Pynapple:一个用于神经科学中数据分析的工具包
原创Pynapple:一个用于神经科学中数据分析的工具包
原创
摘要
在神经科学研究中收集的数据集越来越复杂,通常结合了来自多个数据采集模式的高维时间序列数据。在适当的编程环境中处理和操作这些各种数据流对于确保可靠的分析并促进共享可重复性分析管道至关重要。在这里,我们介绍了Pynapple,这是一个轻量级的Python包,旨在处理系统神经科学中广泛范围的时间解析数据。该包的核心特点是一小部分多功能对象,支持任何数据流和任务参数的操作。该包括一组读取常见数据格式的方法,并允许用户轻松编写自己的方法。
介绍
由于数据集越来越复杂,需要一个通用的数据分析工具箱来满足不断变化的需求。然而,大多数现有的程序都专注于从指定类型的数据中产生高级别分析,并且缺乏快速变化的分析方法和实验方法所需的灵活性。因此,设计一个通用工具箱需要考虑一些原则,如平衡灵活性和稳定性等挑战。
Pynapple的核心特点概述
Pynapple是一种面向对象的Python包,其核心特点是使用相同时间基础表达所有数据流,从而限制编码错误的机会,并为用户提供简单的环境。它围绕着五个对象构建。在Pynapple中,对象是指一种数据结构,用于存储和处理特定类型的数据。Pynapple中有五种不同类型的对象,分别是事件时间戳对象、时间变化数据对象、时间时期对象等。每个对象都有其特定的属性和方法,可以对其进行操作和处理。例如,事件时间戳对象可以存储事件发生的时间戳,并提供方法来计算事件之间的间隔或将其转换为持续时间。时间变化数据对象可以存储随时间变化的数据,并提供方法来计算统计信息或进行滤波等操作。通过使用这些对象,用户可以轻松地加载、处理和分析各种类型的神经科学数据集。此外,Pynapple还提供了各种内置加载器,用于常用数据格式,具体包括:
内置的数据加载器,包括:
1. Numpy loader:用于加载Numpy数组格式的数据。
2. HDF5 loader:用于加载HDF5格式的数据。
3. NWB loader:用于加载Neurodata Without Borders (NWB)格式的数据。
4. Spike2 loader:用于加载Spike2软件生成的数据文件。
5. Blackrock loader:用于加载Blackrock Microsystems公司生成的数据文件。
6. 自定义加载器以适应任何其他格式或特定任务设计。
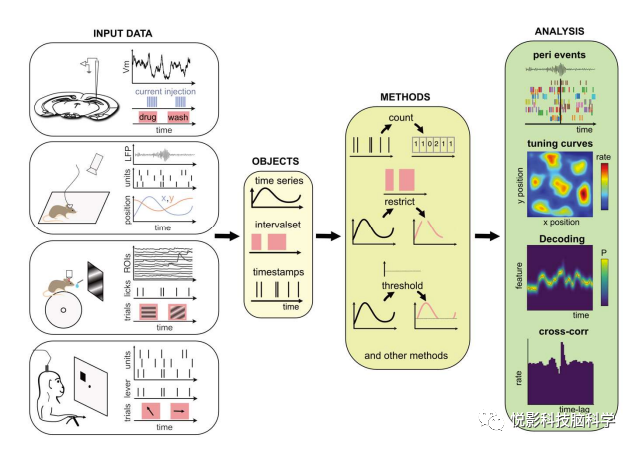
图1.用品pynapple进行数据分析。左边,任何类型的输入数据;中间,用户执行各种基本操作和操作数据操作。右侧,一套基础的分析方法,不依赖于任何外部包,例如(从上到下)数据的周围事件对齐(上),一和二维调谐曲线,一和二维解码;事件的自动关联和互相关联时间(如动作电位)。
核心方法
Pynapple中的核心方法是一组用于操作核心对象的函数,这些函数可以帮助用户执行常见的神经科学分析。这些方法包括:
1. 时间戳对象方法:用于计算事件时间戳之间的间隔、转换时间戳为持续时间等。
2. 时间变化数据对象方法:用于计算统计信息、进行滤波、提取特征等。
3. 时间时期对象方法:用于将时间变化数据划分为不同的时期、计算时期之间的差异等。
这些方法可以帮助用户快速地对神经科学数据进行处理和分析,由于Pynapple采用了最小参数设置策略,因此用户不需要设置太多参数就可以完成复杂的分析任务。
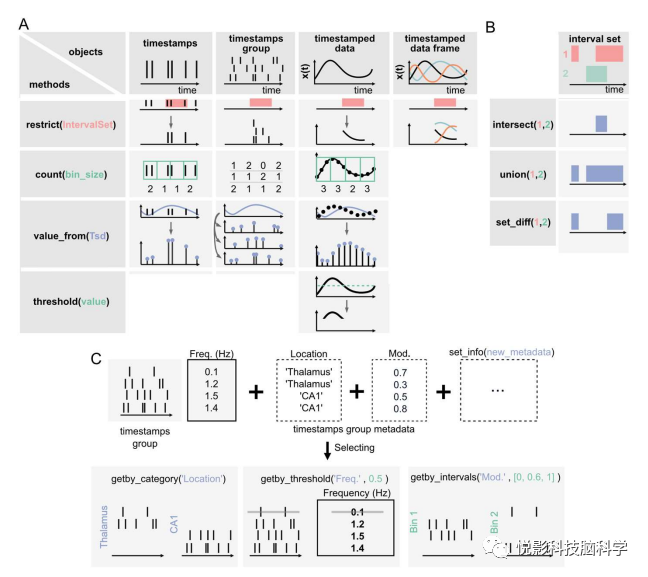
图2.Pynapple中的核心方法
A)时间戳(Ts)和时间戳数据(Tsd)对象。对于不同的对象,可以调用相同的方法,从而导致定性上相似的结果。例如,object.restrict(intervalset)返回一个对象,是其原始时间支持和输入区间集的交集上。对象可以是任何一个时间戳和带有时间戳的数据对象。这些方法可以仅用一个参数进行调用,默认参数对于大多数分析通常是相同的,然而,这些方法还包含了针对更具体操作的附加参数。
B)逻辑操作
C)TsGroup对象的方法。每个时间戳默认与它的发生相关比率可以添加其他自定义元数据,如记录位置。这些元数据可以用来选择和过滤时间戳使用getby_category离散标签,getby_threshold or getby_intervals表示数值。
Pynapple的核心特性主要是基于面向对象编程的思想,解决神经科学数据分析中常见的问题,包括:1. 数据格式不一致:Pynapple通过将所有数据都表示为时间戳和时间变化数据对象。2. 数据处理复杂:Pynapple提供了一组简单但功能强大的核心方法,可以帮助用户快速地对神经科学数据进行处理和分析。3. 参数设置繁琐:Pynapple采用了最小参数设置策略,使得用户不需要设置太多参数就可以完成复杂的分析任务。4. 代码错误率高:Pynapple采用面向对象编程的思想,限制了代码错误率,并提供了简单易用的环境来操作数据。
从Pipeline中导入数据
为了简化从各种流加载和同步数据的过程,Pynapple包括一个I/O (Input/Output) 层,允许用户加载多种类型的数据集并将它们写入一种通用格式以便进行进一步的分析和分享。例如,调用体内电生理记录的load_session将返回一个叫做data的对象,它将有属性如data.spikes, data.position, 和data.epochs,存储到一个Ts组包含峰值时间,TsdFrame则是一个包含动物位置的,以及一个包含动物在轨道上的时间的间隔集。用这个有方向性的 I/O方法,用户可以与给定的实验会话相关联的各种数据流进行交互,并一次加载多个会话,避免时间混淆。
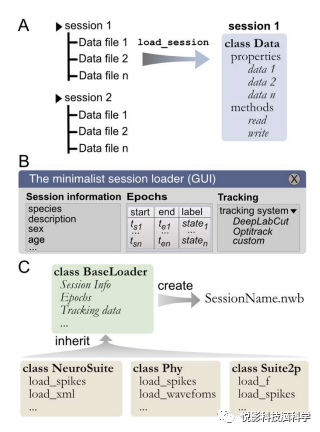
图3.内置和可定制的加载功能
A)数据最初是作为一个文件夹中的单独文件组织起来的。调用内置或定制的load_csesin函数将数据加载到数据类中。B)数据可以通过自定义方式进行加载可识别的GUI,以输入有关实验的所有相关信息,例如动物品系等。记录的主要时期(例如,行为状态、刺激类别等)可以从标准的表格数据文件(如CSV)中加载。还可以加载从各种公共系统中提取并保存为CSV文件的行为跟踪数据。C) Pynapple提供各种用于常用数据格式的内置加载器,以及可以轻松设计可定制加载器的模板,以适应任何其他格式或特定任务设计的模板。
数据同步是任何分析管道的关键。因此,load_session函数是使用包的关键步骤。对于不受支持的数据类型,用户需设计以相同的绝对时间基对齐数据流的预处理脚本。数据加载和同步功能已经包含在包中。虽然数据类型通常是特定于一种记录方式的(即钙成像和电生理学),但有一些元数据在许多实验中是常见的,如动物物种、年龄、性别和实验者的名字。当第一次加载会话时,I/O过程从图形用户界面(GUI)开始,用户可以在GUI中进行快速操作、方便地输入一般信息以及任何会话和行为跟踪数据(图3b),此信息也保存在基础加载器类中。为了覆盖目前在系统神经科学中使用的各种预处理分析管道,I/O可以加载CNMF-E,Phy,NeuroSuite或Suite2P。为了避免代码冗余,这些I/O类继承了BaseLoader类的属性。为了避免重复输入会话信息和多个数据流同步的过程,Pynapple将所有同步的数据保存到一个唯一的文件中,并可以容纳一个广泛范围的神经科学数据类型。使用NWB格式进行快速和通用的数据加载和保存,也是Pynapple所推荐的。在Pynapple的I/O层中使用数据加载类的继承方法有多种好处。首先,未来新的I/O类的开发不会影响核心和流程层。这确保了包装的长期稳定性。其次,用户可以使用已有类的链继承来开发自己的自定义I/O。使用已存在的代码进行加载以特定的方式处理数据,而不是重写现有的函数,这样可以避免预处理错误。第三,用户仍然可以不使用Pynapple的I/O层。最后,为了将以前的分析,或在另一个实验室开发的分析,应用于新的数据或数据类型,用户只需要为他们的数据开发一个新的I/O类。这将把数据导入到通用的Pynapple中核心,从中可以使用相同的分析管道。
基础数据处理
这是Pynapple中的一个部分,它提供了一些基本的方法来操作核心对象,使用户能够执行常见但强大的神经科学分析。这些分析能够描述时间序列对象之间的关系,并且需要用户设置最少数量的参数。这最大程度地减少了复杂性,同时最大化了通用性。Pynapple中的操作可以重新创建来自广泛子学科的神经科学分析,这些分析构成了Pynapple中神经科学数据分析的基础。例如:使用Pynapple对V1神经元进行视觉刺激分析。该实验记录了小鼠在跑步轮上固定头部并呈现自然场景电影时的钙成像数据。通过预处理感兴趣区域的荧光迹线和运动速度数据,可以直接获得连续的调谐曲线。Pynapple计算一个神经元(或任何其他时间戳数据)的发射率,例如离散条件,如“开/关”刺激,调整曲线也可以计算关于一个连续的特征,一旦计算出来,Pynapple就可以使用来自神经元群的调谐曲线,使用贝叶斯解码来解码刺激(图4A)。第二个基本分析是计算事件数据的自动相关图和交叉相关图。在最抽象的意义上,这些相关图显示了之前和未来事件之间的关系在时间为0时的当前事件。在Pynapple中,通过计算目标时间序列中相对于每个事件的每个时间箱的事件率,可以为任意两个事件系列生成交叉相关图的参考时间序列。通常,这被用来检查一个神经元中的动作电位与同一神经元中先前或未来的动作电位相关的可能性或另一个神经元(交叉相关图)(图4B)。然而,Pynapple并不将此功能限制为峰值数据,并且可以对任何基于事件的数据执行相关图。第三个基础分析是事件的对齐。这涉及将指定的窗口从Ts/Tsd/TsGroup数据对齐到特定的Ts,称为“时间戳引用”。这是允许的用户将数据对齐到特定的时间点,并测量在这个指定的时间点附近的速率变化(图4C)。这个函数有用的一个例子是将神经元峰值对齐到规范特异性刺激,如光遗传照明、音调的呈现或电刺激。
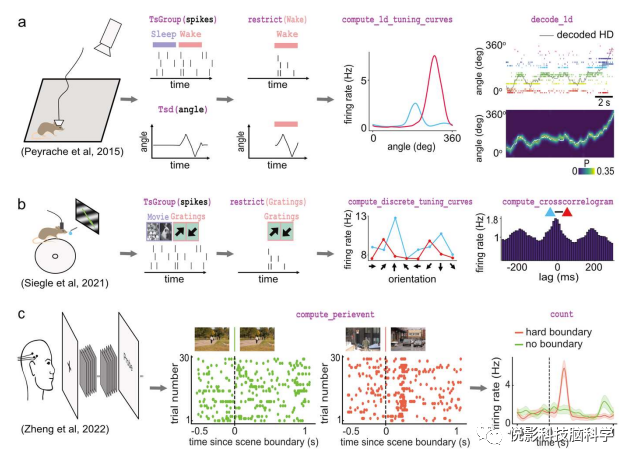
图4.使用Pynapple对各种电生理数据集进行基础分析示例。A)头部方向细胞的分析。从左到右:数据收集方式为一只自由移动的老鼠,随机寻找食物;所有的数据都被限制在觉醒期(即在探索过程中);两个神经元相对于动物头部方向的调谐曲线。B)对视觉刺激过程中V1神经元的分析。从左到右:鼠标在固定头部时被记录下来提出漂移光栅;尖峰、刺激和时代;两个V1神经元的调谐曲线示例,显示了它们在不同光栅方向下的放电率;两个V1神经元之间的相关性,在视觉刺激期间显示出约5Hz的振荡调节。C)癫痫患者内侧颞叶神经元的分析,从左到右:受试者植入混合深电极,展示一系列短片段;围绕连续电影拍摄试验(绿色)和硬背景的单个神经元的栅格图边界试验,这是两个不相关的电影之间的过渡(橙色);两种试验类型的事件周围神经元放电率。
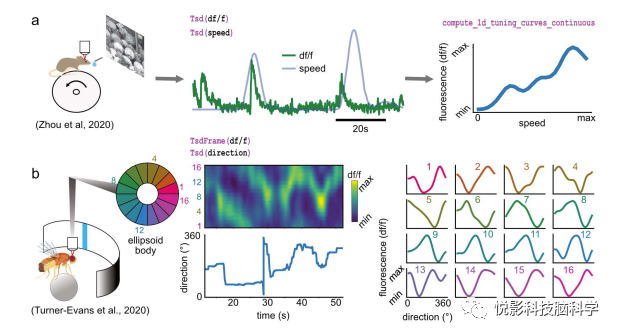
图5.使用Pynapple对各种钙成像数据集进行基础分析示例。A)视觉刺激过程中V1神经元的分析。B)在果蝇中枢复合体中的神经元活动分析。
Pynacollada: 专业的和不断更新的数据分析协作图书馆
Pynacollada是一个专门用于协作的数据分析库,它是Pynapple的一部分。与Pynapple不同,Pynacollada是一个面向项目的库,可以让社区在不影响核心管道功能的情况下协作开发不断发展的数据分析代码。每个项目都应该包括一个可调用特定功能和/或Jupyter笔记本演示代码使用的脚本,以及适当的文档。这个库可以让用户更容易地共享和重复使用他们的代码,并且可以促进更广泛和持续的协作。Pynacollada可以处理各种复杂的数据分析任务,例如:神经科学中的视觉刺激分析、基因组学中的RNA测序数据分析、生态学中的物种多样性分析等。
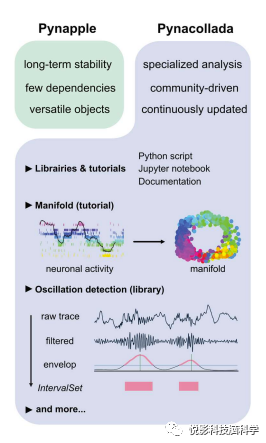
图6.Pyapple软件协作数据分析存储库环境。包括的库和/或教程: (1)流形分析教程,介绍如何使用各种机器学习技术在低维子空间上投射神经元数据;(2)振荡库局部场势中的检测,以原始的宽带轨迹作为输入和输出区间集对象,对应于振荡回合的开始和结束时间。
讨论
Pynapple和Pynacollada的优点和局限性
优点 | 缺陷 | |
|---|---|---|
Pynapple | l 提供了一套易于使用的数据分析工具,可以帮助科学家更好地管理和分析数据。l 采用面向对象的编程方法,使得代码更加模块化、可重用性更高。l 提供了详细的文档和示例,方便用户学习和使用。 | l 目前只支持Python语言,对于其他编程语言的用户需要进行转换。l 对于大规模数据集的处理能力有限。l Python代码运行速度相对较慢。 |
Pynacollada | l 提供了一个协作式数据分析环境,可以促进科学家之间更广泛、更持续的协作。l 采用项目化库设计,使得每个项目都可以独立开发、测试和部署。l 提供了丰富的文档和示例,方便用户学习和使用。 | l 仍然需要一定程度上掌握Python编程技能才能使用。l 对于大规模数据集的处理能力有限。 |
Pynapple和Pynacollada可以帮助科学家更好地管理和共享他们的数据分析代码,并促进更广泛和持续的协作。未来的发展方向是增加对分布式计算框架的支持、增加对GPU加速计算的支持等。最后,作者强调了开源软件在科学研究中的重要性,并呼吁更多科学家参与到开源软件开发中来。
参考文献:Pynapple: a toolbox for data analysis in neuroscience.
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。