Keras-深度学习-神经网络-人脸识别模型

模型搭建
①导入所需的库,导入了 Keras 和其他必要的库,用于构建和处理图像数据。
from keras.models import Sequential
from keras.layers import Dense, Flatten, Conv2D, MaxPooling2D
import os
from PIL import Image
import numpy②加载人脸数据并进行处理,并将其划分为训练集和测试集。每个人的图像按顺序排列,训练集包含每个人前6张图像,测试集包含剩余的图像。每个图像都被转换为像素值列表,并与相应的标签一起存储。
picture_path = r"C:\Users\Yezi\Desktop\机器学习\数据集\Yale_face10080"
suffix = ".bmp"
num_people = 15
num_train = 6
num_picture_single = 11
dimension = [80, 100]
x_train = []
y_train = []
x_test = []
y_test = []
picture_file = [file for file in os.listdir(picture_path) if file.endswith(suffix)]
num_picture = len(picture_file)
for i in range(num_picture):
picture = list(Image.open(picture_path + '\\' + picture_file[i]).getdata())
y = [0] * num_people
y[i // num_picture_single] = 1
if i % num_picture_single < num_train:
x_train.append(picture)
y_train.append(y)
else:
x_test.append(picture)
y_test.append(y)
x_train, x_test, y_train, y_test = numpy.array(x_train), numpy.array(x_test), numpy.array(y_train), numpy.array(y_test)③将数据变为四维张量并归一化,图像数据需要转换为四维张量,维度是(样本数,图像高度,图像宽度,通道数)。此处将图像数据的通道数设置为1,表示灰度图像。然后对图像数据进行归一化处理,将像素值缩放到0到1之间。
x_train = x_train.reshape(x_train.shape[0], dimension[0], dimension[1], 1).astype('float32') / 255
x_test = x_test.reshape(x_test.shape[0], dimension[0], dimension[1], 1).astype('float32') / 255④建了模型,采用了序贯模型(Sequential)。模型由一个卷积层、一个最大池化层、一个扁平层(用于将多维数据展平为一维)、一个全连接层(用于输出分类概率)组成。激活函数使用了 ReLU,并且最后的全连接层使用了 softmax 激活函数以获得分类概率。
model = Sequential()
model.add(Conv2D(filters=4, kernel_size=(3, 3), activation='relu', input_shape=(dimension[0], dimension[1], 1)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(num_people, activation='softmax'))⑤使用交叉熵作为损失函数,Adam 作为优化器进行训练,并且监测模型的准确率。
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])⑥使用训练集对模型进行训练,指定了批次大小和训练轮数,并在训练过程中显示进度和验证集的表现。
history = model.fit(x_train, y_train, batch_size=128, epochs=20, verbose=1, validation_data=(x_test, y_test))⑦对训练好的模型使用测试集进行验证,并打印出测试准确率。
score = model.evaluate(x_test, y_test, verbose=0)
print('Test accuracy:', score[1])模型训练
以下是python构建的卷积神经网络在ORL、FERET和YaleFace三个人脸数据集的训练和表现情况。
- ORL人脸数据集
ORL人脸数据集有40个人的人脸数据,每个人10张照片,一共400张照片,照片的维数是46×56。我们将每个人的前5张照片作为训练集,共200张,剩下的5张作为测试集,最后的全连接层采用40个神经元作为模型的输出,使用了64个卷积核,训练了20轮,训练过程如图1所示。
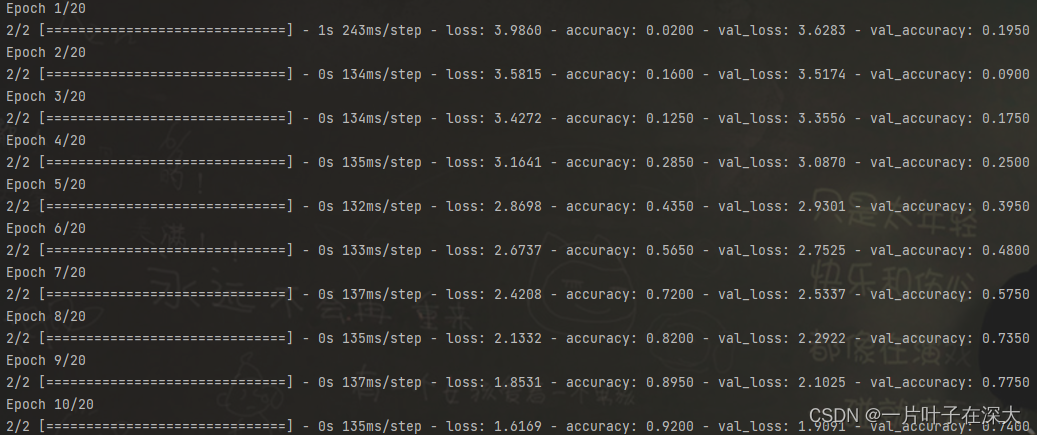
图1 ORL训练过程
训练出的人脸识别模型在测试集上的识别率随训练的轮次的变化如图2所示。

图2 ORL识别率
具体数据如表1所示。

表1 ORL
由结果可以看出,ORL数据集训练出来的模型,其拟合效果和泛化效果都比较好。
- FERET人脸数据集
FERET人脸数据集有200个人的人脸数据,每个人7张照片,一共1400张照片,照片的维数是80×80。我们将每个人的前4张照片作为训练集,共800张,剩下的3张作为测试集,最后的全连接层采用200个神经元作为模型的输出,使用了4个卷积核,训练了20轮,训练过程如图3所示。

图3 FERET训练过程
训练出的人脸识别模型在测试集上的识别率随训练的轮次的变化如图4所示。

图4 FERET识别率
具体数据如表2所示。

表2 FERET
由结果可以知道,FERET数据集训练出来的模型,其拟合效果很好,但泛化效果并不理想,分析原因可能是因为训练的数据过少,加上FERET的噪声影响比较大,最后一张照片光线很暗,导致了测试集的识别率不高。
- Yale Face人脸数据集
Yale Face人脸数据集有15个人的人脸数据,每个人11张照片,一共165张照片,照片的维数是80×100。我们将每个人的前6张照片作为训练集,共90张,剩下的5张作为测试集,最后的全连接层采用15个神经元作为模型的输出,使用了16个卷积核,训练了20轮,训练过程如图5所示。

图5 Yale Face训练过程
训练出的人脸识别模型在测试集上的识别率随训练的轮次的变化如图6所示。

图6 Yale Face识别率
具体数据如表3所示。

表3 Yale Face
由结果可以看出,Yale Face数据集训练出来的模型,其拟合效果和泛化效果都比较好。