R语言豆瓣数据文本挖掘 神经网络、词云可视化和交叉验证
原创R语言豆瓣数据文本挖掘 神经网络、词云可视化和交叉验证
原创
全文链接:http://tecdat.cn/?p=31544
原文出处:拓端数据部落公众号
在网络技术高速发展的背景下,信息纷乱繁杂,如何能够获得需要的文本信息,成了许多企业或组织关注的问题。
该项目以采集的豆瓣电影评论数据为例,使用R语言和神经网络算法,对文本挖掘进行全流程的分析,包括对其特征及其子集进行提取,并对文本进行词云可视化和分类处理,同时采用交叉验证方法对模型进行调整,从而预测有关评论的类型,并将其作为电影推荐的一个标准。
电影评论数据

查看数据
head(pinglun1)
文本预处理
#剔除通用标题
res=(pattern="NIKEiD"," ",res);
res=(pattern="http://t.cn/"," ",res);
res=(pattern="com"," ",res);中文分词技术
不同于英文每一个单词具有明确的划分标准,中国的汉字博大精深、历史悠久。一个词语或者一句话在不同的语境里有多种切分方式,并且随着网络用词的不断更新,许多具有现时意义的词语并不能为计算机所识别。
keyword=(X=res, FUN=segmentCN)绘制词汇图
词云不仅能够形象的将文本的主要内容进行呈现,清晰明了地展示出在一个测试集里面最为重要的关键词,同时也可以检验停用词的处理环节是否完善,因为如果不完善,词云中会不可避免地出现一些无意义的单个词。
mycolors <- brewer.pal(8,"Dark2")#设置一个颜色系:
wordcloud(d$word,d$freq,random.order=FALSE,random.color=FALSE,colors=
unique(words)
## [1] "通过" "亲" "父"
## [4] "养父" "岳父" "人物"
## [7] "关系" "构" "写"
## [10] "一部" "编" "有"转换成词频矩阵
由于计算机比较擅于处理电子表格、数据库这样的结构化数据,但是文本是人类的语言,所以将非结构化的文本转变成结构化的数据是非常必要的。
for(i in 1:nrow(cldata)){
for(j in unique(d$word) ){
if(j %in% unlist(key
## 故事 电影 一个 喜欢 父亲 童话 因为 这个 一部 时候 没有 知道 生活
## [1,] 0 0 0 0 0 0 0 0 1 0 0 0 0
## [2,] 0 0 0 0 0 0 0 0 0 0 0 0 0
## [594,] 0
## [595,] 0
## [596,] 0
## [597,] 0
## [598,] 0
## [599,] 0
## [600,] 0神经网络
nn <- (c(label$V1)[samp]~cldata[samp,],size=10,decay=0.01,maxit=1000,l预测分类结果
yy <- round(predict(nn, cldata))分类混淆矩阵
table(yy,label[1:500,])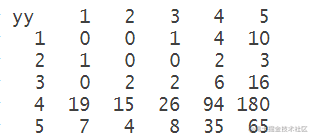
十折交叉验证
利用for循环,将参数依次赋值并对每一个结果求平均值。
k=10
for(kk in 1:k){
index=sample(1:length(data),floor(length(data)*(1/k)),replace=F)#得到测试样本样本号
test=as.data.frame(cldata[index,])#提取测试集
train=as.data.frame(cldata[-index,])#提取训练集
结论
本次项目是基于豆瓣电影评论对文本挖掘的整个流程进行阐释,对文本进行了爬取、分词、文本向量化等一系列操作。项目还需要进一步地完善。首先因文本挖掘的技术手段不如数据挖掘成熟,其次就是在不同的项目中适用的方法和模型也是不同的,比如当改变算法或者参数的时候,会导致准确率发生变化,所以在处理这个项目的时候,需要注意的是,对于运用哪种方法和建立哪种模型必须进行充分的思考和实验,从而得出比较科学的支撑依据。当然就本项目来说,也存在和其他文本挖掘项目相同的问题——分词库和停用词库不完善,所以文本挖掘这一领域仍需要大量的探索和实践,未来的研究中应该更加关注数据本身的质量和真实性并完善词典的构建。通过这个项目可以看出文本挖掘在网络评价分析方面发挥了很重要的作用,目前有很多组织或企业通过文本挖掘来提取相关产品的客户反馈,并提高自身的产品质量和服务水平。尽管这种方式还没有很完善,但是当其得到更加广泛的推广后,其中包含的技术也一定会越来越完善。相信当这种方式走向成熟时,其会广泛地应用于更多的领域,例如商品贸易、新闻出版、医疗和教育等等,那么我们的生活也会获得更多的便利。
参考文献:
[1] 张公让,鲍超,王晓玉,等.基于评论数据的文本语义挖掘与情感分析 [J].情报科学,2021,39(5):53-61.
[2] 王继成,潘金贵,张福炎.Web文本挖掘技术研究 [J].计算机研究与发展,2000(5):513-520.

最受欢迎的见解
1.Python主题建模LDA模型、t-SNE 降维聚类、词云可视化文本挖掘新闻组
3.r语言文本挖掘tf-idf主题建模,情感分析n-gram建模研究
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。