编写高效代码--内存篇
编写高效代码--内存篇


在近期线上故障排查过程中,我发现代码中仍在使用一些libc库函数,诸如malloc()内存分配、memset()内存清零及htonl()、ntohl()高低字节序转换等,这些函数在性能上存在优化空间。鉴于此,本文将借鉴DPDK《高效编码指南》中的相关内容,探讨VPP框架下更为高效的实现策略,以替换上述传统函数,提升系统性能。本节主要介绍在 DPDK&VPP 环境中开发应用程序时的一些关键内存注意事项。
内存拷贝:数据平面切勿使用libc。
虽然libc库中在编译时通常会利用底层硬件的特性,包括Intel的指令集优化。对于像 memcpy 这样的核心函数,glibc 实现会自动检测处理器架构并利用相应的优化,比如SSE、AVX乃至AVX-512指令集,来加速内存复制操作。这些优化能够使 memcpy 在支持这些指令集的Intel处理器上运行得更高效,通过并行处理多个数据来减少复制时间。但是DPDK中 rte_memcpy提供了优化过的内存复制函数,这些函数往往更加针对特定应用场景进行了深度优化。
DPDK环境中通过Linux*应用层引入了众多libc函数,这无疑便利了应用程序的移植与配置平面的开发。然而,这些函数中的许多并未针对性能进行优化。在数据平面中,应避免使用诸如memcpy()或strcpy()这样的函数。对于小规模结构体的复制,推荐采用更为简单的编译器友好型技术以实现优化。 针对频繁调用的特定函数,自定义优化函数是一个良策,此类函数应声明为static inline以利内联优化。DPDK API提供了高度优化的rte_memcpy()函数,专为提升内存拷贝效率而设计。 https://doc.dpdk.org/guides/prog_guide/writing_efficient_code.html
同样在VPP基础架构库vppinfra/string.h文件中提供了VPP高度优化函数clib_memcpy()。此函数主要在X86架构下进行深度优化,在其他架构系统仍然调用libc库memcpy函数。
内存分配优化
libc中的其他函数,如malloc(),提供了灵活的内存分配与释放机制。确有场合需动态分配内存,但在数据处理层使用类似malloc的函数并不推荐,因为管理碎片化的堆空间成本高昂,且分配器未必针对并行分配做了优化。 若数据平面确需动态分配,采用固定大小对象的内存池更为适宜。librte_mempool库为此提供了API支持。此数据结构通过多项服务提升性能,包括对象内存对齐、无锁对象访问、NUMA感知、批量获取/释放以及每核缓存功能。rte_malloc()函数亦采纳了与内存池相似的设计理念。 DPDK程序员指南--
在VPP中18.10版本以前使用自带的内存管理库mheap,可能是因为性能原因自v18.10版本起替换为dlmalloc。在vpp-dev邮箱列表中我们仍然可以查询到mheap的性能缺陷。感兴趣的同学可以阅读下面链接内容:
https://lists.fd.io/g/vpp-dev/topic/17425390#msg9020
https://lists.fd.io/g/vpp-dev/topic/10642197#6399
而VPP不使用libc库malloc内存管理的原因,可以有以下几个原因:
- 性能优化:传统的libc库内存管理模块,如glibc的malloc,虽然通用性强,但在高并发和低延迟的网络环境下,其性能可能无法满足需求。dlmalloc等定制化的内存分配器通过优化内存分配策略,如减少内存碎片、提供更快的分配与释放速度,以及针对特定应用场景的调整,可以更好地满足VPP的性能需求。
- 控制粒度与策略:VPP可能需要对内存管理有更细粒度的控制,包括内存分配的大小、对齐方式、以及内存池的管理等。dlmalloc提供了更多的配置选项和扩展接口,允许VPP根据其特有的数据包处理模式定制内存管理策略,例如使用内存池来减少内存分配的开销,提高数据处理的效率。
- NUMA感知与优化:在多核、NUMA(Non-Uniform Memory Access)架构的系统中,dlmalloc可以通过特定的配置和策略来优化内存分配,确保内存分配尽可能地靠近使用它的CPU,减少跨NUMA节点的内存访问延迟,这一点对于追求极致性能的VPP至关重要。
- 减少系统调用:使用像dlmalloc这样的用户态内存分配器可以减少对操作系统内核的依赖,避免因系统调用导致的性能开销。特别是在高速数据包处理场景下,减少系统调用可以显著提升处理效率。
- 避免全局锁竞争:标准libc的malloc实现可能会使用全局锁来保护堆数据结构,这在多线程环境中可能导致严重的锁竞争。而dlmalloc等分配器通过使用更细粒度的锁机制或者无锁设计来减少这种竞争,提高并行处理能力。
- 内存跟踪功能:Memory tracing通常涉及记录内存分配和释放的详细信息,帮助开发者理解和诊断内存使用情况,包括发现内存泄漏、跟踪内存错误等问题。在文章《VPP 内存泄漏定位跟踪》中我们详细介绍过此功能的应用。
在编码过程中,如需要申请内存,可以使用下面两个函数clib_mem_alloc()或者clib_mem_alloc_aligned()函数;两者的区别在后者可以指定一定的长度对齐(一般是cacheline行64字节对齐),在处理频繁热点数据时,降低cache一致性问题,提升性能。比如报文缓存取buffer就是使用后者。
/* Memory allocator which calls os_out_of_memory() when it fails */
__clib_export __clib_flatten void *
clib_mem_alloc (uword size)
{
return clib_mem_heap_alloc_inline (0, size, CLIB_MEM_MIN_ALIGN,
/* os_out_of_memory */ 1);
}
__clib_export __clib_flatten void *
clib_mem_alloc_aligned (uword size, uword align)
{
return clib_mem_heap_alloc_inline (0, size, align,
/* os_out_of_memory */ 1);
}
对同一内存区域的并发访问:多个逻辑核心(lcores)对同一内存区域进行读写(RW)操作时,会产生大量缓存未命中,这是极其消耗资源的。通常,可以采用以下至少两种解决方案来优化:
利用RTE_PER_LCORE变量。请注意,此时lcore X上的数据对lcore Y不可见。
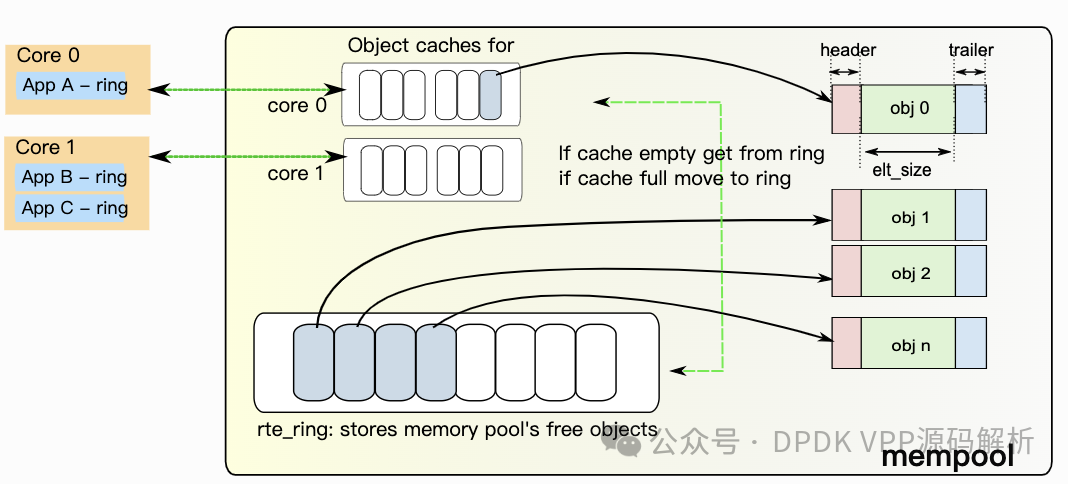
下图是DPDK报文高速缓存区就是基于每个CPU core申请一个缓存区。就CPU使用而言,多个核心并发访问内存池的空闲缓冲区环可能成本较高,因为每次访问都需要执行比较并设置(CAS)操作。为减少对内存池环的访问请求,内存池分配器可维护每个核心的缓存,并通过该缓存进行批量请求至内存池环,这样做会显著减少对实际内存池结构的加锁次数。这样一来,每个核心都能无障碍地访问其私有缓存(含锁)中的空闲对象,仅当缓存填满时,核心才需要将部分空闲对象移回内存池环,或在缓存耗尽时获取更多对象。
尽管这意味着某些核心的缓存中可能会有缓冲区闲置,但核心能无需加锁迅速访问特定内存池的私有缓存,这一机制显著提升了性能。
使用结构体数组(每个逻辑核心对应一个)。这种情况下,每个结构体都应确保缓存对齐。
这种在VPP代码中用的很多,比如handoff 全局配置结构体vlib_frame_queue_main_t中的存储报文缓存区队列vlib_frame_queues就是每个逻辑核对应一个。其中vlib_frame_queues就是确保缓存行对齐
vec_validate (fqm->vlib_frame_queues, tm->n_vlib_mains - 1);
typedef struct
{
/* static data */
CLIB_CACHE_LINE_ALIGN_MARK (cacheline0);
vlib_frame_queue_elt_t *elts;
u64 vector_threshold;
u64 trace;
u32 nelts;
/* modified by enqueue side */
CLIB_CACHE_LINE_ALIGN_MARK (cacheline1);
volatile u64 tail;
/* modified by dequeue side */
CLIB_CACHE_LINE_ALIGN_MARK (cacheline2);
volatile u64 head;
}
vlib_frame_queue_t;
对于大多为只读的变量,若其所在缓存行不含读写变量,则在多个逻辑核心间共享不会造成性能损失。在编码中需要精心的设计数据结构。
NUMA架构:在NUMA系统中,访问本地内存更为可取,因为远程内存访问速度较慢。DPDK中的memzone、ring、rte_malloc及mempool API提供了在指定Socket上创建内存池的方法。
有时,为提升速度复制数据是个好策略。对于频繁访问的大多为只读变量,即使仅保留在一个Socket中也不会构成问题,因为数据将被缓存。
内存通道间的分布:现代内存控制器具备多条内存通道,能够并行进行数据加载或存储。依据内存控制器及其配置,通道数量及内存跨通道的分配方式各不相同。每个通道都有带宽限制,若所有内存访问均集中于第一条通道,可能会形成潜在瓶颈。
默认情况下,Mempool库会将对象地址分散到各个内存通道中,以平衡负载。
锁定内存页操作系统有权自主加载/卸载内存页。这些页面加载操作可能会影响性能,因为在内核获取它们时进程会暂停。
为了避免这种情况,可以预先加载内存页,并使用mlockall()调用来将其锁定在内存中,防止被交换出。
f (mlockall(MCL_CURRENT | MCL_FUTURE)) {
RTE_LOG(NOTICE, USER1, "mlockall() failed with error \"%s\"\n",
strerror(errno));
}