mysql调优哪些事儿
原创
说明
终于到了精细策划的mysql调优环节了!!!!
mysql调优,最主要的就是索引了,这里先出一个面试题,
这边有个数据库-单表1千万数据,未来1年还会增长多500万,性能比较慢,说下你的优化思路
数据库性能优化有这三方面的角度
1 分库分表
2优化
在数据量压力不是很大的情况下,首先考虑缓存,索引优化等技术,数据量极大且增长较快,再考虑分库分表
分库分表我这个假期会出一个专栏,感兴趣的可收藏博客,分库分表专栏会讲到
对于优化,分软优化和硬优化,硬件的优化,包括操作系统层面的优化,带宽,cpu,硬盘等,
软优化就是在数据库层面,例如索引,进行调优,读写分离,还有就是引入NoSql做缓存,这个在我的缓存专栏都有讲
再者
对于索引基础知识,以及各种概念例如覆盖索引,索引下推等技术,都在mysql索引文章
这里我总结下上篇文章mysql索引-腾讯云开发者社区-腾讯云 (tencent.com)
这里我把mysql索引的知识深入的细究完毕,理论上问题已经差不多了,我通过几次面试,在这里,甚至没有难到我的地方,看完这篇文章,就能熟练掌握索引知识,为mysql调优铺垫基础了,但是真正做到mysql调优,光理论是不行的,而且,一般程序员crud很难接触到调优的知识,所以这篇文章,面向实战+理论,我也会把这里构建mysql调优的工具集,也就是说,真正碰到需要的调优的场景,这篇文章就会起很大的作用~!
调优基础知识
上篇文章,过于理论,索引命令放到这里,便于使用。至于慢查询日志和explain是mysql调优必备的!
这里提供一个库,docker 部署mysql8.0的链接,自行部署即可
docker-mysql8.0踩坑敏感问题 | Joseph's Blog (gitee.io)
调优用的这个库
新建数据库 shop
CREATE TABLE `product` (
`id` bigint NOT NULL AUTO_INCREMENT,
`title` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`cover_img` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '封面图',
`amount` decimal(10,2) DEFAULT NULL COMMENT '现价',
`summary` varchar(2048) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '概要',
`detail` longtext CHARACTER SET utf8mb4 COLLATE utf8mb4_bin COMMENT '详情',
`gmt_modified` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`gmt_create` datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin ROW_FORMAT=DYNAMIC;一些数据,可自行扩容
INSERT INTO `shop`.`product` (`id`, `title`, `cover_img`, `amount`, `summary`, `detail`, `gmt_modified`, `gmt_create`) VALUES (4, 'SpringBoot2.x整合消息队列', '1-新版自动化测试Selenium3入门到高级实战教程-cover_img', 4.40, '1-新版【前端高级工程师】面试专题第一季-summary', '1-detaul-互联网架构之JAVA虚拟机JVM零基础到高级实战', '2023-06-02 04:35:16', '2023-06-02 04:35:16');
INSERT INTO `shop`.`product` (`id`, `title`, `cover_img`, `amount`, `summary`, `detail`, `gmt_modified`, `gmt_create`) VALUES (5, '微服务SpringCloud+Docker入门到高级实战', '2-新版后端提效神器MybatisPlus+SwaggerUI3.X+Lombok-cover_img', 5.40, '2-新一代数据库丨海量数据存储ClickHouse列式存储-summary', '2-detaul-SpringBoot+Websocket打造实时聊天/股票行情系统', '2023-06-02 04:35:16', '2023-06-02 04:35:16');
INSERT INTO `shop`.`product` (`id`, `title`, `cover_img`, `amount`, `summary`, `detail`, `gmt_modified`, `gmt_create`) VALUES (6, 'Linux/Centos7视频教程零基础入门到高实战', '3-Node.js教程零基础入门到项目实战前端视频教程-cover_img', 6.40, '3-Jenkins持续集成 Git Gitlab Sonar视频教程-summary', '3-detaul-小白到专家-分布式缓存Redis6.X+高可用集群', '2023-06-02 04:35:16', '2023-06-02 04:35:16');
INSERT INTO `shop`.`product` (`id`, `title`, `cover_img`, `amount`, `summary`, `detail`, `gmt_modified`, `gmt_create`) VALUES (7, 'Spring Boot 2.x零基础入门到高级实战教程', '4-玩转全新JDK8~JDK13全套新特性教程-cover_img', 7.40, '4-SpringBoot 2.x微信支付在线教育网站项目实战-summary', '4-detaul-新版Javascript视频前端零基础到项目实战/js视频', '2023-06-02 04:35:16', '2023-06-02 04:35:16');
INSERT INTO `shop`.`product` (`id`, `title`, `cover_img`, `amount`, `summary`, `detail`, `gmt_modified`, `gmt_create`) VALUES (8, '数据库操作之整合Mybatis和事务讲解', '5-互联网架构之分布式缓存Redis从入门到高级实战-cover_img', 8.40, '5-玩转Nginx分布式架构实战教程 零基础到高级-summary', '5-detaul-新版-玩转ECMAScript6零基础到进阶实战es6视频', '2023-06-02 04:35:16', '2023-06-02 04:35:16');
INSERT INTO `shop`.`product` (`id`, `title`, `cover_img`, `amount`, `summary`, `detail`, `gmt_modified`, `gmt_create`) VALUES (9, '/后端高级工程师面试专题第一季', '6-新版-玩转ECMAScript6零基础到进阶实战es6视频-cover_img', 9.40, '6-新一代微服务全家桶AlibabaCloud+SpringCloud实战-summary', '6-detaul-Redis高并发高可用集群百万级秒杀实战', '2023-06-02 04:35:16', '2023-06-02 04:35:16');
INSERT INTO `shop`.`product` (`id`, `title`, `cover_img`, `amount`, `summary`, `detail`, `gmt_modified`, `gmt_create`) VALUES (10, '互联网架构多线程并发编程高级教程', '7-新版后端提效神器MybatisPlus+SwaggerUI3.X+Lombok-cover_img', 10.40, '7-玩转新版接口自动化测试教程 零基础到设计测试框架-summary', '7-detaul-新版Javascript视频前端零基础到项目实战/js视频', '2023-06-02 04:35:16', '2023-06-02 04:35:16');
INSERT INTO `shop`.`product` (`id`, `title`, `cover_img`, `amount`, `summary`, `detail`, `gmt_modified`, `gmt_create`) VALUES (11, '微服务架构-海量数据商用短链平台项目大课【完结】', '8-玩转TypeScript零基础到项目实战+VUE3新特性-cover_img', 11.40, '8-新版Maven3.5+Nexus私服搭建全套核心技术-summary', '8-detaul-玩转Postman多场景接口自动化测试', '2023-06-02 04:35:16', '2023-06-02 04:35:16');
INSERT INTO `shop`.`product` (`id`, `title`, `cover_img`, `amount`, `summary`, `detail`, `gmt_modified`, `gmt_create`) VALUES (12, 'JMeter4.x接口压力测试打造高性能服务', '9-互联网架构多线程并发编程高级教程-cover_img', 12.40, '9-新版丨急速掌握分布式链路追踪Apache Skywalking最佳实践-summary', '9-detaul-全新React零基础到单页面项目实战', '2023-06-02 04:35:16', '2023-06-02 04:35:16');
INSERT INTO `shop`.`product` (`id`, `title`, `cover_img`, `amount`, `summary`, `detail`, `gmt_modified`, `gmt_create`) VALUES (13, '简历编写-面试BAT高级工程师简历编写', '10-价值198元新版本RocketMQ4.X教程消息队列-cover_img', 13.40, '10-新版全套webpack4教程模块化打包入门到进阶-summary', '10-detaul-SpringBoot2.x整合模板引擎', '2023-06-02 04:35:16', '2023-06-02 04:35:16');
INSERT INTO `shop`.`product` (`id`, `title`, `cover_img`, `amount`, `summary`, `detail`, `gmt_modified`, `gmt_create`) VALUES (14, '互联网架构之JAVA虚拟机JVM零基础到高级实战', '11-新版Python3.7零基础入门到爬虫实战-cover_img', 14.40, '11-三天掌握 Kafka 消息队列 小白到专家之路-大数据教程-summary', '11-detaul-玩转搜索框架ElasticSearch7.x实战', '2023-06-02 04:35:16', '2023-06-02 04:35:16');
INSERT INTO `shop`.`product` (`id`, `title`, `cover_img`, `amount`, `summary`, `detail`, `gmt_modified`, `gmt_create`) VALUES (15, 'js高手进阶之ES6至ES8入门到进阶实战', '12-Docker实战视频教程入门到高级dockerfile-cover_img', 15.40, '12-新版【前端高级工程师】面试专题第一季-summary', '12-detaul-微服务SpringCloud+Docker入门到高级实战', '2023-06-02 04:35:16', '2023-06-02 04:35:16');
INSERT INTO `shop`.`product` (`id`, `title`, `cover_img`, `amount`, `summary`, `detail`, `gmt_modified`, `gmt_create`) VALUES (16, '新版-零基础玩转Vue3+开发仿美团外卖项目vue视频', '13-玩转搜索框架ElasticSearch7.x实战-cover_img', 16.40, '13-618分期活动专属链接2000-summary', '13-detaul-新一代数据库丨海量数据存储ClickHouse列式存储', '2023-06-02 04:35:16', '2023-06-02 04:35:16');
INSERT INTO `shop`.`product` (`id`, `title`, `cover_img`, `amount`, `summary`, `detail`, `gmt_modified`, `gmt_create`) VALUES (17, '全新微信小程序零基础到项目实战', '14-新版javase零基础到高级教程小白自学编程-cover_img', 17.40, '14-玩转新版高性能RabbitMQ容器化分布式集群实战-summary', '14-detaul-全新微信小程序零基础到项目实战', '2023-06-02 04:35:16', '2023-06-02 04:35:16');
索引命令
#查看表的相关索引
show INDEX from product
#创建索引的命令
CREATE INDEX idx_title_summary on product(title,summary)
CREATE INDEX idx_summary on product(summary)
CREATE INDEX idx_title on product(title)
#修改表的方式创建索引
ALTER TABLE product ADD INDEX idx_summary (summary)
#创建唯一索引
CREATE UNIQUE INDEX summary ON TABLE (summary)
#主键索引
CREATE TABLE product
(id int(10) not null ,
name varchar(20) not null,
primary key (id))
ALTER TABLE product ADD PRIMARY KEY(id)
#删除主键索引
ALTER TABLE product DROP PRIMARY KEY;
#全文索引
CREATE FULLTEXT INDEX idx_full ON product (address)
#使用全文索引
select * from product where match (address) against ("wuhan")
#删除索引
DROP INDEX summary ON product
慢查询日志
通过慢查询日志,可以发现慢的sql,然后通过explain分析为什么慢
在表中执行一下show variables like 'slow%'
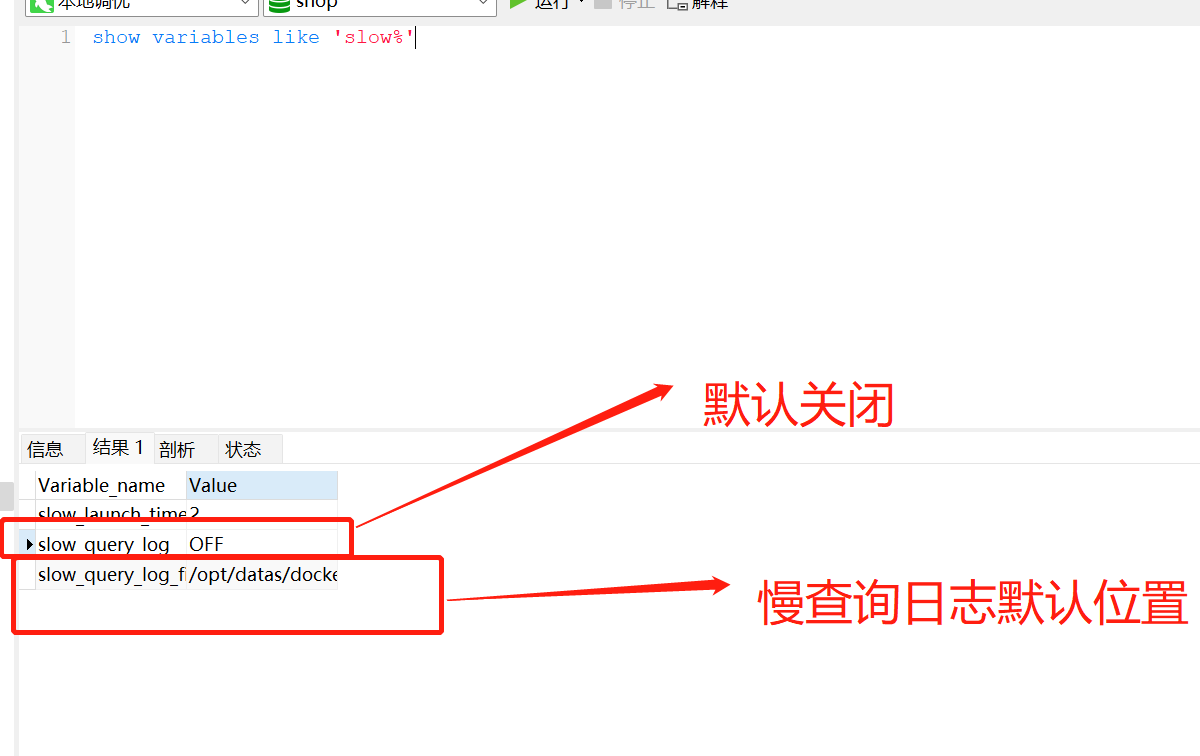
slow_query_log默认OFF为关闭 slow_query_log_file表示慢查询日志文件的存放路径、
执行show variables like '%long%'
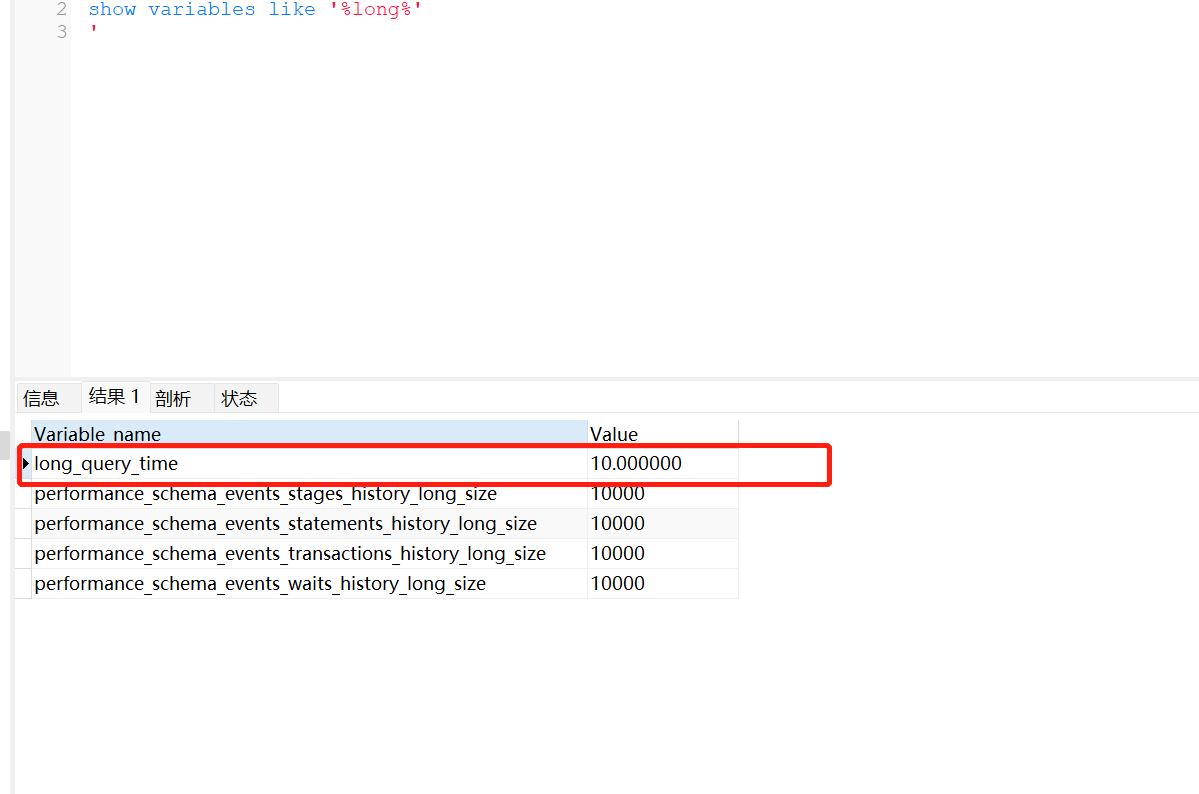
看这个long_query_time即可,默认10s以上为慢查询,在数据量不是很大的情况下,我们要设置成0.02才行
我们一般不在这里临时的搞,而是在配置文件中
通过看上面那篇博文,vim /opt/datas/docker/mysql/conf/my.cnf
我的配置文件是放在这里的
在配置文件中加进去这两个
[mysqld]
slow_query_log=ON
long_query_time = 0.02我直接加在原来的基础上了,方便大家看
注意slow_query_log_file指慢查询持久化文件再docker容器中,慢查询日志的具体位置。这里没有加,执行show variables like 'slow%'的时候知道在哪里就行。
[client]
#socket = /usr/mysql/mysqld.sock
default-character-set = utf8mb4
[mysqld]
slow_query_log=ON
long_query_time = 0.02
#pid-file = /var/run/mysqld/mysqld.pid
#socket = /var/run/mysqld/mysqld.sock
#datadir = /var/lib/mysql
#socket = /usr/mysql/mysqld.sock
#pid-file = /usr/mysql/mysqld.pid
lower_case_table_names=1
datadir = /opt/datas/docker/mysql/data
character_set_server = utf8mb4
collation_server = utf8mb4_bin
secure-file-priv= NULL
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
# Custom config should go here
!includedir /etc/mysql/conf.d/
现在修改好这里的内容:/opt/datas/docker/mysql/conf/my.cnf
dokcer restart [该容器]使得配置生效
select sleep(10)执行这个,睡眠10s,看一下是否生效
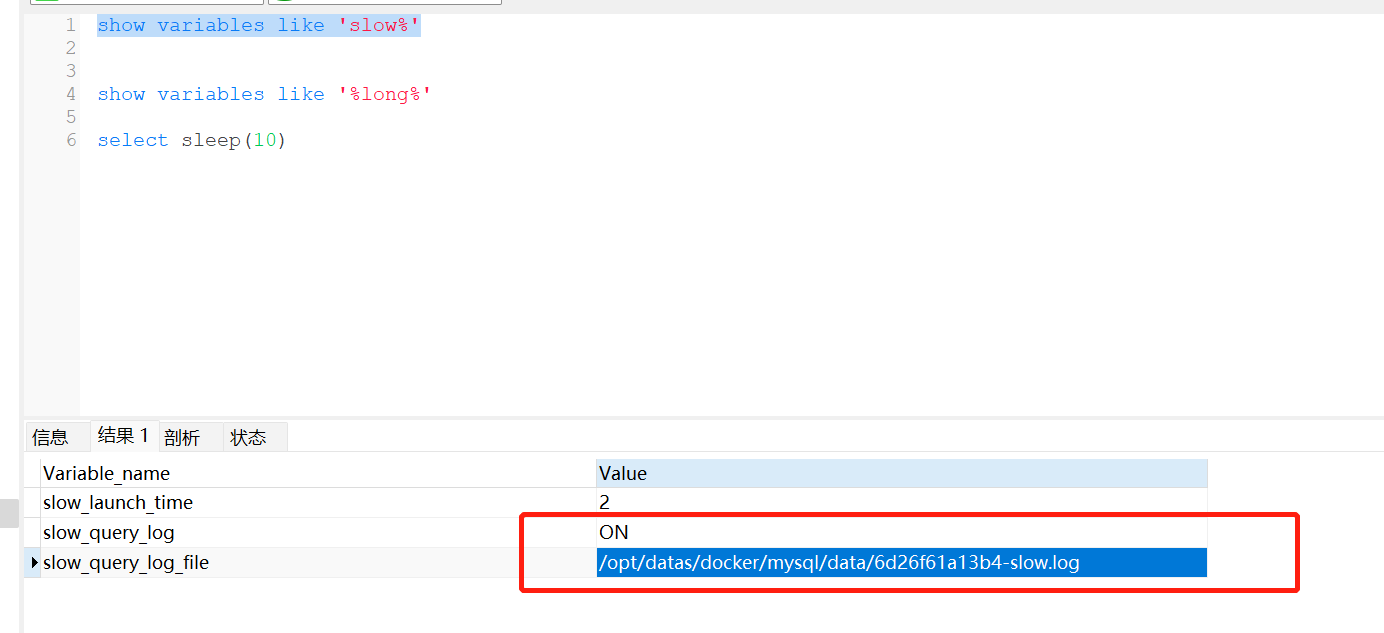
看一看到,这个持久在这里,这里是在docker容器中的,先进入容器
再执行下面代码查看
cat /opt/datas/docker/mysql/data/6d26f61a13b4-slow.log

好,慢查询日志如何去看?
# Time: 2023-05-29T07:16:22.801248Z
# User@Host: root[root] @ [119.130.128.200] Id: 706
# Query_time: 2.000534 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 1
SET timestamp=1685344580;
select * from product
Time: 表示日志记录的时间。格式为 ISO8601 标准的 UTC 时间。
User@Host: 表示执行该SQL语句的用户和主机名。
Id: 表示线程 ID,是一个整数表示。
Query_time: 表示 SQL 语句的执行时间,以秒为单位。
Lock_time: 表示在执行 SQL 语句期间等待锁定资源的时间。如果 SQL 语句没有使用锁,则为 0。
Rows_sent: 表示 SQL 语句返回的行数。
Rows_examined: 表示查询过程中扫描的行数。如果 SQL 语句没有执行查询操作,则该值为 0。
timestamp: 表示该 SQL 语句的执行时间戳,以秒为单位。
sql语句: 实际执行的SQL语句。好这样就能发现慢的sql了,现在就是要分析为什么慢并且解决了!。
多慢算慢?
知道慢查询日志了,那么多慢算慢呢?
对于一般服务器,0.02s 200ms以上就算慢了
对于高并发的业务,也需要0.05s 500ms
explain执行计划

这么多东西,我们只注意几个就行了
id,知道越大越先执行
select_type就是查询或者子查询的类型,
table就是表嘛,查询涉及哪几个表。这个就没什么好说的了
partions分区表,这个一般不属于调优范畴,
type这个就很重要了,这个指的是mysql找到某一行的方式,!
包括All,Index,range,ref.eq_ref,const,system,NULL
性能由差到好
ken_len,ken的长度,下面会讲
ref指的是,mysql要使用哪个列或者常量去跟索引列进行比较
rows,扫描多少行才能拿到数据
Extra也很关键,指的是额外的查询信息,比如索引覆盖,索引下推
这里再着重说一下重要的字段
主要就5个,可能用到的key,实际用到的key,type,key_ken ,extra
type:
上面说到,type从All到NULL效率依次升高
ALL就是全表扫描嘛,这最慢,
index是索引的全表扫描,其次,
range范围查询,比如1w行数据,>9000,从9000查询就可以了,很省时间,值得注意的是,范围查询也是建立在走索引基础上的
ref,非唯一索引,或者唯一索引的前缀扫描,在range的基础上进一步提示,这个怎么理解呢,就是range的话,是走索引,减少了一些范围,还是得索引一个个的扫描,而ref指的是,已经找到了这个索引,但是索引不重复,或者是唯一索引前缀扫描,在很小的范围内进行扫描,效率还是挺快的,若是唯一索引,就直接找到了,这就是eq_ref
const,就是不用扫了,直接找到,类似于数组拿数据的O(1)级别,后面的system和null基本不会出现,我们不用去看他
调优的话,ref及以上是最好的,range是底线!
Extra字段
这里罗列一张图,前四个是重要的,建议看完下面调优部分,再看这里
类型 | 概述 |
|---|---|
Using index | 选择使用了覆盖索引的特性,通过索引直接获取查询结果,而无需回表查询,提高了查询效率。 |
Using filesort | 需要额外进行 一个文件排序操作来实现 ORDER BY 操作,可能会严重影响查询性能。 |
Using temporary | 在执行查询时需要借助临时表来保存中间结果集,这常发生在排序、分组、子查询和 UNION 查询之中。 |
Using where | 条件查询,在查询过程中需要进行表级别的条件过滤,即使共享了某些索引,也需要进行全表扫描查找符合条件的行。不是仅仅通过索引就可以获取所有需要的数据,则会出现 Using where |
Range checked for each record | 通过索引比较操作来过滤部分行,直到找到符合条件的行,这种操作常出现在使用 INDEX 和 ORDER BY 操作时。 |
Using join buffer (Block Nested Loop) | 在执行连接操作时需要额外申请 join buffer 来存储中间结果,这种操作常发生在连接操作中。 |
Using index condition | 利用了查找索引数据的过程中额外发现的过滤条件进行了优化,无需回表查询或查表,可以直接通过索引结果来返回查询的结果 |
Using sort_union()和Using union() | 通过 UNION ALL 或 UNION DISTINCT 操作来合并查询结果集,使用了一些优化策略来提高查询效率。 |
Using Index,就是走了覆盖索引,无需回表操作,很简单
Using filesort,就是没走B+树构建的排序好的索引,需要在内存中排序,很影响性能,优化方案就是在排序的字段加索引
explain SELECT province,STATUS from account ORDER BY province asc
-- Using index
explain SELECT province,STATUS from account ORDER BY province desc
-- Backward index scan; Using index
-- 默认索引的叶子节点是从小到大排序的,查询排序是从大到小,在扫描时就是反向扫描,就会出现 Backward index scan
上面两种情况,就没用using index,但是反向扫描,出现了Backward index scan,这个认识就行
explain SELECT province,city,STATUS from account ORDER BY province asc,STATUS asc
-- 索引生效,Using index
explain SELECT province,city,STATUS from account ORDER BY province asc,STATUS desc
-- 索引生效,但是多了排序 Using index; Using filesort
字段排序时,也遵循最左前缀法则,需要保证都是升序或者都是降序,否则依旧会出现排序
Using temporary,需要借助临时表来保存中间的结构集,
show global variables like 'max_heap_table_size'
show global variables like 'tmp_table_size';选择内存临时表还是硬盘临时表取决于参数 tmp_table_size和max_heap_table_size, 两者的默认值均为16M
- 内存临时表的最大容量为tmp_table_size和max_heap_table_size值的最小值
- 当所需临时表的容量大于两者的最小值时,mysql就会使用硬盘临时表存放数据
Using where
是我们平时见的最多的,条件查询的时候,进行全表扫描

explain SELECT province,city,STATUS from account where province = '北京市'
-- 索引生效 Using index
这里虽然走了索引,但是!,还是需要通过type来判断是否需要进一步优化,ref,可以看到,达到 命中索引,但是还是需要小部分的查询。
调优
key_len索引长度计算
这个是很重要的,通过这个,我们可以知道用了哪个索引,为什么这样说呢?可能很多人会有疑问,explain执行计划不是告诉key了吗?
这样就错喽~
比如一个联合索引,a,b,c,当你where字段只有a和b的时候,当然还是走的前两个了~这个时候就要我们计算来分析了
首先,理清字符,和字节
字符指的是任意一个可以敲出来的东西,逗号,字母这些,一个字符,在utf-8是3个字节
(utf-8就是utf-8mb3)一个字符是3个字节,而utf-8mb4一个字符是4个字节
varchar存的就是字符,一个varchar(n)索引需要3n+2个字节,3就是三个字节,n是字符数量,2,因为需要两个字节来存储字符串的长度
char(n) 就是n个字节
上面是特殊的字符串的场景需要我们看utf-8的编码类型
数值
tinyint 1字节 int 4字节 bigint 8字节
时间
data 3字节 timestamp 4字节 datatime 8字节
另外
如果允许null,那么还需要多加1 个字节来存储
另外这里说一下容易混淆的 点那就是 int(1) 和int (4)的关系
int都是占4个字节,一个字节8位,那么对于无符号的int,最大值就是2^32-1,将近40亿
这个int(1)括号中的内容,只是在使用zerofill显示的区别而已,如果不使用zerofill自动填充,那么他们没有任何区别
eg:int(1) 和 int(4),都存1,分别是1,0001,都存10.分别是10,0010
好,基础知识晓得了,咱来实践看一下
CREATE TABLE `product` (
`id` bigint NOT NULL AUTO_INCREMENT,
`title` varchar(128) NOT NULL,
`cover_img` varchar(255) DEFAULT NULL COMMENT '封面图',
`amount` decimal(10,2) DEFAULT NULL COMMENT '现价',
`summary` varchar(255) DEFAULT NULL COMMENT '概要',
`detail` longtext COMMENT '详情',
`gmt_modified` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`gmt_create` datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb3 ROW_FORMAT=DYNAMIC;
INSERT INTO `shop`.`product` (`id`, `title`, `cover_img`, `amount`, `summary`, `detail`, `gmt_modified`, `gmt_create`) VALUES (1, '课程1', '主图', 8888.00, '这个是概要', '详情', '2023-05-30 02:47:55', '2023-05-30 02:47:55');
INSERT INTO `shop`.`product` (`id`, `title`, `cover_img`, `amount`, `summary`, `detail`, `gmt_modified`, `gmt_create`) VALUES (2, '课程2', '12312', 10.00, '8888', '6666', '2023-05-30 02:48:32', '2023-05-30 02:48:11');
INSERT INTO `shop`.`product` (`id`, `title`, `cover_img`, `amount`, `summary`, `detail`, `gmt_modified`, `gmt_create`) VALUES (3, 'springboot', '这个是spring boot教程', 333.00, '999', '微服务的底层spring boot', '2023-06-01 03:47:04', '2023-05-30 02:48:27');
#查看表的相关索引
show INDEX from product
CREATE INDEX idx_title_summary on product(title,summary)
CREATE INDEX idx_summary on product(summary)
CREATE INDEX idx_title on product(title)我们先看一下创建的索引
联合索引和单个索引,
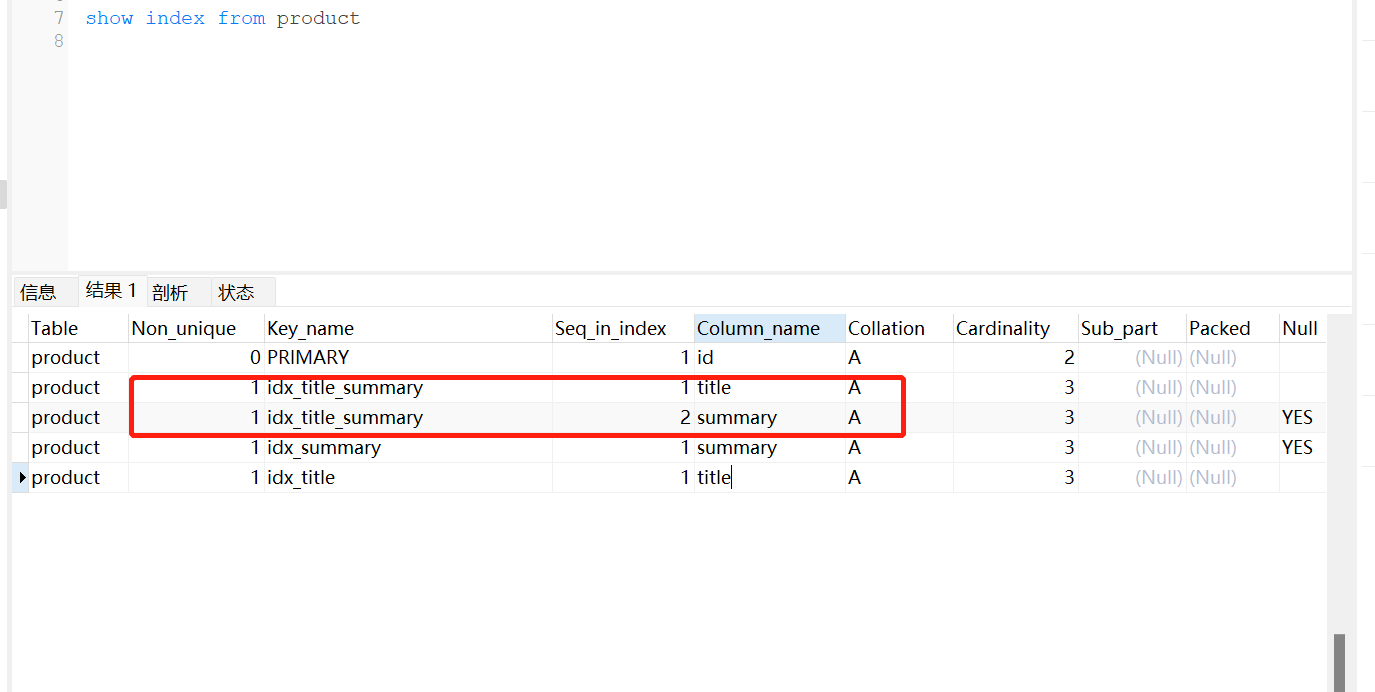
还有表的结构
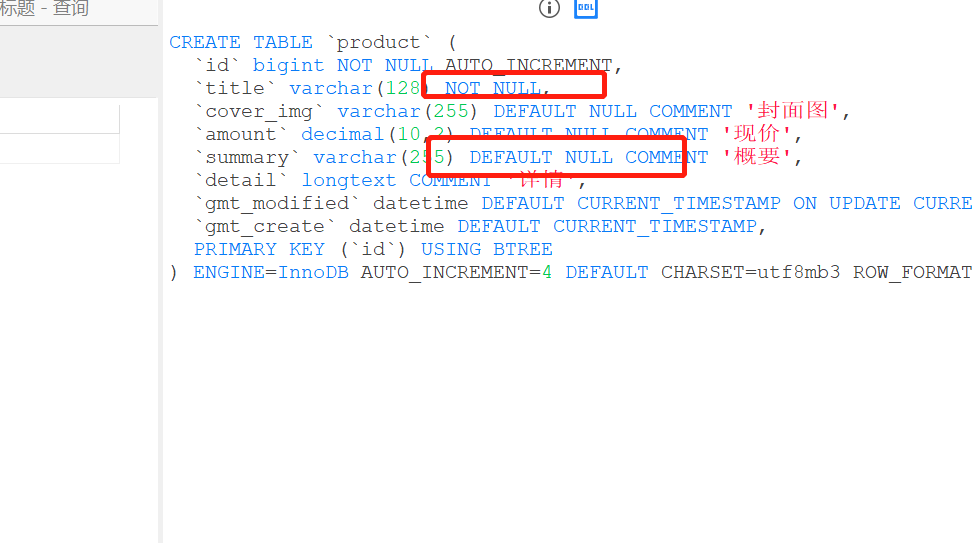
注意,summary是默认为空的,所以计算的结果要+1
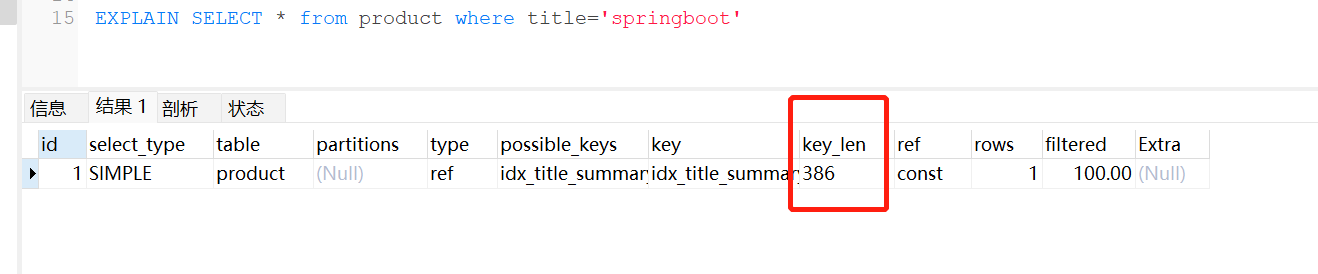
EXPLAIN SELECT * from product where title='springboot'
titile不为空,那么varchcar类型,答案是3*128+2=386
执行一下
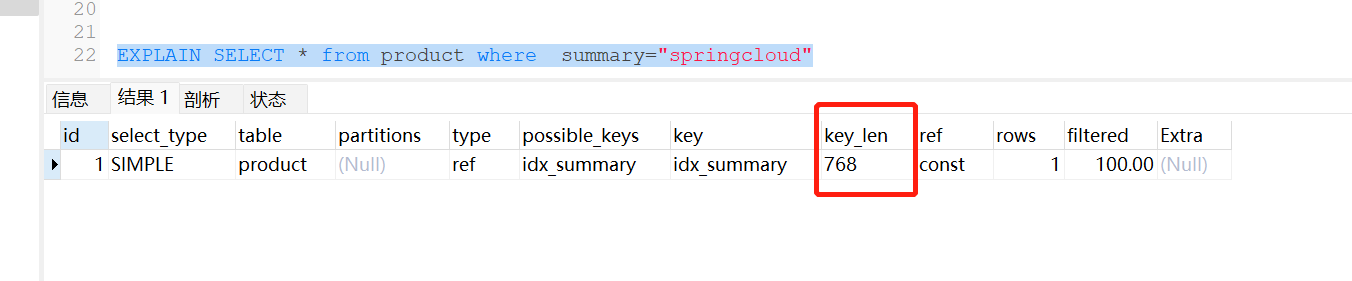
EXPLAIN SELECT * from product where summary="springcloud"
summary可为空,答案是3*255+2+1=768
执行
EXPLAIN SELECT * from product force index(idx_title_summary) where title='springboot' and summary='springboot'
因为我们强制使用联合索引,这个显然是386 + 768 = 1154

不强制呢?
也是这样,这是执行优化器帮忙选的,
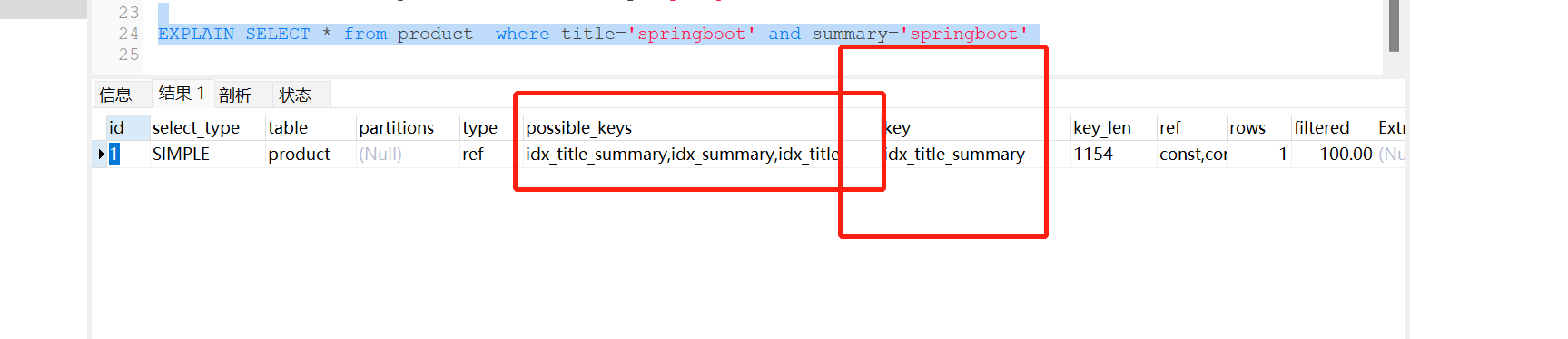
好,也许有人会问,key不是就已经告诉我们走哪个key了吗,要这个干嘛,
原因1,key_len的值越小,性能会越好,
原因2,待我在最左匹配原则讲`~~~
这里先点一下,这个计算key_len很牛的,可以让我们知道联合索引哪部分有效!
最左匹配原则
这玩意儿我在索引篇章中讲了理论,但是没有实践,这里细致的分析一下
这里我们搞一个新的表来讲最左匹配原则
#建表
CREATE TABLE `account` (
`id` bigint NOT NULL AUTO_INCREMENT,
`phone` varchar(64) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
`pwd` varchar(128) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
`province` varchar(80) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
`city` varchar(60) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL,
`status` int NOT NULL,
`gmt_create` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;
#插入数据
INSERT INTO `shop`.`account` (`id`, `phone`, `pwd`, `province`, `city`, `status`, `gmt_create`) VALUES (1, '13113', '1234', '广东省', '广州市', 1, '2024-01-09 00:00:00');
INSERT INTO `shop`.`account` (`id`, `phone`, `pwd`, `province`, `city`, `status`, `gmt_create`) VALUES (2, '887323', '1421', '浙江省', '杭州市', 0, '2025-10-23 00:00:00');
INSERT INTO `shop`.`account` (`id`, `phone`, `pwd`, `province`, `city`, `status`, `gmt_create`) VALUES (3, '4312', '992323', '广东省', '深圳市', 1, '2023-10-13 00:00:00');
#创建索引
CREATE INDEX idx_provice_status_city on account(province,status,city)代码搞这里,自行运行
还是先分析下索引和字段
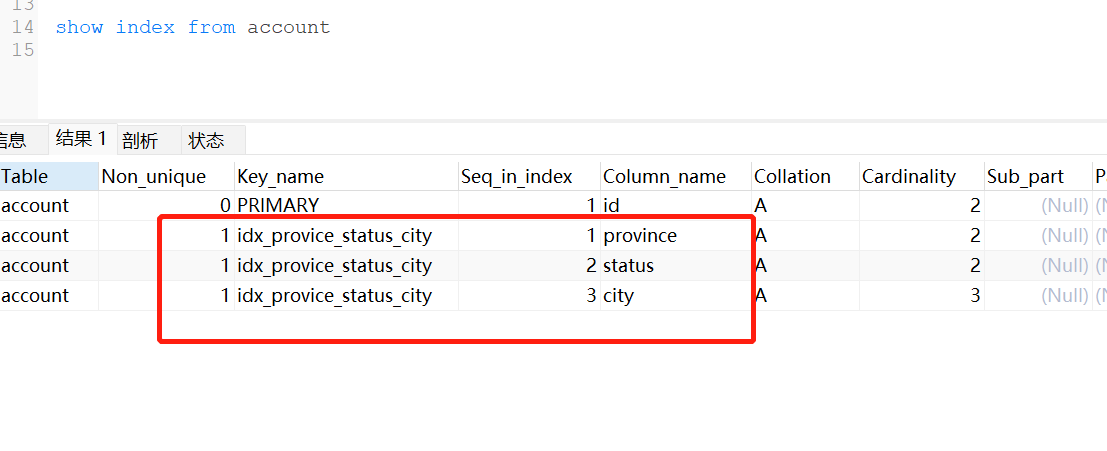
这里建了一个联合索引,顺序是province,status,city
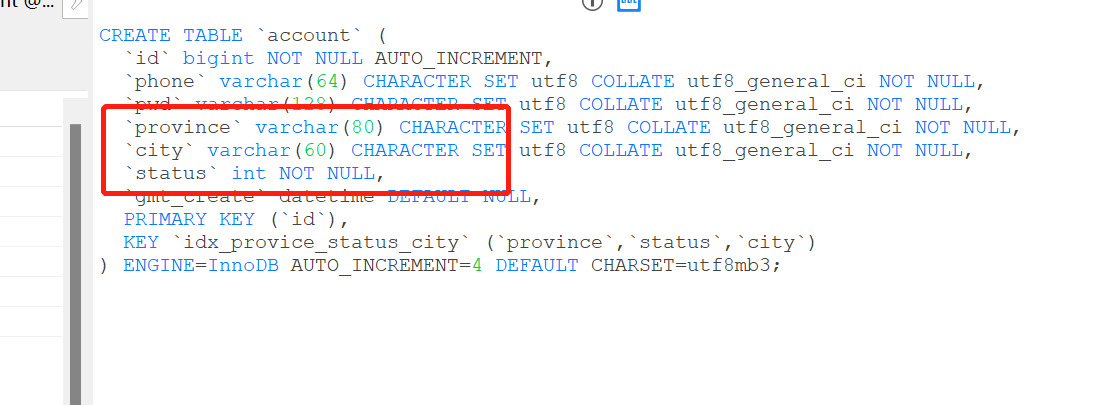
provice 3×80+2=242字节 status 4字节 city 3*×60=2 = 182字节
现在开始分析语句
语句1
explain SELECT * from account where province='广东省' and status=1 and city = '广州市'
最左匹配原则不一定要一一对应,但是要存在,这是mysql帮我们对应的,但是最左面的一定要存在

482= 242 + 4 + 182
索引联合索引几个字段都用上了
语句2
explain SELECT * from account where province='广东省' and status=1

注意这里,key还是和刚才一样显示联合索引的key,但是key_len变小了,也就是说,只有部分字段起到作用
246=242+4,所以是provice和status生效
语句3
explain SELECT * from account where province='广东省'
这里就不截图了
242嘛,easy的很
语句4
explain SELECT * from account where status=1 and city = '广州市'
联合索引失效,我在索引篇章讲过原理,可以去看
这里实战,大概就是在B+树层面,他是更加联合索引的顺序拍好的,联合索引第一个不在,那么他从B+树的根节点去哪个子树都不知道,何从找准确的值呢?只能全表扫描
语句5
explain SELECT * from account where province='广东省' and city = '广州市' -- 242
这里跳过中间列,只有最左侧失效
语句6
explain SELECT * from account where province='广东省' and status>0 and city = '广州市' --246 = (3*80+2) + 4
范围查询,右面的列会失效
对于语句5和语句6,我在这里谈一下字节的理解,当然若是使用的话,背会就行,但是它失效的原因是:由于B+树的节点是按照字段顺序排序的,当中间进行排序或者不走索引的话,是都是走不了后面的索引的,比如排序,在第二层条件变化之后,第三层的排序就被打乱了,可以这么理解,他们构建的B+树都是有明确的排序的,不能变化,一变化,排序就被破坏失效了
进一步索引失效
索引失效就是调优的主题,刚才讲的最左匹配原则的失效
下面讲其他的失效
or连接失效、like模糊查询失效、字段重复量太多失效、函数操作失效
or连接
or连接这里算比较坑的
or连接左右两个索引,都有索引才会生效,且数据量太少,也不会走索引
explain SELECT * from account where province='广东省' or gmt_create = '2024-01-01'
看这条语句,
首先,现在只有province有索引,是联合索引的一部分,而gmt_create是没有索引的
这样的话,他是不会走索引的

现在我们给gmt_create加上索引
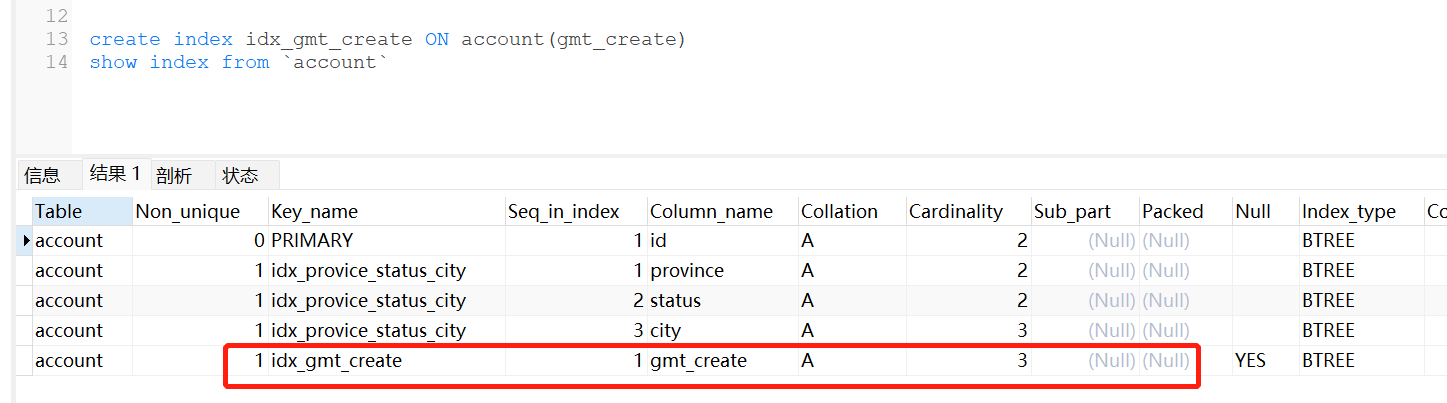
还是没有走索引

这就是因为数据量的问题了

现在拷贝3号数据,多执行几次
INSERT INTO `shop`.`account` (`phone`, `pwd`, `province`, `city`, `status`, `gmt_create`) VALUES ('4312', '992323', '广东省', '深圳市', 1, '2023-10-13 00:00:00');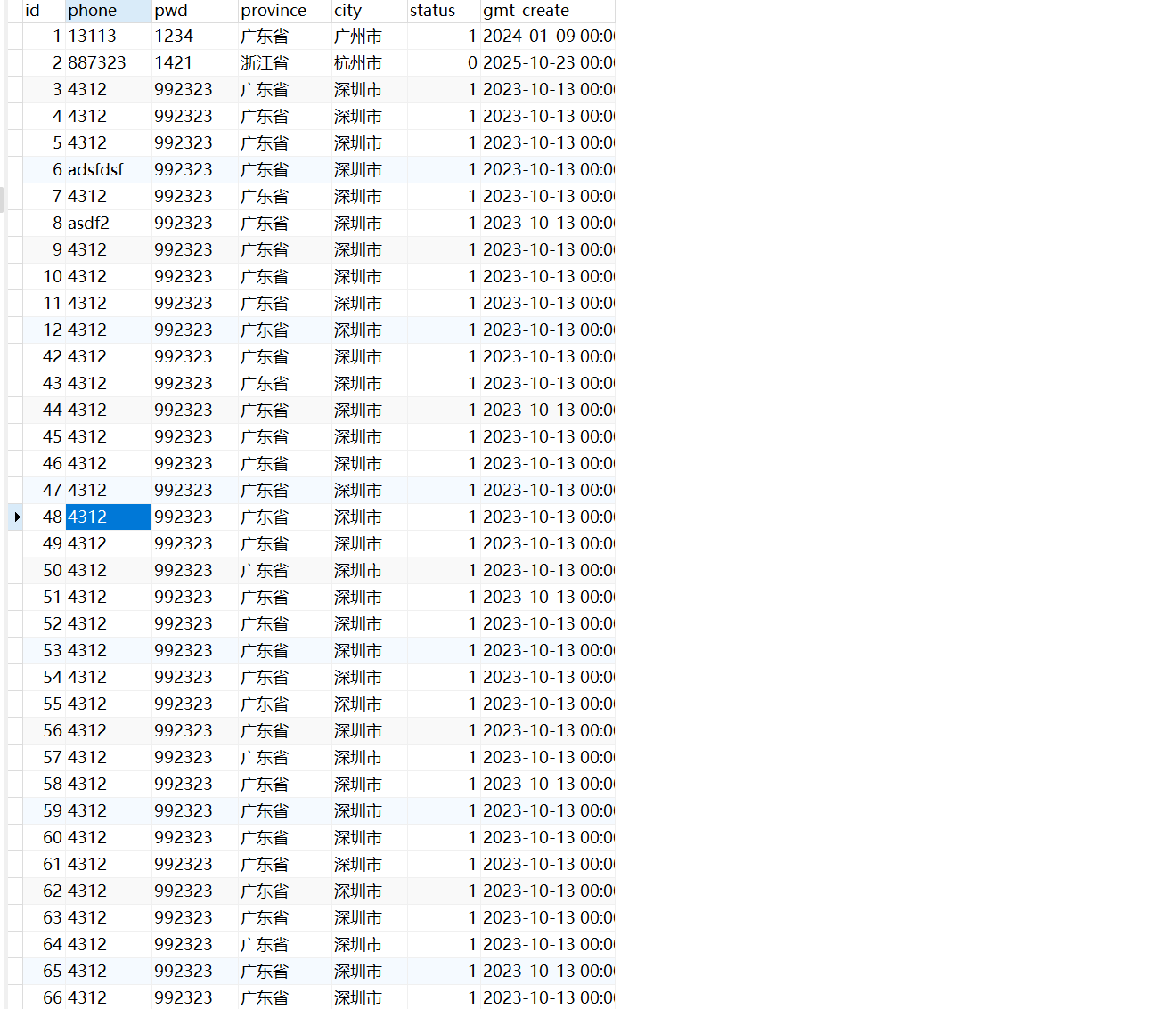
现在数据是这样的,

看,现在是不走索引的,为什么呢?
字段重复性过高失效
这个说的是重复太多,广东省太多了,索引查询,不如全表来的快,我们知道,select * 的时候,这个sql语句用索引的话,是需要回表操作的,执行计划认为直接进行全表扫描会比通过索引来取会更快!,索引不走索引

我们再查询江苏省,可以看到,这时候or连接就生效了,
like模糊查询
like这里其实也是和最左匹配原则类似的,就是使用索引,必须按照B+树构建索引数据结构去查询,
explain SELECT * from account where province like '广%'
-- 242这样的话,就会用到索引,
那么可想而知,
explain SELECT * from account where province like '%省'
-- 没采用索引
同样%东%,也是不可以的函数操作
隐式转换
函数操作和隐式转换,索引失效的原理,在这里一并讲,听起来高大上,其实很简单,我们知道,B+树是通过索引进行构建的,
如果进行对where后面字段的操作,或者隐式转换,还想走索引的话,就要构建新的B+树,这样性能和空间都会极大的浪费,总不能通过这一个查询单独浪费一个树吧
对于函数操作,比如 where a + 1 = 1,(a为int类型)这个还要走B+树的话 ,就要新构建B+树,这样就不会进行操作了,有人说,我把a+1=1 移成a = 1-1不就行了吗,对不起,mysql没做这个
对于隐式转换,这个就值得讨论了,我在这里举几个demo.,a是varchar类型
select * from table1 where a = 1
select * from table1 where a = '1'
对于varchar类型比较来说,a,b,c,d这些东西,比较int的时候会转换成数字1,但是我构建树的时候是按照字符构建的,那么就不会走B+树索引,
且注意一点:抛开调优,这里也是不对的!!!,因为a ,b,c,d转换成数字都是1,这样查询没有任何意义,甚至出现加引号、不加引号出现查询不到,或者根本查不出来东西的情况,这是我们值得注意的
NULL
null就是一个特殊的场面,is null,是不会走索引的,但是is not null,会走,所以进来给null赋一个具体的空值,这个原理的话,也是属于没遵顼B+树的数据结构的问题,NULL的话,怎么自定向下找东西啊,你说是不
索引失效总结
索引失效的原因无非就是两大点,一种是没必要走索引,一部分就是没遵循B+树的构建好的排序结构
第一种,
比如字段重复量过多,或者数据量过少,执行优化器认为没必要走索引了,全表扫描会更快,
范围查询的时候,1w行数据,且是select * 需要回表,那么id>9998和id<9998,那么id<9998是没必要进行索引的,因为回表操作次数太多,会导致性能下降,虽然不走索引会导致在内存排序,但是相较于9000多次的回表,这是没必要的
还有order by的时候,一个升序一个降序,也会导致失效,触发using filesort,但是先排序的哪个索引还是走覆盖索引的,using index
第二种
就比较多了,其他情况全是!,隐式转换,函数操作,NULL,like模糊查询,最左匹配原则,都是没按照B+树构建好的排序结构
索引调优方法论
上面讲到了索引调优失效的场景和一些调优基础
那么索引创建有哪些方法论呢?
这里就从三方面考虑,1索引创建的成本代价,2索引失效的情况3优化查询需求
代价方面:
首先就是要区分什么时候加索引,和加哪些索引
加索引的代价是很高的,每添加一个索引,就会建立一个B+Tree,索引有必要才加!
加索引,应当尽量通过联合索引来达到覆盖索引,以及达到通过索引来排序分表,而不是全表扫描,因为扫描完在内存中排序是很影响性能的,
唯一索引,唯一索引代价要比普通索引高 ,因为,唯一索引插入的时候要判断是否是唯一的,所以非必要不添加
索引长度当尽量的短,io小了速度也会更快,对于长的varchar,可以使用前缀索引,所谓前缀索引就是截取索引的部分来构建B+树,由此可见,部分的数据,是无法group by和orderBy的,
选离散型高的索引,索引创建代价高,要建立在有意义的地方上,比如性别上,只有男和女,那还建立什么索引
2索引失效情况:
通过索引失效情况,也可以总结一下索引调优的方法
索引列不参与函数计算操作,
3优化查询
比如经常需要排序,分组,联合操作,就需要构建索引,通过B+树的物理结构直接排好序,而不是在内存中排序
还有就是建立索引要尽量避免回表,做到覆盖索引,详细可以了解三星索引原则。
limit深度分页问题
这个问题,程序员一般用到少嘛,但是一旦遇到,影响是很大的,我这里有10w零4条数据,测试一下
好,我们现在查询10000条语句后的10条

这就以及8s了,要是上千万呢?影响是很大的
分页操作,也是会引起排序的,查询条件有索引列的话,主键>唯一索引>大于普通索引,按照这样的优先级排序,选择根据哪个索引进行排序
若没有索引列,就会根据主键进行排序
好,那么,既然会进行排序,只涉及字段的时候,排序是很快的,我们可以先只通过id列找到匹配的id,再进行索引列查询
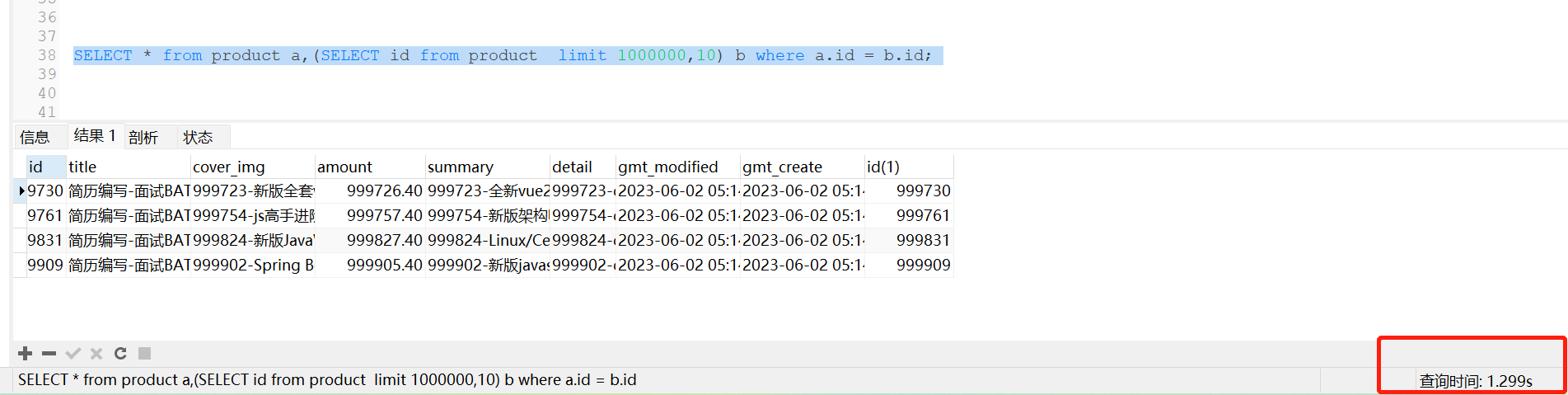
同样的数据,仅仅是用了1s,所以不一定关联查询一定差!调优也是很精彩的!
补充:
这里我谈论一下联合索引的最左匹配和索引下推这两个概念,这两个概念再索引篇章都讲过,但是我认为不够细致,
我在这里再次的细致讲一下
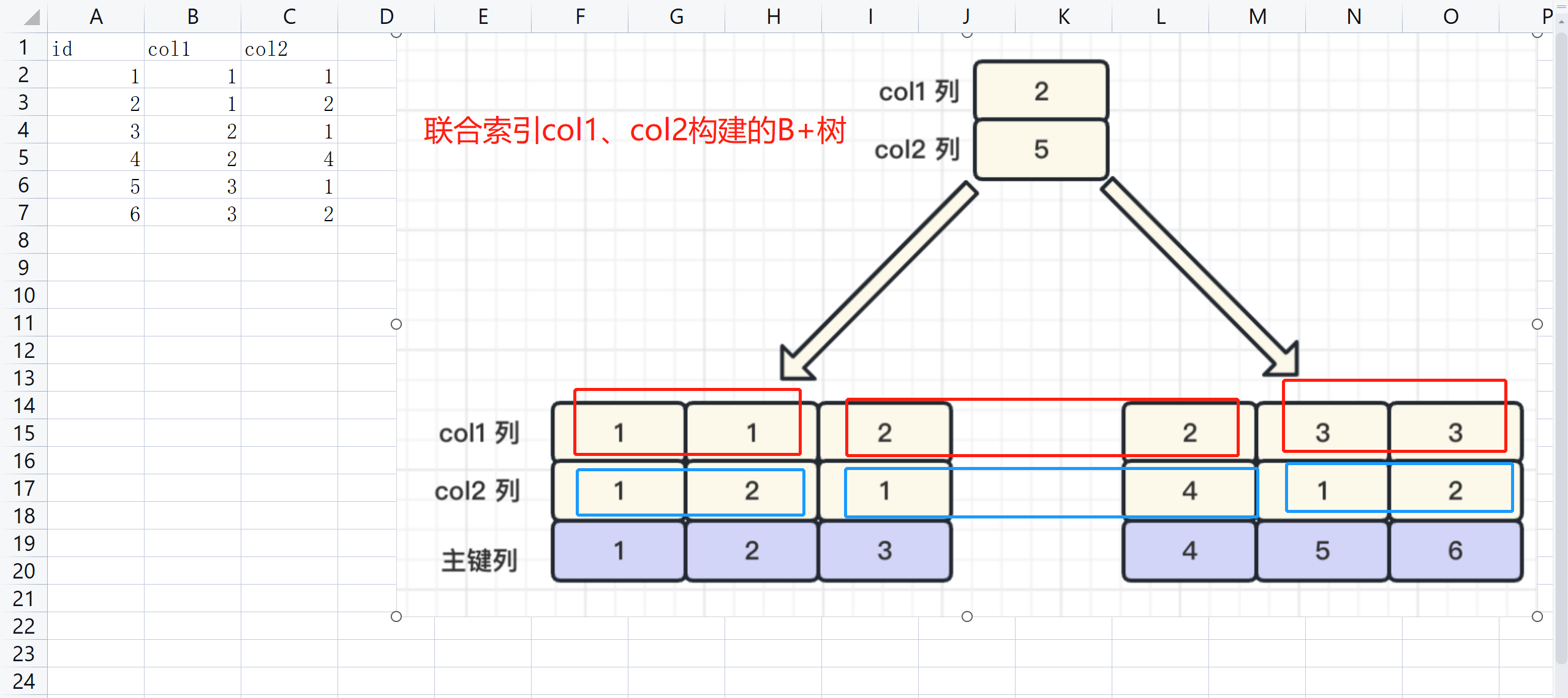
好,这个图,col1和col2进行构建B+树,是先按照col1排,再按照col2排,红色和蓝色,col1时候,col2排,有前面的才能进行排序!,再高级点,B+树查询时从上往下排的,要从上面的根节点到找到这两个叶子节点,你最起码得知道col1字段吧,知道大于2还是小于2才能知道走哪个叶子,才能继续找
好里就讲的彻底清晰了
再就是索引下推,为啥我没在调优部分讲这个呢?因为这时mysql帮咱们做的,比如我去找col1= 2 and col2 = 1这个地方,我们取select * 数据,如果没有索引下推,则需要这叶子节点的12也跟着回表找数据,但是用索引下推,也就是Using Index condition这个技术的话,会先在叶子节点中找到主键3,会一个表,从聚簇索引中拿数据就可以了!!!
结篇:
性能的好坏取决于具体的场景和查询的需求,不能单独的看某项指标,比如你sql慢,有可能就是公司其他服务占用硬件资源多了而已!所以先宏观再考虑调优,究竟是所有sql慢,还是单个sql慢,甚至是整个数据库关系模式的架构不足以应对并发,就要读写分离,引入NOsql缓存,提高硬件设施,或者说是高成本维护的分库分表,乃至有可能重新涉及库表结构等!
呕心沥血肝出来的,就说顶不顶?还不收藏+分享?
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。