每日学术速递6.30

点击下方卡片,关注「AiCharm」公众号
Subjects: cs.CV
1.MIMIC: Masked Image Modeling with Image Correspondences

标题:MIMIC:具有图像对应的蒙版图像建模
作者:Kalyani Marathe, Mahtab Bigverdi, Nishat Khan, Tuhin Kundu, Aniruddha Kembhavi, Linda G. Shapiro, Ranjay Krishna
文章链接:https://arxiv.org/abs//2306.15128
项目代码:https://github.com/RAIVNLab/MIMIC
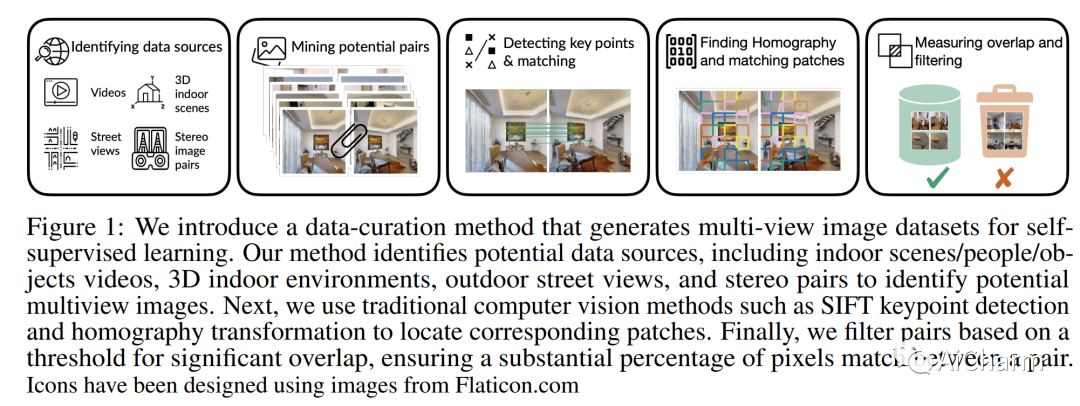
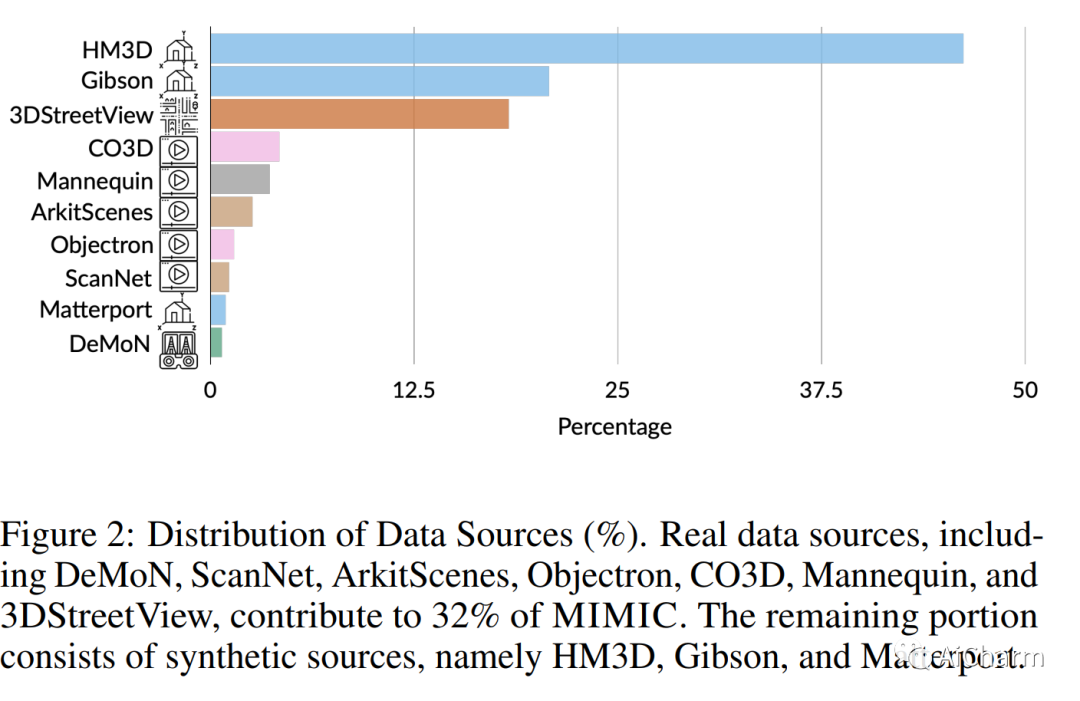
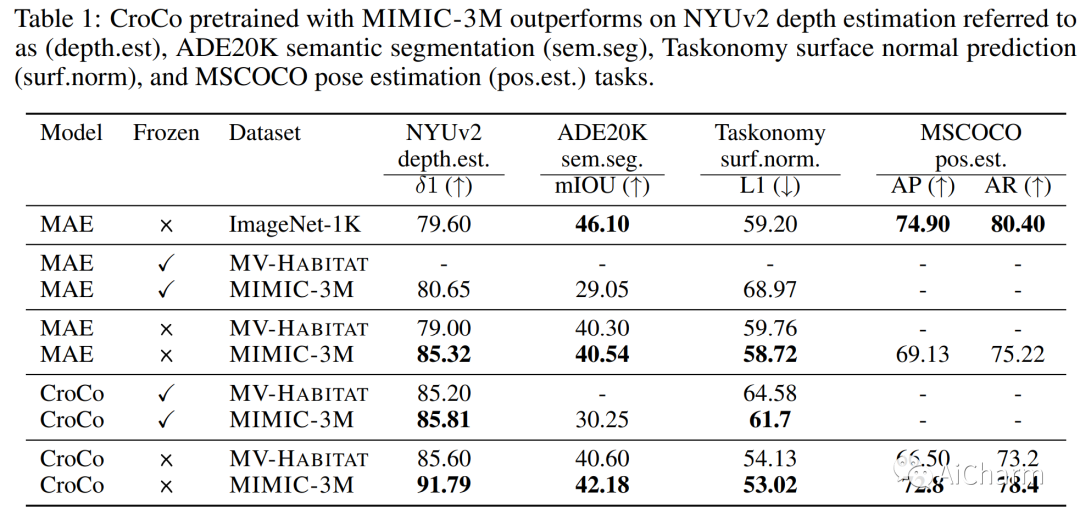
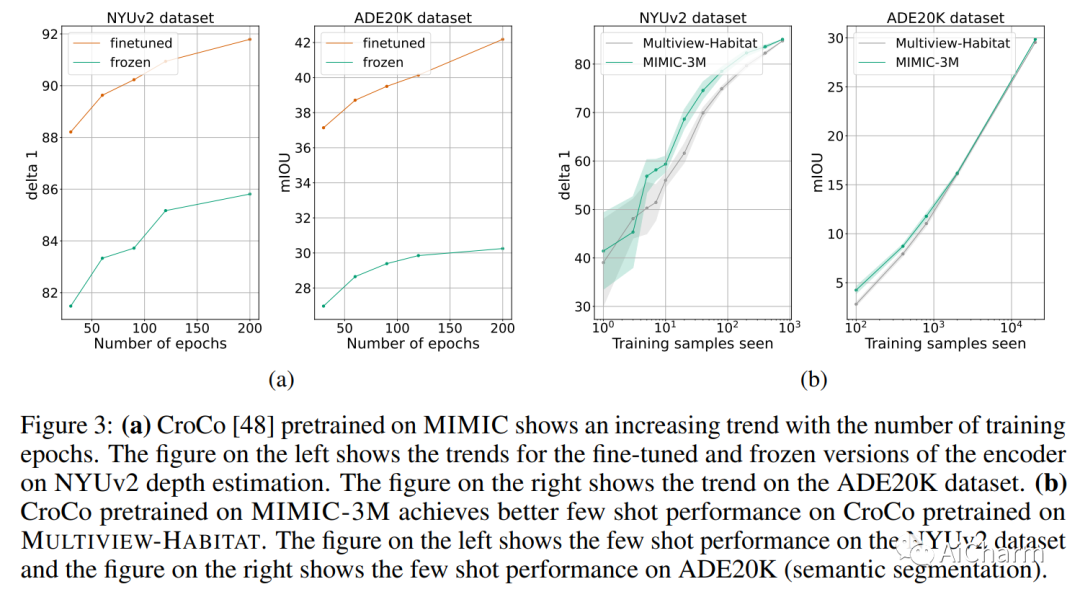
摘要:
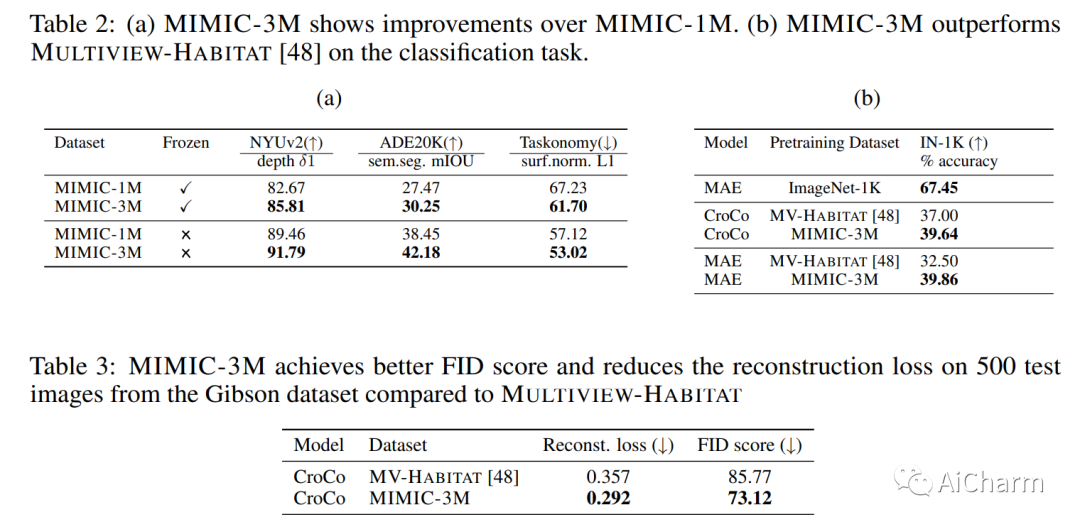
如今计算机视觉中的许多像素密集预测任务(深度估计和语义分割)都依赖于预训练的图像表示。因此,整理有效的预训练数据集至关重要。不幸的是,有效的预训练数据集是那些具有多视图场景的数据集,并且仅使用来自模拟环境的带注释的 3D 网格、点云和相机参数进行整理。我们提出了一种不需要任何注释的数据集管理机制。我们从开源视频数据集和合成 3D 环境中挖掘两个数据集:具有 1.3M 的 MIMIC-1M 和具有 3.1M 多视图图像对的 MIMIC-3M。我们训练具有不同掩模图像建模目标的多个自监督模型,以展示以下发现:在 MIMIC-3M 上训练的表示优于在多个下游任务上使用注释挖掘的表示,包括深度估计、语义分割、表面法线和姿势估计。当下游训练数据仅限于少数样本时,它们的性能也优于冻结的表示。更大的数据集 (MIMIC-3M) 显着提高了性能,这是有希望的,因为我们的管理方法可以任意扩展以生成更大的数据集。MIMIC 代码、数据集和预训练模型在此 https URL 上开源。
2.CLIPA-v2: Scaling CLIP Training with 81.1% Zero-shot ImageNet Accuracy within a 10,000 Budget; An Extra 4,000 Unlocks 81.8% Accuracy
标题:CLIPA-v2:在 10,000 美元的预算内以 81.1% 的零样本 ImageNet 准确率扩展 CLIP 训练;额外 4,000 美元可实现 81.8% 的准确率
作者:Xianhang Li, Zeyu Wang, Cihang Xie
文章链接:https://arxiv.org/abs//2306.15658
项目代码:https://github.com/UCSC-VLAA/CLIPA

摘要:
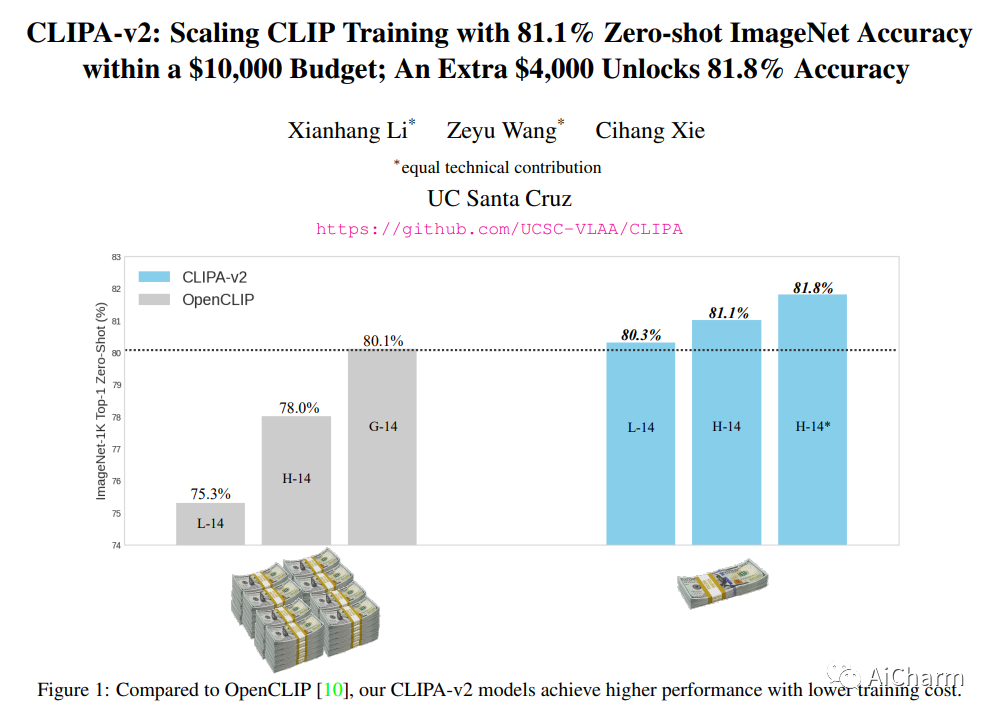
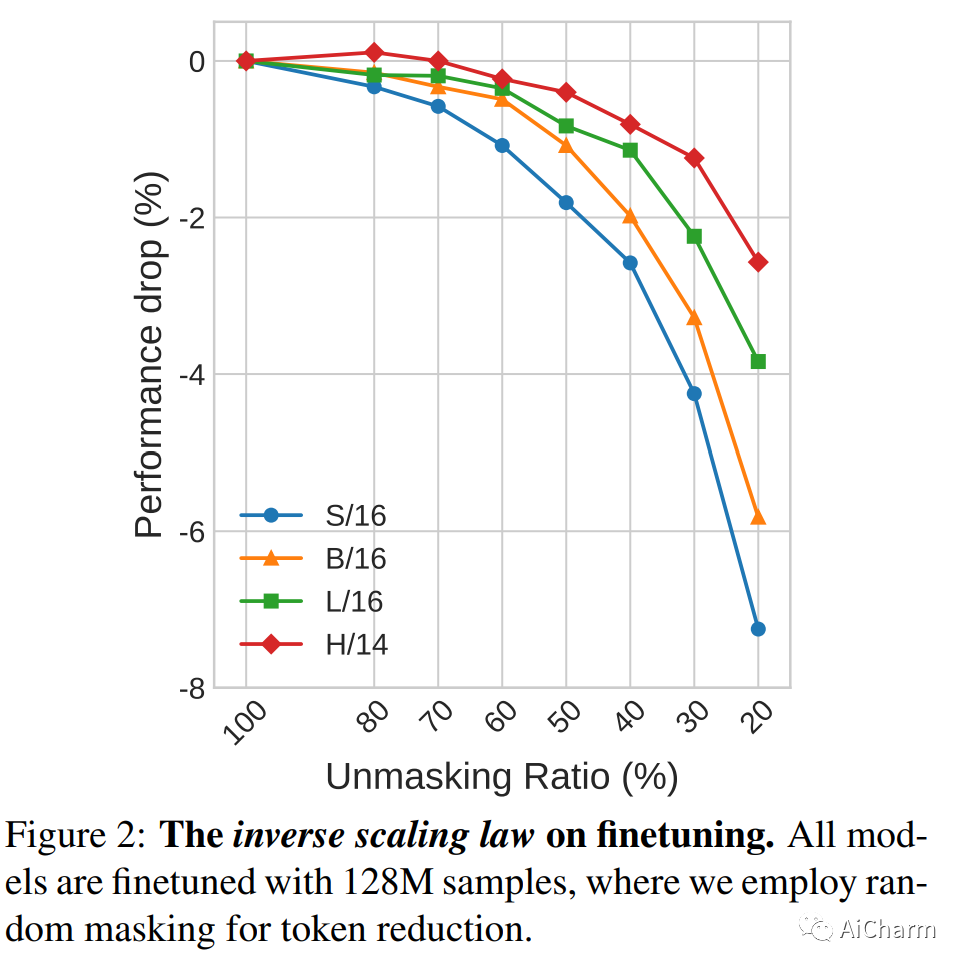
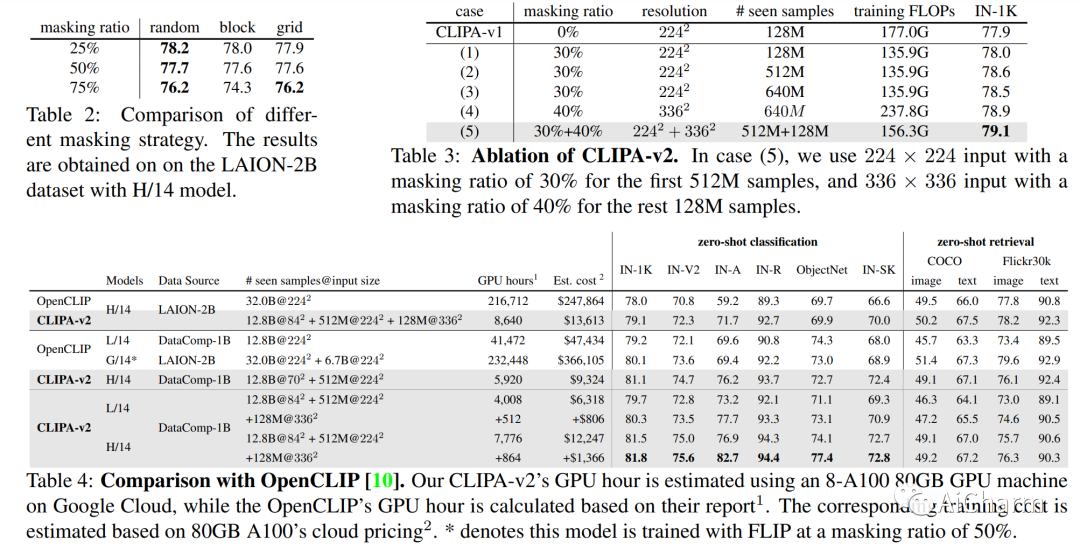
最近的工作 CLIPA 提出了 CLIP 训练的逆缩放定律——使用的图像/文本编码器越大,可应用于训练的图像/文本标记的序列长度越短。这一发现使我们能够训练高性能 CLIP 模型,并显着减少计算量。在此工作的基础上,我们特此提出 CLIPA-v2 的两个关键贡献。从技术上讲,我们发现这种逆缩放定律也适用于微调阶段,从而进一步减少计算需求。根据经验,我们大规模探索 CLIPA,将实验扩展到 H/14 模型,在训练期间看到约 13B 个图像-文本对。我们的结果令人兴奋——仅分配 10,000 美元的预算,我们的 CLIP 模型就实现了令人印象深刻的 81.1% 的零样本 ImageNet 准确率,比之前最好的 CLIP 模型(来自 OpenCLIP,80.1%)高出 1.0%,同时减少了计算量成本约 39 倍。此外,额外投资 4,000 美元,我们可以将零样本 ImageNet 准确率进一步提升至 81.8%。我们的代码和模型可从此 https URL 获取。
3.Kosmos-2: Grounding Multimodal Large Language Models to the World

标题:Kosmos-2:为世界奠定多模态大型语言模型的基础
作者:Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei
文章链接:https://arxiv.org/abs/2306.14824
项目代码:https://aka.ms/kosmos-2





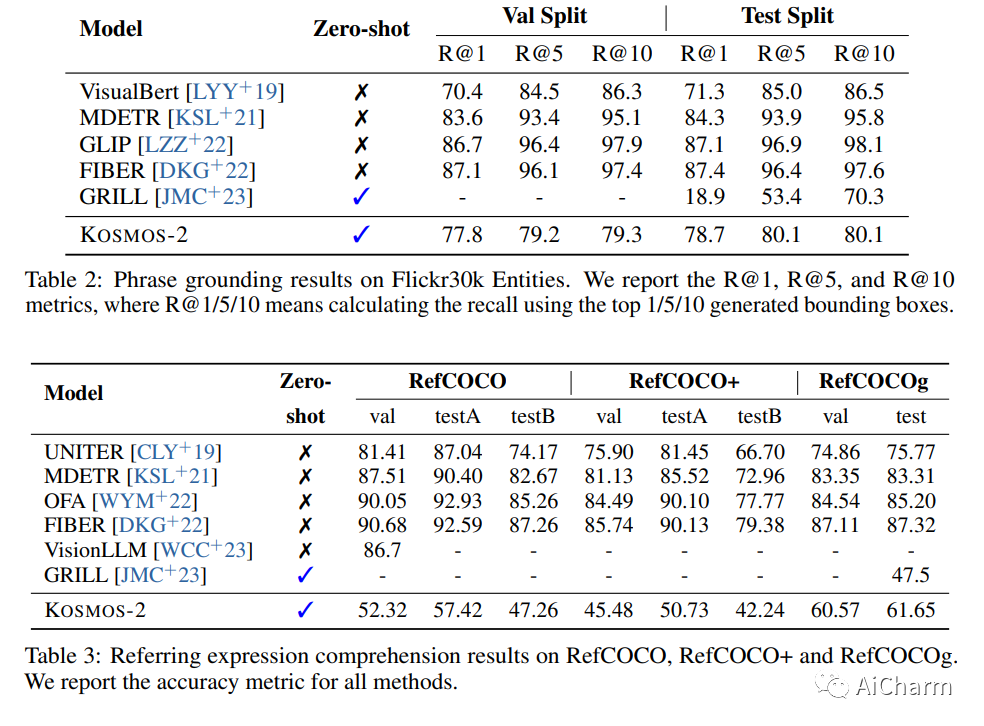

摘要:
我们引入了 Kosmos-2,一种多模态大语言模型 (MLLM),支持感知对象描述(例如边界框)和将文本融入视觉世界的新功能。具体来说,我们将引用表达式表示为 Markdown 中的链接,即“[文本范围](边界框)”,其中对象描述是位置标记的序列。我们与多模态语料库一起构建大规模的基础图像文本对数据(称为 GrIT)来训练模型。除了 MLLM 的现有功能(例如感知一般模式、遵循指令以及执行上下文学习)之外,Kosmos-2 还将接地功能集成到下游应用程序中。我们在广泛的任务上评估 Kosmos-2,包括(i)多模态基础,例如指称表达理解和短语基础,(ii)多模态指称,例如指称表达生成,(iii)感知语言任务,以及(iv) 语言理解和生成。这项工作为 Embody AI 的发展奠定了基础,并揭示了语言、多模态感知、动作和世界建模的大融合,这是迈向通用人工智能的关键一步。数据、演示和预训练模型可从此 https URL 获取。
推荐阅读
CVPR 2023 | 自动驾驶3D occupancy prediction挑战赛—冠军方案


CVPR 2023 | 神经网络超体?新国立LV lab提出全新网络克隆技术

点击卡片,关注「AiCharm」公众号
喜欢的话,请给我个在看吧!
