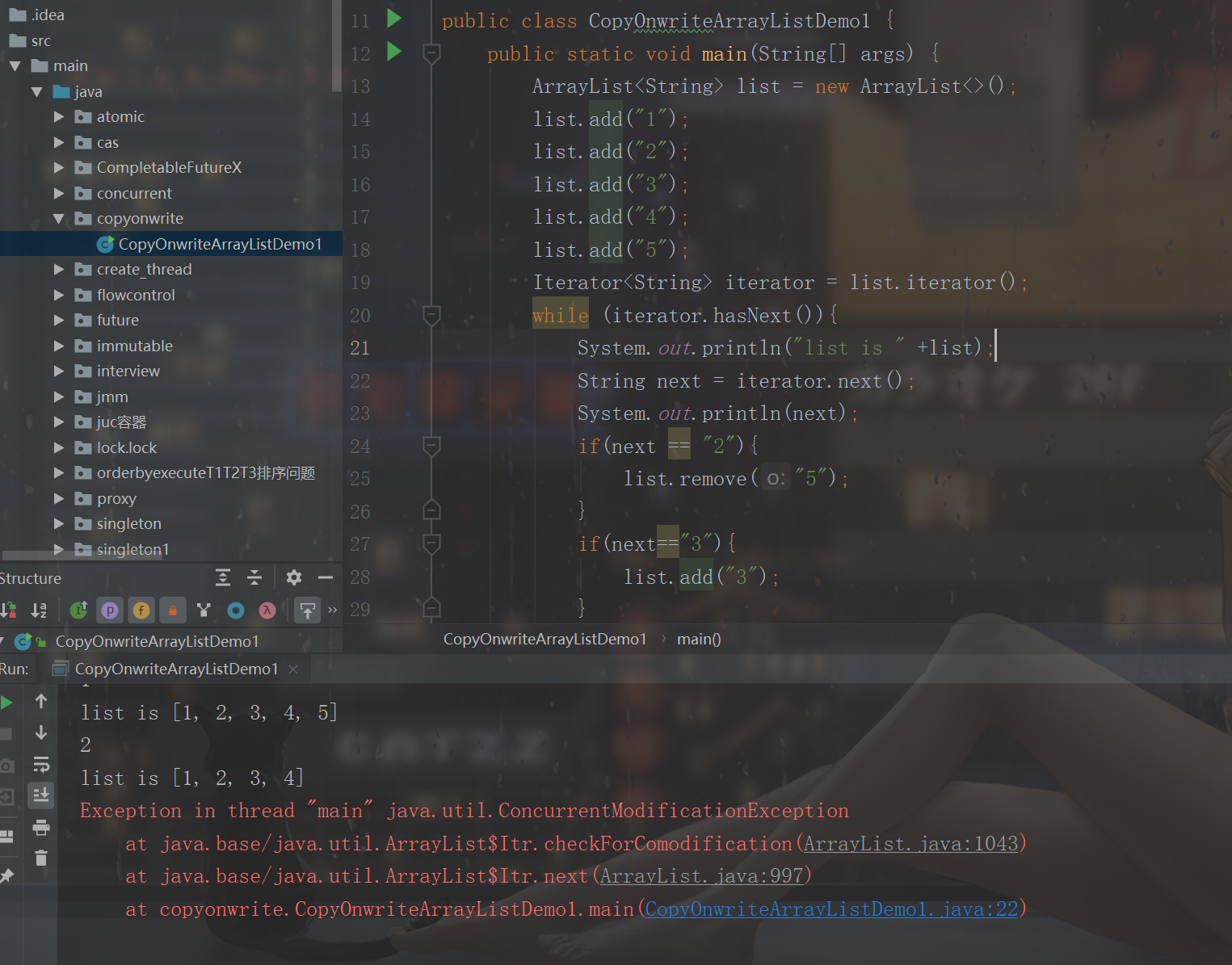
/**
* @Author:Joseph
* 演示迭代的时候copyOnWriteArrayList可以在迭代的时候修改数据
* 而ArrayList不行
*/
public class CopyOnwriteArrayListDemo1 {
public static void main(String[] args) {
CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();
list.add("1");
list.add("2");
list.add("3");
list.add("4");
list.add("5");
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()){
System.out.println("list is " +list);
String next = iterator.next();
System.out.println(next);
if(next == "2"){
list.remove("5");
}
if(next=="3"){
list.add("3 found");
}
}
}
}
//结果
list is [1, 2, 3, 4, 5]
1
list is [1, 2, 3, 4, 5]
2
list is [1, 2, 3, 4]
3
list is [1, 2, 3, 4, 3 found]
4
list is [1, 2, 3, 4, 3 found]
5可以发现迭代的时候,是修改之前的,而没有打印3found,读写分离!你管你的修改,我管我的迭代!
4实现原理
什么叫copyOnWrite
写的时候,copy一份出来,进行修改,删除,做好了之后,指针指向这个新的,读的时候还是读的旧的数据
采用的是读写分离、最终一致的思想
不可变原理:
对于旧的容器,是不会变的,可以并发读
迭代的时候,使用的旧的容器 ,会有读到旧数据的问题
public class CopyOnwriteArrayListDemo2 {
public static void main(String[] args) {
CopyOnWriteArrayList<Integer> list = new CopyOnWriteArrayList<>(new Integer[]{1, 2, 3});
System.out.println(list);
Iterator<Integer> itr1 = list.iterator();
list.add(4);
System.out.println(list);
Iterator<Integer> itr2 = list.iterator();
itr1.forEachRemaining(System.out::print);
System.out.println();
itr2.forEachRemaining(System.out::print);
}
}
//结果
[1, 2, 3]
[1, 2, 3, 4]
123
1234可以看到,这里有数据过期的问题,itr1生成之后add的4,迭代时候是看不到的
5缺点
数据一致性问题:
最终一致性,修改的时候读的是旧的数据
内存占用问题,cow,写时复制,内存中驻扎两个对象的内存。
所有copyOnwrite都会有这两个问题
6源码分析
这里我分析的是jdk11的copyOnwriteList,凡事都要向前看嘛,偶然发现的,jdk8用的锁是renntrantLock而jdk11采用的是Object做的锁,
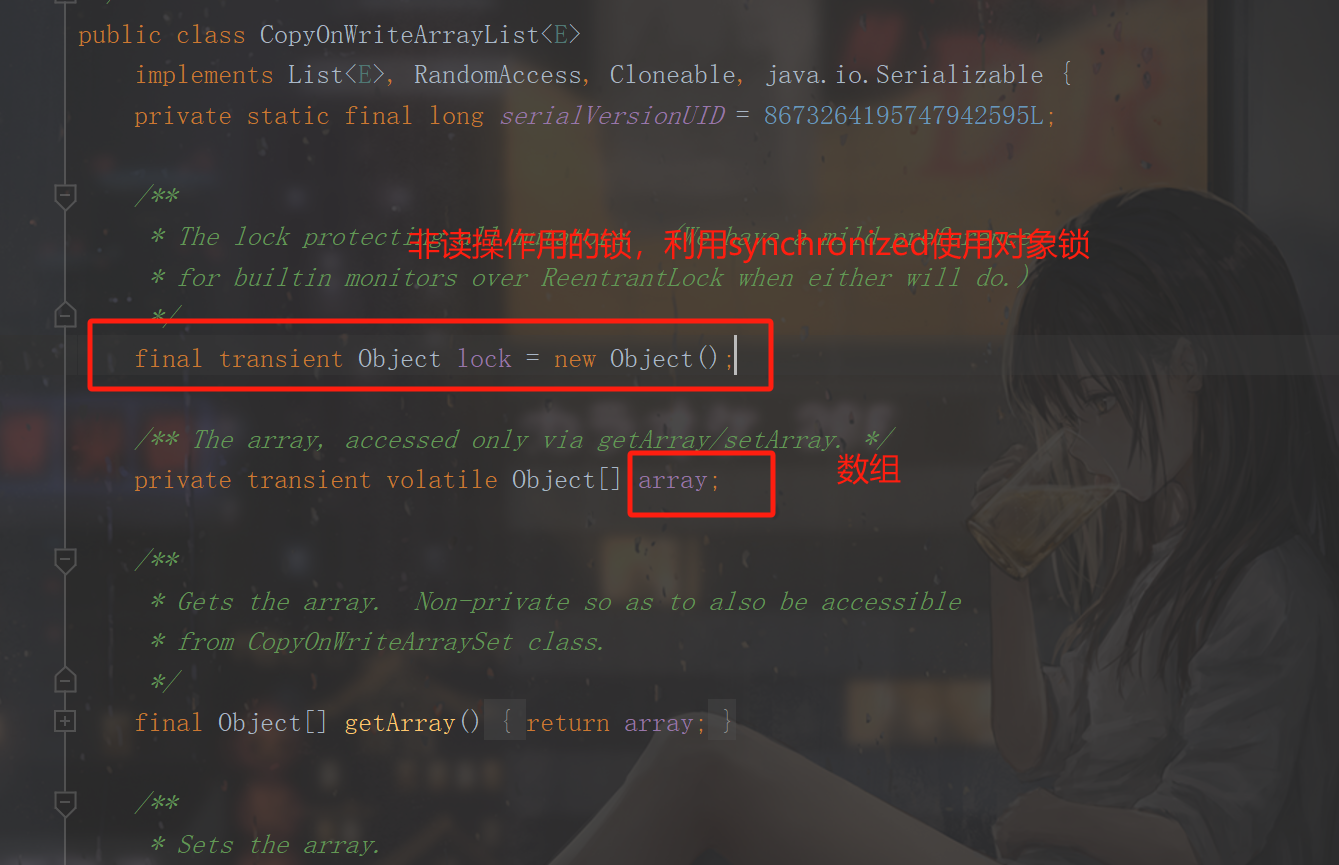
public void sort(Comparator<? super E> c) {
synchronized (lock) {
sortRange(c, 0, getArray().length);
}
}可以看到这个cowarrayList的一个方法,采用的是用synchronized对象锁
copyArrayList为什么使用synchronized代替renntrantLock呢?
我个人认为是和concurrentHashMap相似
从这3方面来说:1性能开销小,2jvm内部锁优化,3cow读写分离的特性不会阻塞读操作。
jvm内部优化
synchronized则是jvm直接支持的,jvm能够在运行时做出优化措施,自旋自适应、锁消除、锁粗化等
synchronized 关键字是 Java 中最基本的线程同步机制,相比于 ReentrantLock,synchronized 的性能开销更低,因为它是由 JVM 内部的同步机制实现的。
另外,copyOnwriteArrayList读写分离,读的时候不会因为Synchronized阻塞读线程的读操作
这只是我偶然的发现,正确性有待考证。谢谢
再看下add方法
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
//对象锁,保证并发安全
synchronized (lock) {
//拷贝旧的数组
Object[] es = getArray();
int len = es.length;
//扩容长度
es = Arrays.copyOf(es, len + 1);
//赋值
es[len] = e;
//set新的引用
setArray(es);
return true;
}
}get方法
public E get(int index) {
return elementAt(getArray(), index);
}可以看出get方法没有加任何锁
并发对列Queue(阻塞队列、非阻塞队列)
并发队列不只是阻塞队列,还有非阻塞队列
为什么使用队列
用队列在线程间传递数据:生产消费模式、银行转账
考虑线程安全的问题,从你转移到了队列上
并发队列简介
Queue
保存一组等待的数据,比如ConcurrentLinkedQueue,先进先出
还有prioirtyQueue优先级队列,不支持并发,但是能根据内容进行排序
底层是链表实现的,为撒不用链表儿用队列呢???
那就是队列先进先出的特性,要满足,不会先链表一样可以取到中间的数据
BlokingQueue
在queue的基础上增加了阻塞的特性,队列满的时候,放数据的时候会阻塞,队列空的时候,取数据的时候会阻塞。
并发队列关系图
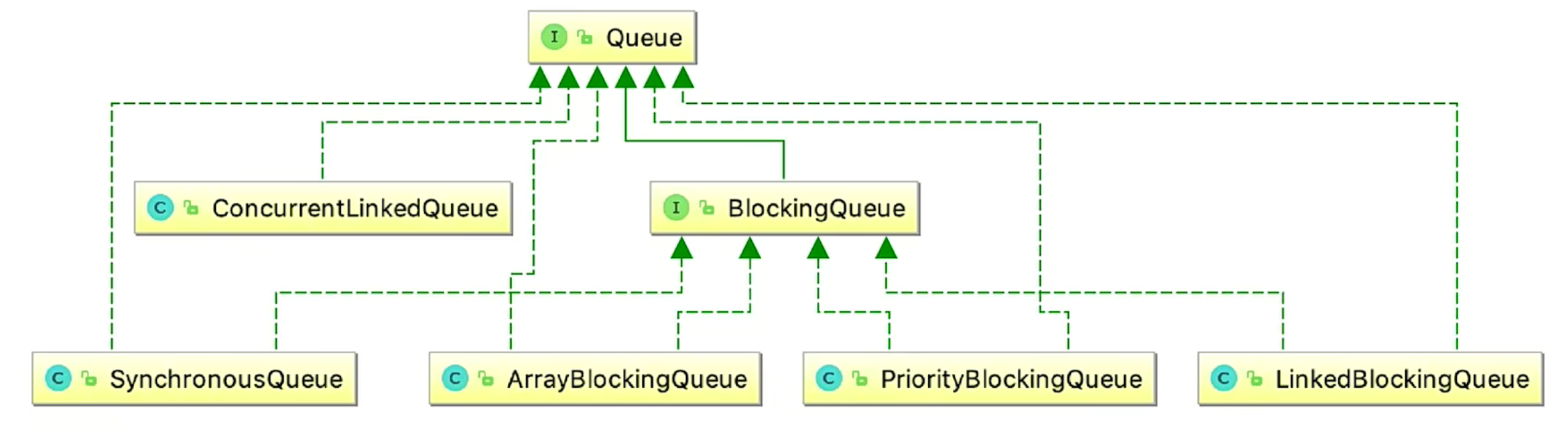
阻塞队列!***重要
什么是阻塞队列
顾名思义。首先是个队列,具有阻塞功能,适合生产消费模型,阻塞队列是线程安全的,所以生产者核消费者可以是多线程的,不用考虑线程安全
take和put方法,空的时候,take阻塞,满的时候,put阻塞
是否有界,无界的阻塞队列的大小是Integer.MAX_Value
注意阻塞队列和线程池的关系,我在线程池的篇章中有讲奥
主要方法介绍
take和put方法
这是特色的方法,take和put上面讲过了
add、remove、element
这三个方法,没数据、或者满的时候会报错
offer、poll、peek
这组方法友好点,offer是添加数据,满了之后返回boolean值,而不是报错
poll取值,没值的时候返回null,而不是报错、有数据的时候取出
peek取的时候不会删除,只是查看
是否有界,无界的阻塞队列的大小是Integer.MAX_Value
注意阻塞队列和线程池的关系,我在线程池的篇章中有讲奥
ArrayBlockingQueue
这里主要演示 take和put,演示面试官面试,但是房间就三个等待座位(阻塞队列),演示put和take阻塞
/**
* @Author:Joseph
* 面试场景,一个面试官
* 3个座位
* 但是有10个面试者
*
*/
public class ArrayBlockingQueueDemo {
public static void main(String[] args) {
//模拟只有3个等待座位
ArrayBlockingQueue<String> queue = new ArrayBlockingQueue<String>(3);
Interviewer r1 = new Interviewer(queue);
Consumer r2 = new Consumer(queue);
new Thread(r1).start();
new Thread(r2).start();
}
}
//面试官
class Interviewer implements Runnable{
BlockingQueue<String> queue;
public Interviewer(BlockingQueue queue){
this.queue = queue;
}
@Override
public void run() {
System.out.println("10个候选人都来了");
for (int i = 0; i < 10; i++) {
String candidate = "Candidate"+i;
try {
queue.put(candidate);
System.out.println("安排好了"+candidate+"坐着等待面试");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//结束信号,让消费者知道结束了
try {
queue.put("stop");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
class Consumer implements Runnable{
BlockingQueue<String> queue;
public Consumer(BlockingQueue queue) {
this.queue = queue;
}
@Override
public void run() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
String msg;
try {
while (!(msg = queue.take()).equals("stop")){
System.out.println(msg+"在面试");
}
System.out.println("面试完了10个人了");
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println();
}再看一下,如何实现等待的,
put方法源码
public void put(E e) throws InterruptedException {
Objects.requireNonNull(e);
final ReentrantLock lock = this.lock;
//lock可中断锁,put等待时候,可以被线程中断方法打断,而不是非要获取到这个锁
lock.lockInterruptibly();
try {
//满了,则等待,
while (count == items.length)
//等待不满
notFull.await();
//入队
enqueue(e);
} finally {
//解锁。
lock.unlock();
}
}LinkedBlockingQueue
第一个特点。无界
容量是Intger.MAX_VALUE
内部结构:Node、两把锁,
这里就不看源码了,知道是lock加锁保证线程安全,用condition保证等待就好了,
PriorityBlockingQueue
支持优先级
自然排序,不是先进先出,并发采用reenrantLock
无界队列,这里点一下,linkedBlockingQueue和这个优先级blockingQueue的put是不会阻塞的,因为无界限,但是take会,空了就要等
可以理解为是PriorityQueue的线程安全保本,
SynchronousQueue
直接交换使用的,队列商都为0,但是连头节点都没有,也就没有peek方法
是一个极好的直接传递的并发数据结构
线程池中不停的新开线程的线程池:Executor.newCachedThreadPool()使用的阻塞队列
新开线程而不用队列进行存储,就采用的SynchronoutQueue
DelayQueue()
延迟队列,根据延迟时间排序,元素需要实现Delayed接口,规定排序规则
也是无解队列
非阻塞队列(CAS非阻塞算法)
非阻塞队列只有一个
就是concurrentLinkedQueue
链表作为数据结构,使用CAS非阻塞算法实现线程安全,不具备阻塞功能,适用于高并发,高性能的场景
当然由于非阻塞,cpu禁不住造啊,用的相对也就少一点
我们看一下如何用CAS实现非阻塞队列的,
offer方法,
用p.casNext方法,用的是Unsafe类提供的,compareAndSwapObject方法
通过for死循环,和unsafe类提供的cpu的原子性的compareAndSwap来完成非阻塞队列
如何选择适合自己的队列
选择边界,是有边界的还是无边界的,考虑使用场景
空间 来说:synchronoutQueue没有容量,但是Array和linked比的话,array空间上更整齐
吞吐量:一般来说linkedBlockingQueue更高,jdk8中,用了两把锁,来完成读和取的操作
当然考虑一些特殊的场景,比如优先级blocking或者是不用存储,直接交换的synchronousQueue
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。